Použití řídicích panelů k vizualizaci metrik Azure Databricks
Poznámka:
Tento článek spoléhá na opensourcovou knihovnu hostované na GitHubu na adrese: https://github.com/mspnp/spark-monitoring.
Původní knihovna podporuje Azure Databricks Runtimes 10.x (Spark 3.2.x) a starší.
Databricks přispěl aktualizovanou verzí pro podporu azure Databricks Runtimes 11.0 (Spark 3.3.x) a vyšší ve l4jv2 větvi na adrese: https://github.com/mspnp/spark-monitoring/tree/l4jv2.
Upozorňujeme, že verze 11.0 není zpětně kompatibilní kvůli různým systémům protokolování používaným v modulech Databricks Runtime. Nezapomeňte použít správné sestavení pro databricks Runtime. Knihovna a úložiště GitHub jsou v režimu údržby. Pro další verze nejsou žádné plány a podpora problémů bude maximálně náročná. Pokud máte jakékoli další dotazy týkající se knihovny nebo plánu monitorování a protokolování prostředí Azure Databricks, obraťte se na azure-spark-monitoring-help@databricks.com.
Tento článek ukazuje, jak nastavit řídicí panel Grafana pro monitorování úloh Azure Databricks kvůli problémům s výkonem.
Azure Databricks je rychlá, výkonná analytická služba založená na Apache Sparku, která usnadňuje rychlý vývoj a nasazování řešení pro analýzu velkých objemů dat a umělou inteligenci (AI). Monitorování je důležitou součástí provozu úloh Azure Databricks v produkčním prostředí. Prvním krokem je shromáždit metriky do pracovního prostoru pro účely analýzy. V Azure je nejlepším řešením pro správu dat protokolů Azure Monitor. Azure Databricks nativně nepodporuje odesílání dat protokolů do služby Azure Monitor, ale knihovna pro tuto funkci je dostupná na GitHubu.
Tato knihovna umožňuje protokolování metrik služeb Azure Databricks a také metriky událostí dotazů streamování Apache Sparku. Po úspěšném nasazení této knihovny do clusteru Azure Databricks můžete dále nasadit sadu řídicích panelů Grafana , které můžete nasadit jako součást produkčního prostředí.
Požadavky
Nakonfigurujte cluster Azure Databricks tak, aby používal knihovnu monitorování, jak je popsáno v souboru readme GitHubu.
Nasazení pracovního prostoru Azure Log Analytics
Pokud chcete nasadit pracovní prostor Azure Log Analytics, postupujte takto:
Přejděte do
/perftools/deployment/loganalyticsadresáře.Nasaďte šablonu logAnalyticsDeploy.json Azure Resource Manageru. Další informace o nasazení šablon Resource Manageru najdete v tématu Nasazení prostředků pomocí šablon Resource Manageru a Azure CLI. Šablona má následující parametry:
- umístění: Oblast, kde se nasadí pracovní prostor a řídicí panely služby Log Analytics.
- serviceTier: Cenová úroveň pracovního prostoru. Seznam platných hodnot najdete tady .
- dataRetention (volitelné): Počet dnů, po které se data protokolu uchovávají v pracovním prostoru služby Log Analytics. Výchozí hodnota je 30 dní. Pokud je
Freecenová úroveň, uchovávání dat musí být sedm dní. - workspaceName (volitelné): Název pracovního prostoru. Pokud není zadáno, šablona vygeneruje název.
az deployment group create --resource-group <resource-group-name> --template-file logAnalyticsDeploy.json --parameters location='East US' serviceTier='Standalone'
Tato šablona vytvoří pracovní prostor a také vytvoří sadu předdefinovaných dotazů, které používají řídicí panel.
Nasazení Grafany ve virtuálním počítači
Grafana je opensourcový projekt, který můžete nasadit k vizualizaci metrik časových řad uložených v pracovním prostoru služby Azure Log Analytics pomocí modulu plug-in Grafana pro Azure Monitor. Grafana se spouští na virtuálním počítači a vyžaduje účet úložiště, virtuální síť a další prostředky. Pokud chcete nasadit virtuální počítač s bitnami certifikovanou imagí Grafany a přidruženými prostředky, postupujte takto:
Pomocí Azure CLI přijměte podmínky image z Azure Marketplace pro Grafana.
az vm image terms accept --publisher bitnami --offer grafana --plan defaultPřejděte do
/spark-monitoring/perftools/deployment/grafanaadresáře v místní kopii úložiště GitHub.Šablonu grafanaDeploy.json Resource Manageru nasaďte následujícím způsobem:
export DATA_SOURCE="https://raw.githubusercontent.com/mspnp/spark-monitoring/master/perftools/deployment/grafana/AzureDataSource.sh" az deployment group create \ --resource-group <resource-group-name> \ --template-file grafanaDeploy.json \ --parameters adminPass='<vm password>' dataSource=$DATA_SOURCE
Po dokončení nasazení se na virtuálním počítači nainstaluje bitnami image Grafany.
