Ukládání do mezipaměti je běžná technika, jejímž cílem je zvýšit výkon a zlepšit škálovatelnost celého systému. Ukládá data do mezipaměti tím, že dočasně kopíruje často přístupná data do rychlého úložiště umístěného v blízkosti aplikace. Pokud je toto rychlé úložiště dat umístěno blíž k aplikaci než původní zdroj, může se díky ukládání do mezipaměti výrazně zkrátit doba odezvy pro klientské aplikace, protože obsluha dat probíhá rychleji.
Ukládání do mezipaměti je nejúčinnější, když instance klienta opakovaně čte stejná data, zejména pokud původní úložiště dat splňuje všechny následující podmínky:
- Zůstává relativně statické.
- Ve srovnání s rychlostí mezipaměti je pomalé.
- Dochází v něm k velkému množství kolizí.
- Je daleko, pokud latence sítě může přístup zpomalovat.
Ukládání do mezipaměti v distribuovaných aplikacích
Distribuované aplikace při ukládání dat do mezipaměti obvykle implementují jednu nebo obě z následujících strategií:
- Používají privátní mezipaměť, kde se data uchovávají místně v počítači, na kterém běží instance aplikace nebo služby.
- Používají sdílenou mezipaměť, která slouží jako běžný zdroj, ke kterému může přistupovat více procesů a počítačů.
V obou případech je možné ukládání do mezipaměti provádět na straně klienta i na straně serveru. Ukládání do mezipaměti na straně klienta probíhá v rámci procesu, který poskytuje uživatelské rozhraní pro systém, jako je webový prohlížeč nebo aplikace pracovní plochy. Ukládání do mezipaměti na straně serveru probíhá v rámci procesu, který poskytuje obchodní služby spuštěné vzdáleně.
Soukromé ukládání do mezipaměti
Základním typem mezipaměti je úložiště v paměti. Běží v adresním prostoru jednoho procesu a kód spuštění v tomto procesu k němu přistupuje přímo. Tento typ mezipaměti je rychlý pro přístup. Může také poskytovat efektivní prostředky pro ukládání skromných objemů statických dat. Velikost mezipaměti je obvykle omezena množstvím paměti dostupné na počítači, který je hostitelem procesu.
Pokud potřebujete ukládat do mezipaměti víc informací, než paměť fyzicky umožňuje, můžete data uložená v mezipaměti zapisovat do místního systému souborů. Tento proces bude pomalejší než přístup k datům uloženým v paměti, ale měl by být stále rychlejší a spolehlivější než načítání dat v síti.
Pokud pracujete s několika současně běžícími instancemi aplikace, která tento model používá, každá instance aplikace má vlastní nezávislou mezipaměť, která obsahuje její vlastní kopii dat.
Mezipaměť si můžete představit jako snímek původních data v určitém okamžiku v minulosti. Pokud tato data nejsou statická, je pravděpodobné, že různé instance aplikací obsahují různé verze dat v jejich mezipaměti. Stejný dotaz zpracovaný těmito instancemi proto může vrátit různé výsledky, jak je znázorněno na obrázku 1.
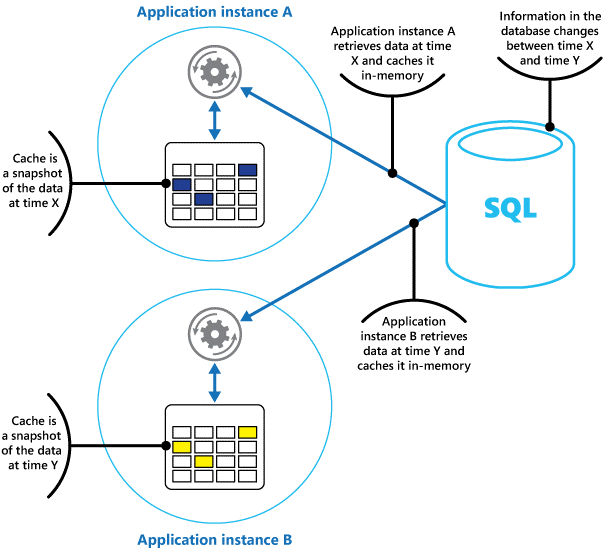
Obrázek 1: Použití mezipaměti v paměti v různých instancích aplikace
Ukládání do sdílené mezipaměti
Pokud používáte sdílenou mezipaměť, může to pomoct zmírnit obavy, že se data můžou v každé mezipaměti lišit, což může nastat při ukládání do mezipaměti v paměti. Ukládání do sdílené mezipaměti zajišťuje, že různé instance aplikace pracují se stejnými daty uloženými v mezipaměti. Nachází mezipaměť v samostatném umístění, které je obvykle hostované jako součást samostatné služby, jak je znázorněno na obrázku 2.
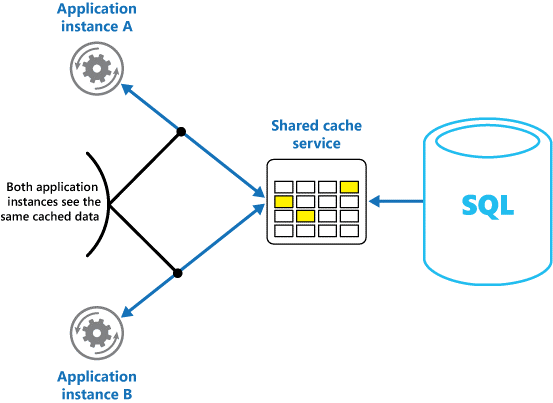
Obrázek 2: Použití sdílené mezipaměti
Důležitou výhodou přístupu ukládání do sdílené mezipaměti je škálovatelnost, kterou poskytuje. Mnoho služeb sdílené mezipaměti se implementuje pomocí clusteru serverů a používá software k transparentní distribuci dat napříč clusterem. Instance aplikace jednoduše odešle požadavek službě mezipaměti. Základní infrastruktura určuje umístění dat uložených v mezipaměti v clusteru. Mezipaměť je možné snadno škálovat přidáváním dalších serverů.
Přístup s ukládáním do sdílené mezipaměti má dvě hlavní nevýhody:
- Přístup k mezipaměti je pomalejší, protože se už neuchová místně pro každou instanci aplikace.
- Požadavek na implementaci samostatné služby mezipaměti může zvyšovat složitost řešení.
Aspekty využívání ukládání do mezipaměti
Následující části podrobněji popisují aspekty týkající se návrhu a používání mezipaměti.
Rozhodování o tom, kdy se data mají do mezipaměti ukládat
Ukládání do mezipaměti může výrazně zvýšit výkon a zlepšit škálovatelnost a dostupnost. Čím víc dat máte a čím vyšší je počet uživatelů, kteří k těmto datům potřebují mít přístup, tím větší jsou výhody ukládání do mezipaměti. Ukládání do mezipaměti snižuje latenci a kolize spojené se zpracováním velkých objemů souběžných požadavků v původním úložišti dat.
Databáze může například podporovat omezený počet souběžných připojení. Načítání dat ze sdílené mezipaměti namísto ze základní databáze ale klientské aplikaci poskytuje přístup k těmto datům i v případě, že je aktuálně dosažen maximální počet připojení k dispozici. Pokud navíc databáze přestane být k dispozici, může klientské aplikace pokračovat a používat data uložená v mezipaměti.
Zvažte, jestli do mezipaměti neukládat data, která se často čtou, ale upravují jen zřídka (například data s vyšším počtem operací čtení než operací zápisu). Nedoporučujeme ale používat mezipaměť jako autoritativní úložiště důležitých informací. Místo toho se ujistěte, že všechny změny, které si vaše aplikace nemůže dovolit ztratit, se vždy ukládají do trvalého úložiště dat. Pokud mezipaměť není dostupná, může vaše aplikace dál fungovat pomocí úložiště dat a neztratíte důležité informace.
Určení způsobu efektivního ukládání dat do mezipaměti
Předpokladem efektivního používání mezipaměti je určení nejvhodnějších dat pro ukládání do mezipaměti a jejich ukládání do mezipaměti ve správnou dobu. Data je možné přidat do mezipaměti na vyžádání při prvním načtení aplikací. Aplikace potřebuje načíst data pouze jednou z úložiště dat a že následný přístup může být splněn pomocí mezipaměti.
Mezipaměť může také být částečně nebo zcela naplněná daty už předem, obvykle při spuštění aplikace (přístup známý jako seeding). Ne vždy se ale doporučuje implementovat seeding pro velkou mezipaměť, protože tento přístup může znamenat náhlou velkou zátěž původního úložiště dat při spuštění aplikace.
Při rozhodování, jestli mezipaměť částečně nebo zcela naplnit předem, a při výběru dat, která se mají do mezipaměti uložit, často pomůže analýza schémat použití. Můžete například uložit mezipaměť se statickými daty profilu uživatele pro zákazníky, kteří aplikaci používají pravidelně (třeba každý den), ale ne pro zákazníky, kteří aplikaci používají jen jednou týdně.
Ukládání do mezipaměti obvykle funguje dobře s daty, která jsou neměnná nebo se mění zřídka. Mezi příklady patří referenční informace, například údaje o produktu a cenách v aplikaci elektronického obchodování, nebo sdílené statické prostředky, jejichž sestavování je nákladné. Některá nebo všechna tato data je možné načíst do mezipaměti při spuštění aplikace, aby se minimalizoval objem požadavků na prostředky a zvýšil se výkon. Můžete také chtít mít proces na pozadí, který pravidelně aktualizuje referenční data v mezipaměti, aby se zajistilo, že jsou aktuální. Nebo proces na pozadí může aktualizovat mezipaměť při změně referenčních dat.
Ukládání do mezipaměti je méně užitečné v případě dynamických dat, i když existují výjimky z tohoto pravidla (další informace najdete níž v tomto článku v části Ukládání vysoce dynamických dat do mezipaměti). Když se původní data pravidelně mění, informace uložené v mezipaměti se rychle zastaralou nebo režijní náklady na synchronizaci mezipaměti s původním úložištěm dat snižují efektivitu ukládání do mezipaměti.
