Rozdělí úlohu, která provádí komplexní zpracování, do řady samostatných prvků, které je možné využít znovu. Tímto způsobem můžete zvýšit výkon, škálovatelnost a opětovnou použitelnost počátečních kroků tím, že povolíte prvky úloh, které provádějí nasazení a škálování nezávisle na sobě. Model potrubí a filtrů podporuje vysokou úroveň modularity.
Kontext a problém
Máte kanál sekvenčních úloh, které potřebujete zpracovat. Jednoduchý, ale nepružný přístup k implementaci této aplikace spočívá v provedení tohoto zpracování v monolitickém modulu. Tento přístup ale pravděpodobně sníží příležitosti k refaktoringu kódu, jeho optimalizaci nebo opakovanému použití, pokud se části stejného zpracování vyžadují jinde v aplikaci.
Následující diagram znázorňuje jeden z problémů se zpracováním dat pomocí monolitického přístupu, nemožnost opakovaně používat kód napříč několika kanály. V tomto příkladu aplikace přijímá a zpracovává data ze dvou zdrojů. Samostatný modul zpracovává data z každého zdroje provedením řady úloh, které transformují data před předáním výsledku do obchodní logiky aplikace.
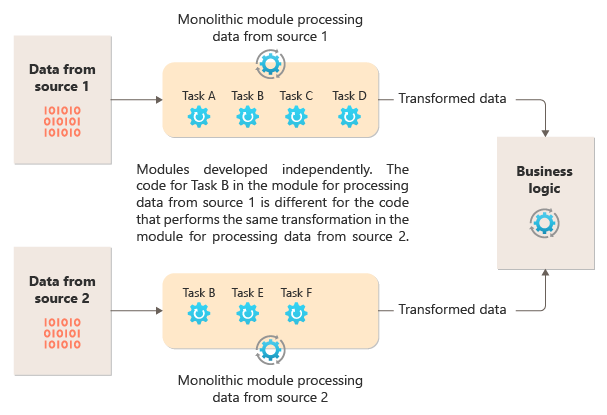
Některé úlohy, které monolitické moduly provádějí, jsou funkčně podobné, ale kód se musí opakovat v obou modulech a je pravděpodobně úzce svázán v rámci jeho modulu. Kromě nemožnosti opakovaně používat logiku představuje tento přístup riziko, když se požadavky změní. Nezapomeňte aktualizovat kód na obou místech.
Existují další problémy s monolitickou implementací nesouvisející s více kanály nebo opětovným použitím. Pomocí monolitu nemáte možnost spouštět konkrétní úlohy v různých prostředích nebo je škálovat nezávisle. Některé úlohy můžou být náročné na výpočetní výkon a můžou být užitečné z provozu na výkonném hardwaru nebo paralelně spuštěných více instancí. Jiné úkoly nemusí mít stejné požadavky. U monolitických objektů je navíc obtížné změnit pořadí úkolů nebo vložit do kanálu nové úlohy. Tyto změny vyžadují opětovné otestování celého kanálu.
Řešení
Zpracování potřebné pro každý datový proud rozdělte do sady samostatných částí (nebo filtrů), aby každá část prováděla jediný úkol. Složené úkoly by měly používat více filtrů než jeden. Filtry se skládají do kanálů propojením filtrů s kanály. Filtry jsou nezávislé, samostatné a obvykle bezstavové. Filtry přijímají zprávy z příchozího kanálu a publikují zprávy do jiného odchozího kanálu. Filtry můžou zprávu transformovat nebo testovat na základě jednoho nebo více kritérií, aby zahrnovaly podmíněnou logiku. Kanály neprovádějí směrování ani žádnou jinou logiku. Připojují pouze filtry a předávají výstupní zprávu z jednoho filtru jako vstup do dalšího.
Filtry fungují nezávisle a nejsou si vědomy jiných filtrů. Vědí jen o svých vstupních a výstupních schématech. Filtry se proto dají uspořádat v libovolném pořadí, pokud vstupní schéma pro jakýkoli filtr odpovídá výstupnímu schématu předchozího filtru. Použití standardizovaného schématu pro všechny filtry zlepšuje možnost změnit pořadí filtrů. Architektura kanálů a filtrů podporuje opětovné použití kompozičního prostředí.
Volné spojení filtrů usnadňuje:
- Vytvoření nových kanálů složených z existujících filtrů
- Aktualizace nebo nahrazení logiky v jednotlivých filtrech
- V případě potřeby přeuspořádat filtry
- V případě potřeby spusťte filtry na odlišném hardwaru.