Aktualizace hesla Grafany
Instalační skript Grafana v rámci procesu nastavení vypíše dočasné heslo pro uživatele s rolí správce . K přihlášení potřebujete toto dočasné heslo. Chcete-li získat dočasné heslo, postupujte takto:
- Přihlaste se k portálu Azure.
- Vyberte skupinu prostředků, ve které byly prostředky nasazeny.
- Vyberte virtuální počítač, na kterém byl grafana nainstalovaný. Pokud jste v šabloně nasazení použili výchozí název parametru, název virtuálního počítače je před názvem sparkmonitoring-vm-grafana.
- V části Podpora a řešení potíží otevřete stránku diagnostiky spouštění kliknutím na diagnostiku spouštění.
- Klikněte na sériový protokol na stránce diagnostiky spouštění.
- Vyhledejte následující řetězec: "Nastavení hesla aplikace Bitnami na".
- Zkopírujte heslo do bezpečného umístění.
Dále změňte heslo správce Grafana pomocí následujícího postupu:
- Na webu Azure Portal vyberte virtuální počítač a klikněte na Přehled.
- Zkopírujte veřejnou IP adresu
- Otevřete webový prohlížeč a přejděte na následující adresu URL:
http://<IP address>:3000. - Na přihlašovací obrazovce Grafana zadejte správce uživatelského jména a použijte heslo Grafana z předchozích kroků.
- Po přihlášení vyberte Možnost Konfigurace (ikona ozubeného kola).
- Vyberte Správce serveru.
- Na kartě Uživatelé vyberte přihlašovací jméno správce.
- Aktualizujte heslo.
Vytvoření zdroje dat azure Monitoru
Vytvořte instanční objekt, který grafana umožňuje spravovat přístup k pracovnímu prostoru služby Log Analytics. Další informace najdete v tématu Vytvoření instančního objektu Azure pomocí Azure CLI.
az ad sp create-for-rbac --name http://<service principal name> \ --role "Log Analytics Reader" \ --scopes /subscriptions/mySubscriptionIDPoznamenejte si hodnoty appId, password a tenant ve výstupu tohoto příkazu:
{ "appId": "xxxxxxxx-xxxx-xxxx-xxxx-xxxxxxxxxxxx", "displayName": "azure-cli-2019-03-27-00-33-39", "name": "http://<service principal name>", "password": "xxxxxxxx-xxxx-xxxx-xxxx-xxxxxxxxxxxx", "tenant": "xxxxxxxx-xxxx-xxxx-xxxx-xxxxxxxxxxxx" }Přihlaste se k Grafana, jak je popsáno výše. Vyberte Možnost Konfigurace (ikona ozubeného kola) a potom Zdroje dat.
Na kartě Zdroje dat klikněte na Přidat zdroj dat.
Jako typ zdroje dat vyberte Azure Monitor .
V části Nastavení zadejte název zdroje dat do textového pole Název.
V části Podrobnosti rozhraní API služby Azure Monitor zadejte následující informace:
- ID předplatného: ID vašeho předplatného Azure.
- ID tenanta: ID tenanta z dřívější verze.
- ID klienta: Hodnota appId z dřívější verze.
- Tajný klíč klienta: Hodnota "password" z dřívější verze.
V části Podrobnosti rozhraní API služby Azure Log Analytics zaškrtněte políčko Stejné podrobnosti jako rozhraní API služby Azure Monitor.
Klikněte na Uložit a otestovat. Pokud je zdroj dat Log Analytics správně nakonfigurovaný, zobrazí se zpráva o úspěchu.