Mezipaměť nemusí obsahovat úplná data entity. Pokud například datová položka představuje objekt s více hodnotami, například bankovní zákazník s názvem, adresou a zůstatkem účtu, můžou některé z těchto prvků zůstat statické, například jméno a adresa. Jiné prvky, například zůstatek na účtu, můžou být dynamičtější. V těchto situacích může být užitečné ukládat statické části dat do mezipaměti a načítat (nebo vypočítat) jenom zbývající informace, pokud je to potřeba.
Doporučujeme provést testování výkonu a analýzu využití, abyste zjistili, jestli je vhodné předem načíst mezipaměť nebo na vyžádání nebo jestli je vhodná kombinace obojího. Rozhodnutí by mělo být založeno na proměnlivosti dat a na schématu jejich používání. Využití mezipaměti a analýza výkonu jsou důležité v aplikacích, které narazí na velké zatížení a musí být vysoce škálovatelné. Například ve vysoce škálovatelných scénářích můžete mezipaměť nasadit, abyste snížili zatížení úložiště dat ve špičkách.
Použitím ukládání do mezipaměti můžete také předcházet opakování výpočtů v době, kdy aplikace běží. Pokud operace transformuje data nebo provádí složitý výpočet, můžete výsledky operace uložit do mezipaměti. Pokud je stejný výpočet vyžadován později, aplikace může jednoduše načíst výsledky z mezipaměti.
Aplikace může upravovat data uložená v mezipaměti. Doporučujeme však pracovat s mezipamětí jako s přechodným úložištěm dat, které může kdykoli zmizet. Neukládejte cenná data pouze do mezipaměti; ujistěte se, že informace uchováváte i v původním úložišti dat. To znamená, že se minimalizuje riziko ztráty dat, pokud by mezipaměť přestala být k dispozici.
Ukládání vysoce dynamických dat do mezipaměti
Při rychlé změně informací v trvalém úložišti dat může systém zatěžovat režii. Představme si třeba zařízení, které průběžně informuje o stavu nebo jiném ukazateli. Pokud aplikace rozhodne, že se tato data nemají ukládat do mezipaměti, protože by téměř vždy byla zastaralá, může se stejné hledisko uplatňovat při ukládání těchto informací do úložiště dat a načítání z něj. V průběhu času potřebného pro uložení a načtení těchto dat by mohlo dojít k jejich změně.
V podobné situaci zvažte výhody ukládání dynamických informací přímo do mezipaměti, a ne do trvalého úložiště dat. Pokud jsou data nekritická a nevyžadují auditování, nezáleží na tom, jestli dojde ke ztrátě občasné změny.
Správa konce platnosti dat v mezipaměti
Ve většině případů jsou data, která se nachází v mezipaměti, kopii dat, která se nachází v původním úložišti dat. Data v původním úložišti dat se po uložení do mezipaměti můžou změnit, takže data v mezipaměti jsou pak zastaralá. Mnoho systémů ukládání do mezipaměti umožňuje nakonfigurovat mezipaměť tak, aby ukončovala platnost dat a zkracovala dobu, během které mohou být data zastaralá.
Když vyprší platnost dat uložených v mezipaměti, odeberou se z mezipaměti a aplikace musí načíst data z původního úložiště dat (může nově načtené informace vložit zpět do mezipaměti). Při konfiguraci mezipaměti můžete nastavit výchozí zásady ukončení platnosti. V mnoha službách ukládání do mezipaměti můžete také určovat dobu platnosti pro jednotlivé objekty při jejich ukládání do mezipaměti prostřednictvím kódu programu. Některé mezipaměti umožňují určit dobu vypršení platnosti jako absolutní hodnotu nebo jako posuvnou hodnotu, která způsobí odebrání položky z mezipaměti, pokud není v zadaném čase přístupná. Toto nastavení potlačí veškeré zásady ukončení platnosti pro celou mezipaměť, ale vztahuje se jen na určené objekty.
Poznámka:
Dobu platnosti pro mezipaměť a pro objekty, které obsahuje, pečlivě zvažte. Pokud ji nastavíte příliš krátkou, platnost objektů vyprší příliš brzy a výhody používání mezipaměti se tím zmenší. Pokud nastavíte příliš dlouhou dobu platnosti, hrozí, že data budou zastaralá.
Mezipaměť se také může zaplnit, pokud v ní data můžou zůstat po dlouhou dobu. V takovém případě může u kterékoli žádosti o přidání nových položek do mezipaměti dojít k vynucení odebrání v rámci procesu nazývaného vyřazení. Služby mezipaměti obvykle vyřazují nejdéle nepoužitá data (zásada LRU), tuto zásadu ale obvykle můžete potlačit a zabránit vyřazení položek. Pokud však použijete tento přístup, riskujete zaplnění paměti, která je v mezipaměti k dispozici. Aplikace, která se pokusí o přidání položky do mezipaměti, selže s výjimkou.
V některých implementacích ukládání do mezipaměti můžou být k dispozici další zásady vyřazení. Existuje několik typů zásad vyřazení. Tady jsou některé z nich:
- Naposledy použité zásady (v očekávání, že se data nebudou znovu vyžadovat).
- Zásada fronty (nejstarší data se vyřadí jako první).
- Zásada explicitního odebrání na základě aktivované události (například úpravy dat).
Zrušení platnosti dat v mezipaměti na straně klienta
Data uložená v mezipaměti na straně klienta se obecně považují za data nechráněná službou, která poskytuje data klientovi. Služba nemůže přímo vynutit, aby klient přidal nebo odebral informace z mezipaměti na straně klienta.
To znamená, že pokud klient používá nevhodně nakonfigurovanou mezipaměť, může i nadále používat zastaralé informace. Pokud například zásady konce platnosti pro mezipaměť nejsou implementované správně, může klient používat zastaralé informace, které jsou místně uložené, i po změně příslušných informací v původním zdroji dat.
Pokud vytvoříte webovou aplikaci, která obsluhuje data přes připojení HTTP, můžete implicitně vynutit, aby webový klient (například prohlížeč nebo webový proxy server) načítá nejnovější informace. Můžete to udělat, pokud je prostředek aktualizován změnou v identifikátoru URI prostředku. Weboví klienti obvykle používají identifikátor URI prostředku jako klíč v mezipaměti na straně klienta, takže pokud se identifikátor URI změní, webový klient ignoruje všechny verze prostředku, které byly v mezipaměti uložení dřív, a načte místo toho novou verzi.
Správa souběžnosti v mezipaměti
Mezipaměti jsou často navržené tak, aby je sdílelo víc instancí aplikace. Každá instance aplikace může číst a upravovat data v mezipaměti. V důsledku toho se stejné problémy se souběžností, které vznikají u každého úložiště sdílených dat, týkají i mezipaměti. V situaci, kdy aplikace potřebuje upravit data uložená v mezipaměti, může být potřeba zajistit, aby aktualizace provedené jednou instancí aplikace nepřepsaly změny provedené jinou instancí.
V závislosti na charakteru dat a pravděpodobnosti kolizí můžete využít jeden ze dvou přístupů týkající se souběžnosti:
- Optimistický. Bezprostředně před aktualizací dat aplikace zkontroluje, jestli se data v mezipaměti od načtení změnila. Pokud jsou data i nadále stejná, je možné změnu provést. V opačném případě musí aplikace rozhodnout, jestli data aktualizuje. (Obchodní logika, která toto rozhodnutí řídí, bude specifická pro aplikaci.) Tento přístup je vhodný pro situace, kdy jsou aktualizace občasné nebo kdy pravděpodobně nedojde ke kolizím.
- Pesimistický. Když aplikace načte data, uzamkne je v mezipaměti, aby zabránila jiné instanci v jejich změně. Tento proces zajišťuje, že ke kolizím nedojde, ale mohou také blokovat jiné instance, které potřebují zpracovávat stejná data. Pesimistická souběžnost může ovlivňovat škálovatelnost řešení a doporučuje se jen pro krátkodobé operace. Tento přístup může být vhodný v situacích, kdy je pravděpodobnost kolizí vyšší, zejména pokud aplikace aktualizuje v mezipaměti několik položek a musí zajistit konzistentní provedení těchto změn.
Implementace vysoké dostupnosti a škálovatelnosti a zvýšení výkonu
Nepoužívejte mezipaměť jako primární úložiště dat; tuto roli má původní úložiště dat, ze kterého se mezipaměť naplní. Původní úložiště dat odpovídá za trvalost dat.
Dbejte na to, abyste do řešení nezaváděli kritické závislosti na dostupnosti služby sdílené mezipaměti. Aplikace by měla i nadále fungovat, pokud služba poskytující sdílenou mezipaměť nebude k dispozici. Aplikace by neměla při čekání na obnovení služby mezipaměti přestat reagovat nebo selhat.
Aplikace proto musí být připravená na zjišťování dostupnosti služby mezipaměti a v případě, že mezipaměť není k dispozici, se musí vrátit k používání původního úložiště dat. Pro tento scénář je užitečný model Circuit-Breaker (jistič). Službu, která poskytuje mezipaměť, lze obnovit, a jakmile je znovu k dispozici, je možné mezipaměť znovu naplňovat daty čtenými z původního úložiště dat podle strategie, jako je například model s doplňováním mezipaměti.
Pokud se však aplikace vrátí do původního úložiště dat, když je mezipaměť dočasně nedostupná, může být ovlivněna škálovatelnost systému. Zatímco probíhá zotavování úložiště dat, může dojít k zaplavení původního úložiště dat požadavky na data, a v důsledku toho může docházet k vypršení časového limitu a k selhání připojení.
Společně se sdílenou mezipamětí, ke které přistupují všechny instance aplikace, zvažte implementaci místní soukromé mezipaměti v každé instanci aplikace. Když aplikace načte položku, může ji nejprve zkontrolovat v příslušné místní mezipaměti, pak ve sdílené mezipaměti, a pak v původním úložišti dat. Místní mezipaměť je možné naplnit s použitím dat buď ve sdílené mezipaměti, nebo v databázi, pokud sdílená mezipaměť není k dispozici.
Tento přístup vyžaduje pečlivou konfiguraci, aby nedocházelo k přílišnému zastarávání místní mezipaměti vzhledem ke sdílené mezipaměti. Místní mezipaměť však funguje jako vyrovnávací paměť, pokud sdílená mezipaměť není k dispozici. Tato struktura je znázorněna na obrázku 3.
