Komunikace mezi mikroslužbami musí být efektivní a robustní. Díky spoustě malých služeb, které pracují na dokončení jedné obchodní aktivity, může to být výzva. V tomto článku se podíváme na kompromisy mezi asynchronním zasíláním zpráv a synchronními rozhraními API. Pak se podíváme na některé problémy při navrhování odolné komunikace mezi službami.
Výzvy
Tady jsou některé z hlavních problémů vyplývajících z komunikace mezi službami. Sítě služeb popsané dále v tomto článku jsou navržené tak, aby zvládly řadu těchto problémů.
Odolnost. Může existovat desítky nebo dokonce stovky instancí jakékoli dané mikroslužby. Instance může selhat z libovolného počtu důvodů. Může dojít k selhání na úrovni uzlu, jako je selhání hardwaru nebo restartování virtuálního počítače. Instance může dojít k chybovému ukončení nebo zahlcení žádostmi a nemůže zpracovat žádné nové žádosti. Některé z těchto událostí můžou způsobit selhání síťového volání. Existují dva vzory návrhu, které můžou pomoct, aby síťová volání mezi službami byla odolnější:
Opakování. Síťové volání může selhat kvůli přechodné chybě, která zmizí sama o sobě. Místo toho, aby selhálo přímo, volající by obvykle měl operaci opakovat určitou dobu nebo až do uplynutí nakonfigurovaného časového limitu. Pokud však operace není idempotentní, může opakování způsobit nežádoucí vedlejší účinky. Původní volání může být úspěšné, ale volající nikdy nedostane odpověď. Pokud volající opakuje pokusy, může být operace vyvolána dvakrát. Obecně platí, že není bezpečné opakovat metody POST nebo PATCH, protože tyto metody nejsou zaručeny idempotentní.
Jistič. Příliš mnoho neúspěšných požadavků může způsobit kritický bod, protože čekající požadavky se hromadí ve frontě. Tyto blokované požadavky můžou blokovat důležité systémové prostředky jako paměť vlákna, připojení k databázím atd., což může způsobit další chyby. Model Jistič může bránit službě v opakovaném pokusu o operaci, která pravděpodobně selže.
Vyrovnávání zatížení. Když služba "A" volá službu "B", požadavek musí kontaktovat spuštěnou instanci služby "B". V Kubernetes Service poskytuje typ prostředku stabilní IP adresu pro skupinu podů. Síťový provoz na IP adresu služby se přesměruje na pod pomocí pravidel iptable. Ve výchozím nastavení se vybere náhodný pod. Síť služeb (viz níže) může poskytovat inteligentnější algoritmy vyrovnávání zatížení na základě pozorované latence nebo jiných metrik.
Distribuované trasování Jedna transakce může zahrnovat více služeb. To může ztížit monitorování celkového výkonu a stavu systému. I když každá služba generuje protokoly a metriky bez nějakého způsobu jejich propojení, jsou omezené použití. Článek Protokolování a monitorování se zabývá distribuovaným trasováním, ale zde je zmíníme jako výzvu.
Správa verzí služby. Když tým nasadí novou verzi služby, musí se vyhnout narušení jiných služeb nebo externích klientů, kteří na ní závisejí. Kromě toho můžete chtít spustit více verzí služby vedle sebe a směrovat požadavky na konkrétní verzi. Další informace o tomto problému najdete v tématu Správa verzí rozhraní API.
Šifrování TLS a vzájemné ověřování TLS. Z bezpečnostních důvodů můžete chtít šifrovat provoz mezi službami pomocí protokolu TLS a použít vzájemné ověřování TLS k ověřování volajících.
Synchronní a asynchronní zasílání zpráv
Existují dva základní vzory zasílání zpráv, které mikroslužby můžou použít ke komunikaci s jinými mikroslužbami.
