Přehled automatického škálování clusteru ve službě Azure Kubernetes Service (AKS)
Pokud chcete držet krok s požadavky aplikací ve službě Azure Kubernetes Service (AKS), možná budete muset upravit počet uzlů, na kterých běží vaše úlohy. Komponenta automatického škálování clusteru sleduje pody v clusteru, které nelze naplánovat kvůli omezením prostředků. Když automatické škálování clusteru zjistí neplánované pody, škáluje počet uzlů ve fondu uzlů tak, aby splňoval požadavky aplikace. Také pravidelně kontroluje uzly, které nemají žádné naplánované pody, a podle potřeby vertikálně snižuje počet uzlů.
Tento článek vám pomůže pochopit, jak automatické škálování clusteru funguje v AKS. Poskytuje také pokyny, osvědčené postupy a důležité informace o konfiguraci automatického škálování clusteru pro úlohy AKS. Pokud chcete povolit, zakázat nebo aktualizovat automatické škálování clusteru pro úlohy AKS, přečtěte si téma Použití automatického škálování clusteru v AKS.
Informace o automatickém škálování clusteru
Clustery často potřebují způsob automatického škálování, aby se přizpůsobily měnícím se požadavkům aplikací, například mezi pracovními dny a večery nebo víkendy. Clustery AKS se můžou škálovat následujícími způsoby:
- Automatické škálování clusteru pravidelně kontroluje pody, které není možné naplánovat na uzlech kvůli omezením prostředků. Cluster pak automaticky zvýší počet uzlů. Pokud používáte automatické škálování clusteru, je ruční škálování zakázané. Další informace najdete v tématu Jak funguje vertikální navýšení kapacity?.
- Horizontální automatické škálování podů používá server metrik v clusteru Kubernetes k monitorování požadavků na prostředky podů. Pokud aplikace potřebuje více prostředků, počet podů se automaticky zvýší tak, aby splňoval poptávku.
- Vertikální automatické škálování podů automaticky nastaví požadavky na prostředky a limity pro kontejnery na každou úlohu na základě předchozího využití, aby se zajistilo, že pody jsou naplánované na uzly, které mají požadované prostředky procesoru a paměti.
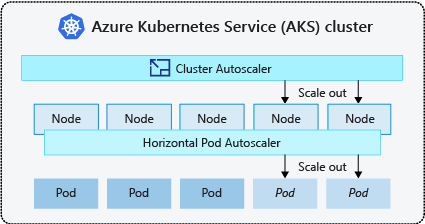
Je běžné povolit automatické škálování clusteru pro uzly a vertikální automatické škálování podů nebo horizontální automatické škálování podů pro pody. Když povolíte automatické škálování clusteru, použije se zadaná pravidla škálování, pokud je velikost fondu uzlů nižší než minimální počet uzlů, až do maximálního počtu uzlů. Automatické škálování clusteru počká, dokud ve fondu uzlů nebude potřeba nový uzel nebo dokud se uzel nebude bezpečně odstraňovat z aktuálního fondu uzlů. Další informace najdete v tématu Jak funguje vertikální snížení kapacity?
Osvědčené postupy a důležité informace
- Při implementaci zón dostupnosti s automatickým škálováním clusteru doporučujeme pro každou zónu použít jeden fond uzlů. Parametr můžete nastavit
--balance-similar-node-groupstak, abyTruese zachovala vyvážená distribuce uzlů napříč zónami pro vaše úlohy během operací vertikálního navýšení kapacity. Pokud tento přístup není implementovaný, operace vertikálního snížení kapacity můžou narušit rovnováhu uzlů napříč zónami. - Pro clustery s více než 400 uzly doporučujeme použít Azure CNI nebo Azure CNI Překrytí.
- Pokud chcete efektivně spouštět úlohy současně na fondech spotových i pevných uzlů, zvažte použití rozšíření priority. Tento přístup umožňuje plánovat pody na základě priority fondu uzlů.
- Při přiřazování požadavků na procesor a paměť na pody buďte opatrní. Automatické škálování clusteru vertikálně navyšuje kapacitu na základě čekajících podů, nikoli na uzlech s tlakem na procesor nebo paměť.
- U clusterů, které současně hostují jak dlouhotrvající úlohy, jako jsou webové aplikace, tak úlohy s krátkými nebo nárazovými úlohami, doporučujeme je oddělit do samostatných fondů uzlů s rozbalovacími moduly pravidel/vztahů nebo pomocí rozšíření PodDisruptionBudget, abyste zabránili zbytečným operacím vyprázdnění uzlů nebo vertikálnímu snížení kapacity. Zadání poznámek cluster-autoscaler.kubernetes.io/safe-to-evict: "false" ve specifikaci podu také zabrání vyřazení podů. Tuto poznámku používejte opatrně, protože může způsobit problémy s automatickým škálováním clusteru při vyprázdnění uzlu se spuštěným podem, který obsahuje tuto poznámku.
