Úspěch cloudového řešení závisí na jeho spolehlivosti. Spolehlivost může být široce definována jako pravděpodobnost, že systém funguje podle očekávání za zadaných podmínek prostředí v zadaném čase. SRE (Site Reliability Engineering) je sada principů a postupů pro vytváření škálovatelných a vysoce spolehlivých softwarových systémů. SRE se stále častěji používá při návrhu digitálních služeb k zajištění větší spolehlivosti.
Další informace o strategiích SRE najdete v tématu AZ-400: Vývoj strategie SRE (Site Reliability Engineering).
Potenciální případy použití
Koncepty v tomto článku platí pro:
- Cloudové služby založené na rozhraní API.
- Veřejné webové aplikace.
- Úlohy založené na IoT nebo na událostech
Architektura

Stáhněte si soubor PowerPointu této architektury.
Architektura, která je zde považována za škálovatelnou platformu rozhraní API. Řešení se skládá z několika mikroslužeb, které používají celou řadu databází a služeb úložiště, včetně řešení SaaS (software jako služba), jako jsou Dynamics 365 a Microsoft 365.
Tento článek se domnívá, že řešení, které zpracovává případy použití marketplace vysoké úrovně a elektronického obchodování, ukazuje bloky zobrazené v diagramu. Případy použití:
- Procházení produktu.
- Registrace a přihlášení.
- Zobrazení obsahu, jako jsou články s příspěvky
- Správa objednávek a předplatných
Klientské aplikace, jako jsou webové aplikace, mobilní aplikace a dokonce i aplikace služeb, využívají služby platformy API prostřednictvím sjednocené přístupové cesty. https://api.contoso.com
Komponenty
- Azure Front Door poskytuje zabezpečený jednotný vstupní bod pro všechny požadavky na řešení. Další informace najdete v tématu Přehled architektury směrování.
- Azure API Management poskytuje vrstvu zásad správného řízení nad všemi publikovanými rozhraními API. Pomocí zásad služby Azure API Management můžete použít další funkce na vrstvě rozhraní API, jako jsou omezení přístupu, ukládání do mezipaměti a transformace dat. API Management podporuje automatické škálování na úrovních Standard a Premium.
- Azure Kubernetes Service (AKS) je implementace opensourcových clusterů Kubernetes v Azure. Azure jako hostovaná služba Kubernetes zpracovává důležité úlohy, jako je monitorování stavu a údržba. Vzhledem k tomu, že hlavní servery Kubernetes spravuje Azure, spravujete a udržujete pouze uzly agenta. V této architektuře jsou všechny mikroslužby nasazené v AKS.
- Aplikace Azure lication Gateway je služba kontroleru doručování aplikací. Funguje ve vrstvě 7, aplikační vrstvě a má různé možnosti vyrovnávání zatížení. Kontroler příchozího přenosu dat služby Application Gateway (AGIC) je aplikace Kubernetes, která zákazníkům Azure Kubernetes Service (AKS) umožňuje používat nativní nástroj pro vyrovnávání zatížení služby Application Gateway L7 pro Azure k zveřejnění cloudového softwaru na internetu. Automatické škálování a redundance zón se podporují ve skladové poště v2.
- Azure Storage, Azure Data Lake Storage, Azure Cosmos DB a Azure SQL můžou ukládat strukturovaný i nestrukturovaný obsah. Kontejnery a databáze Azure Cosmos DB je možné vytvořit s propustností automatického škálování.
- Microsoft Dynamics 365 je nabídka SaaS (software jako služba) od Microsoftu, která poskytuje několik obchodních aplikací pro zákaznické služby, prodej, marketing a finance. V této architektuře se Dynamics 365 primárně používá ke správě katalogů produktů a ke správě zákaznických služeb. Jednotky škálování poskytují odolnost vůči Dynamics 365 aplikacím.
- Microsoft 365 (dříve Office 365) se používá jako podnikový systém pro správu obsahu, který je založený na SharePointu Microsoftu 365 v Microsoftu 365. Slouží k vytváření, správě a publikování obsahu, jako jsou mediální prostředky a dokumenty.
