Spuštění n-vrstvé aplikace v několika oblastech služby Azure Stack Hub pro zajištění vysoké dostupnosti
Tato referenční architektura ukazuje sadu osvědčených postupů pro provozování n-vrstvé aplikace v několika oblastech služby Azure Stack Hub, aby bylo možné dosáhnout dostupnosti a robustní infrastruktury pro zotavení po havárii. V tomto dokumentu se Traffic Manager používá k dosažení vysoké dostupnosti, ale pokud Traffic Manager není ve vašem prostředí upřednostňovanou volbou, může se nahradit také dvojice vysoce dostupných nástrojů pro vyrovnávání zatížení.
Poznámka
Upozorňujeme, že Traffic Manager použitý v následující architektuře musí být nakonfigurovaný v Azure a koncové body použité ke konfiguraci profilu Traffic Manageru musí být veřejně směrovatelné IP adresy.
Architektura
Tato architektura je založená na architektuře zobrazené v n-vrstvé aplikaci s SQL Server.
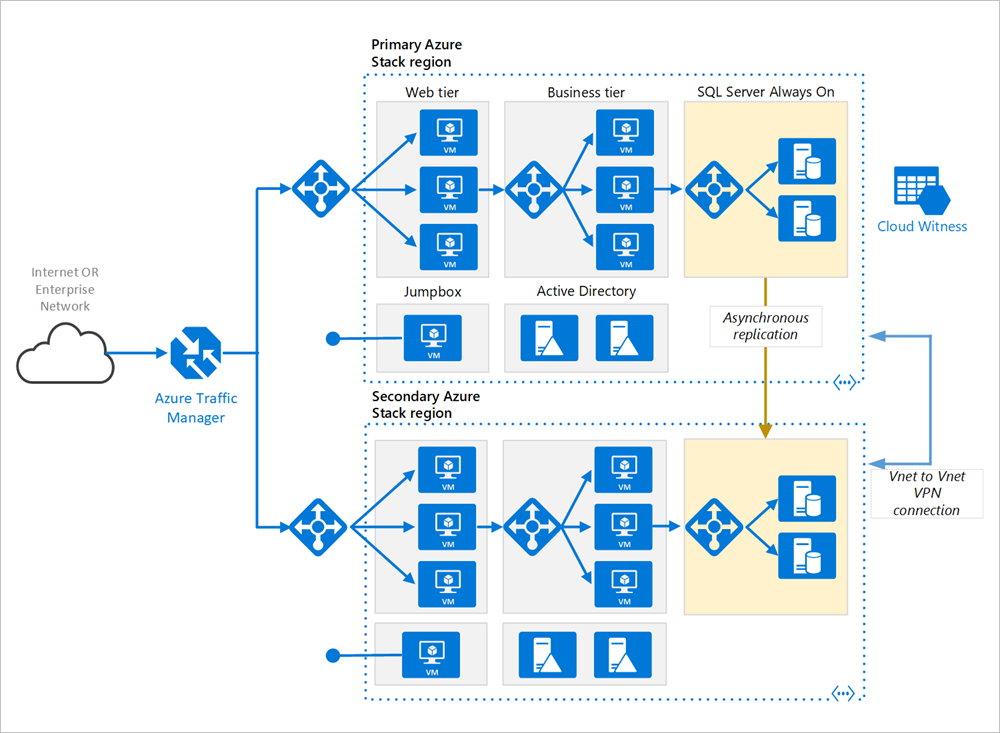
Primární a sekundární oblasti. Abyste dosáhli vysoké dostupnosti, použijte dvě oblasti. Jedna bude primární oblastí. Druhá oblast bude sloužit k převzetí služeb při selhání.
Azure Traffic Manager. Traffic Manager směruje příchozí žádosti do jedné z oblastí. V normálním provozu směruje žádosti do primární oblasti. Pokud se tato oblast stane nedostupnou, Traffic Manager zajistí převzetí služby při selhání sekundární oblastí. Další informace najdete v části konfigurace Traffic Manageru.