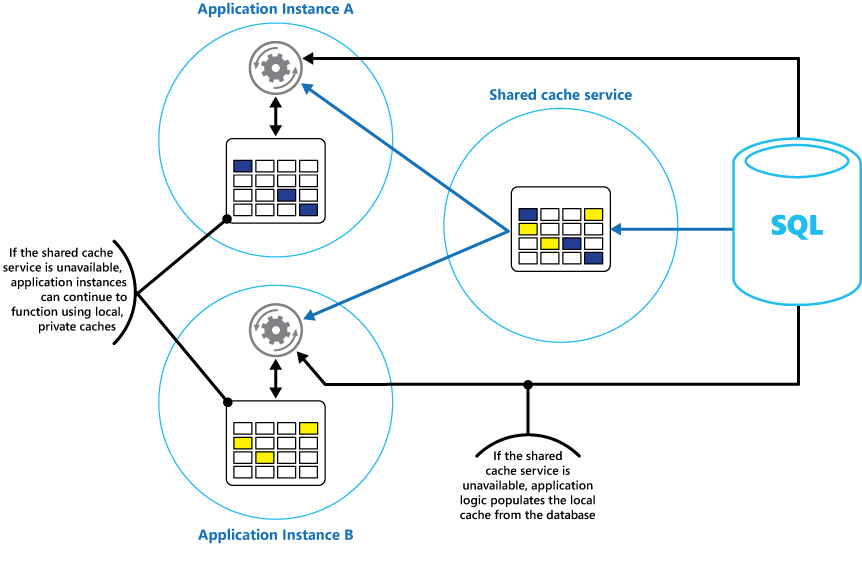
Obrázek 3: Použití místní privátní mezipaměti se sdílenou mezipamětí
Některé služby mezipaměti poskytují jako podporu velkých mezipamětí, ve kterých jsou uložena relativně dlouhodobá data, možnost vysoké dostupnosti, která implementuje automatické převzetí služeb při selhání, pokud mezipaměť přestane být k dispozici. Tento přístup obvykle zahrnuje replikaci dat uložených v mezipaměti na primárním serveru mezipaměti na sekundární server mezipaměti a přepnutí na sekundární server, pokud dojde k selhání primárního serveru nebo k přerušení připojení.
Pokud se do mezipaměti na primárním serveru zapisují data, může replikace na sekundární server probíhat asynchronně, aby se snížila latence související se zápisem do více umístění. Tento přístup vede ke ztrátě některých informací uložených v mezipaměti, pokud dojde k selhání, ale poměr těchto dat by měl být malý v porovnání s celkovou velikostí mezipaměti.
Pokud je sdílená mezipaměť velká, může být užitečné při rozdělit data uložená v mezipaměti do oddílů mezi uzly, aby se snížila pravděpodobnost kolizí a zlepšila se škálovatelnost. Mnoho sdílených mezipamětí podporuje možnost dynamického přidávání (a odebírání) uzlů a obnovování rovnováhy dat mezi oddíly. Tento přístup může zahrnovat clustering, v rámci kterého je kolekce uzlů prezentována klientským aplikacím jako jediná nedělená mezipaměť. Interně jsou však data rozptýlena mezi uzly podle předem definované distribuční strategie rovnoměrného rozkládání zátěže. Další informace o možnýchstrategiích
Clustering může také zvýšit dostupnost mezipaměti. Pokud selže jeden uzel, je zbytek mezipaměti i nadále přístupný. Clustering se často používá v kombinaci s replikací a převzetím služeb při selhání. Každý uzel je možné replikovat a repliku lze rychle převést do stavu online, pokud uzel selže.
Je pravděpodobné, že mnoho operací čtení a zápisu se bude týkat jednoduchých datových hodnot nebo objektů. V některých případech ale může být třeba rychle ukládat nebo načítat velké objemy dat. Naplnění mezipaměti může například zahrnovat zápis stovek nebo tisíců položek do mezipaměti. Je také možné, že aplikace bude muset v rámci téhož požadavku načítat z mezipaměti velké množství souvisejících položek.
Mnohé z velkoobjemových mezipamětí poskytují pro tyto účely dávkové operace. Díky tomu může klientská aplikace zabalit velký objem položek do jednoho požadavku a snížit režii spojenou se zpracováním velkého množství malých požadavků.
Ukládání do mezipaměti a konečná konzistence
Aby model s doplňováním mezipaměti fungoval, musí mít instance aplikace, která mezipaměť naplňuje, přístup k nejnovější a současně konzistentní verzi dat. To však nemusí být případ systému, který implementuje konečnou konzistenci (například replikované úložiště dat).
Jedna instance může upravit datovou položku a zneplatnit její verzi uloženou v mezipaměti. Jiná instance aplikace se může pokusit o čtení této položky z mezipaměti, což vede k neúspěšnému přístupu do mezipaměti, takže data načte z úložiště dat a přidá je do mezipaměti. Pokud však úložiště dat nebylo plně synchronizováno s ostatními replikami, instance aplikace by mohla číst a naplnit mezipaměť starou hodnotou.
Další informace o zajištění konzistence dat najdete v článku Úvod do konzistence dat.
Ochrana dat uložených v mezipaměti
Bez ohledu na službu mezipaměti, kterou používáte, zvažte, jak data, která se nachází v mezipaměti, chránit před neoprávněným přístupem. Zásadní jsou dva aspekty:
- Utajení dat v mezipaměti.
- Utajení dat při přenosu mezi mezipamětí a aplikací, která mezipaměť využívá.
K ochraně dat v mezipaměti může služba mezipaměti implementovat mechanismus ověřování, který vyžaduje, aby aplikace určily následující údaje:
- Které identity můžou přistupovat k datům v mezipaměti.
- Které operace (čtení a zápis) smějí tyto identity provádět.
Pokud chcete snížit režii spojenou s čtením a zápisem dat, může tato identita po udělení přístupu k zápisu nebo čtení do mezipaměti používat všechna data v mezipaměti.
Pokud potřebujete omezit přístup k podmnožinám dat uložených v mezipaměti, můžete provést jednu z těchto akcí:
- Rozdělit mezipaměť na oddíly (s použitím různých serverů mezipaměti) a udělit identitám přístup jen k oddílům, jejichž používání mají mít povoleno.
- Zašifrovat data v každé podmnožině s použitím různých klíčů a poskytnout šifrovací klíče jen identitám, které mají mít povolen přístup k příslušné podmnožině. Klientská aplikace může i nadále načítat všechna data uložená v mezipaměti, ale dešifrovat bude moct jen data, pro která má klíče.
Je také třeba, abyste chránili data přenášená do mezipaměti a z ní. Praktická realizace závisí na funkcích zabezpečení poskytovaných síťovou infrastrukturou, kterou klientské aplikace používají pro připojení k mezipaměti. Pokud je mezipaměť implementovaná s použitím místního serveru v rámci stejné organizace, která je hostitelem klientských aplikací, nemusí samotná izolace sítě vyžadovat další kroky. Pokud je mezipaměť ve vzdáleném umístění a vyžaduje připojení TCP nebo HTTP přes veřejnou síť (třeba internet), zvažte implementaci zabezpečení SSL.
Důležité informace o implementaci ukládání do mezipaměti v Azure
Azure Cache for Redis je implementace opensourcové mezipaměti Redis , která běží jako služba v datacentru Azure. Poskytuje službu ukládání do mezipaměti, která je přístupná z každé aplikace Azure bez ohledu na to, jestli je příslušná aplikace implementovaná jako cloudová služba či web nebo jestli běží v rámci virtuálního počítače Azure. Mezipaměti můžou být sdílené klientskými aplikacemi, které mají příslušný přístupový klíč.
Azure Cache for Redis je vysoce výkonné řešení ukládání do mezipaměti, které poskytuje dostupnost, škálovatelnost a zabezpečení. Obvykle běží jako služba rozložená mezi jeden nebo více vyhrazených počítačů. Pokouší se ukládat do paměti co nejvíce informací, aby byl zajištěn rychlý přístup. Tato architektura je navržena tak, aby díky omezování nutnosti provádět pomalé vstupně-výstupní operace dosahovala nízkou latenci a vysokou propustnost.
Azure Cache for Redis je kompatibilní s mnoha různými rozhraními API, která používají klientské aplikace. Pokud už máte existující aplikace, které už používají Azure Cache for Redis spuštěné místně, poskytuje Azure Cache for Redis rychlý způsob migrace pro ukládání do mezipaměti v cloudu.
Funkce Redisu
Redis není jen jednoduchý server mezipaměti. Poskytuje distribuovanou databázi v paměti s rozsáhlou sadou příkazů, která podporuje mnoho běžných scénářů. Tyto možnosti jsou popsány dále v tomto dokumentu v části Použití mezipaměti Redis. Tento oddíl shrnuje některé klíčové funkce, které Redis poskytuje.
Redis jako databáze v paměti
Redis podporuje operace čtení i zápisu. V mezipaměti Redis je možné chránit zápisy před selháním systému buď jejich pravidelným ukládáním do místního souboru snímku, nebo ukládáním do souboru protokolu, do kterého se data jen přidávají na konec. Tato situace není případem mnoha mezipamětí, které by se měly považovat za přechodná úložiště dat.
Všechny zápisy jsou asynchronní a nezablokují klientům čtení a zápis dat. Když se Redis spustí, načte data ze souboru snímku nebo protokolu a použije je k vytvoření mezipaměti umístěné v paměti. Další informace najdete na stránce věnované trvalosti Redisu na webu Redis.
Poznámka:
Redis nezaručuje, že se všechny zápisy uloží, pokud dojde ke katastrofickému selhání, ale v nejhorším případě může dojít ke ztrátě dat jen pár sekund. Mějte na paměti, že mezipaměť není určená k tomu, aby fungovala jako autoritativní zdroj dat, a je zodpovědností aplikací, které mezipaměť používají, aby se zajistilo úspěšné uložení důležitých dat do příslušného úložiště dat. Další informace najdete v modelu doplňování mezipaměti.
Datové typy Redis
Redis je úložiště dvojic klíč-hodnota, kde hodnoty mohou obsahovat jednoduché typy nebo komplexní datové struktury, například hodnoty hash, seznamy a množiny. U těchto datových typů je podporována sada atomických operací. Klíče můžou být trvalé nebo můžou mít určenou omezenou životnost, po jejímž uplynutí se klíč a jeho odpovídající hodnota automaticky odeberou z mezipaměti. Další informace o hodnotách a klíčích Redis najdete na stránce s úvodem do datových typů a abstrakcí Redis na webu Redis.