Synchronní komunikace. V tomto vzoru služba volá rozhraní API, které jiná služba zveřejňuje, pomocí protokolu, jako je HTTP nebo gRPC. Tato možnost je synchronní vzor zasílání zpráv, protože volající čeká na odpověď příjemce.
Asynchronní předávání zpráv V tomto vzoru služba odesílá zprávu bez čekání na odpověď a jedna nebo více služeb zprávu zpracovává asynchronně.
Je důležité rozlišovat mezi asynchronními vstupně-výstupními operacemi a asynchronním protokolem. Asynchronní vstupně-výstupní operace znamená, že volající vlákno není blokováno během dokončení vstupně-výstupních operací. To je důležité pro výkon, ale je to detail implementace z hlediska architektury. Asynchronní protokol znamená, že odesílatel nečeká na odpověď. HTTP je synchronní protokol, i když klient HTTP může při odesílání požadavku použít asynchronní vstupně-výstupní operace.
Každý vzor má kompromisy. Požadavek/odpověď je dobře pochopitelné paradigma, takže návrh rozhraní API může být přirozenější než návrh systému zasílání zpráv. Asynchronní zasílání zpráv má ale některé výhody, které můžou být užitečné v architektuře mikroslužeb:
Snížená spojka. Odesílatel zprávy nemusí o příjemci vědět.
Více odběratelů. Pomocí pub/dílčího modelu se může přihlásit více uživatelů k odběru událostí. Viz styl architektury řízené událostmi.
Izolace selhání Pokud příjemce selže, může odesílatel dál posílat zprávy. Zprávy se převezmou, jakmile se příjemce obnoví. Tato schopnost je zvlášť užitečná v architektuře mikroslužeb, protože každá služba má svůj vlastní životní cyklus. Služba může být kdykoli nedostupná nebo může být nahrazena novější verzí. Asynchronní zasílání zpráv může zpracovávat občasné výpadky. Synchronní rozhraní API na druhé straně vyžadují, aby podřízená služba byla dostupná nebo operace selže.
Rychlost odezvy. Upstreamová služba může rychleji odpovědět, pokud nečeká na podřízené služby. To je užitečné zejména v architektuře mikroslužeb. Pokud existuje řetěz závislostí služeb (služba A volá B, která volá C atd.), může čekání na synchronní volání přidat nepřijatelné množství latence.
Vyrovnávání zátěže. Fronta může fungovat jako vyrovnávací paměť pro vyrovnání úlohy, aby příjemci mohli zpracovávat zprávy vlastní rychlostí.
Pracovní postupy. Fronty lze použít ke správě pracovního postupu tak, že po každém kroku pracovního postupu nasměruje na zprávu.
Existuje však také několik problémů s efektivním používáním asynchronního zasílání zpráv.
Párování s infrastrukturou zasílání zpráv. Použití konkrétní infrastruktury zasílání zpráv může způsobit úzkou vazbu s danou infrastrukturou. Později bude obtížné přepnout na jinou infrastrukturu zasílání zpráv.
Latence. Koncová latence operace se může stát vysokou, pokud se fronty zpráv zaplní.
Náklady: Při vysoké propustnosti můžou být peněžní náklady na infrastrukturu zasílání zpráv významné.
Složitost: Zpracování asynchronního zasílání zpráv není triviální úlohou. Musíte například zpracovávat duplicitní zprávy, a to buď odstraněním duplicit, nebo vytvořením idempotentních operací. Je také obtížné implementovat sémantiku odpovědi na požadavky pomocí asynchronního zasílání zpráv. Pokud chcete odeslat odpověď, potřebujete další frontu a způsob korelace zpráv požadavků a odpovědí.
