Umělá inteligence nabízí potenciál transformace maloobchodního prodeje, jak ho dnes známe. Je rozumné se domnívat, že maloobchodní prodejci budou vyvíjet architekturu zkušeností zákazníků podporovanou AI. Některá očekávání jsou, že platforma vylepšená pomocí umělé inteligence zajistí nárůst výnosů z důvodu hyper personalizace. Digitální obchodování pokračuje ve zvýšeném očekávání zákazníků, preferencích a chování. Požadavky, jako je zapojení v reálném čase, relevantní doporučení a hyper-personalizace, jsou rychlost a pohodlí při kliknutí na tlačítko. Inteligentní funkce v aplikacích umožňujeme prostřednictvím přirozené řeči, zraku a tak dále. Tato inteligence umožňuje vylepšení maloobchodního prodeje, která zvýší hodnotu a zároveň naruší způsob, jakým zákazníci nakupují.
Tento dokument se zaměřuje na koncept vizuálního vyhledávání a nabízí několik klíčových aspektů jeho implementace. Poskytuje příklad pracovního postupu a mapuje své fáze na relevantní technologie Azure. Koncept je založený na tom, že zákazníci můžou využít image pořízenou s mobilním zařízením nebo umístěným na internetu. V závislosti na záměru prostředí by provedli vyhledávání relevantních a podobných položek. Vizuální vyhledávání tedy zlepšuje rychlost zadávání textu na obrázek s několika metadatnými body, aby se rychle vynoily všechny dostupné položky.
Vizuální vyhledávací weby
Vizuální vyhledávací weby načítají informace pomocí obrázků jako vstupu a často ( ale ne výhradně) jako výstupu.
Motory jsou stále častější a častější v maloobchodě, a to z velmi dobrých důvodů:
- Přibližně 75 % uživatelů internetu hledá obrázky nebo videa produktu před nákupem podle zprávy Emarketer publikované v roce 2017.
- 74 % spotřebitelů také najde neefektivní vyhledávání textu podle sestavy Slyce (společnost vizuálního vyhledávání) 2015.
Proto bude trh pro rozpoznávání obrazu v hodnotě více než 25 miliard DOLARŮ do roku 2019 podle výzkumu trhy a trhy.
Tato technologie již převzala hlavní značky elektronického obchodování, které také významně přispěly k jeho rozvoji. Nejvýraznější časná osvojovatelé jsou pravděpodobně:
- eBay s nástroji Hledání obrázků a "Najít v eBay" v aplikaci (to je momentálně jenom mobilní prostředí).
- Pinterest se svým nástrojem pro vizuální zjišťování lens.
- Microsoft s vizuálním vyhledáváním Bingu
Přijetí a přizpůsobení
Naštěstí nepotřebujete velké množství výpočetního výkonu, abyste mohli profitovat z vizuálního vyhledávání. Všechny firmy s katalogem imagí můžou využívat znalosti umělé inteligence Microsoftu integrované do svých služeb Azure.
Rozhraní API Pro vizuální vyhledávání Bingu poskytuje způsob, jak extrahovat kontextové informace z obrázků, identifikovat – například – domácí vybavení, módu, několik druhů produktů atd.
Bude také vracet vizuálně podobné obrázky z vlastního katalogu, produkty s relativními nákupními zdroji, související vyhledávání. I když je to zajímavé, bude to omezené použití, pokud vaše společnost není jedním z těchto zdrojů.
Bing také poskytne:
- Značky, které umožňují prozkoumat objekty nebo koncepty nalezené na obrázku.
- Ohraničující rámečky pro oblasti zájmu na obrázku (například pro oděvy nebo nábytek).
Tyto informace můžete vzít, abyste snížili prostor hledání (a čas) do katalogu produktů společnosti výrazně a omezili je na objekty, jako jsou objekty v oblasti a kategorii zájmu.
Implementace vlastního
Při implementaci vizuálního vyhledávání je potřeba zvážit několik klíčových komponent:
- Ingestování a filtrování obrázků
- Techniky ukládání a načítání
- Featurizace, kódování nebo "hashování"
- Míry podobnosti nebo vzdálenosti a hodnocení

Obrázek 1: Příklad kanálu vizuálního vyhledávání
Získání obrázků
Pokud katalog obrázků nevlastníte, možná budete muset vytrénovat algoritmy na veřejně dostupných datových sadách, jako je módní MNIST, hloubková móda atd. Obsahují několik kategorií produktů a běžně se používají k srovnávacímu kategorizaci obrázků a vyhledávacím algoritmům.

Obrázek 2: Příklad z datové sady DeepFashion
Filtrování obrázků
Většina srovnávacích datových sad, například dříve zmíněných, již byla předem zpracována.
Pokud vytváříte vlastní srovnávací test, minimálně budete chtít, aby image měly stejnou velikost, většinou určuje vstup, pro který je váš model natrénovaný.