- Ve fondu uzlů s podporou automatického škálování můžete vertikálně snížit kapacitu uzlů odebráním úloh místo ručního snížení počtu uzlů. To může být problematické, pokud fond uzlů už má maximální kapacitu nebo pokud jsou na uzlech spuštěné aktivní úlohy, což může způsobit neočekávané chování automatického škálování clusteru.
- Uzly se neupupnou, pokud pody mají hodnotu PriorityClass nižší než -10. Priorita -10 je vyhrazená pro nadměrné zřízení podů. Další informace najdete v tématu Použití automatického škálování clusteru s prioritou podu a preemption.
- Nekombinujte další mechanismy automatického škálování uzlů, jako jsou automatické škálování škálovací sady virtuálních počítačů, s automatickým škálováním clusteru.
- Automatické škálování clusteru nemusí být možné vertikálně snížit kapacitu, pokud se pody nedají přesunout, například v následujících situacích:
- Přímo vytvořený pod, který není zálohovaný objektem kontroleru, jako je nasazení nebo sada replik.
- Rozpočet na přerušení podu (PDB), který je příliš omezující a neumožňuje, aby počet podů spadl podů nižší než určitá prahová hodnota.
- Pod používá selektory uzlů nebo spřažení, které nelze respektovat, pokud je naplánováno na jiném uzlu. Další informace najdete v tématu Jaké typy podů můžou zabránit odebrání uzlu automatického škálování clusteru?
Důležité
Neprovádávejte změny jednotlivých uzlů v rámci fondů uzlů s automatickým škálováním. Všechny uzly ve stejné skupině uzlů by měly mít jednotnou kapacitu, popisky, tainty a systémové pody spuštěné na nich.
- Automatické škálování clusteru neodpovídá za vynucování maximálního počtu uzlů ve fondu uzlů clusteru bez ohledu na aspekty plánování podů. Pokud některý objekt actor automatického škálování bez clusteru nastaví počet fondů uzlů na číslo nad rámec nakonfigurovaného maximálního počtu automatického škálování clusteru, automatické škálování clusteru automaticky neodebere uzly. Chování automatického škálování clusteru zůstává omezené na odebrání pouze uzlů, které nemají naplánované pody. Jediným účelem konfigurace maximálního počtu uzlů automatického škálování clusteru je vynutit horní limit pro operace vertikálního navýšení kapacity. Nemá žádný vliv na aspekty vertikálního snížení kapacity.
Profil automatického škálování clusteru
Profil automatického škálování clusteru je sada parametrů, které řídí chování automatického škálování clusteru. Profil automatického škálování clusteru můžete nakonfigurovat při vytváření clusteru nebo aktualizaci existujícího clusteru.
Optimalizace profilu automatického škálování clusteru
Nastavení profilu automatického škálování clusteru byste měli vyladit podle konkrétních scénářů úloh a zároveň zvážit kompromisy mezi výkonem a náklady. Tato část obsahuje příklady, které ukazují tyto kompromisy.
Je důležité si uvědomit, že nastavení profilu automatického škálování clusteru je v rámci clusteru a použito pro všechny fondy uzlů s povoleným automatickým škálováním. Jakékoli akce škálování, které probíhají v jednom fondu uzlů, můžou ovlivnit chování automatického škálování jiných fondů uzlů, což může vést k neočekávaným výsledkům. Ujistěte se, že pro všechny relevantní fondy uzlů používáte konzistentní a synchronizované konfigurace profilů, abyste měli jistotu, že získáte požadované výsledky.
Příklad 1: Optimalizace výkonu
Pro clustery, které zpracovávají podstatné a nárazové úlohy s primárním zaměřením na výkon, doporučujeme zvýšit scan-interval a snížit scale-down-utilization-thresholdúroveň . Tato nastavení pomáhají dávkovat více operací škálování do jednoho volání, optimalizovat dobu škálování a využití kvót pro čtení a zápis výpočetních prostředků. Pomáhá také zmírnit riziko rychlého snížení kapacity operací na nevyužitých uzlech a zvyšuje efektivitu plánování podů. Také zvýšení ok-total-unready-counta max-total-unready-percentage.