Propustnost. Pokud zprávy vyžadují sémantiku fronty, může se stát kritickým bodem v systému. Každá zpráva vyžaduje alespoň jednu operaci fronty a jednu operaci odstranění fronty. Kromě toho sémantika fronty obecně vyžaduje nějaký druh uzamčení uvnitř infrastruktury zasílání zpráv. Pokud je fronta spravovanou službou, může dojít k další latenci, protože fronta je externí pro virtuální síť clusteru. Tyto problémy můžete zmírnit dávkováním zpráv, ale tím se kód komplikuje. Pokud zprávy nevyžadují sémantiku fronty, můžete místo fronty použít stream událostí. Další informace najdete v tématu Styl architektury řízený událostmi.
Doručování pomocí dronů: Volba vzorů zasílání zpráv
Toto řešení používá příklad doručování pomocí dronů. Je ideální pro letecký a letecký průmysl.
S ohledem na tyto aspekty vývojový tým provedl následující volby návrhu aplikace pro doručování pomocí dronů:
Služba Ingestování zveřejňuje veřejné rozhraní REST API, které klientské aplikace používají k plánování, aktualizaci nebo rušení dodávek.
Služba Ingestování používá službu Event Hubs k odesílání asynchronních zpráv do služby Scheduler. Asynchronní zprávy jsou nezbytné k implementaci vyrovnávání zatížení, které je vyžadováno pro příjem dat.
Služba Account, Delivery, Package, Drone a Third-Party Transport services všechny zpřístupňují interní rozhraní REST API. Služba Scheduler volá tato rozhraní API k provedení žádosti uživatele. Jedním z důvodů použití synchronních rozhraní API je to, že plánovač potřebuje získat odpověď z každé podřízené služby. Selhání v některé z podřízených služeb znamená, že celá operace selhala. Potenciálním problémem je ale latence, která se zavádí voláním back-endových služeb.
Pokud některá podřízená služba nemá nepřehlednou chybu, měla by být celá transakce označena jako neúspěšná. Pro zpracování tohoto případu služba Scheduler odešle do správce asynchronní zprávu, aby správce mohl naplánovat kompenzační transakce.
Služba Delivery zveřejňuje veřejné rozhraní API, které můžou klienti použít k získání stavu doručení. V článku o bráně rozhraní API probereme, jak může brána rozhraní API skrýt základní služby od klienta, takže klient nemusí vědět, které služby zpřístupňují která rozhraní API.
Během letu dronů odesílá služba Drony události, které obsahují aktuální polohu a stav dronu. Služba doručování naslouchá těmto událostem, aby mohla sledovat stav doručení.
Když se stav doručení změní, služba doručení odešle událost stavu doručení, například
DeliveryCreatedneboDeliveryCompleted. K odběru těchto událostí se může přihlásit libovolná služba. V aktuálním návrhu je služba Historie doručení jediným odběratelem, ale později může existovat i další odběratelé. Události můžou například přejít do analytické služby v reálném čase. A protože plánovač nemusí čekat na odpověď, přidání dalších odběratelů nemá vliv na hlavní cestu pracovního postupu.
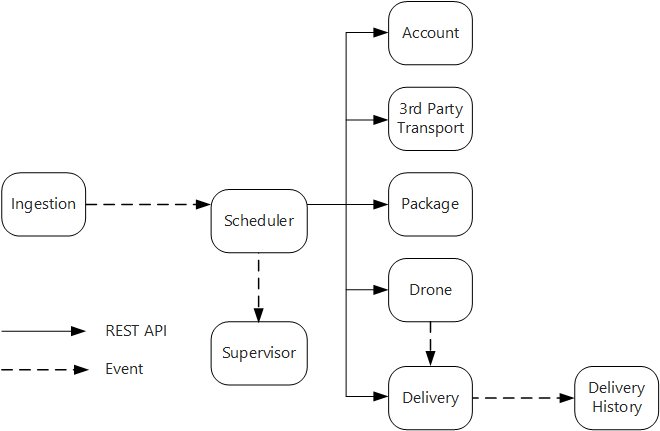
Všimněte si, že události stavu doručení jsou odvozené od událostí polohy dronů. Když například dron dosáhne místa doručení a vypustí balíček, služba Delivery service ji přeloží na událost DeliveryCompleted. Toto je příklad myšlení z hlediska doménových modelů. Jak je popsáno výše, správa dronů patří do samostatného vázaného kontextu. Události dronů vyjadřují fyzické umístění dronu. Na druhou stranu události doručení představují změny ve stavu doručení, což je jiná obchodní entita.