Alternativy
Vzhledem k tomu, že toto řešení používá vysoce škálovatelnou architekturu založenou na mikroslužbách, zvažte tyto alternativy pro výpočetní rovinu:
- Azure Functions pro bezserverové služby API
- Mikroslužby založené na Azure Spring Apps pro javu
Odpovídající spolehlivost
Míra spolehlivosti, která se vyžaduje pro řešení, závisí na obchodním kontextu. Maloobchodní prodejna, která je otevřená 14 hodin a má špičku využití systému v daném rozsahu, má jiné požadavky než online firma, která přijímá objednávky po celou dobu. Postupy SRE lze přizpůsobit tak, aby dosáhly odpovídající úrovně spolehlivosti.
Spolehlivost se definuje a měří pomocí cílů na úrovni služeb (cíle úrovně služeb), které definují cílovou úroveň spolehlivosti služby. Dosažení cílové úrovně zaručuje, že jsou spotřebitelé spokojení. Cíle SLO se mohou vyvíjet nebo měnit v závislosti na požadavcích firmy. Vlastnícislužebch služeb by ale měli neustále měřit spolehlivost s cílem zjistit problémy a provádět opravné akce. Cíle úrovně služeb se obvykle definují jako procento dosaženého cíle za určité období.
Dalším důležitým termínem, který je potřeba poznamenat, je ukazatel úrovně služby (SLI), což je metrika, která se používá k výpočtu cíle úrovně služby. Rozhraní SLA jsou založená na přehledech odvozených z dat zachycených při využívání služby zákazníkem. SLI se vždy měří z pohledu zákazníka.
SLO a SLI se vždy dají ruku v ruce a obvykle jsou definovány iterativním způsobem. SLO jsou řízeny klíčovými obchodními cíli, zatímco SLI jsou řízeny tím, co je možné měřit při implementaci služby.
Vztah mezi monitorovanou metrikou, SLI a SLO je znázorněn níže:
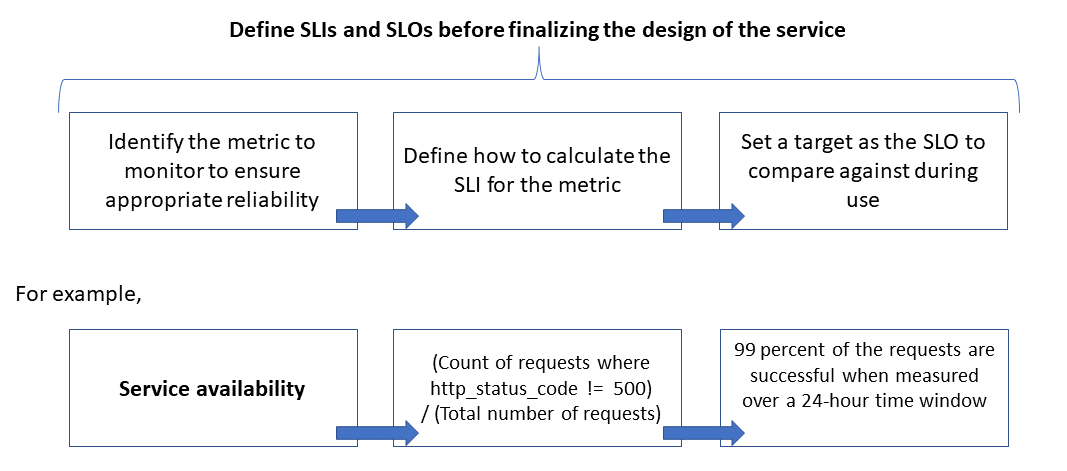
Toto je podrobněji vysvětleno v definici metrik SLI pro výpočet cílů úrovně služby.
Modelování očekávání škálování a výkonu
U softwarového systému obecně výkon odkazuje na celkovou odezvu systému při provádění akce v zadaném čase, zatímco škálovatelnost je schopnost systému zpracovávat zvýšené uživatelské zatížení bez snížení výkonu.
Systém se považuje za škálovatelný, pokud jsou podkladové prostředky zpřístupněny dynamicky, aby podporovaly zvýšení zatížení. Cloudové aplikace musí být navržené pro škálování a objem provozu je obtížné předpovědět v čase. Sezónní špičky můžou zvýšit požadavky na škálování, zejména když služba zpracovává požadavky pro více tenantů.