Pro clustery s pody démona doporučujeme nastavit , ignore-daemonsets-utilization aby truebylo efektivně ignorováno využití uzlů pomocí podů démona a minimalizuje zbytečné operace vertikálního snížení kapacity. Zobrazení profilu pro úlohy s nárazy
Příklad 2: Optimalizace nákladů
Pokud chcete profil optimalizovaný pro náklady, doporučujeme nastavit následující konfigurace parametrů:
- Zkracujte
scale-down-unneeded-timedobu, po kterou by měl být uzel nepotřebný, než bude mít nárok na snížení kapacity. - Snížit
scale-down-delay-after-add, což je doba čekání po přidání uzlu před zvážením vertikálního snížení kapacity. - Zvýšení
scale-down-utilization-threshold, což je prahová hodnota využití pro odebrání uzlů. - Zvýšit
max-empty-bulk-delete, což je maximální počet uzlů, které lze odstranit v jednom volání. - Nastavte
skip-nodes-with-local-storagena hodnotu false. - Zvýšit
ok-total-unready-countamax-total-unready-percentage.
Běžné problémy a doporučení pro zmírnění rizik
Zobrazení selhání škálování a vertikální navýšení kapacity neaktivovaných událostí prostřednictvím rozhraní příkazového řádku nebo portálu
Neaktivuje se operace vertikálního navýšení kapacity
| Běžné příčiny | Doporučení pro zmírnění rizik |
|---|---|
| Konflikty spřažení uzlu PersistentVolume, ke kterým může dojít při použití automatického škálování clusteru s více zónami dostupnosti nebo když se zóna podu nebo trvalého svazku liší od zóny uzlu. | Použijte jeden fond uzlů pro každou zónu dostupnosti a povolte --balance-similar-node-groups. Můžete také nastavit volumeBindingMode pole ve WaitForFirstConsumer specifikaci podu, aby se svazek neváže na uzel, dokud se nevytvořil pod pomocí svazku. |
| Spřažení taintů a tolerací / Konflikty spřažení uzlů | Vyhodnoťte tainty přiřazené k uzlům a zkontrolujte tolerance definované v podech. V případě potřeby upravte tainty a tolerance , abyste zajistili efektivní naplánování podů na uzlech. |
Selhání operace vertikálního navýšení kapacity
| Běžné příčiny | Doporučení pro zmírnění rizik |
|---|---|
| Vyčerpání IP adres v podsíti | Přidejte další podsíť ve stejné virtuální síti a přidejte do nové podsítě další fond uzlů. |
| Vyčerpání základní kvóty | Schválená kvóta jader byla vyčerpána. Požádejte o navýšení kvóty. Když dojde k několika neúspěšným pokusům o vertikální navýšení kapacity, automatické škálování clusteru přejde do konkrétní skupiny uzlů do exponenciálního stavu. |
| Maximální velikost fondu uzlů | Zvyšte maximální počet uzlů ve fondu uzlů nebo vytvořte nový fond uzlů. |
| Požadavky nebo volání překračující limit rychlosti | Viz chyby 429 Příliš mnoho požadavků. |
Selhání operace vertikálního snížení kapacity
| Běžné příčiny | Doporučení pro zmírnění rizik |
|---|---|
| Pod brání vyprázdnění uzlu / Nejde vyřadit pod | • Podívejte se , jaké typy podů mohou zabránit vertikálnímu snížení kapacity. • U podů používajících místní úložiště, například hostPath a emptyDir, nastavte příznak skip-nodes-with-local-storage profilu automatického škálování clusteru na falsehodnotu . • Ve specifikaci podu nastavte poznámku cluster-autoscaler.kubernetes.io/safe-to-evict na truehodnotu . • Zkontrolujte soubor PDB, protože může být omezující. |
| Minimální velikost fondu uzlů | Zmenšete minimální velikost fondu uzlů. |
| Požadavky nebo volání překračující limit rychlosti | Viz chyby 429 Příliš mnoho požadavků. |
| Zamknuté operace zápisu | Neprovádejte žádné změny plně spravované skupiny prostředků AKS (viz zásady podpory AKS). Odeberte nebo resetujte všechny zámky prostředků, které jste dříve použili pro skupinu prostředků. |
Další problémy
| Běžné příčiny | Doporučení pro zmírnění rizik |
|---|---|
| PriorityConfigMapNotMatchedGroup | Ujistěte se, že do konfiguračního souboru rozbalovacího modulu přidáte všechny skupiny uzlů, které vyžadují automatické škálování. |
Fond uzlů v backoffu
Fond uzlů v backoffu byl zaveden ve verzi 0.6.2 a způsobí, že automatické škálování clusteru se po selhání vyvrátí ze škálování fondu uzlů.
V závislosti na tom, jak dlouho dochází k selháním operací škálování, může trvat až 30 minut, než se pokusíte o další pokus. Stav obnovení fondu uzlů můžete resetovat zakázáním a opětovným povolením automatického škálování.

Azure Kubernetes Service