Skupiny prostředků. Vytvořte samostatné skupiny prostředků pro primární oblast, sekundární oblast. Díky tomu získáte flexibilitu spravovat každou oblast jako jedinou kolekci prostředků. Můžete například znovu nasadit jednu oblast, aniž byste museli zastavovat tu druhou. Skupiny prostředků propojte, abyste mohli spustit dotaz, který vypíše všechny prostředky pro danou aplikaci.
Virtuální sítě. Vytvořte samostatnou virtuální síť pro každou oblast. Ujistěte se, že se adresní prostory nepřekrývají.
SQL Server skupiny dostupnosti AlwaysOn. Pokud používáte SQL Server, doporučujeme vám pro vysokou dostupnost použít skupiny dostupnosti AlwaysOn pro SQL Server. Vytvořte jednu skupinu dostupnosti, která obsahuje instance SQL Serveru v obou oblastech.
Připojení VPN typu VNET-TO-VNET. Vzhledem k tomu, že partnerský vztah virtuálních sítí ještě není ve službě Azure Stack Hub dostupný, použijte k propojení těchto dvou virtuálních sítí připojení VPN mezi virtuálními sítěmi. Další informace najdete v tématu VNET-to-VNET ve službě Azure Stack Hub .
Doporučení
Architektura pro více oblastí může poskytnout vyšší dostupnost než nasazení do jedné oblasti. Pokud oblastní výpadek ovlivní primární oblast, můžete použít Traffic Manager a převzít služby při selhání sekundární oblastí. Tato architektura může také pomoct, když jednotlivý subsystém aplikace selže.
Existuje několik obecných přístupů k dosažení vysoké dostupnosti napříč oblastmi:
Aktivní/pasivní s aktivním pohotovostním režimem. provoz směruje do jedné oblasti, zatímco ta druhá čeká v aktivním pohotovostním režimu. Aktivní pohotovostní režim znamená, že virtuální počítače v sekundární oblasti jsou přidělené a běží za všech okolností.
Aktivní/pasivní se studeným pohotovostním režimem. provoz směruje do jedné oblasti, zatímco ta druhá čeká v pasivním pohotovostním režimu. Pasivní pohotovostní režim znamená, že virtuální počítače v sekundární oblasti nejsou přidělené, dokud není potřeba převzetí služeb při selhání. Tento přístup je méně nákladný, ale obecně bude trvat déle, než v případě selhání přejde do režimu online.
Aktivní/aktivní. obě oblasti jsou aktivní, žádosti se mezi ně rozdělují a vyrovnává se tak zatížení. Pokud bude jedna oblast nedostupná, vyřadí se z oběhu.
Tato referenční architektura se zaměřuje na aktivní/pasivní vysokou dostupnost s aktivním pohotovostním režimem a pro převzetí služeb při selhání používá Traffic Manager. Můžete nasadit malý počet virtuálních počítačů pro aktivní pohotovostní režim a pak podle potřeby škálovat na více instancí.
Konfigurace Traffic Manageru
Při konfiguraci Traffic Manageru zvažte následující body:
Směrování Traffic Manager podporuje několik algoritmů směrování. U scénáře popsaném v tomto článku použijte prioritní směrování (dříve nazývané směrování s převzetím služeb při selhání). S tímto nastavením odešle Traffic Manager všechny žádosti do primární oblasti (pokud se nestane nedostupnou). Od tohoto okamžiku služby při selhání automaticky převezme sekundární oblast. Viz Konfigurace metody směrování s převzetím služeb při selhání.
Sonda stavu. Traffic Manager používá ke sledování dostupnosti každé oblasti sondu protokolu HTTP (nebo HTTPS). Tato sonda kontroluje odpověď HTTP 200 pro zadanou cestu adresy URL. Osvědčeným postupem je vytvořit koncový bod, který bude hlásit celkový stav aplikace, a použít tento koncový bod pro sondu stavu. Jinak by sonda mohla ohlásit funkční koncový bod, přestože by důležité části aplikace ve skutečnosti selhávaly. Další informace najdete v tématu Model monitorování stavu koncových bodů.