Replikace a clustering Redisu
Redis podporuje primární/podřízenou replikaci, která pomáhá zajistit dostupnost a udržovat propustnost. Operace zápisu do primárního uzlu Redis se replikují do jednoho nebo více podřízených uzlů. Operace čtení mohou obsluhovat primární nebo některé podřízené.
Pokud máte síťový oddíl, podřízené můžou dál obsluhovat data a pak transparentně znovu synchronizovat s primárním serverem při opětovném publikování připojení. Další podrobnosti najdete na stránce věnované replikaci na webu Redis.
Redis také nabízí clustering, který umožňuje transparentně dělit data do horizontálních oddílů mezi servery a rozkládat zatížení. Tato funkce zvyšuje škálovatelnost, protože lze přidávat nové servery Redis a se zvětšováním mezipaměti se může měnit rozložení dat mezi oddíly.
Každý server v clusteru je navíc možné replikovat pomocí primární/podřízené replikace. Tím se zajistí dostupnosti mezi všechny uzly v clusteru. Další informace o clusteringu a horizontálním dělení najdete na stránce s kurzem ke clusteru Redis na webu Redis.
Využití paměti Redis
Mezipaměť Redis má konečnou velikost závislou na prostředcích, které jsou k dispozici na hostitelském počítači. Při konfigurování serveru Redis můžete zadat maximální velikost paměti, kterou smí používat. Klíč v mezipaměti Redis můžete také nakonfigurovat tak, aby měl čas vypršení platnosti, po kterém se automaticky odebere z mezipaměti. Tato funkce může pomoci bránit tomu, aby se mezipaměť umístěná v paměti zaplnila starými nebo zastaralými daty.
Když se paměť plní, Redis může automaticky vyřazovat klíče a jejich hodnoty podle mnoha zásad. Výchozí hodnota je LRU (nejméně nedávno použitá), ale můžete také vybrat jiné zásady, jako je vyřazování klíčů náhodně nebo úplné vypnutí vyřazení (v takovém případě se pokusy o přidání položek do mezipaměti nezdaří, pokud je zaplněná). Další informace najdete na stránce věnované použití Redisu jako mezipaměti se zásadou LRU (nejdéle nepoužitá data).
Transakce a dávky Redis
Redis umožňuje klientské aplikaci odeslat posloupnost operací, které čtou a zapisují data v mezipaměti, jako jednu atomickou transakci. Je zaručené sekvenční spuštění všech příkazů v transakci a nedostanou se mezi ně žádné příkazy vydané ostatními souběžně spuštěnými klienty.
Nejedná se však o skutečné transakce, protože relační databáze by je prováděla. Zpracování transakcí se skládá ze dvou fází – první spočítá v zařazení příkazů do fronty a druhá v jejich spuštění. Ve fázi zařazení příkazů do fronty jsou příkazy, které tvoří transakci, odeslány klientem. Pokud v tomto okamžiku dojde k nějaké chyby (jako je například chyba syntaxe nebo nesprávný počet parametrů), Redis odmítne zpracovat celou transakce a zahodí ji.
Ve fázi spuštění Redis provede jednotlivé příkazy z fronty v příslušném pořadí. Pokud příkaz v této fázi selže, Redis pokračuje dalším příkazem ve frontě a nevrátí zpět účinky všech příkazů, které už byly spuštěny. Ta zjednodušená forma transakcí pomáhá udržovat výkon a vyhnout se problémům s výkonem, které jsou způsobené kolizemi.
Jako pomůcku pro zachování konzistence Redis implementuje formu optimistického zamykání. Podrobné informace o transakcích a zamykání s využitím Redisu najdete na stránce věnované transakcím na webu Redis.
Redis také podporuje netransakční dávkování požadavků. Protokol Redis, který klienti používají k odesílání příkazů do serveru Redis, umožňuje klientovi umožní odeslat posloupnost operací v rámci jednoho požadavku. To napomáhá snížení fragmentace paketů v síti. Když se zpracovává dávka, provedou se všechny příkazy. Pokud jsou některé z těchto příkazů poškozené, budou odmítnuty (což se nestane s transakcí), ale zbývající příkazy budou provedeny. Neexistuje ani žádná záruka na pořadí, ve kterém se budou příkazy v dávce zpracovávat.
Zabezpečení Redisu
Redis se zaměřuje výhradně na poskytování rychlého přístupu k datům a je určený ke spouštění uvnitř důvěryhodného prostředí, ke kterému mají přístup jenom důvěryhodní klienti. Redis podporuje model omezeného zabezpečení na základě ověření hesla. (Ověřování je možné úplně odebrat, i když to nedoporučujeme.)
Všichni ověření klienti sdílejí stejné globální heslo a mají přístup ke stejným prostředkům. Pokud potřebujete komplexnější zabezpečení přihlášení, musíte implementovat vlastní vrstvu zabezpečení před server Redis. Přes tuto dodatečnou vrstvu by měly procházet všechny klientské požadavky. Redis by neměl být přímo vystavený nedůvěryhodným nebo neověřeným klientům.
Přístup k příkazům můžete omezit tak, že je zakážete nebo přejmenujete (a nové názvy poskytnete jenom oprávněným klientům).
Redis přímo nepodporuje žádnou formu šifrování dat, takže veškeré kódování musí provádět klientské aplikace. Redis navíc neposkytuje žádnou formu zabezpečení přenosu. Pokud potřebujete chránit data při průchodu sítí, doporučujeme implementovat SSL proxy.
Další informace najdete na stránce věnované zabezpečení Redisu na webu Redis.
Poznámka:
Azure Cache for Redis poskytuje vlastní vrstvu zabezpečení, pomocí které se klienti připojují. Základní servery Redis nejsou přístupné veřejné síti.
Azure Redis Cache
Azure Cache for Redis poskytuje přístup k serverům Redis hostovaným v datacentru Azure. Slouží jako adaptační vrstva, která poskytuje řízení přístupu a zabezpečení. Ke zřízení mezipaměti můžete využít Azure Portal.
Tento portál poskytuje řadu předdefinovaných konfigurací. Rozsah je od 53 GB mezipaměti spuštěné jako vyhrazená služba, která podporuje komunikaci SSL (pro ochranu osobních údajů) a replikaci hlavní/podřízené s 99,9% dostupností až 99,9% dostupností až do 250 MB mezipaměti bez replikace (bez záruk dostupnosti) běžící na sdíleném hardwaru.
Pomocí webu Azure Portal můžete také nakonfigurovat zásady vyřazení mezipaměti a řídit přístupu k mezipaměti přidáváním uživatelů do zadaných rolí. Tyto role definují operace, které mohou provést členové, a zahrnují role Vlastník, Přispěvatel a Čtenář. Například členové role Vlastník mají plnou kontrolu nad mezipamětí (včetně zabezpečení) a jejím obsahem, členové role Přispěvatel mohou v mezipaměti číst a zapisovat informace a členové role Čtenář mohou z mezipaměti jenom načítat data.
Většina úkolů správy se provádí prostřednictvím webu Azure Portal. Z tohoto důvodu není k dispozici mnoho příkazů pro správu dostupných ve standardní verzi Redis, včetně možnosti programově upravit konfiguraci, vypnout server Redis, nakonfigurovat další podřízené nebo vynuceně ukládat data na disk.
Web Azure Portal poskytuje praktické grafické zobrazení, které umožňuje sledovat výkon mezipaměti. Můžete například zobrazit počet vytvářených připojení, počet zpracovávaných požadavků, objem operací čtení a zápisu a počet úspěšných a neúspěšných přístupů k mezipaměti. Na základě těchto informací můžete určit efektivitu mezipaměti a v případě potřeby přepnout na jinou konfiguraci nebo změnit zásady vyřazování.
Kromě toho můžete také vytvářet upozornění, která správci odešlou e-mailovou zprávy v případě, pokud jedna nebo několik důležitých metrik spadá mimo očekávaný rozsah. Správce můžete například chtít upozornit v případě, že počet nezdařených přístupů k mezipaměti za poslední hodinu překročil zadanou hodnotu, protože to může znamenat, že mezipaměť je příliš malá nebo data se vyřazují příliš rychle.
Pro mezipaměť můžete také sledovat využití procesoru, paměti a sítě.
Další informace a příklady ukazující, jak vytvořit a nakonfigurovat Azure Cache for Redis, najdete na stránce Kolem azure Cache for Redis na blogu Azure.
Uložení výstupu HTML a stavu relace do mezipaměti
Pokud vytváříte ASP.NET webových aplikací, které běží pomocí webových rolí Azure, můžete uložit informace o stavu relace a výstup HTML ve službě Azure Cache for Redis. Zprostředkovatel stavu relace pro Azure Cache for Redis umožňuje sdílet informace o relacích mezi různými instancemi webové aplikace ASP.NET a je velmi užitečný v situacích webové farmy, kdy není k dispozici spřažení klienta a ukládání dat relace do mezipaměti v paměti by nebylo vhodné.
Použití zprostředkovatele stavu relace se službou Azure Cache for Redis přináší několik výhod, mezi které patří:
- Sdílení stavu relace s velký počet instancí webových aplikací ASP.NET.
- Zajištění vylepšené škálovatelnosti.
- Podpora řízeného souběžného přístupu ke stejným údajům o stavu relací pro několik čtenářů a jednoho zapisovatele.
- Použití komprese k úspoře paměti a zlepšení výkonu sítě.
Další informace najdete v tématu ASP.NET zprostředkovatele stavu relace pro Azure Cache for Redis.
Poznámka:
Nepoužívejte zprostředkovatele stavu relace pro Azure Cache for Redis s ASP.NET aplikacemi, které běží mimo prostředí Azure. Latence přístupu k mezipaměti z prostředí mimo Azure může eliminovat výhody ukládání dat do mezipaměti z hlediska výkonu.