Použití sítě služeb
Síť služeb je softwarová vrstva, která zpracovává komunikaci mezi službami. Sítě služeb jsou navržené tak, aby řešily řadu problémů uvedených v předchozí části a přesunuly odpovědnost za tyto obavy mimo samotné mikroslužby a do sdílené vrstvy. Síť služeb funguje jako proxy server, který zachycuje síťovou komunikaci mezi mikroslužbami v clusteru. Koncept služby Mesh se v současné době vztahuje hlavně na orchestrátory kontejnerů, nikoli na bezserverové architektury.
Poznámka:
Síť služeb je příkladem vzoru Ambassador – pomocná služba, která odesílá síťové požadavky jménem aplikace.
Právě teď jsou hlavní možnosti sítě služeb v Kubernetes Linkerd a Istio. Obě tyto technologie se rychle vyvíjejí. Mezi běžné funkce linkerdu i Istio patří:
Vyrovnávání zatížení na úrovni relace na základě pozorovaných latencí nebo počtu nevyřízených požadavků To může zlepšit výkon vyrovnávání zatížení vrstvy 4, které poskytuje Kubernetes.
Směrování vrstvy 7 na základě cesty URL, hlavičky hostitele, verze rozhraní API nebo jiných pravidel na úrovni aplikace.
Zkuste neúspěšné žádosti zopakovat. Síť služeb rozumí kódům chyb HTTP a může automaticky opakovat neúspěšné požadavky. Můžete nakonfigurovat maximální počet opakovaných pokusů spolu s časovým limitem, abyste dosáhli maximální latence.
Jistič. Pokud instance konzistentně selže s požadavky, síť služeb ji dočasně označí jako nedostupnou. Po období zpětného ukončení se instance zkusí znovu. Jistič můžete nakonfigurovat na základě různých kritérií, jako je počet po sobě jdoucích selhání.
Síť služeb zaznamenává metriky o voláních mezislužeb, jako je objem požadavků, latence, míra chyb a úspěšnost a velikosti odpovědí. Síť služeb také umožňuje distribuované trasování přidáním informací o korelaci pro každý segment směrování v požadavku.
Vzájemné ověřování TLS pro volání mezi službami.
Potřebujete síť služeb? To záleží na okolnostech. Bez sítě služeb budete muset zvážit všechny výzvy uvedené na začátku tohoto článku. Můžete vyřešit problémy, jako je opakování, jistič a distribuované trasování bez sítě služeb, ale síť služeb tyto obavy přesouvá mimo jednotlivé služby a do vyhrazené vrstvy. Na druhou stranu síť služeb zvyšuje složitost nastavení a konfigurace clusteru. Může to mít vliv na výkon, protože požadavky se teď směrují přes proxy server sítě služeb a protože na každém uzlu v clusteru teď běží další služby. Před nasazením sítě služeb v produkčním prostředí byste měli provést důkladný výkon a zátěžové testování.
Distribuované transakce
Běžným problémem v mikroslužbách je správné zpracování transakcí, které pokrývají více služeb. V tomto scénáři je úspěch transakce vše nebo nic – pokud jedna ze zúčastněných služeb selže, musí celá transakce selhat.
Existují dva případy, které je potřeba vzít v úvahu:
U služby může docházet k přechodnému selhání, jako je vypršení časového limitu sítě. Tyto chyby je často možné vyřešit jednoduše opakovaným pokusem o volání. Pokud operace po určitém počtu pokusů stále selže, považuje se za netransientní selhání.