- Paralelní spouštění filtrů
Tento diagram znázorňuje řešení implementované s kanály a filtry:
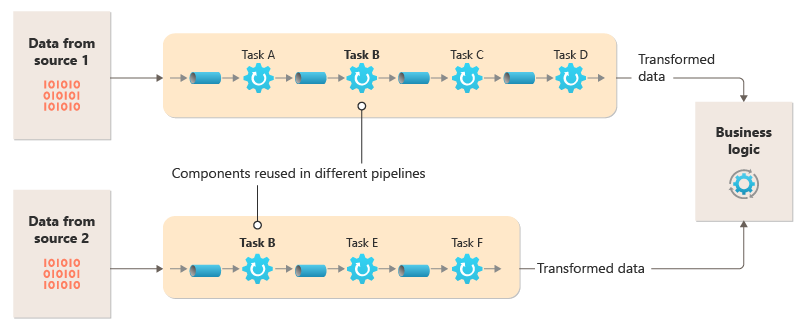
Doba potřebnou ke zpracování jednoho požadavku závisí na rychlosti nejpomalejších filtrů v kanálu. Jedním nebo více filtrům může být kritických bodů, zejména pokud se v datovém proudu z určitého zdroje dat zobrazuje velký počet požadavků. Schopnost spouštět paralelní instance pomalých filtrů umožňuje systému rozložit zatížení a zlepšit propustnost.
Možnost spouštět filtry v různých výpočetních instancích umožňuje nezávisle škálovat a využívat elasticitu, kterou poskytuje mnoho cloudových prostředí. Filtr, který je výpočetně náročný, může běžet na vysoce výkonném hardwaru, zatímco jiné méně náročné filtry je možné hostovat na levnějším komoditních hardwaru. Filtry nemusí být ani ve stejném datacentru nebo zeměpisném umístění, což umožňuje každému prvku v kanálu spustit v prostředí, které je blízko požadovaným prostředkům. Tyto snahy vyžadují specifické techniky návrhu, jako je zasílání zpráv, vícevláknové zpracování atd., aby se maximalizovala elasticita jednotlivých potrubí nebo filtrů. Tento diagram znázorňuje příklad použitý na kanál pro data ze zdroje 1:
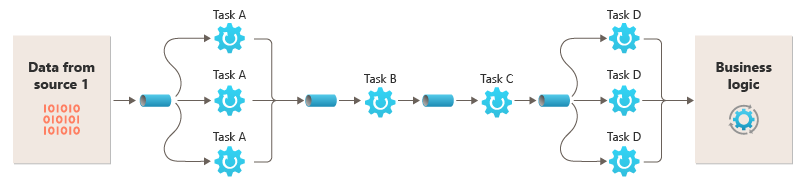
Pokud je vstup a výstup filtru strukturovaný jako datový proud, můžete provádět zpracování pro každý filtr paralelně. První filtr v kanálu může zahájit svou práci a vypíše výsledky, které se předají přímo dalšímu filtru v posloupnosti před tím, než první filtr dokončí svou práci.
Použití modelu Kanály a filtry společně s modelem kompenzační transakce je alternativní přístup k implementaci distribuovaných transakcí. Distribuovanou transakci můžete rozdělit do samostatných, komplementovatelných úloh, z nichž každý lze implementovat prostřednictvím filtru, který také implementuje model kompenzační transakce. Filtry můžete v kanálu implementovat jako samostatné hostované úlohy, které se spouštějí v blízkosti dat, která udržují.
Problémy a důležité informace
Při rozhodování o implementaci tohoto modelu zvažte následující body:
Monolitická povaha. Tento model se obvykle implementuje jako monolitický kanál, takže pro všechny změny by se celý řetěz filtrů měl testovat až do konce. Je také třeba zvážit odolnost proti chybám pro celý proces; pokud filtr nebo kanál selže, pravděpodobně selže celý kanál.
Složitost: zvýšená flexibilita, kterou tento model poskytuje, může mít také za následek komplikovanost, zvlášť pokud jsou filtry v kanálu distribuované napříč různými servery.
Spolehlivost. Použijte infrastrukturu, která zajišťuje, že se neztratí tok dat mezi filtry v kanálu.