Podobně poskytovatel výstupní mezipaměti pro Azure Cache for Redis umožňuje ukládat odpovědi HTTP generované ASP.NET webovou aplikací. Použití zprostředkovatele výstupní mezipaměti se službou Azure Cache for Redis může zlepšit dobu odezvy aplikací, které vykreslují složitý výstup HTML. Instance aplikací, které generují podobné odpovědi, můžou místo generování tohoto výstupu HTML použít sdílené výstupní fragmenty v mezipaměti. Další informace najdete v tématu ASP.NET poskytovatele výstupní mezipaměti pro Azure Cache for Redis.
Vytvoření vlastní mezipaměti Redis
Azure Cache for Redis funguje jako fasáda na podkladových serverech Redis. Pokud potřebujete pokročilou konfiguraci, která není pokryta službou Azure Redis Cache (například mezipamětí větší než 53 GB), můžete sestavovat a hostovat vlastní servery Redis pomocí služby Azure Virtual Machines.
Jedná se o potenciálně složitý proces, protože pokud chcete implementovat replikaci, možná budete muset vytvořit několik virtuálních počítačů, které budou fungovat jako primární a podřízené uzly. Pokud navíc chcete vytvořit cluster, potřebujete několik primárních a podřízených serverů. Minimální topologie clusterované replikace, která poskytuje vysoký stupeň dostupnosti a škálovatelnosti, zahrnuje alespoň šest virtuálních počítačů uspořádaných jako tři páry primárních/podřízených serverů (cluster musí obsahovat alespoň tři primární uzly).
Aby se minimalizovala latence, měla by být každá dvojice primární/podřízená umístěná blízko sebe. Pokud chcete data v mezipaměti umístit blízko aplikací, které je s největší pravděpodobností budou používat, můžete každou sadu párů spustit v jiném datovém centru Azure umístěném v jiné oblasti. Příklad vytvoření a konfigurace uzlu Redis spuštěného jako virtuální počítač Azure najdete v tématu věnovaném spuštění Redisu na virtuálním počítači se systémem CentOS Linux v Azure.
Poznámka:
Pokud tímto způsobem implementujete vlastní mezipaměť Redis, zodpovídáte za monitorování, správu a zabezpečení služby.
Dělení mezipaměti Redis
Vytváření oddílů mezipaměti zahrnuje rozdělení mezipaměti mezi několik počítačů. Tato struktura poskytuje ve srovnání s použitím jednoho serveru mezipaměti několik výhod, včetně následujících:
- Vytvoření mezipaměti, která je mnohem větší, než by bylo možné uložit na jednom serveru.
- Distribuce dat mezi servery, zlepšení dostupnosti. Pokud jeden server selže nebo je nepřístupný, data, která obsahuje, jsou nedostupná, ale k datům na ostatních serverech se dá i nadále dostat. Pro mezipaměť to není zásadní, protože data uložená v mezipaměti jsou pouze přechodná kopie dat uložených v databázi. Data uložená v mezipaměti na serveru, který přestane být přístupný, mohou být místo toho uložená v mezipaměti na jiném serveru.
- Rozložení zátěže mezi servery a následné vylepšení výkonu a škálovatelnosti.
- Geografické umístění dat blízko uživatelů, kteří k nim přistupují, a související snížení latence.
Nejběžnější metodou dělení mezipaměti je horizontální dělení (sharding). V této strategii každý oddíl (nebo horizontální oddíl) je mezipaměť Redis sama o sobě. Data se směrují do konkrétního oddílu na základě logiky horizontálního dělení, která může pro distribuci data využívat různé přístupy. Model horizontálního dělení poskytuje další informace o implementaci horizontálního dělení.
Pokud chcete implementovat vytváření oddílů v mezipaměti Redis, můžete použít jeden z následujících postupů:
- Směrování dotazů na straně serveru. Při použití této techniky klientská aplikace odešle požadavek libovolnému ze serverů Redis, které tvoří mezipaměť (pravděpodobně nejbližšímu serveru). Každý server Redis ukládá metadata popisující oddíl, který obsahuje, a také obsahuje informace o tom, které oddíly jsou umístěné na jiných serverech. Server Redis prozkoumá požadavek klienta. Pokud se dá vyřešit místně, provede požadovanou operaci. V opačném případě předá požadavek na příslušný server. Tento model je implementovaný clusteringem Redis a je podrobněji popsaný na stránce věnované kurzu ke cluster Redis na webu Redis. Clustering Redis je pro klientské aplikace transparentní a další servery Redis je možné přidat do clusteru (a opětovně rozdělení dat) bez nutnosti překonfigurovat klienty.
- Dělení na straně klienta. V tomto modelu klientská aplikace obsahuje logiku (například ve formě knihovny), která směruje požadavky na příslušný server Redis. Tento přístup je možné použít se službou Azure Cache for Redis. Vytvořte několik Azure Cache for Redis (jeden pro každý oddíl dat) a implementujte logiku na straně klienta, která směruje požadavky do správné mezipaměti. Pokud se schéma dělení změní (pokud se například vytvoří další služba Azure Cache for Redis), může být potřeba překonfigurovat klientské aplikace.
- Dělení s asistencí proxy-. V tomto schématu klientské aplikace odesílají žádosti zprostředkující službě proxy, která ví, jak jsou data rozdělená na oddíly, a potom přesměruje požadavek na příslušný server Redis. Tento přístup lze také použít se službou Azure Cache for Redis; proxy službu je možné implementovat jako cloudovou službu Azure. Tento postup vyžaduje další úroveň složitosti pro implementaci této služby a zpracování požadavků může trvat déle než při použití dělení na straně klienta.
Stránka věnovaná dělení dat mezi několik instancí Redisu na webu Redis poskytuje další informace o implementaci dělení s využitím Redisu.
Implementace klientských aplikací mezipaměti Redis
Redis podporuje klientské aplikace napsané v řadě programovacích jazyků. Pokud vytváříte nové aplikace pomocí rozhraní .NET Framework, doporučujeme použít klientskou knihovnu StackExchange.Redis. Tato knihovna nabízí objektový model rozhraní .NET Framework, který získává podrobnosti pro připojení k serveru Redis, odesílání příkazů a příjem odpovědí. Je k dispozici v sadě Visual Studio jako balíček NuGet. Stejnou knihovnu můžete použít k připojení ke službě Azure Cache for Redis nebo k vlastní mezipaměti Redis hostované na virtuálním počítači.
Pro připojení k serveru Redis použijete statickou metodu Connect třídy ConnectionMultiplexer. Připojení, které tato metoda vytvoří, je určené k použití v průběhu životního cyklu klientské aplikace. Stejné připojení může využívat několik souběžných vláken. Při každé operaci Redis se znovu nepřipojujte a odpojte, protože to může snížit výkon.
Můžete zadat parametry připojení, třeba adresu hostitele Redis a heslo. Pokud používáte Azure Cache for Redis, heslo je primární nebo sekundární klíč vygenerovaný pro Azure Cache for Redis pomocí webu Azure Portal.
Po připojení k serveru Redis můžete získat popisovač databáze Redis, která funguje jako mezipaměť. Připojení Redis k tomuto účelu poskytuje metodu GetDatabase. Potom můžete k načítání položek z mezipaměti a ukládání dat do mezipaměti využít metody StringGet a StringSet. Tyto metody očekávají klíč jako parametr a buď vrací položku v mezipaměti, která má odpovídající hodnotu (StringGet), nebo přidají položku do mezipaměti s tímto klíčem (StringSet).
V závislosti na umístění serveru Redis může řada operací způsobit určitou latenci při přenášení požadavku na server a vracení odpovědi klientovi. Knihovna StackExchange poskytuje pro mnoho metod asynchronní verze, jejichž zpřístupněním pomáhá zajistit rychlost odezvy klientských aplikací. Tyto metody podporují asynchronní vzor založený na úlohách v rozhraní .NET Framework.
Následující fragment kódu ukazuje metodu s názvem RetrieveItem. Ukazuje implementaci modelu s doplňováním mezipaměti na základě Redisu a knihovny StackExchange. Tato metoda vezme řetězcovou hodnotu klíče a pokusí se načíst příslušnou položku z mezipaměti Redis voláním metody StringGetAsync (asynchronní verze metody StringGet).
Pokud se položka nenajde, načte se z podkladového zdroje dat pomocí GetItemFromDataSourceAsync metody (což je místní metoda, nikoli součást knihovny StackExchange). Potom se pomocí metody StringSetAsync přidá do mezipaměti, takže se příště dá načíst rychleji.
// Connect to the Azure Redis cache
ConfigurationOptions config = new ConfigurationOptions();
config.EndPoints.Add("<your DNS name>.redis.cache.windows.net");
config.Password = "<Redis cache key from management portal>";
ConnectionMultiplexer redisHostConnection = ConnectionMultiplexer.Connect(config);
IDatabase cache = redisHostConnection.GetDatabase();
...
private async Task<string> RetrieveItem(string itemKey)
{
// Attempt to retrieve the item from the Redis cache
string itemValue = await cache.StringGetAsync(itemKey);
// If the value returned is null, the item was not found in the cache
// So retrieve the item from the data source and add it to the cache
if (itemValue == null)
{
itemValue = await GetItemFromDataSourceAsync(itemKey);
await cache.StringSetAsync(itemKey, itemValue);
}
// Return the item
return itemValue;
}
Tyto StringGet metody StringSet nejsou omezeny na načítání nebo ukládání řetězcových hodnot. Mohou zpracovat libovolnou položku, která je serializovaná jako pole bajtů. Pokud je nutné uložit objekt .NET, můžete ho serializovat jako datový proud bajtů a k jeho zápisu do mezipaměti použít metodu StringSet.