Vhodné je navrhovat aplikace tak, aby se cloudové prostředky automaticky navyšily a snížit podle potřeby, aby splňovaly zatížení. V podstatě by se systém měl přizpůsobit nárůstu úloh zřizováním nebo přidělováním prostředků přírůstkovým způsobem, aby splňoval poptávku. Škálovatelnost se týká nejen výpočetních instancí, ale i dalších prvků, jako je úložiště dat a infrastruktura zasílání zpráv.
Tento článek ukazuje, jak zajistit odpovídající spolehlivost cloudové aplikace provedením škálování a modelování výkonu scénářů úloh a použitím výsledků k definování monitorů, cílů úrovně služeb a cílů úrovně služeb.
Důležité informace
Pokyny k vytváření škálovatelných a spolehlivých aplikací najdete v pilířích spolehlivosti a efektivity výkonu architektury Azure Well Architected Framework.
Tento článek popisuje, jak použít techniky modelování škálovatelnosti a výkonu k vyladění architektury a návrhu řešení. Tyto techniky identifikují změny toků transakcí pro optimální uživatelské prostředí. Založte technická rozhodnutí na nefunkčních požadavcích řešení. Proces je následující:
- Identifikujte požadavky na škálovatelnost.
- Modelujte očekávané zatížení.
- Definujte rozhraní SLA a cíle úrovně služby pro uživatelské scénáře.
Poznámka:
Aplikace Azure lication Insights, součást služby Azure Monitor, je výkonný nástroj pro správu výkonu aplikací (APM), který můžete snadno integrovat s aplikacemi, abyste mohli odesílat telemetrická data a analyzovat metriky specifické pro aplikace. Poskytuje také připravené řídicí panely a průzkumník metriky, které můžete použít k analýze dat za účelem prozkoumání obchodních potřeb.
Zachycení požadavků na škálovatelnost
Předpokládejme tyto metriky zatížení ve špičce:
- Počet příjemců, kteří používají platformu API: 1,5 milionu
- Hodinově aktivní spotřebitelé (30 procent z 1,5 milionu): 450 000
- Procento zatížení pro každou aktivitu:
- Procházení produktů: 75 procent
- Registrace včetně vytvoření profilu a přihlášení: 10 procent
- Správa objednávek a předplatných: 10 procent
- Zobrazení obsahu: 5 procent
Zatížení vytváří následující požadavky na škálování za normálního zatížení ve špičce pro rozhraní API hostovaná platformou:
- Mikroslužba produktu: přibližně 500 požadavků za sekundu (RPS)
- Profilová mikroslužba: přibližně 100 RPS
- Objednávky a platební mikroslužba: přibližně 100 RPS
- Mikroslužba obsahu: přibližně 50 RPS
Tyto požadavky na škálování nebere v úvahu sezónní a náhodné špičky a špičky během zvláštních událostí, jako jsou marketingové propagační akce. Během špičky je požadavek na škálování některých uživatelských aktivit až 10krát vyšší než běžné zatížení ve špičce. Tato omezení a očekávání mějte na paměti při rozhodování o návrhu mikroslužeb.
Definování metrik SLI pro výpočet cílů úrovně služby
Metriky SLI označují stupeň, ve kterém služba poskytuje uspokojivé prostředí, a lze je vyjádřit jako poměr dobrých událostí k celkovým událostem.
U služby rozhraní API události odkazují na metriky specifické pro aplikaci, které se zaznamenávají během provádění jako telemetrie nebo zpracovávaná data. Tento příklad obsahuje následující metriky SLI:
| Metrický | Description |
|---|---|
| Dostupnost | Zda požadavek obsluhoval rozhraní API |
| Latence | Čas zpracování požadavku rozhraní API a vrácení odpovědi |
| Propustnost | Počet požadavků, které rozhraní API zpracovávalo |
| Úspěšnost | Počet požadavků, které rozhraní API úspěšně zpracoval |
| Míra chyb | Počet chyb pro požadavky, které rozhraní API zpracovávalo |
| Aktuálnost | Počet, kolikrát uživatel obdržel nejnovější data pro operace čtení v rozhraní API, i když se podkladové úložiště dat aktualizovalo s určitou latencí zápisu |
Poznámka:
Nezapomeňte identifikovat další rozhraní SLA, která jsou pro vaše řešení důležitá.