Idempotence: Pokud filtr v kanálu selže po přijetí zprávy a práce se přeplánuje na jinou instanci filtru, část práce už může být dokončená. Pokud práce aktualizuje určitý aspekt globálního stavu (například informace uložené v databázi), může se jedna aktualizace opakovat. Podobný problém může nastat, pokud filtr selže, jakmile výsledky publikuje do dalšího filtru, ale před tím, než indikuje, že dokončil svou práci úspěšně. V těchto případech může tato práce opakovat jiná instance filtru, což způsobí, že se stejné výsledky publikují dvakrát. Tento scénář by mohl vést k následným filtrům při zpracování stejných dat dvakrát. Proto by filtry v kanálu měly být navržené tak, aby byly idempotentní. Další informace najdete v tématu Idempotency Patterns na blogu Jonathana Olivera.
Opakované zprávy: Pokud filtr v kanálu selže, jakmile odešle zprávu do další fáze kanálu, může se spustit jiná instance filtru a publikuje kopii stejné zprávy do kanálu. Tento scénář může způsobit předání dvou instancí stejné zprávy do dalšího filtru. Aby se zabránilo tomuto problému, kanál by měl rozpoznat a odstranit duplicitní zprávy.
Poznámka:
Pokud kanál implementujete pomocí front zpráv (jako jsou fronty služby Azure Service Bus), může infrastruktura front zpráv poskytovat automatickou detekci a odebrání duplicitních zpráv.
Kontext a stav: Každý filtr v kanálu v podstatě běží izolovaně a neměl by jakkoli předpokládat, jakým způsobem byl vyvolán. Každý filtr by proto měl být k dispozici s dostatečným kontextem k provádění své práce. Tento kontext může zahrnovat značné množství informací o stavu. Pokud filtry používají externí stav, například data v databázi nebo externím úložišti, musíte zvážit dopad na výkon. Každý filtr musí načíst, provozovat a zachovat tento stav, což zvyšuje režii nad řešeními, která načítají externí stav jednou.
Tolerance zpráv. Filtry musí být odolné vůči datům v příchozí zprávě, se kterými nepracují. Pracují s daty, která jsou pro ně relevantní, a ignorují ostatní data a předávají je beze změny ve výstupní zprávě.
Zpracování chyb – Každý filtr musí určit, co dělat v případě chyby způsobující chybu. Filtr musí určit, jestli kanál selže, nebo výjimku rozšíří.
Kdy se má tento model použít
Tento model použijte v těchto případech:
Zpracování vyžadované aplikací může být snadno rozloženo do sady nezávislých kroků.
Kroky zpracování prováděné aplikací mají jiné požadavky na škálovatelnost.
Poznámka:
Filtry, které by se měly škálovat společně ve stejném procesu, můžete seskupit. Další informace najdete v tématu o modelu výpočtu konsolidace prostředků.
Potřebujete flexibilitu, abyste umožnili změnit pořadí kroků zpracování, které aplikace provede, nebo povolit možnost přidávat a odebírat kroky.
Systém může mít užitek z distribuování zpracování pro kroky napříč různými servery.
Potřebujete spolehlivé řešení, které minimalizuje účinky selhání v kroku během zpracování dat.
Tento model nebude pravděpodobně vhodný v následujících případech:
Aplikace se řídí vzorem odpovědi na požadavek.
Zpracování úkolů musí být dokončeno jako součást počátečního požadavku, například scénáře požadavku nebo odpovědi.
Kroky zpracování prováděné aplikací nejsou nezávislé nebo musí být provedeny společně jako součást jedné transakce.
Množství kontextových nebo stavových informací, které krok vyžaduje, je tento přístup neefektivní. Je možné, že budete moct zachovat informace o stavu v databázi, ale tuto strategii nepoužívejte, pokud dodatečné zatížení databáze způsobí nadměrné kolize.
Návrh úloh
Architekt by měl vyhodnotit způsob použití modelu Kanály a filtry v návrhu úloh k řešení cílů a principů popsaných v pilířích architektury Azure Well-Architected Framework. Příklad:
| Pilíř | Jak tento model podporuje cíle pilíře |
|---|---|
| Rozhodnutí o návrhu spolehlivosti pomáhají vaší úloze stát se odolnou proti selhání a zajistit, aby se po selhání obnovila do plně funkčního stavu. | Jediná zodpovědnost každé fáze umožňuje zaměřit pozornost a vyhnout se rušivému kompingingu zpracování dat. - RE:01 Jednoduchost - RE:07 Úlohy na pozadí |
Stejně jako u jakéhokoli rozhodnutí o návrhu zvažte jakékoli kompromisy proti cílům ostatních pilířů, které by mohly být s tímto vzorem zavedeny.