Podobně můžete číst objekt z mezipaměti pomocí metody StringGet a deserializovat ho jako objekt .NET. Následující kód ukazuje sadu rozšiřujících metod pro rozhraní IDatabase (metoda GetDatabase připojení Redis vrací objekt IDatabase) a část ukázkového kódu, který používá tyto metody pro čtení a zápis objektu BlogPost do mezipaměti:
public static class RedisCacheExtensions
{
public static async Task<T> GetAsync<T>(this IDatabase cache, string key)
{
return Deserialize<T>(await cache.StringGetAsync(key));
}
public static async Task<object> GetAsync(this IDatabase cache, string key)
{
return Deserialize<object>(await cache.StringGetAsync(key));
}
public static async Task SetAsync(this IDatabase cache, string key, object value)
{
await cache.StringSetAsync(key, Serialize(value));
}
static byte[] Serialize(object o)
{
byte[] objectDataAsStream = null;
if (o != null)
{
var jsonString = JsonSerializer.Serialize(o);
objectDataAsStream = Encoding.ASCII.GetBytes(jsonString);
}
return objectDataAsStream;
}
static T Deserialize<T>(byte[] stream)
{
T result = default(T);
if (stream != null)
{
var jsonString = Encoding.ASCII.GetString(stream);
result = JsonSerializer.Deserialize<T>(jsonString);
}
return result;
}
}
Následující kód ukazuje metodu s názvem RetrieveBlogPost, která tyto rozšiřující metody používá pro čtení a zápis serializovatelného objektu BlogPost do mezipaměti s využitím doplňování mezipaměti:
// The BlogPost type
public class BlogPost
{
private HashSet<string> tags;
public BlogPost(int id, string title, int score, IEnumerable<string> tags)
{
this.Id = id;
this.Title = title;
this.Score = score;
this.tags = new HashSet<string>(tags);
}
public int Id { get; set; }
public string Title { get; set; }
public int Score { get; set; }
public ICollection<string> Tags => this.tags;
}
...
private async Task<BlogPost> RetrieveBlogPost(string blogPostKey)
{
BlogPost blogPost = await cache.GetAsync<BlogPost>(blogPostKey);
if (blogPost == null)
{
blogPost = await GetBlogPostFromDataSourceAsync(blogPostKey);
await cache.SetAsync(blogPostKey, blogPost);
}
return blogPost;
}
Redis podporuje paralelní zpracování příkazů, pokud klientská aplikace odešle více asynchronní požadavků. Redis může multiplexovat požadavky pomocí stejného připojení a nemusí příkazy přijímat a reagovat na ně v pevně daném pořadí.
Tento přístup pomáhá snížit latenci, neboť zajišťuje efektivnější využití sítě. Následující fragment kódu ukazuje příklad, který načte podrobné informace o dvou zákaznících současně. Kód předá dva požadavky, provede další zpracování (není vidět) a potom čeká na příjem výsledků. Metoda Wait objektu mezipaměti je podobná metodě Task.Wait rozhraní .NET Framework:
ConnectionMultiplexer redisHostConnection = ...;
IDatabase cache = redisHostConnection.GetDatabase();
...
var task1 = cache.StringGetAsync("customer:1");
var task2 = cache.StringGetAsync("customer:2");
...
var customer1 = cache.Wait(task1);
var customer2 = cache.Wait(task2);
Další informace o psaní klientských aplikací, které můžou používat Azure Cache for Redis, najdete v dokumentaci ke službě Azure Cache for Redis. Další informace najdete také na StackExchange.Redis.
Stránka na stejném webu, která je věnovaná kanálům a multiplexorům, poskytuje další informace o asynchronních operacích a paralelním zpracováním využitím Redisu a knihovny StackExchange.
Použití mezipaměti Redis
Nejjednodušší použití Redisu pro ukládání do mezipaměti spočívá v párech klíč-hodnota, kde hodnota je neinterpretovaný řetězec libovolné délky, který může obsahovat libovolná binární data. (Jedná se v podstatě o pole bajtů, které lze považovat za řetězec). Tento scénář jsme ukázali v části Implementace klientských aplikací mezipaměti Redis dříve v tomto článku.
Všimněte si, že klíče také obsahují neinterpretovaná data, takže jako klíč můžete použít libovolné binární informace. Čím delší ale tento klíč je, tím více místa zabere jeho uložení a tím déle budou trvat operace vyhledávání. Pro zajištění použitelnosti a snadné údržby pečlivě navrhněte prostor klíčů a používejte smysluplné (ale ne příliš dlouhé) klíče.
K reprezentaci zákazníka s ID 100 můžete například místo jednoduchého klíče „100“ použít strukturovaný klíč „customer:100“. Toto schéma umožňuje snadno rozlišit mezi hodnotami, které obsahují různé datové typy. Můžete například také použít klíč „order:100“ k reprezentaci objednávky s ID 100.
Kromě jednorozměrných binárních řetězců může pár klíč-hodnota ukládat také strukturovanější informace, včetně seznamů, sad (seřazených i neseřazených) a hodnot hash. Redis poskytuje komplexní sadu příkazů, které umožňují manipulovat s těmito typy, a řada těchto příkazů je pro aplikace .NET Framework dostupná pomocí klientských knihoven, jako je například StackExchange. Stránka s úvodem do datových typů a abstrakcí Redis na webu Redis poskytuje podrobnější přehled těchto typů a příkazů, které můžete při manipulaci s nimi využít.
Tento oddíl obsahuje přehled běžných případů použití pro tyto datové typy a příkazy.
Provádění atomických a dávkových operací
Redis podporuje pro řetězcové hodnoty řadu atomických operací typu get a set. Tyto operace zajistí, že nenastane možné soupeření o pořadí, ke kterému může dojít při použití samostatných příkazů GET a SET. Mezi dostupné operace patří:
INCR,INCRBY,DECR, aDECRBY, které provádějí atomické operace inkrementace a dekrementace pro celočíselné datové hodnoty. Knihovna StackExchange poskytuje pro provedení těchto operací přetížené verze metodIDatabase.StringIncrementAsyncaIDatabase.StringDecrementAsynca vrátí výslednou hodnotu, která je uložená v mezipaměti. Následující fragment kódu ukazuje, jak tyto metody používat:ConnectionMultiplexer redisHostConnection = ...; IDatabase cache = redisHostConnection.GetDatabase(); ... await cache.StringSetAsync("data:counter", 99); ... long oldValue = await cache.StringIncrementAsync("data:counter"); // Increment by 1 (the default) // oldValue should be 100 long newValue = await cache.StringDecrementAsync("data:counter", 50); // Decrement by 50 // newValue should be 50GETSETnačte hodnotu, která je přidružená ke klíči, a změní ji na novou hodnotu. Knihovna StackExchange zpřístupňuje tuto operaci prostřednictvím metodyIDatabase.StringGetSetAsync. Následující fragment kódu ukazuje příklad této metody. Tento kód vrátí aktuální hodnotu, která je přidružená ke klíči „data:counter“ z předchozího příkladu. Potom resetuje hodnotu pro tento klíč zpátky na nulu, a to všechno v rámci stejné operace:ConnectionMultiplexer redisHostConnection = ...; IDatabase cache = redisHostConnection.GetDatabase(); ... string oldValue = await cache.StringGetSetAsync("data:counter", 0);MGETaMSETmohou vrátit nebo změnit sadu řetězcových hodnot jako jednu operaci. MetodyIDatabase.StringGetAsyncaIDatabase.StringSetAsyncjsou pro podporu této funkce přetížené, jak ukazuje následující příklad:ConnectionMultiplexer redisHostConnection = ...; IDatabase cache = redisHostConnection.GetDatabase(); ... // Create a list of key-value pairs var keysAndValues = new List<KeyValuePair<RedisKey, RedisValue>>() { new KeyValuePair<RedisKey, RedisValue>("data:key1", "value1"), new KeyValuePair<RedisKey, RedisValue>("data:key99", "value2"), new KeyValuePair<RedisKey, RedisValue>("data:key322", "value3") }; // Store the list of key-value pairs in the cache cache.StringSet(keysAndValues.ToArray()); ... // Find all values that match a list of keys RedisKey[] keys = { "data:key1", "data:key99", "data:key322"}; // values should contain { "value1", "value2", "value3" } RedisValue[] values = cache.StringGet(keys);
Můžete také zkombinovat několik operací do jedné transakce Redis, jak je popsáno v části Transakce a dávky Redis dříve v tomto článku. Knihovna StackExchange poskytuje podporu pro transakce prostřednictvím rozhraní ITransaction.
K vytvoření objektu ITransaction použijete metodu IDatabase.CreateTransaction. K vyvolání příkazů pro transakci použijete metody, které poskytuje objekt ITransaction.
Rozhraní ITransaction poskytuje přístup k sadě metod, které jsou podobné metodám, k nimž přistupuje rozhraní IDatabase, ale s tím rozdílem, že všechny metody jsou asynchronní. To znamená, že se provádějí pouze při ITransaction.Execute vyvolání metody. Hodnota, kterou vrátí metoda ITransaction.Execute, určuje, jestli se transakce úspěšně vytvořila (true) nebo jestli selhala (false).
Následující fragment kódu ukazuje příklad, který inkrementuje a dekrementuje dva čítače v rámci stejné transakce:
ConnectionMultiplexer redisHostConnection = ...;
IDatabase cache = redisHostConnection.GetDatabase();
...
ITransaction transaction = cache.CreateTransaction();
var tx1 = transaction.StringIncrementAsync("data:counter1");
var tx2 = transaction.StringDecrementAsync("data:counter2");
bool result = transaction.Execute();
Console.WriteLine("Transaction {0}", result ? "succeeded" : "failed");
Console.WriteLine("Result of increment: {0}", tx1.Result);
Console.WriteLine("Result of decrement: {0}", tx2.Result);
Nezapomeňte, že jsou transakce Redis jsou jiné než transakce v relačních databázích. Metoda Execute jednoduše zařadí do fronty všechny příkazy, které tvoří příslušnou transakci ke spuštění, a pokud je některý z nich poškozený, transakce se zastaví. Pokud jsou všechny příkazy úspěšně zařazené ve frontě, každý příkaz běží asynchronně.
Pokud některý příkaz selže, zpracování ostatních pokračuje i nadále. Pokud je třeba ověřit, jestli se příkaz úspěšně dokončil, musíte načíst výsledky tohoto příkazu pomocí vlastnosti Result odpovídající úlohy, jak je uvedené v předchozím příkladu. Čtení vlastnosti Result bude blokovat volající vlákno, dokud se úloha nedokončí.
Další informace naleznete v tématu Transakce v Redis.
Při provádění dávkových operací můžete použít rozhraní IBatch knihovny StackExchange. Toto rozhraní poskytuje přístup k sadě metod, které jsou podobné metodám, k nimž přistupuje rozhraní IDatabase, ale s tím rozdílem, že všechny metody jsou asynchronní.