Netransientní selhání je jakékoli selhání, které se pravděpodobně samo o sobě neodejde. Mezi nepřehledná selhání patří normální chybové podmínky, jako je neplatný vstup. Zahrnují také neošetřené výjimky v kódu aplikace nebo chybové ukončení procesu. Pokud k tomuto typu chyby dojde, musí být celá obchodní transakce označena jako selhání. Může být nutné vrátit zpět další kroky ve stejné transakci, která již byla úspěšná.
Po nepřehledném selhání může být aktuální transakce v částečně neúspěšném stavu, kde jeden nebo více kroků již úspěšně dokončeno. Pokud například služba Dron už naplánovala dron, musí být dron zrušen. V takovém případě musí aplikace vrátit zpět kroky, které byly úspěšné, pomocí kompenzační transakce. V některých případech musí být tato akce provedena externím systémem nebo dokonce ručním procesem. Ve vašem návrhu nezapomeňte, že kompenzační míry jsou také předmětem selhání.
Pokud je logika kompenzačních transakcí složitá, zvažte vytvoření samostatné služby, která je zodpovědná za tento proces. V aplikaci pro doručování pomocí dronů služba Scheduler umístí neúspěšné operace do vyhrazené fronty. Samostatná mikroslužba, která se nazývá Supervisor, čte z této fronty a volá rozhraní API pro zrušení služeb, které potřebují kompenzovat. Jedná se o variantu vzoru Scheduler Agent Supervisor. Služba supervisor může také provádět jiné akce, například upozornit uživatele textem nebo e-mailem nebo odeslat upozornění na řídicí panel operací.
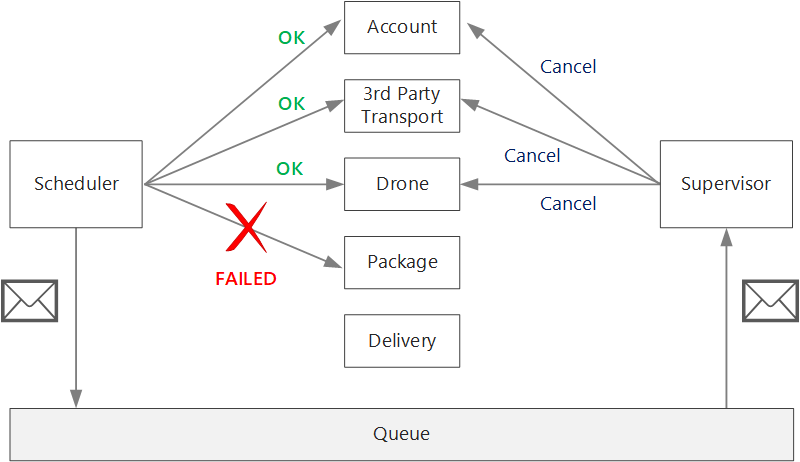
Samotná služba Scheduler může selhat (například kvůli chybovému ukončení uzlu). V takovém případě se může nová instance aktivovat a převzít. Všechny probíhající transakce však musí být obnoveny.
Jedním z přístupů je uložení kontrolního bodu do odolného úložiště po dokončení každého kroku pracovního postupu. Pokud dojde k chybovému ukončení instance služby Scheduler uprostřed transakce, může nová instance pomocí kontrolního bodu pokračovat tam, kde předchozí instance skončila. Zápis kontrolních bodů ale může způsobit režii na výkon.
Další možností je navrhnout všechny operace tak, aby byly idempotentní. Operace je idempotentní, pokud ji lze volat vícekrát, aniž by se po prvním volání vytvářely další vedlejší účinky. Podřízená služba by v podstatě měla ignorovat duplicitní volání, což znamená, že služba musí být schopná detekovat duplicitní volání. Není vždy jednoduché implementovat idempotentní metody. Další informace najdete v tématu Idempotentní operace.
Další kroky
U mikroslužeb, které spolu komunikují přímo, je důležité vytvořit dobře navržená rozhraní API.