Příklad
Abyste poskytli infrastrukturu potřebnou k implementaci kanálu, můžete použít sekvenci front zpráv. Počáteční fronta zpráv přijímá nezpracované zprávy, které se stanou začátkem implementace kanálů a filtrů vzorů. Komponenta implementovaná jako úloha filtru naslouchá zprávě v této frontě, provádí svou práci a pak publikuje novou nebo transformovanou zprávu do další fronty v pořadí. Další úloha filtru může naslouchat zprávám v této frontě, zpracovávat je, publikovat výsledky do jiné fronty atd. až do posledního kroku, který ukončí proces kanálů a filtrů. Tento diagram znázorňuje kanál, který používá fronty zpráv:

Pomocí tohoto vzoru je možné implementovat kanál zpracování obrázků. Pokud vaše úloha pořídí image, může image projít řadou z velké části nezávislých a změnit pořadí filtrů, aby bylo možné provádět například tyto akce:
- con režim stanu ration
- změna velikosti
- Vodotisk
- přeorientování
- Odebrání exif metadat
- Publikování sítě pro doručování obsahu (CDN)
V tomto příkladu je možné filtry implementovat jako jednotlivě nasazené funkce Azure Functions nebo dokonce jednu aplikaci Azure Functions, která obsahuje každý filtr jako izolované nasazení. Použití triggerů funkce Azure Functions, vstupních vazeb a výstupních vazeb může zjednodušit kód filtru a automaticky pracovat s kanálem založeným na frontě pomocí kontroly deklarací identity image, která se má zpracovat.

Tady je příklad toho, jak jeden filtr, implementovaný jako funkce Azure Functions, aktivovaný z kanálu Queue Storage s deklarací identity Zkontrolovat na obrázek, a zápis nové kontroly deklarací identity do jiného kanálu Queue Storage může vypadat. Nahradili jsme implementaci pseudokódem v komentářích za stručnost. Další kód podobný tomuto najdete v ukázce vzoru Kanály a filtry, který je k dispozici na GitHubu.
// This is the "Resize" filter. It handles claim checks from input pipe, performs the
// resize work, and places a claim check in the next pipe for anther filter to handle.
[Function(nameof(ResizeFilter))]
[QueueOutput("pipe-fjur", Connection = "pipe")] // Destination pipe claim check
public async Task<string> RunAsync(
[QueueTrigger("pipe-xfty", Connection = "pipe")] string imageFilePath, // Source pipe claim check
[BlobInput("{QueueTrigger}", Connection = "pipe")] BlockBlobClient imageBlob) // Image to process
{
_logger.LogInformation("Processing image {uri} for resizing.", imageBlob.Uri);
// Idempotency checks
// ...
// Download image based on claim check in queue message body
// ...
// Resize the image
// ...
// Write resized image back to storage
// ...
// Create claim check for image and place in the next pipe
// ...
_logger.LogInformation("Image resizing done or not needed. Adding image {filePath} into the next pipe.", imageFilePath);
return imageFilePath;
}
Poznámka:
Architektura spring integration framework má implementaci modelu kanálů a filtrů.
Další kroky
Při implementaci tohoto modelu můžou být užitečné následující zdroje informací:
- Ukázka vzoru kanálů a filtrů pomocí scénáře zpracování obrázků je k dispozici na GitHubu.
- Vzory idempotence na blogu Jonathana Olivera.
Související prostředky
Při implementaci tohoto modelu můžou být relevantní také následující vzory:
- Model kontroly deklarací identity Kanál implementovaný pomocí fronty nemusí obsahovat skutečnou položku odesílanou prostřednictvím filtrů, ale ukazatel na data, která je potřeba zpracovat. Příklad používá vrácení deklarace identity ve službě Azure Queue Storage pro obrázky uložené ve službě Azure Blob Storage.
- Model konkurenčních spotřebitelů: Kanál může obsahovat několik instancí jednoho nebo více filtrů. Tento přístup je užitečný pro spouštění paralelních instancí pomalých filtrů. Umožňuje systému rozložit zatížení a zlepšit propustnost. Každá instance filtru soupeří o vstup s ostatními instancemi, ale dvě instance filtru by neměly být schopny zpracovávat stejná data. Tento článek vysvětluje přístup.
- Model výpočtu konsolidace prostředků: Filtry, které by se měly škálovat do jednoho procesu, může být možné seskupit. Tento článek obsahuje další informace o výhodách a kompromisech této strategie.
- Model kompenzační transakce: Filtr můžete implementovat jako operaci, která se dá vrátit zpět nebo která má kompenzační operaci, která obnoví stav na předchozí verzi, pokud dojde k selhání. Tento článek vysvětluje, jak tento model implementovat za účelem zachování nebo dosažení konečné konzistence.
- Kanály a filtry – vzory podnikové integrace