Vytvoříte objekt IBatch pomocí metody IDatabase.CreateBatch a potom spustíte dávku pomocí metody IBatch.Execute, jak ukazuje následující příklad. Tento kód jednoduše nastaví řetězcovou hodnotu, inkrementuje a dekrementuje čítače použité v předchozím příkladu a zobrazí výsledky:
ConnectionMultiplexer redisHostConnection = ...;
IDatabase cache = redisHostConnection.GetDatabase();
...
IBatch batch = cache.CreateBatch();
batch.StringSetAsync("data:key1", 11);
var t1 = batch.StringIncrementAsync("data:counter1");
var t2 = batch.StringDecrementAsync("data:counter2");
batch.Execute();
Console.WriteLine("{0}", t1.Result);
Console.WriteLine("{0}", t2.Result);
Je důležité si uvědomit, že na rozdíl od transakce je příkaz v dávce neúspěšný, protože je poškozený, ostatní příkazy se můžou pořád spouštět. Metoda IBatch.Execute nevrací žádnou indikaci úspěchu nebo selhání.
Provedení operací typu „spustit a zapomenout“
Redis podporuje operace typu „spustit a zapomenout“ pomocí příznaků příkazů. V takové situaci klient jednoduše zahájí operaci, ale nemá zájem o výsledek a nečeká na dokončení příkazu. Následující příklad ukazuje, jak provést příkaz INCR jako operaci typu „spustit a zapomenout“:
ConnectionMultiplexer redisHostConnection = ...;
IDatabase cache = redisHostConnection.GetDatabase();
...
await cache.StringSetAsync("data:key1", 99);
...
cache.StringIncrement("data:key1", flags: CommandFlags.FireAndForget);
Zadání klíčů s automatickým vypršením platnosti
Když ukládáte položky v mezipaměti Redis, můžete zadat časový limit, po kterém se položky z mezipaměti automaticky odeberou. Můžete taky zadat dotaz, kolik času klíči ještě zbývá, než vyprší jeho platnost, a to pomocí příkazu TTL. Tento příkaz pro aplikace StackExchange dostupný pomocí metody IDatabase.KeyTimeToLive.
Následující fragment kódu ukazuje, jak nastavit dobu vypršení platnosti klíče na 20 sekund a jak zadat dotaz na zbývající dobu životnosti klíče:
ConnectionMultiplexer redisHostConnection = ...;
IDatabase cache = redisHostConnection.GetDatabase();
...
// Add a key with an expiration time of 20 seconds
await cache.StringSetAsync("data:key1", 99, TimeSpan.FromSeconds(20));
...
// Query how much time a key has left to live
// If the key has already expired, the KeyTimeToLive function returns a null
TimeSpan? expiry = cache.KeyTimeToLive("data:key1");
Dobu vypršení platnosti můžete také nastavit na konkrétní datum a čas pomocí příkazu EXPIRE, který je v knihovně StackExchange k dispozici jako metoda KeyExpireAsync:
ConnectionMultiplexer redisHostConnection = ...;
IDatabase cache = redisHostConnection.GetDatabase();
...
// Add a key with an expiration date of midnight on 1st January 2015
await cache.StringSetAsync("data:key1", 99);
await cache.KeyExpireAsync("data:key1",
new DateTime(2015, 1, 1, 0, 0, 0, DateTimeKind.Utc));
...
Tip
K ručnímu odebrání položky z mezipaměti můžete použít příkaz DEL, který je v knihovně StackExchange k dispozici jako metoda IDatabase.KeyDeleteAsync.
Použití značek ke vzájemné korelaci položek v mezipaměti
Sada Redis je kolekce několik položek, které sdílejí jeden klíč. K vytvoření sady můžete použít příkaz SADD. Položky v sadě můžete načíst pomocí příkazu SMEMBERS. Knihovna StackExchange implementuje příkaz SADD pomocí metody IDatabase.SetAddAsync a příkaz SMEMBERS pomocí metody IDatabase.SetMembersAsync.
Můžete také kombinovat existující sady a vytvořit nové sady pomocí příkazů SDIFF (rozdíl množin), SINTER (průnik) a SUNION (sjednocení). Knihovna StackExchange unifikuje tyto operace v rámci metody IDatabase.SetCombineAsync. První parametr této metody určuje, jaká množinová operace se má provést.
Následující fragmenty kódu ukazují, že sady mohou být užitečné pro rychlé ukládání a načítání kolekcí souvisejících položek. Tento kód využívá typ BlogPost, který byl popsaný v části Implementace klientských aplikací mezipaměti Redis dříve v tomto článku.
Objekt BlogPost obsahuje čtyři pole – ID, název, hodnocení a kolekce značek. První fragment kódu ukazuje ukázková data použitá k naplnění seznamu objektů BlogPost v jazyce C#:
List<string[]> tags = new List<string[]>
{
new[] { "iot","csharp" },
new[] { "iot","azure","csharp" },
new[] { "csharp","git","big data" },
new[] { "iot","git","database" },
new[] { "database","git" },
new[] { "csharp","database" },
new[] { "iot" },
new[] { "iot","database","git" },
new[] { "azure","database","big data","git","csharp" },
new[] { "azure" }
};
List<BlogPost> posts = new List<BlogPost>();
int blogKey = 0;
int numberOfPosts = 20;
Random random = new Random();
for (int i = 0; i < numberOfPosts; i++)
{
blogKey++;
posts.Add(new BlogPost(
blogKey, // Blog post ID
string.Format(CultureInfo.InvariantCulture, "Blog Post #{0}",
blogKey), // Blog post title
random.Next(100, 10000), // Ranking score
tags[i % tags.Count])); // Tags--assigned from a collection
// in the tags list
}
Značky pro každý objekt BlogPost můžete uložit jako sadu v mezipaměti Redis a ke každé sadě přidružit ID BlogPost. To aplikaci umožňuje rychle najít všechny značky, které patří ke konkrétnímu blogovému příspěvku. Pokud chcete povolit vyhledávání v opačném směru a najít všechny blogové příspěvky, které sdílejí konkrétní značku, můžete vytvořit jinou sadu, která obsahuje blogové příspěvky odkazující na příslušné ID značky v klíči:
ConnectionMultiplexer redisHostConnection = ...;
IDatabase cache = redisHostConnection.GetDatabase();
...
// Tags are easily represented as Redis Sets
foreach (BlogPost post in posts)
{
string redisKey = string.Format(CultureInfo.InvariantCulture,
"blog:posts:{0}:tags", post.Id);
// Add tags to the blog post in Redis
await cache.SetAddAsync(
redisKey, post.Tags.Select(s => (RedisValue)s).ToArray());
// Now do the inverse so we can figure out which blog posts have a given tag
foreach (var tag in post.Tags)
{
await cache.SetAddAsync(string.Format(CultureInfo.InvariantCulture,
"tag:{0}:blog:posts", tag), post.Id);
}
}
Tyto struktury umožňují velmi efektivně provádět řadu běžných dotazů. Tímto způsobem můžete například najít a zobrazit všechny značky pro blogový příspěvek 1:
// Show the tags for blog post #1
foreach (var value in await cache.SetMembersAsync("blog:posts:1:tags"))
{
Console.WriteLine(value);
}
Všechny značky, které jsou společné pro blogový příspěvek 1 a blogový příspěvek 2, můžete najít tak, že následujícím způsobem provedete operaci průniku:
// Show the tags in common for blog posts #1 and #2
foreach (var value in await cache.SetCombineAsync(SetOperation.Intersect, new RedisKey[]
{ "blog:posts:1:tags", "blog:posts:2:tags" }))
{
Console.WriteLine(value);
}
A můžete také najít všechny blogové příspěvky, které obsahují konkrétní značku:
// Show the ids of the blog posts that have the tag "iot".
foreach (var value in await cache.SetMembersAsync("tag:iot:blog:posts"))
{
Console.WriteLine(value);
}
Vyhledání nedávno použitých položek
Běžnou úlohou řady aplikací je vyhledání naposledy použitých položek. Například blogovací web může chtít zobrazit informace o naposledy přečtených příspěvcích.
Tuto funkci můžete implementovat pomocí seznamu Redis. Seznam Redis obsahuje několik položek, které sdílejí stejný klíč. Tento seznam funguje jako fronta se dvěma konci. Na oba konce tohoto seznamu můžete vkládat položky pomocí příkazů LPUSH (vložení vpravo) a RPUSH (vložení vlevo). Položky můžete z obou konců seznamu načítat pomocí příkazů LPOP a RPOP. Pomocí příkazů LRANGE a RRANGE můžete také vrátit sadu elementů.
Uvedené fragmenty kódu ukazují, jak se tyto operace dají provést pomocí knihovny StackExchange. Tento kód používá typ BlogPost z předchozích příkladů. Když čtenář čte blogový příspěvek, metoda IDatabase.ListLeftPushAsync vloží název tohoto příspěvku do seznamu, který je přidružený ke klíči „blog:recent_posts“ v mezipaměti Redis.
ConnectionMultiplexer redisHostConnection = ...;
IDatabase cache = redisHostConnection.GetDatabase();
...
string redisKey = "blog:recent_posts";
BlogPost blogPost = ...; // Reference to the blog post that has just been read
await cache.ListLeftPushAsync(
redisKey, blogPost.Title); // Push the blog post onto the list
Jak se čtou další blogové příspěvky, jejich názvy se vkládají do stejného seznamu. Tento seznam je uspořádaný v pořadí, ve kterém byly přidány jednotlivé názvy. Poslední přečtené blogové příspěvky se nacházejí na levém konci seznamu. (Pokud je blogový příspěvek přečtený několikrát, bude mít v tomto seznamu několik položek.)
Názvy naposledy přečtených příspěvků můžete zobrazit pomocí metody IDatabase.ListRange. Tato metoda používá klíč, který obsahuje příslušný seznam, a počáteční a koncový bod. Následující kód načte názvy 10 blogových příspěvků (položky od 0 do 9) na levém konci seznamu:
// Show latest ten posts
foreach (string postTitle in await cache.ListRangeAsync(redisKey, 0, 9))
{
Console.WriteLine(postTitle);
}
Všimněte si, že ListRangeAsync metoda neodebere položky ze seznamu. K tomuto účelu můžete použít metody IDatabase.ListLeftPopAsync a IDatabase.ListRightPopAsync.
