Rychlý start: Vytvoření modelu klasifikace obrázků pomocí portálu Custom Vision
Tento rychlý start vysvětluje, jak pomocí webového portálu Custom Vision vytvořit model klasifikace obrázků. Jakmile vytvoříte model, můžete ho otestovat pomocí nových imagí a nakonec ho integrovat do vlastní aplikace pro rozpoznávání obrázků.
Požadavky
- Předplatné Azure. Můžete si vytvořit bezplatný účet.
- Sada obrázků pro trénování klasifikačního modelu Sadu ukázkových obrázků můžete použít na GitHubu. Nebo si můžete vybrat vlastní obrázky pomocí následujících tipů.
- Podporovaný webový prohlížeč.
Vytváření prostředků Custom Vision
Pokud chcete použít službu Custom Vision Service, budete muset v Azure vytvořit prostředky pro trénování a predikce služby Custom Vision. Uděláte to tak, že na webu Azure Portal vyplníte dialogové okno na stránce Vytvořit vlastní zpracování obrazu a vytvoříte prostředek trénování i predikce.
Vytvoření nového projektu
Přejděte na webovou stránku Služby Custom Vision a přihlaste se pomocí stejného účtu, který jste použili k přihlášení k webu Azure Portal.
Pokud chcete vytvořit první projekt, vyberte Nový projekt. Zobrazí se dialogové okno Vytvořit nový projekt .
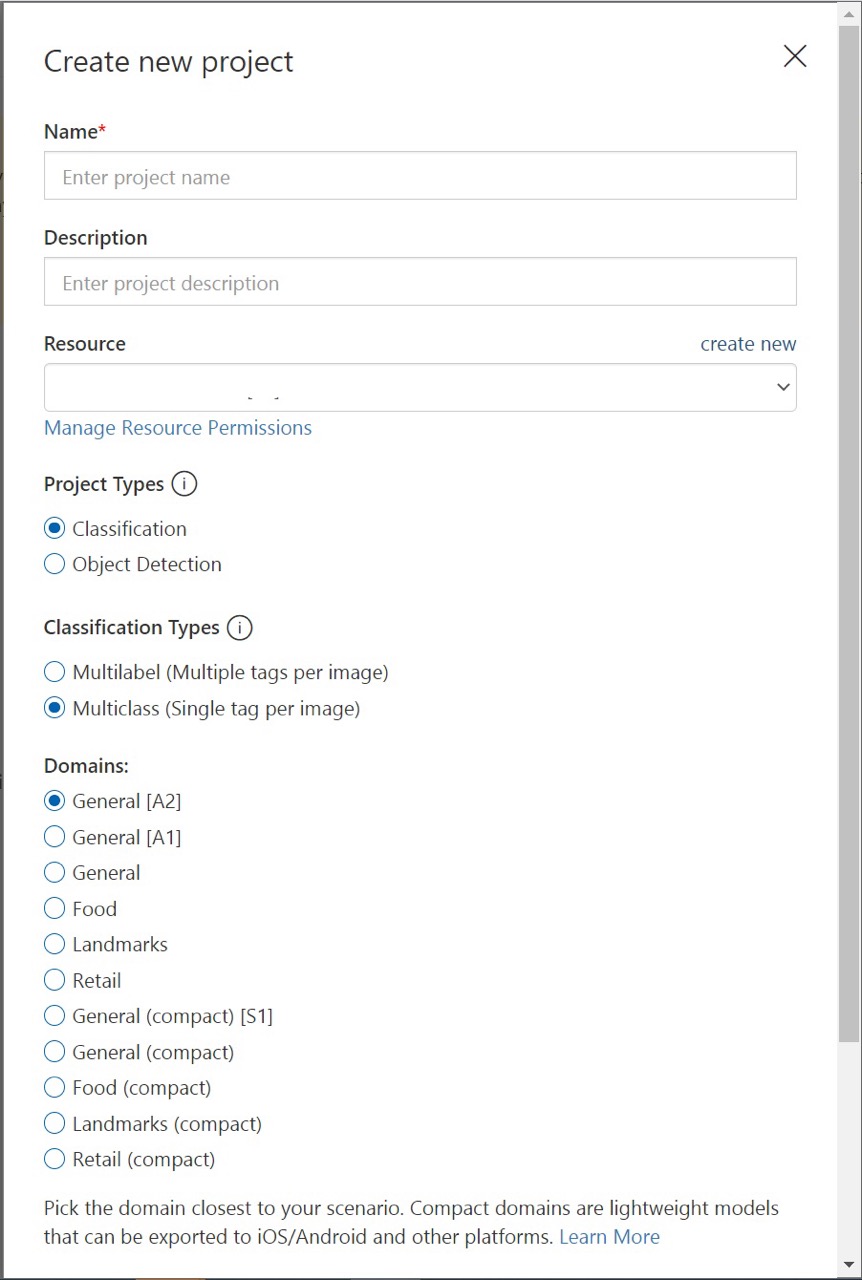
Zadejte název a popis projektu. Pak vyberte váš prostředek pro trénování služby Custom Vision. Pokud je váš přihlášený účet přidružený k účtu Azure, zobrazí se v rozevíracím seznamu Prostředek všechny vaše kompatibilní prostředky Azure.