V mnoha případech je nejlepší také normalizovat světelnost obrázků. V závislosti na úrovni podrobností hledání může být barva také redundantní informace, takže snížení na černou a bílou vám pomůže s dobou zpracování.
V neposlední řadě by datová sada obrázků měla být vyvážená mezi různými třídami, které představuje.
Image database
Datová vrstva je zvlášť citlivou součástí vaší architektury. Bude obsahovat:
- Obrázky
- Všechna metadata o obrázcích (velikost, značky, skladové položky produktu, popis)
- Data generovaná modelem strojového učení (například číselný vektor 4096 prvků na obrázek)
Při načítání obrázků z různých zdrojů nebo použití několika modelů strojového učení pro optimální výkon se struktura dat změní. Proto je důležité zvolit technologii nebo kombinaci, která se může zabývat částečně strukturovanými daty a bez pevného schématu.
Můžete také vyžadovat minimální počet užitečných datových bodů (například identifikátor obrázku nebo klíč, skladovou položku produktu, popis nebo pole značky).
Azure Cosmos DB nabízí požadovanou flexibilitu a různé mechanismy přístupu pro aplikace založené na ní (což vám pomůže s vyhledáváním v katalogu). Musíte ale dávat pozor, abyste dosáhli nejlepší ceny a výkonu. Azure Cosmos DB umožňuje ukládat přílohy dokumentů, ale pro každý účet existuje celkový limit a může se jednat o nákladnou nabídku. Běžným postupem je uložit skutečné soubory obrázků do objektů blob a vložit na ně do databáze odkaz. V případě služby Azure Cosmos DB to znamená vytvoření dokumentu, který obsahuje vlastnosti katalogu přidružené k tomuto obrázku (například skladovou položku, značku atd.) a přílohu, která obsahuje adresu URL souboru obrázku (například ve službě Azure Blob Storage, OneDrive atd.).
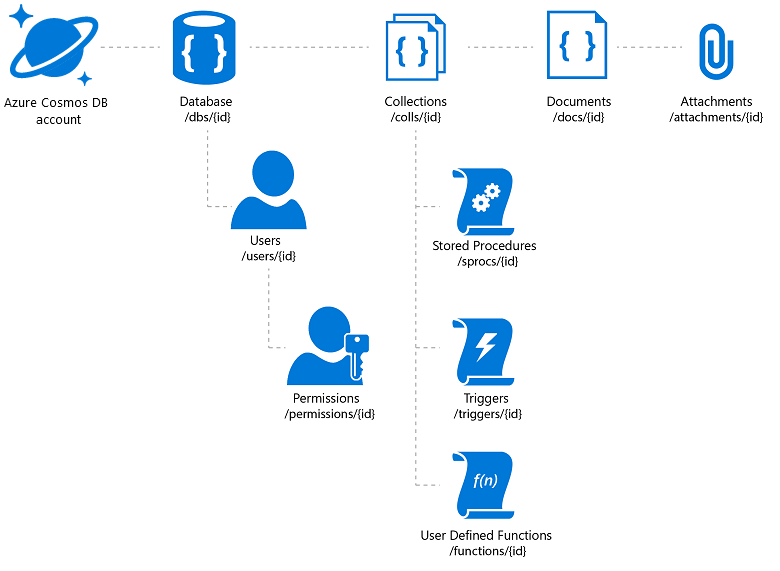
Obrázek 3: Hierarchický model prostředků služby Azure Cosmos DB
Pokud plánujete využít globální distribuci služby Azure Cosmos DB, mějte na paměti, že replikuje dokumenty a přílohy, ale ne propojené soubory. Pro tyto účely možná budete chtít zvážit distribuční síť obsahu.
Další použitelné technologie jsou kombinací služby Azure SQL Database (pokud je pevné schéma přijatelné) a objektů blob nebo dokonce tabulek a objektů blob Azure pro levné a rychlé ukládání a načítání.
Extrakce a kódování funkcí
Proces kódování extrahuje z obrázků v databázi určité prvky a mapuje je na řídký vektor "funkce" (vektor s mnoha nulami), který může mít tisíce komponent. Tento vektor je číselná reprezentace vlastností (například okrajů a obrazců), které charakterizují obrázek. Je to podobné kódu.
Techniky extrakce funkcí obvykle používají mechanismy transferového učení. K tomu dochází, když vyberete předem vytrénovanou neurální síť, spustíte každou image a uložíte vektor funkce vytvořený zpět v databázi obrázků. Tímto způsobem "přenášíte" učení od toho, kdo vytrénoval síť. Microsoft vyvinul a publikoval několik předem natrénovaných sítí, které se běžně používaly pro úlohy rozpoznávání obrázků, jako je ResNet50.
V závislosti na neurální síti bude vektor funkce delší nebo méně dlouhý a řídký, proto se požadavky na paměť a úložiště budou lišit.
Můžete také zjistit, že různé sítě se vztahují na různé kategorie, a proto implementace vizuálního vyhledávání může ve skutečnosti generovat vektory funkcí s různou velikostí.