Vytvoření řídicího panelu
Pomocí následujícího postupu vytvořte řídicí panely v Grafaně:
Přejděte do
/perftools/dashboards/grafanaadresáře v místní kopii úložiště GitHub.Spusťte tento skript:
export WORKSPACE=<your Azure Log Analytics workspace ID> export LOGTYPE=SparkListenerEvent_CL sh DashGen.shVýstupem skriptu je soubor s názvem SparkMonitoringDash.json.
Vraťte se na řídicí panel Grafana a vyberte Vytvořit (ikona plus).
Vyberte Importovat.
Klikněte na Nahrát .json soubor.
Vyberte soubor SparkMonitoringDash.json vytvořený v kroku 2.
V části Možnosti v části ALA vyberte dříve vytvořený zdroj dat služby Azure Monitor.
Klepněte na tlačítko Import.
Vizualizace na řídicích panelech
Řídicí panely Azure Log Analytics i Grafana zahrnují sadu vizualizací časových řad. Každý graf je graf časových řad dat metrik souvisejících s úlohou Apache Sparku, fázemi úlohy a úkoly, které tvoří každou fázi.
Vizualizace jsou:
Latence úlohy
Tato vizualizace ukazuje latenci provádění úlohy, což je hrubý pohled na celkový výkon úlohy. Zobrazí dobu trvání provádění úlohy od začátku do dokončení. Všimněte si, že čas zahájení úlohy není stejný jako čas odeslání úlohy. Latence je reprezentována jako percentily (10 %, 30 %, 50 %, 90 %) provádění úloh indexovaných podle ID clusteru a ID aplikace.
Latence fáze
Vizualizace ukazuje latenci jednotlivých fází na cluster, aplikaci a jednotlivé fáze. Tato vizualizace je užitečná pro identifikaci konkrétní fáze, která běží pomalu.
Latence úlohy
Tato vizualizace zobrazuje latenci provádění úloh. Latence je reprezentována jako percentil spouštění úloh na cluster, název fáze a aplikace.
Sum Task Execution per host
Tato vizualizace ukazuje součet latence spouštění úloh na hostitele spuštěného v clusteru. Zobrazení latence provádění úkolů na hostitele identifikuje hostitele, kteří mají mnohem vyšší celkovou latenci úkolů než ostatní hostitelé. To může znamenat, že úlohy byly neefektivní nebo nerovnoměrně distribuované na hostitele.
Metriky úloh