Poznámka:
Pokud není k dispozici žádný prostředek, ověřte, že jste se přihlásili k customvision.ai pomocí stejného účtu, který jste použili k přihlášení k webu Azure Portal. Ověřte také, že jste na webu Custom Vision vybrali stejný adresář jako adresář na webu Azure Portal, kde se nacházejí vaše prostředky Služby Custom Vision. Na obou webech můžete v rozevírací nabídce účtu v pravém horním rohu obrazovky vybrat svůj adresář.
Vyberte klasifikaci v části Typy projektů. Potom v části Typy klasifikace zvolte v závislosti na vašem případu použití možnost Multilabel nebo Multiclass. Klasifikace multilabelu aplikuje na obrázek libovolný počet značek (nula nebo více), zatímco klasifikace s více třídami seřadí obrázky do jedné kategorie (každý odeslaný obrázek se seřadí do nejpravděpodobnější značky). Pokud chcete, můžete typ klasifikace později změnit.
Pak vyberte jednu z dostupných domén. Každá doména optimalizuje model pro konkrétní typy obrázků, jak je popsáno v následující tabulce. Pokud chcete, můžete doménu později změnit.
Doména Účel Generický Optimalizováno pro širokou škálu úloh klasifikace obrázků. Pokud žádná z ostatních domén není vhodná nebo si nejste jisti, kterou doménu zvolit, vyberte obecnou doménu. Jídlo Optimalizované pro fotografie jídel, jak byste je viděli v restauraci menu. Pokud chcete klasifikovat fotografie jednotlivých ovoce nebo zeleniny, použijte doménu Jídlo. Památek Optimalizované pro rozpoznatelné orientační body, přírodní i umělé. Tato doména funguje nejlépe, když je orientační bod jasně viditelný ve fotografii. Tato doména funguje i v případě, že je orientační bod mírně zablokovaný lidmi před ním. Retail Optimalizováno pro obrázky, které se nacházejí v nákupním katalogu nebo na webu nakupování. Pokud chcete klasifikovat vysoce přesné šaty, kalhoty a košile, použijte tuto doménu. Kompaktní domény Optimalizováno pro omezení klasifikace v reálném čase na mobilních zařízeních. Modely vygenerované kompaktními doménami je možné exportovat, aby se spouštěly místně. Nakonec vyberte Vytvořit projekt.
Volba trénovacích obrázků
Jako minimum doporučujeme použít alespoň 30 obrázků na značku v počáteční trénovací sadě. Po vytrénování modelu budete také chtít shromáždit několik dalších obrázků k otestování modelu.
K efektivnímu trénování modelu používejte obrázky s různými vizuálními možnostmi. Vyberte obrázky, které se liší podle:
- úhel kamery
- osvětlení
- pozadí
- vizuální styl
- individuální/seskupené předměty
- size
- type
Kromě toho se ujistěte, že všechny trénovací obrázky splňují následující kritéria:
- formát .jpg, .png, .bmp nebo .gif
- velikost maximálně 6 MB (4 MB pro obrázky předpovědí)
- ne méně než 256 pixelů na nejkratším okraji; Všechny obrázky kratší, než je tato možnost, se automaticky škáluje službou Custom Vision Service.
Nahrání a označení obrázků
Obrázky můžete nahrát a ručně označit, abyste mohli klasifikátor vytrénovat.