Tady jsou příklady SLI:
- (Počet úspěšně dokončených požadavků za méně než 1 000 ms) / (počet požadavků)
- (Počet výsledků hledání, které se vrátí do tří sekund, všechny produkty publikované v katalogu) / (počet hledání)
Jakmile definujete rozhraní SLA, určete, jaké události nebo telemetrie se mají zaznamenávat, aby se změřily. Pokud například chcete měřit dostupnost, zaznamenáte události, které indikují, jestli služba API úspěšně zpracovala požadavek. U služeb založených na protokolu HTTP je úspěch nebo selhání označený stavovými kódy HTTP. Návrh a implementace rozhraní API musí obsahovat správné kódy. Obecně platí, že metriky SLI jsou důležitým vstupem implementace rozhraní API.
U cloudových systémů můžete některé metriky získat pomocí podpory diagnostiky a monitorování, které jsou pro prostředky k dispozici. Azure Monitor je komplexní řešení pro shromažďování, analýzu a akce na telemetrii z vašich cloudových služeb. V závislosti na vašich požadavcích na SLI je možné zachytávat další data monitorování pro výpočet metrik.
Použití percentilových distribucí
Některé úrovně úrovně služeb se počítají pomocí techniky rozdělení percentilu. To poskytuje lepší výsledky, pokud existují odlehlé hodnoty, které mohou zkosit jiné techniky, jako jsou střední nebo medián distribuce.
Představte si například, že metrika je latence požadavků rozhraní API a tři sekundy představuje prahovou hodnotu pro optimální výkon. Seřazená doba odezvy po dobu jedné hodiny požadavků rozhraní API ukazuje, že několik požadavků trvá déle než tři sekundy a většina odpovědí obdrží v rámci limitu prahové hodnoty. Toto je očekávané chování systému.
Rozdělení percentilu je určené k vyloučení odlehlých hodnot způsobených přerušovanými problémy. Pokud jsou například správné odpovědi služby v 90. nebo 95. percentilu, považuje se cíl úrovně služby za splněný.
Volba správných měrných období
Období měření pro definování cíle úrovně služeb je velmi důležité. Aby výsledky byly smysluplné pro uživatelské prostředí, musí zaznamenávat aktivitu, nikoli nečinnost. V závislosti na tom, jak chcete monitorovat a vypočítat metriku SLI, může toto okno být pět minut až 24 hodin.
Vytvoření procesu zásad správného řízení výkonu
Výkon rozhraní API se musí spravovat z jeho počátku, dokud nebude zastaralý nebo vyřazený. Musí být zaveden robustní proces zásad správného řízení, aby se zajistilo, že se v rané fázi zjistí a opraví problémy s výkonem, než způsobí velký výpadek, který má vliv na firmu.
Tady jsou prvky zásad správného řízení výkonu:
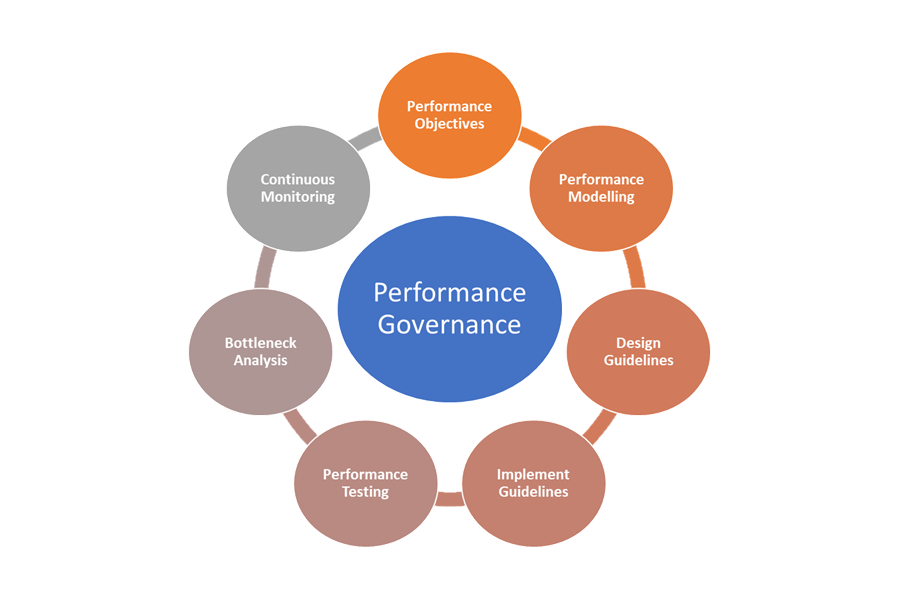
- Cíle výkonu: Definujte cíle výkonu pro obchodní scénáře.