Když Traffic Manager převezme služby při selhání, nastane časový úsek, ve kterém se klienti nebudou moct k aplikaci připojit. Dobu trvání ovlivňují následující faktory:
Sonda stavu musí odhalit, že primární oblast už není dostupná.
Servery DNS musí aktualizovat záznamy DNS v mezipaměti pro danou IP adresu, která je závislá na DNS hodnotě TTL (Time to Live). Výchozí hodnotou TTL je 300 sekund (5 minut), ale tuto hodnotu můžete při vytváření profilu Traffic Manageru upravit.
Podrobnosti najdete v tématu o monitorování Traffic Manageru.
Pokud Traffic Manager převezme služby při selhání, raději než provést navrácení služeb po obnovení automaticky, ho doporučujeme udělat ručně. Jinak může nastat situace, kdy aplikace přebíhá mezi různými oblastmi. Před navrácením služeb po obnovení si ověřte, že všechny subsystémy aplikace jsou v pořádku.
Nezapomeňte, že Traffic Manager ve výchozím nastavení provádí navrácení služeb po obnovení automaticky. Pokud tomu chcete zabránit, snižte po převzetí služeb při selhání ručně prioritu primární oblasti. Předpokládejme například, že priorita primární oblasti je 1 a priorita sekundární oblasti je 2. Po převzetí služeb při selhání nastavte prioritu primární oblasti na 3, abyste automatickému navrácení služeb po obnovení předešli. Až budete připraveni přepnout zpět, aktualizujte prioritu na 1.
Následující příkaz Azure CLI tuto prioritu aktualizuje:
az network traffic-manager endpoint update --resource-group <resource-group> --profile-name <profile>
--name <endpoint-name> --type externalEndpoints --priority 3
Další možností je dočasně zakázat koncový bod, dokud nebudete připravení navrátit služby po obnovení:
az network traffic-manager endpoint update --resource-group <resource-group> --profile-name <profile>
--name <endpoint-name> --type externalEndpoints --endpoint-status Disabled
V závislosti na příčině převzetí služeb při selhání možná budete muset v rámci oblasti znovu nasadit prostředky. Před navrácením služby po obnovení proveďte test provozní připravenosti. Test by měl ověřit například:
správnou konfiguraci virtuálních počítačů (veškerý software je nainstalovaný, služba IIS je spuštěná atd.)
stav subsystémů aplikace
funkční testování (například že databázová vrstva je dostupná z webové vrstvy)
Konfigurace skupin dostupnosti AlwaysOn pro SQL Server
Skupiny dostupnosti AlwaysOn pro SQL Server vyžadují před Windows Serverem 2016 řadič domény a všechny uzly ve skupině dostupnosti musí být ve stejné doméně Active Directory (AD).
Postup konfigurace skupiny dostupnosti:
Umístěte do každé oblasti alespoň dva řadiče domény.
Přiřaďte každému řadiči domény statickou IP adresu.
Vytvořte síť VPN pro umožnění komunikace mezi dvěma virtuálními sítěmi.
Pro každou virtuální síť přidejte IP adresy řadičů domény (z obou oblastí) do seznamu serverů DNS. Můžete k tomu použít následující příkaz rozhraní příkazového řádku. Další informace najdete v tématu Změna serverů DNS.
az network vnet update --resource-group <resource-group> --name <vnet-name> --dns-servers "10.0.0.4,10.0.0.6,172.16.0.4,172.16.0.6"Vytvořte clustering převzetí služeb při selhání ve Windows Serveru, který obsahuje instance SQL Serveru v obou oblastech.
Vytvořte skupinu dostupnosti AlwaysOn pro SQL Server, která obsahuje instance SQL Serveru jak v primárních, tak i v sekundárních oblastech. Postup najdete v tématu o rozšíření skupiny dostupnosti AlwaysOn na vzdálené datacentrum Azure (PowerShell).
Primární repliku dejte do primární oblasti.
Do primární oblasti dejte také jednu nebo více sekundárních replik. Nakonfigurujte je, aby s automatickým převzetím služeb při selhání používaly synchronní potvrzování.