Pokud chcete přidat obrázky, vyberte Přidat obrázky a pak vyberte Procházet místní soubory. Výběrem možnosti Otevřít přejdete na označování. Výběr značky se použije pro celou skupinu obrázků, které nahrajete, takže je jednodušší nahrávat obrázky v samostatných skupinách podle použitých značek. Po nahrání můžete také změnit značky jednotlivých obrázků.
Pokud chcete vytvořit značku, zadejte text do pole Moje značky a stiskněte Enter. Pokud značka již existuje, zobrazí se v rozevírací nabídce. V projektu s více značkami můžete do obrázků přidat více než jednu značku, ale v projektu s více třídami můžete přidat jenom jednu. K dokončení nahrávání obrázků použijte tlačítko Nahrát [číslo] souborů .
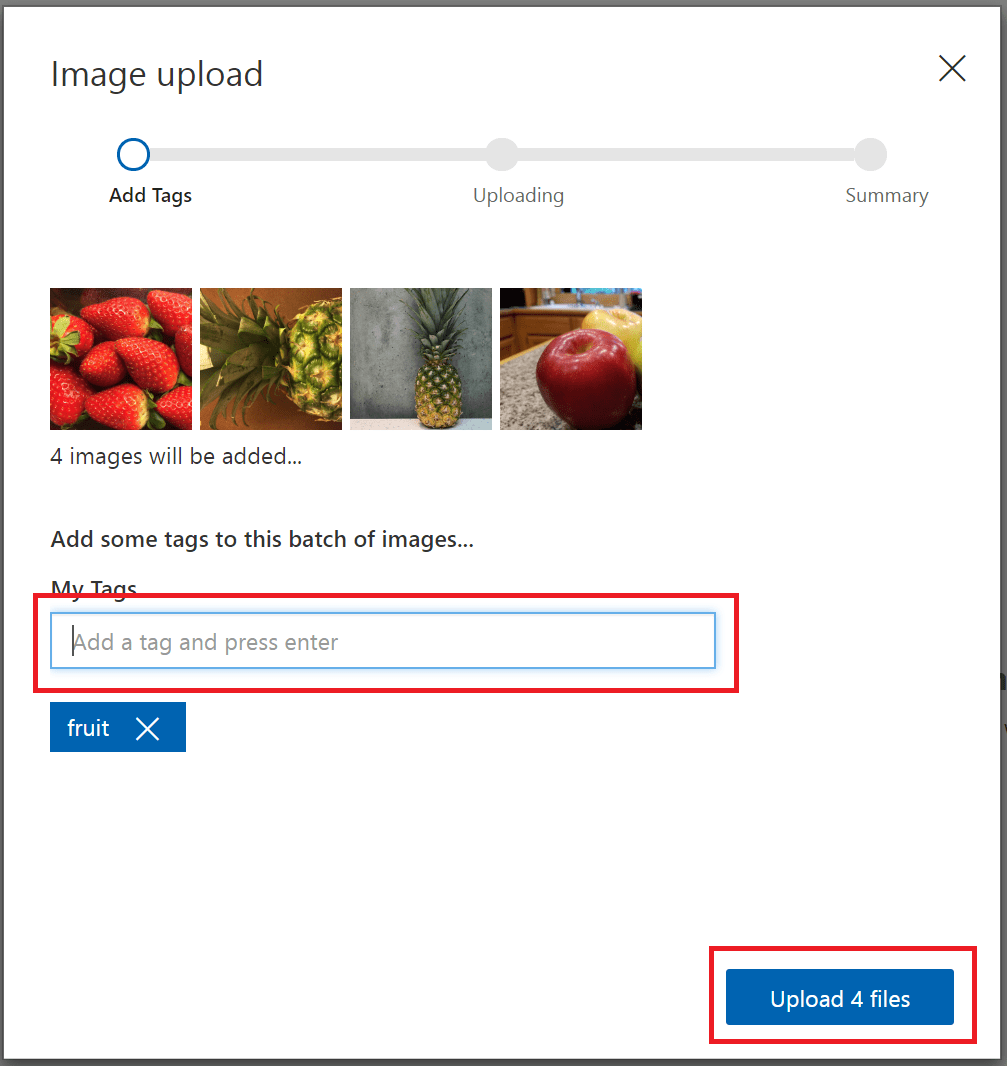
Po nahrání obrázků vyberte Hotovo .