Tato vizualizace ukazuje sadu metrik spuštění pro provádění daného úkolu. Mezi tyto metriky patří velikost a doba trvání náhodného prohazování dat, doba trvání serializace a deserializačních operací a další. Úplnou sadu metrik zobrazíte v dotazu Log Analytics na panelu. Tato vizualizace je užitečná pro pochopení operací, které tvoří úkol, a identifikaci spotřeby prostředků jednotlivých operací. Špičky v grafu představují nákladné operace, které by se měly prozkoumat.
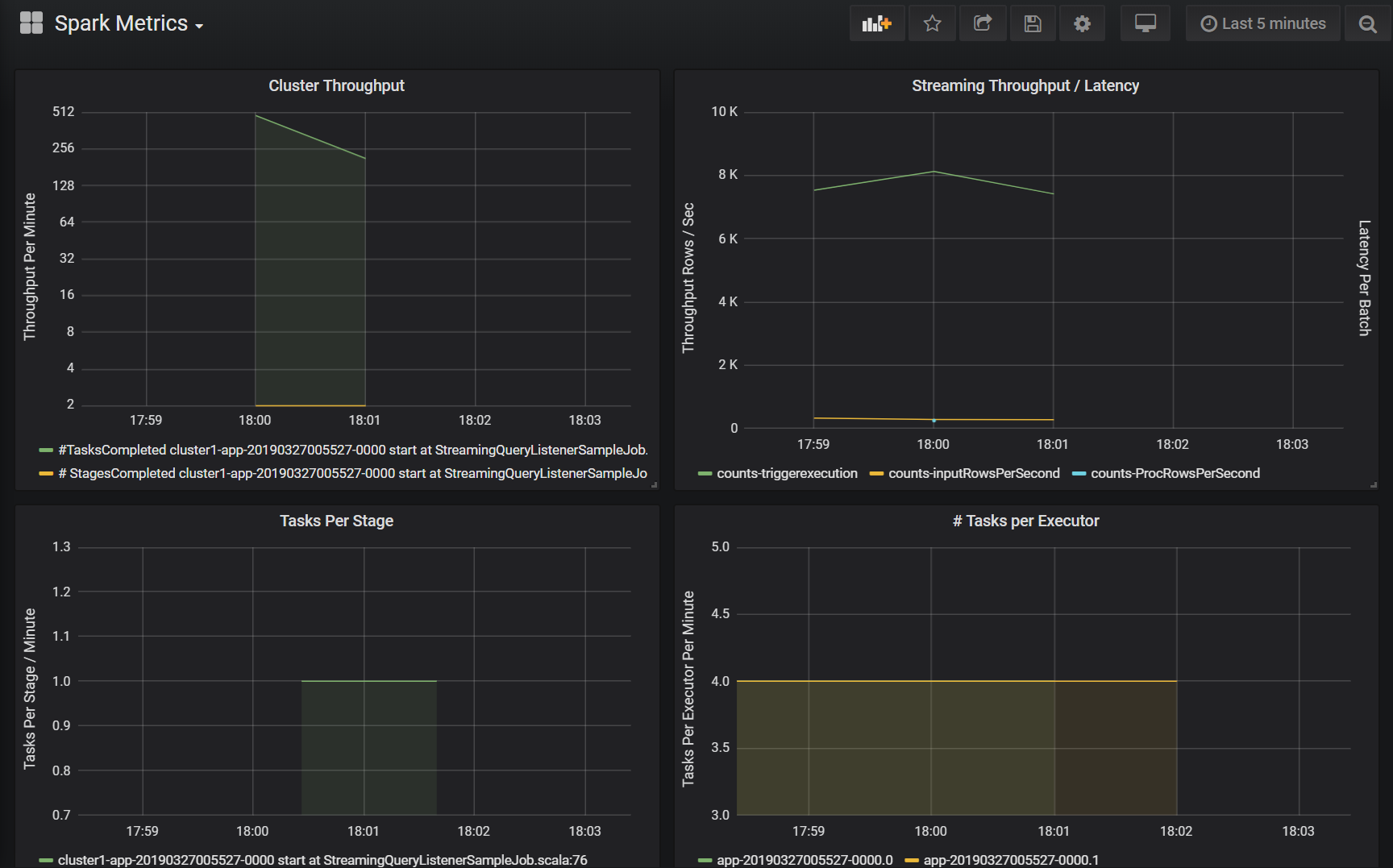
Propustnost clusteru
Tato vizualizace představuje základní zobrazení pracovních položek indexovaných clusterem a aplikací, které představují množství práce provedené na clusteru a aplikaci. Zobrazuje počet dokončených úloh, úkolů a fází na cluster, aplikaci a fázi v minutových přírůstcích.
Propustnost a latence streamování
Tato vizualizace souvisí s metrikami přidruženými k dotazu strukturovaného streamování. Graf zobrazuje počet vstupních řádků za sekundu a počet zpracovaných řádků za sekundu. Metriky streamování jsou také reprezentovány pro každou aplikaci. Tyto metriky se odesílají, když se událost OnQueryProgress vygeneruje při zpracování dotazu strukturovaného streamování a vizualizace představuje latenci streamování v milisekundách, než se provede dávka dotazu.
Spotřeba prostředků na exekutor
Dále je sada vizualizací řídicího panelu, které znázorňují konkrétní typ prostředku a způsob jeho využití pro každý exekutor v každém clusteru. Tyto vizualizace pomáhají identifikovat odlehlé hodnoty ve spotřebě prostředků na exekutor. Pokud je například přidělení práce pro konkrétní exekutor nerovnoměrné, spotřeba prostředků se zvýší ve vztahu k ostatním exekutorům spuštěným v clusteru. To je možné identifikovat špičkami ve spotřebě prostředků exekutoru.
Metriky výpočetního času exekutoru
Dále je sada vizualizací pro řídicí panel, které zobrazují poměr času serializace exekutoru, deserializace času, času procesoru a času virtuálního počítače Java na celkovou výpočetní dobu exekutoru. To ukazuje vizuálně, kolik každé z těchto čtyř metrik přispívá ke zpracování celkového exekutoru.
Metriky náhodného náhodného prohazu
Poslední sada vizualizací zobrazuje metriky náhodného prohazování dat přidružené k strukturovanému streamovacímu dotazu napříč všemi exekutory. Mezi ně patří čtení bajtů náhodného náhodného prohazení, zamíchání paměti a využití disku v dotazech, kde se používá systém souborů.