- Modelování výkonu: Identifikace obchodních klíčových pracovních postupů a transakcí a provádění modelování za účelem pochopení dopadů souvisejících s výkonem Zachyťte tyto informace na podrobné úrovni pro přesnější předpovědi.
- Pokyny k návrhu: Připravte pokyny k návrhu výkonu a doporučte vhodné úpravy obchodních pracovních postupů. Zajistěte, aby týmy porozuměly těmto pokynům.
- Implementujte pokyny: Implementujte pokyny pro návrh výkonu pro komponenty řešení, včetně instrumentace pro zachycení metrik. Proveďte kontroly návrhu výkonu. Je důležité sledovat všechny tyto položky pomocí backlogu architektury pro různé týmy.
- Testování výkonu: Zátěžové a zátěžové testování proveďte v souladu s distribucí profilu zatížení za účelem zachycení metrik souvisejících se stavem platformy. Tyto testy můžete provést také pro omezené zatížení, abyste mohli testovat požadavky infrastruktury řešení.
- Analýza kritických bodů: Pomocí kontroly kódu a revizí kódu můžete identifikovat, analyzovat a odstraňovat kritické body výkonu v různých komponentách. Identifikujte vylepšení horizontálního nebo vertikálního škálování, která jsou potřebná k podpoře zatížení ve špičce.
- Průběžné monitorování: V rámci procesů DevOps vytvořte infrastrukturu průběžného monitorování a upozorňování. Ujistěte se, že příslušné týmy budou upozorněny, když se doba odezvy výrazně sníží oproti srovnávacím testům.
- Zásady správného řízení výkonu: Vytvořte zásady správného řízení výkonu, které se skládají z dobře definovaných procesů a týmů pro zajištění cílů úrovně výkonu. Sledujte dodržování předpisů po každé vydané verzi, abyste se vyhnuli snížení výkonu kvůli upgradům sestavení. Pravidelně provádí kontroly, které posoudí případné zvýšené zatížení a identifikují upgrady řešení.
Nezapomeňte kroky opakovat v průběhu vývoje řešení v rámci progresivního procesu zpracování.
Sledování cílů výkonu a očekávání v backlogu
Sledujte cíle výkonu, abyste zajistili jejich dosažení. Zachyťte podrobné a podrobné uživatelské scénáře ke sledování. To pomůže zajistit, aby vývojové týmy udělaly aktivity zásad správného řízení výkonu vysokou prioritou.
Vytvoření cílených cílů úrovně služby pro cílové řešení
Tady jsou ukázkové cíle úrovně služeb pro řešení platformy API, které je potřeba vzít v úvahu:
- Reaguje na 95 procent všech žádostí o čtení během jednoho dne během jedné sekundy.
- Reaguje na 95 procent všech požadavků CREATE a UPDATE během jednoho dne během tří sekund.
- Reaguje na 99 procent všech požadavků během jednoho dne během pěti sekund bez selhání.
- Reaguje na 99,9 % všech požadavků během dne během pěti minut.
- Méně než jedno procento požadavků během špičky 1hodinová chyba okna.
SLO je možné přizpůsobit tak, aby vyhovovaly konkrétním požadavkům aplikace. Je však důležité, aby byla dostatečně podrobná, aby byla jasná, aby byla zajištěna spolehlivost.