Jednu nebo více sekundárních replik dejte do sekundární oblasti. Nakonfigurujte je, aby z důvodu zachování výkonu používaly asynchronní potvrzování. (Jinak všechny transakce T-SQL musí čekat na dobu odezvy ze sítě do sekundární oblasti.)
Poznámka
Repliky asynchronního potvrzení nepodporují automatické převzetí služeb při selhání.
Aspekty dostupnosti
U komplexní n-vrstvé aplikace nemusíte v sekundární oblasti replikovat celou aplikaci. Místo toho můžete replikovat pouze hlavní subsystém, který je potřeba k podpoře kontinuity podnikových procesů.
Traffic Manager je možným bodem selhání v systému. Pokud služba Traffic Manager selže, klienti nebudou mít během výpadku k vaší aplikaci přístup. Zkontrolujte smlouvu SLA pro Traffic Manager a rozhodněte se, zda použití samotného Traffic Manageru splňuje vaše podnikové požadavky na vysokou dostupnost. Pokud ne, zvažte přidání jiného řešení správy provozu jako navrácení služeb po obnovení. Pokud služba Azure Traffic Manager selže, změňte záznamy CNAME v DNS tak, aby odkazovaly na jinou službu pro správu provozu. (Tento krok je nutné provést ručně a vaše aplikace nebude dostupná, dokud se změny DNS nerozšíří.)
U clusteru SQL Serveru musíte zvážit dva scénáře převzetí služeb při selhání:
Všechny repliky databáze SQL Serveru v primární oblasti selžou. K tomu může dojít například během oblastního výpadku. V takovém případě musíte služby při selhání skupiny dostupnosti převzít ručně, přestože Traffic Manager služby při selhání převezme na front-endu automaticky. Postupujte podle pokynů v tématu o provedení vynuceného ručního převzetí služeb při selhání skupiny dostupnosti SQL Serveru, které popisuje, jak provést vynucené převzetí služeb při selhání použitím aplikací SQL Server Management Studio, Transact-SQL nebo prostředí PowerShell v SQL Serveru 2016.
Upozornění
Při použití vynuceného převzetí služeb při selhání existuje riziko ztráty dat. Jakmile se primární oblast vrátí do režimu online, pořiďte snímek databáze a použijte nástroj tablediff, abyste našli rozdíly.
Traffic Manager převezme služby při selhání sekundární oblastí, ale primární replika databáze SQL Serveru bude stále k dispozici. Front-endová vrstva může například selhat, aniž by ovlivnila virtuální počítače SQL Serveru. V takovém případě je internetový provoz směrován do sekundární oblasti a ta se stále může připojit k primární replice. Zvýší se však latence, protože připojení SQL Serveru cestují napříč oblastmi. V takovém případě byste měli následujícím způsobem provést ruční převzetí služeb při selhání:
Repliku databáze SQL Serveru v sekundární oblasti dočasně přepněte na synchronní potvrzování. Tím se zajistí, že během převzetí služeb při selhání nedojde ke ztrátě dat.
Převezměte služby při selhání touto replikou.
Když převezmete služby zpět primární oblastí, obnovte nastavení asynchronního potvrzování.
Aspekty správy
Při aktualizaci nasazení aktualizujte současně pouze jednu oblast, abyste snížili riziko globálního selhání z nesprávné konfigurace nebo chyby v aplikaci.
Otestujte odolnost systému vůči chybám. Zde jsou některé běžné scénáře selhání, které byste měli testovat:
Vypnutí instancí virtuálních počítačů
Přetížení prostředků – například procesorů nebo pamětí
Odpojení nebo zpoždění sítě
Násilné ukončení procesů
Vypršení certifikátů
Simulace hardwarových chyb
Vypnutí služby DNS na řadičích domény
Změřte dobu zotavení a ověřte, zda splňuje vaše obchodní požadavky. Otestujte také kombinace různých typů selhání.
Další kroky
- Další informace o modelech cloudu Azure najdete v tématu Vzory návrhu v cloudu.