Pokud chcete nahrát další sadu obrázků, vraťte se do horní části této části a opakujte kroky.
Trénování klasifikátoru
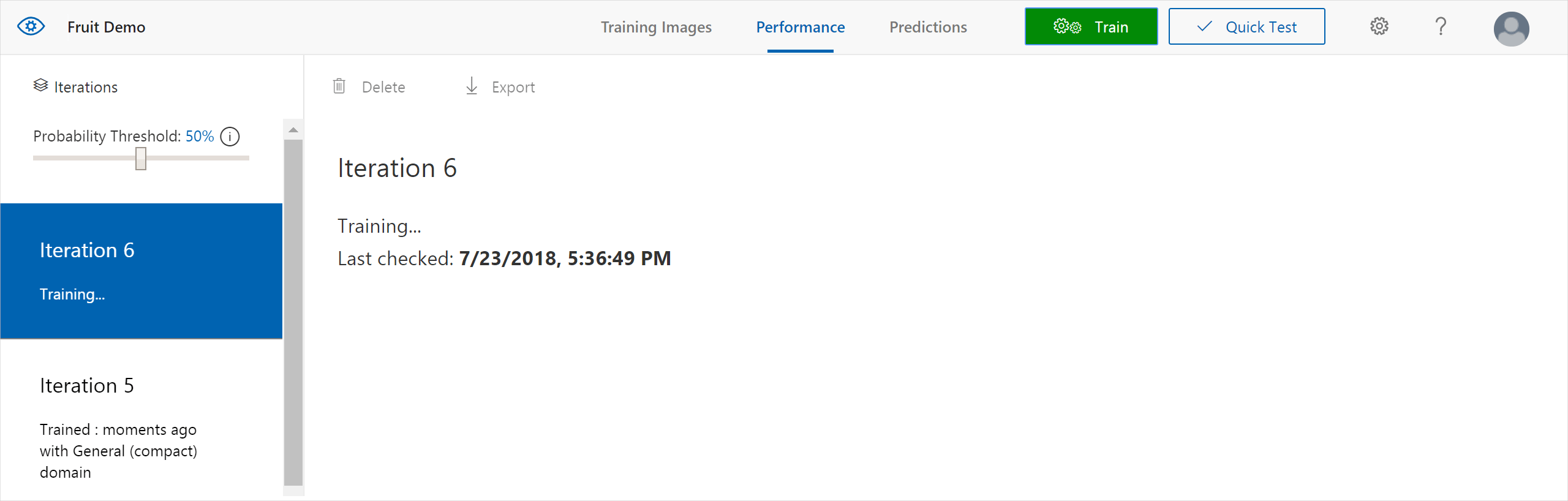
Pokud chcete vytrénovat klasifikátor, vyberte tlačítko Train (Trénovat ). Klasifikátor používá všechny aktuální obrázky k vytvoření modelu, který identifikuje vizuální vlastnosti každé značky. Tento proces může trvat několik minut.

Proces trénování by měl trvat jenom několik minut. Během této doby se informace o procesu trénování zobrazí na kartě Výkon .