Měření počátečních cílů úrovně služby založené na datech z protokolů
Protokoly monitorování se vytvoří automaticky při použití služby API. Předpokládejme, že týden dat ukazuje následující:
- Žádosti: 123 456
- Úspěšné žádosti: 123 204
- 90. percentil latence: 497 ms
- Latence 95. percentilu: 870 ms
- 99. percentil latence: 1 024 ms
Tato data vytvářejí následující počáteční rozhraní SLA:
- Dostupnost = (123 204 / 123 456) = 99,8 procenta
- Latence = nejméně 90 procent požadavků se obsluhovalo během 500 ms.
- Latence = přibližně 98 procent požadavků se obsloužilo do 1 000 ms.
Předpokládejme, že v průběhu plánování cíl cíle na dosažení cíle cíle s cílem dosažení cíle s cílem dosažení maximální latence je 90 procent požadavků zpracováno do 500 ms s mírou úspěšnosti 99 procent za období jednoho týdne. S daty protokolu můžete snadno zjistit, jestli byl cíl cíle úrovně služby splněn. Pokud tento typ analýzy provedete několik týdnů, můžete začít sledovat trendy týkající se dodržování předpisů SLO.
Pokyny pro zmírnění technických rizik
Ke zmírnění škálovatelnosti a rizik výkonu použijte následující kontrolní seznam doporučených postupů:
- Návrh pro škálování a výkon
- Ujistěte se, že zachytáváte požadavky na škálování pro každý scénář a úlohy uživatelů, včetně sezónnosti a špiček.
- Modelování výkonu za účelem identifikace systémových omezení a kritických bodů
- Správa technického dluhu.
- Proveďte rozsáhlé trasování metrik výkonu.
- Zvažte použití skriptů ke spouštění nástrojů, jako jsou K6.io, Karate a JMeter ve vývojovém přípravném prostředí s rozsahem uživatelských zatížení – například 50 až 100 RPS. V protokolech se zobrazí informace o detekci problémů s návrhem a implementací.
- Integrujte automatizované testovací skripty jako součást procesů průběžného nasazování (CD) a detekujte přerušení sestavení.
- Mějte produkční myšlení.
- Upravte prahové hodnoty automatického škálování podle statistik stavu.
- Upřednostněte techniky horizontálního škálování před vertikálním.
- Buďte proaktivní díky škálování, abyste zvládli sezónnost.
- Upřednostněte nasazení založené na okruhu.
- Experimentujte pomocí rozpočtů chyb.
Ceny
Spolehlivost, efektivita výkonu a optimalizace nákladů jdou ruku v ruce. Služby Azure, které se používají v architektuře, pomáhají snížit náklady, protože se automaticky škálují tak, aby vyhovovaly měnícím se zatížením uživatelů.
V případě AKS můžete nejprve začít se standardními virtuálními počítači pro fond uzlů. Pak můžete monitorovat požadavky na prostředky během vývoje nebo produkčního použití a odpovídajícím způsobem je upravit.
Optimalizace nákladů je pilířem dobře architektuře Microsoft Azure. Další informace najdete v tématu Přehled pilíře optimalizace nákladů. Pokud chcete odhadnout náklady na produkty a konfigurace Azure, použijte cenovou kalkulačku.
Přispěvatelé
Tento článek spravuje Microsoft. Původně byla napsána následujícími přispěvateli.
Hlavní autor:
- Subhajit Chatterjee | Hlavní softwarový inženýr
Další kroky
- Dokumentace Azure
- Dobře navržená architektura Microsoft Azure
- Styl architektury mikroslužeb
- Návrh pro horizontální navýšení kapacity
- Volba výpočetní služby Azure pro vaši aplikaci
- Vzory návrhu a implementace
- Architektura mikroslužeb ve službě Azure Kubernetes Service
- Co je Azure Front Door?
- Informace o službě API Management
- Co je kontroler příchozího přenosu dat služby Application Gateway?
- Azure Kubernetes Service
- Automatické škálování a zónově redundantní služby Application Gateway v2
- Automatické škálování clusteru pro splnění požadavků aplikace ve službě Azure Kubernetes Service (AKS)
- Vytváření kontejnerů a databází Azure Cosmos DB s propustností automatického škálování
- Dokumentace k řešení Microsoft Dynamics 365
- Dokumentace k Microsoftu 365
- Dokumentace ke službě Site Reliability Engineering
- AZ-400: Vývoj strategie SRE (Site Reliability Engineering)
- Standardní webová aplikace s redundancí zón