Předem vytrénované neurální sítě se poměrně snadno používají, ale nemusí být tak efektivní jako vlastní model natrénovaný v katalogu obrázků. Tyto předem vytrénované sítě jsou obvykle určené pro klasifikaci datových sad srovnávacích testů, nikoli pro vyhledávání konkrétní kolekce obrázků.
Je možné, že je budete chtít upravit a znovu vytrénovat tak, aby vytvářely predikci kategorií i hustý vektor (tedy menší, řídký) vektor, který bude velmi užitečný k omezení vyhledávacího prostoru, snížení požadavků na paměť a úložiště. Binární vektory lze použít a často se označují jako " sémantická hodnota hash" – termín odvozený z technik kódování a načítání dokumentů. Binární reprezentace zjednodušuje další výpočty.

Obrázek 4: Úpravy resnetu pro vizuální vyhledávání – F. Yang et al., 2017
Bez ohledu na to, jestli zvolíte předem natrénované modely nebo budete vyvíjet vlastní, budete se muset rozhodnout, kde se má spustit featurizace a/nebo trénování samotného modelu.
Azure nabízí několik možností: virtuální počítače, Azure Batch, Batch AI, clustery Databricks. Ve všech případech je však nejlepší cena/výkon udělena použitím GRAFICKÝch procesorů.
Microsoft nedávno oznámil dostupnost FPGA pro rychlé výpočty za zlomek nákladů na GPU (projekt Brainwave). V době psaní tohoto článku je ale tato nabídka omezená na určité síťové architektury, takže budete muset pečlivě vyhodnotit jejich výkon.
Míra podobnosti nebo vzdálenost
Když jsou obrázky reprezentovány ve vektorovém prostoru funkce, hledání podobností se stává otázkou definování míry vzdálenosti mezi body v tomto prostoru. Po definování vzdálenosti můžete vypočítat clustery podobných imagí nebo definovat matice podobnosti. Výsledky se můžou lišit v závislosti na vybrané metrice vzdálenosti. Nejběžnější míra euklidovské vzdálenosti nad vektory reálného čísla je například snadno pochopitelná: zachycuje velikost vzdálenosti. Je ale poměrně neefektivní z hlediska výpočtů.
Kosinus vzdálenost se často používá k zachycení orientace vektoru místo jeho velikosti.
Alternativy, jako je vzdálenost Hamming nad binární reprezentací, obchodují s určitou přesností pro efektivitu a rychlost.
Kombinace velikosti vektoru a míry vzdálenosti určuje, jak bude hledání náročné na výpočet a paměť.
Hledání a řazení
Jakmile je definována podobnost, musíme navrhnout efektivní metodu pro načtení nejbližších N položek k té, která byla předána jako vstup, a pak vrátit seznam identifikátorů. To se také označuje jako "hodnocení obrázků". U velké datové sady je doba výpočtu každé vzdálenosti zakázána, takže používáme přibližné algoritmy nejbližšího souseda. Pro tyto knihovny existuje několik opensourcových knihoven, takže je nebudete muset zakódovat úplně od začátku.
Nakonec požadavky na paměť a výpočty určují volbu technologie nasazení pro natrénovaný model a také vysokou dostupnost. Obvykle bude vyhledávací prostor rozdělený na oddíly a několik instancí algoritmu řazení se spustí paralelně. Jednou z možností, která umožňuje škálovatelnost a dostupnost, je clustery Azure Kubernetes . V takovém případě je vhodné nasadit model řazení napříč několika kontejnery (zpracování oddílu vyhledávacího prostoru každý) a několik uzlů (pro zajištění vysoké dostupnosti).
Přispěvatelé
Tento článek spravuje Microsoft. Původně byla napsána následujícími přispěvateli.
Hlavní autoři:
- Giovanni Marchetti | Manager, architekti řešení Azure
- Mariya Zorotovich | Vedoucí zákaznického prostředí, HLS a vznikající technologie
Další přispěvatelé:
- Scott Seely | Softwarový architekt
Další kroky
Implementace vizuálního vyhledávání nemusí být složitá. Bing můžete používat nebo si vytvářet vlastní služby Azure a využívat přitom výzkum a nástroje AI od Microsoftu.
Vývoj
- Pokud chcete začít vytvářet přizpůsobenou službu, podívejte se na přehled rozhraní API vizuálního vyhledávání Bingu.
- Pokud chcete vytvořit první požadavek, projděte si rychlé starty: C# | Java | Node.js Python |
- Seznamte se s referenčními informacemi k rozhraní API pro vizuální vyhledávání.
Pozadí
- Segmentace obrázků hlubokého učení: Dokument Microsoftu popisuje proces oddělení obrázků od pozadí.
- Vizuální vyhledávání na Ebay: Cornell University research
- Visual Discovery ve společnosti Pinterest Cornell University research
- Sémantická hashingová univerzita v Toronto výzkum