Vyhodnocení klasifikátoru
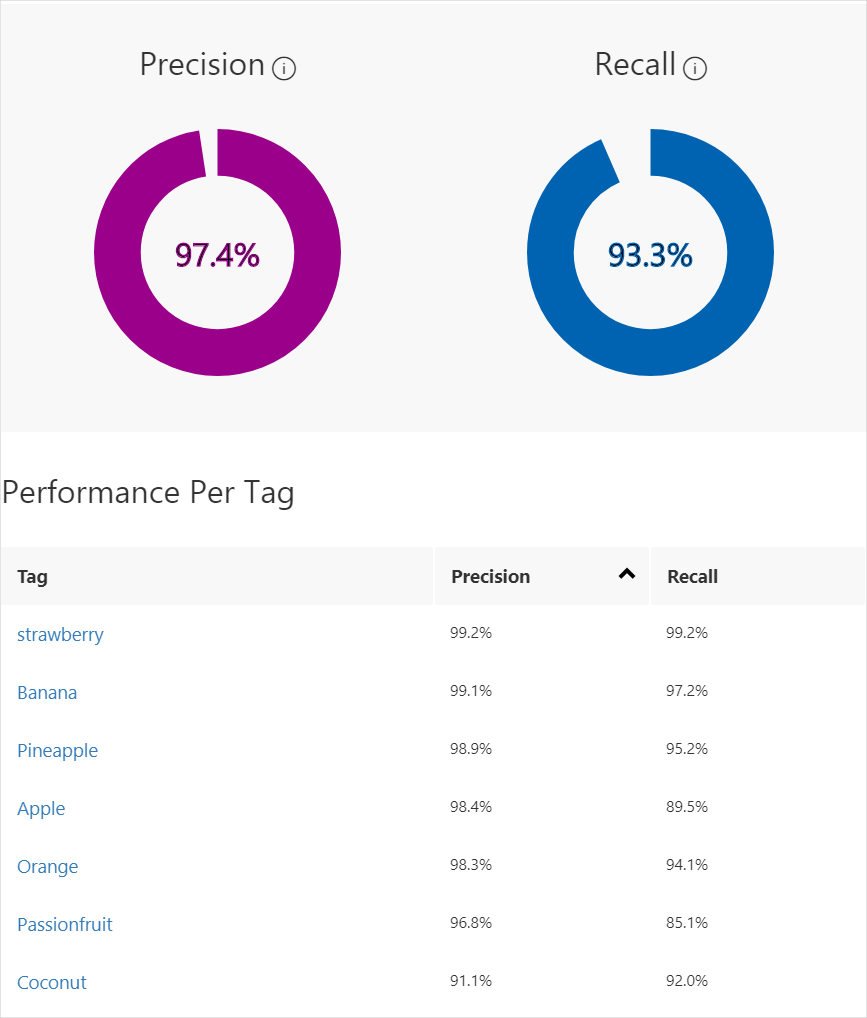
Po dokončení trénování se výkon modelu odhaduje a zobrazí. Služba Custom Vision používá obrázky, které jste odeslali k trénování k výpočtu přesnosti a úplnosti. Přesnost a úplnost jsou dvě různá měření účinnosti klasifikátoru:
- Přesnost označuje zlomek identifikovaných klasifikací, které byly správné. Pokud například model identifikoval 100 obrázků jako psy a 99 z nich byl ve skutečnosti psů, přesnost by byla 99 %.
- Úplnost označuje zlomek skutečných klasifikací, které byly správně identifikovány. Pokud by například existovalo 100 obrázků jablek a model identifikovaný jako jablka 80, bude úplnost 80 %.
Prahová hodnota pravděpodobnosti
Všimněte si posuvníku Prahová hodnota pravděpodobnosti v levém podokně na kartě Výkon . Jedná se o úroveň spolehlivosti, kterou musí mít předpověď, aby byla považována za správnou (pro účely výpočtu přesnosti a úplnosti).
Když interpretujete volání predikce s vysokou prahovou hodnotou pravděpodobnosti, mají tendenci vracet výsledky s vysokou přesností na úkor úplnosti – zjištěné klasifikace jsou správné, ale mnoho z nich zůstává nezjištěno. Prahová hodnota nízké pravděpodobnosti je opačná – většina skutečných klasifikací se detekuje, ale v této sadě je více falešně pozitivních výsledků. S ohledem na to byste měli nastavit prahovou hodnotu pravděpodobnosti podle konkrétních potřeb projektu. Později, když na straně klienta dostáváte výsledky predikce, měli byste použít stejnou prahovou hodnotu pravděpodobnosti, jakou jste použili zde.
Správa iterací trénování
Při každém trénování klasifikátoru vytvoříte novou iteraci s aktualizovanými metrikami výkonu. Všechny iterace můžete zobrazit v levém podokně na kartě Výkon . Najdete také tlačítko Odstranit , které můžete použít k odstranění iterace, pokud je zastaralé. Když iteraci odstraníte, odstraníte všechny obrázky, které jsou k ní jednoznačně přidružené.
Informace o tom, jak přistupovat k natrénovaným modelům prostřednictvím kódu programu, najdete v tématu Volání rozhraní API pro predikce.
Další krok
V tomto rychlém startu jste zjistili, jak vytvořit a vytrénovat model klasifikace obrázků pomocí webového portálu Custom Vision. V dalším kroku získáte další informace o iterativním procesu vylepšování modelu.