Abyste zabránili tomu, že tento seznam bude narůstat donekonečna, můžete položky pravidelně probírat ořezáváním tohoto seznamu. Následující fragment kódu ukazuje, jak odebrat všechny položky ze seznamu až na posledních pět položek nejvíce vlevo:
await cache.ListTrimAsync(redisKey, 0, 5);
Implementace tabulky výsledků
Ve výchozím nastavení nejsou položky v sadě uloženy v žádném konkrétním pořadí. Seřazené sady můžete vytvořit pomocí příkazu ZADD (metoda IDatabase.SortedSetAdd v knihovně StackExchange). Položky jsou uspořádané pomocí číselné hodnoty nazvané skóre, která se poskytuje jako parametr tohoto příkazu.
Následující fragment kódu přidá název blogového příspěvku do uspořádaného seznamu. V tomto příkladu má každý blogový příspěvek také pole skóre, které obsahuje pozici tohoto blogového příspěvku.
ConnectionMultiplexer redisHostConnection = ...;
IDatabase cache = redisHostConnection.GetDatabase();
...
string redisKey = "blog:post_rankings";
BlogPost blogPost = ...; // Reference to a blog post that has just been rated
await cache.SortedSetAddAsync(redisKey, blogPost.Title, blogPost.Score);
Názvy a skóre blogových příspěvků můžete načíst ve vzestupném pořadí pomocí metody IDatabase.SortedSetRangeByRankWithScores:
foreach (var post in await cache.SortedSetRangeByRankWithScoresAsync(redisKey))
{
Console.WriteLine(post);
}
Poznámka:
Knihovna StackExchange také poskytuje metodu IDatabase.SortedSetRangeByRankAsync , která vrací data v pořadí skóre, ale nevrací skóre.
Položky můžete také načíst podle skóre v sestupném pořadí a omezit počet vrácených položek tím, že metodě IDatabase.SortedSetRangeByRankWithScoresAsync poskytnete další parametry. Následující příklad zobrazuje názvy a skóre 10 nejlépe hodnocených blogových příspěvků:
foreach (var post in await cache.SortedSetRangeByRankWithScoresAsync(
redisKey, 0, 9, Order.Descending))
{
Console.WriteLine(post);
}
Následující příklad používá metodu IDatabase.SortedSetRangeByScoreWithScoresAsync, pomocí které můžete omezit vracené položky jenom na ty, které spadají do určeného rozsahu skóre:
// Blog posts with scores between 5000 and 100000
foreach (var post in await cache.SortedSetRangeByScoreWithScoresAsync(
redisKey, 5000, 100000))
{
Console.WriteLine(post);
}
Zpráva s využitím kanálů
Server Redis kromě toho, že funguje jako mezipaměť dat, poskytuje také zasílání zpráv prostřednictvím vysoce výkonného mechanismu vydavatel/odběratel. Klientské aplikace se mohou přihlásit k odběru kanálu, do kterého mohou publikovat zprávy jiné aplikace nebo služby. Aplikace přihlášené k odběru potom obdrží tyto zprávy a mohou je zpracovávat.
Redis poskytuje pro klientské aplikace příkaz SUBSCRIBE, který umožňuje přihlásit se k odběru kanálů. Tento příkaz očekává název jednoho nebo několika kanálů, ze kterých bude aplikace přijímat zprávy. Knihovna StackExchange zahrnuje rozhraní ISubscription, které aplikaci rozhraní .NET Framework umožňuje přihlásit se k odběru kanálů a publikovat do nich.
Pomocí metody GetSubscriber připojení k serveru Redis vytvoříte objekt ISubscription. Potom můžete pomocí metody SubscribeAsync tohoto objektu naslouchat zprávám v kanálu. Následující příklad kódu ukazuje, jak se přihlásit k odběru kanálu s názvem „messages: blogPosts“:
ConnectionMultiplexer redisHostConnection = ...;
ISubscriber subscriber = redisHostConnection.GetSubscriber();
...
await subscriber.SubscribeAsync("messages:blogPosts", (channel, message) => Console.WriteLine("Title is: {0}", message));
Prvním parametrem metody Subscribe je název kanálu. Pro kanály se používají stejné konvence pojmenování jako pro klíče v mezipaměti. Název může obsahovat jakákoli binární data, ale doporučujeme použít relativně krátké smysluplné řetězce, které vám pomůžou zajistit dobrý výkon a udržovatelnost.
Všimněte si také, že je obor názvů, který používají kanály, je oddělený od oboru názvů, který používají klíče. To znamená, že můžete mít kanály a klíče, které mají stejný název, i když to může představovat obtížnější údržbu kódu aplikace.
Druhým parametrem je delegát akce. Tento delegát se spustí asynchronně vždy, když na kanálu se objeví nová zpráva. Tento příklad jednoduše zobrazí zprávu na konzole (zpráva bude obsahovat název blogového příspěvku).
K publikování do kanálu může aplikace v Redisu využít příkaz PUBLISH. Knihovna StackExchange poskytuje k provedení této operace metodu IServer.PublishAsync. Další fragment kódu ukazuje, jak publikovat zprávu do kanálu „messages:blogPosts“:
ConnectionMultiplexer redisHostConnection = ...;
ISubscriber subscriber = redisHostConnection.GetSubscriber();
...
BlogPost blogPost = ...;
subscriber.PublishAsync("messages:blogPosts", blogPost.Title);
Existuje několik věcí, které byste o mechanismu publikování/odebírání měli vědět:
- Ke stejnému kanálu se může přihlásit více odběratelů a všichni dostanou zprávy publikované do daného kanálu.
- Předplatitelé dostanou zprávy, které byly publikovány až po přihlášení k odběru. Kanály nejsou uloženy do vyrovnávací paměti a jakmile se publikuje zpráva, infrastruktura Redis zprávu odešle každému odběrateli a pak ji odebere.
- Ve výchozím nastavení jsou zprávy přijímány odběrateli v pořadí, ve kterém se odesílají. Ve vysoce aktivním systému s velkým počtem zpráv a mnoha odběrateli a vydavateli může garantované sekvenční doručování zpráv snížit výkon systému. Pokud jsou jednotlivé zprávy nezávislé a jejich pořadí není důležité, můžete systému Redis povolit souběžné zpracování a zlepšit tak rychlost odezvy. Provede to tak, že v klientovi StackExchange nastavíte vlastnost PreserveAsyncOrder připojení použitého odběratelem na hodnotu false:
ConnectionMultiplexer redisHostConnection = ...;
redisHostConnection.PreserveAsyncOrder = false;
ISubscriber subscriber = redisHostConnection.GetSubscriber();
Aspekty serializace
Při volbě formátu serializace zvažte kompromis mezi výkonem, interoperabilitou, správou verzí, kompatibilitou s existujícími systémy, kompresí dat a režijními náklady na paměť. Při vyhodnocování výkonu mějte na paměti, že srovnávací testy jsou vysoce závislé na kontextu. Nemusejí odpovídat skutečným úlohám a brát v úvahu novější knihovny nebo verze. Pro všechny scénáře neexistuje jediný "nejrychlejší" serializátor.
Zvažte například tyto možnosti:
Protocol Buffers (také označovaný jako protobuf) je serializační formát vyvinutý Googlem pro efektivní serializaci strukturovaných dat. K definování struktur zpráv používá definiční soubory silného typu. Z těchto definičních souborů se potom zkompiluje kód pro serializaci a deserializaci zpráv pro konkrétní jazyk. Protobuf je možné využít přes stávající mechanismy RPC nebo může vygenerovat službu RPC.
Apache Thrift používá podobný přístup – definiční soubory silného typu a kompilační krok pro vygenerování serializačního kódu a služeb RPC.
Apache Avro poskytuje podobné funkce jako vyrovnávací paměti protokolu a thrift, ale neexistuje žádný krok kompilace. Místo toho serializovaná data vždycky obsahují schéma, které popisuje strukturu.
JSON je otevřený standard, který používá uživatelsky čitelná textová pole. Nabízí širokou podporu pro různé platformy. JSON nepoužívá schémata zpráv. Vzhledem k tomu, že je textový formát, není příliš efektivní přes drát. V některých případech ale můžete vracet položky v mezipaměti přímo do klienta prostřednictvím protokolu HTTP a v takovém případě ukládání ve formátu JSON může snížit náklady na deserializaci z jiného formátu a následnou serializaci do formátu JSON.
Binary JSON (BSON) je binární serializační formát, který používá strukturu podobnou formátu JSON. Formát BSON je navržený tak, aby byl jednoduchý a umožňoval snadné procházení a rychlou serializaci a deserializaci (ve srovnání s formátem JSON). Velikost datových částí je srovnatelná s formátem JSON. V závislosti na datech může být datová část BSON menší nebo větší než datová část JSON. BSON má některé další datové typy, které nejsou dostupné ve formátu JSON, zejména BinData (pro bajtová pole) a Datum.
MessagePack je binární serializační formát, který je navržený pro kompaktní přenos linkou. Nevyužívá žádná schémata zpráv ani kontrolu typu zpráv.
Bond je architektura pro práci se schematizovanými daty pro různé platformy. Podporuje serializaci a deserializaci napříč jazyky. Významný rozdíl oproti ostatním systémům spočívá v podpoře dědičnosti, aliasů typů a obecných typů.
gRPC je opensourcový systém RPC vyvinutý společností Google. Jako svůj definiční jazyk a základní formát pro výměnu zpráv ve výchozím nastavení používá Protocol Buffers.
Další kroky
- Dokumentace ke službě Azure Cache for Redis
- Nejčastější dotazy ke službě Azure Cache for Redis
- Asynchronní vzor založený na úlohách
- Dokumentace k Redisu
- StackExchange.Redis
- Průvodce dělením dat
Související prostředky
Při implementaci ukládání do mezipaměti v aplikacích můžou být pro váš scénář relevantní také následující vzory:
Model s doplňováním mezipaměti: Tento model popisuje načítání dat na vyžádání do mezipaměti z úložiště dat. Tento model také pomáhá zachovat konzistenci mezi daty uloženými v mezipaměti a daty v původním úložišti dat.
Model horizontálního dělení poskytuje informace o implementaci horizontálního dělení, které pomáhá vylepšit škálovatelnost při ukládání a využívání velkých objemů dat.