Monitorování virtuálních počítačů s využitím služby Azure Monitor: Upozornění
Tento článek je součástí příručky Monitorování virtuálních počítačů a jejich úloh ve službě Azure Monitor. Výstrahy ve službě Azure Monitor proaktivně upozorňují na zajímavá data a vzory v datech monitorování. Neexistují žádná předem nakonfigurovaná pravidla upozornění pro virtuální počítače, ale můžete vytvořit vlastní na základě dat, která shromažďujete z agenta služby Azure Monitor. Tento článek obsahuje koncepty upozorňování specifické pro virtuální počítače a běžná pravidla upozornění používaná jinými zákazníky služby Azure Monitor.
Tento scénář popisuje, jak implementovat úplné monitorování prostředí azure a hybridního virtuálního počítače:
Pokud chcete začít monitorovat první virtuální počítač Azure, přečtěte si téma Monitorování virtuálních počítačů Azure.
Pokud chcete rychle povolit doporučenou sadu upozornění, přečtěte si téma Povolení doporučených pravidel upozornění pro virtuální počítač Azure.
Důležité
Většina pravidel upozornění má náklady, které závisí na typu pravidla, kolik dimenzí zahrnuje a jak často se spouští. Před vytvořením pravidel upozornění se podívejte na část Pravidla upozornění v cenách služby Azure Monitor.
Shromažďování dat
Pravidla upozornění kontrolují data, která už jsou shromážděná ve službě Azure Monitor. Před vytvořením pravidla upozornění musíte zajistit, aby se data shromáždila pro konkrétní scénář. Viz Monitorování virtuálních počítačů se službou Azure Monitor: Shromažďování dat pro pokyny ke konfiguraci shromažďování dat pro různé scénáře, včetně všech pravidel upozornění v tomto článku.
Doporučená pravidla upozornění
Azure Monitor poskytuje sadu doporučených pravidel upozornění, která můžete rychle povolit pro libovolný virtuální počítač Azure. Tato pravidla jsou skvělým výchozím bodem pro základní monitorování. Ale sami nebudou poskytovat dostatečná upozornění pro většinu podnikových implementací z následujících důvodů:
- Doporučená upozornění se vztahují pouze na virtuální počítače Azure, nikoli na hybridní počítače.
- Doporučená upozornění zahrnují pouze metriky hostitele, nikoli metriky nebo protokoly hosta. Tyto metriky jsou užitečné ke sledování stavu samotného počítače. Poskytují vám ale minimální přehled o úlohách a aplikacích spuštěných na počítači.
- Doporučené výstrahy jsou přidružené k jednotlivým počítačům, které vytvářejí nadměrný počet pravidel upozornění. Místo spoléhání na tuto metodu pro každý počítač najdete v tématu Pravidla upozornění škálování pro strategie použití minimálního počtu pravidel upozornění pro více počítačů.
Typy výstrah
Nejběžnější typy pravidel upozornění ve službě Azure Monitor jsou upozornění na metriky a upozornění prohledávání protokolů. Typ pravidla upozornění, které vytvoříte pro konkrétní scénář, závisí na tom, kde se nacházejí data, na kterých se nachází upozornění.
Můžete mít případy, kdy jsou data pro konkrétní scénář upozorňování dostupná v metrikách i protokolech. Pokud ano, musíte určit, jaký typ pravidla se má použít. Můžete mít také flexibilitu při shromažďování určitých dat a nechat rozhodnutí o typu pravidla upozornění řídit vaše rozhodnutí o metodě shromažďování dat.
Upozornění na metriky
Běžná použití pro upozornění na metriky:
- Upozornění, když konkrétní metrika překročí prahovou hodnotu Příkladem je vysoké využití procesoru počítače.
Zdroje dat pro upozornění metrik:
- Metriky hostitele pro virtuální počítače Azure, které se shromažďují automaticky
- Metriky shromážděné agentem Azure Monitoru z hostovaného operačního systému
Upozornění prohledávání protokolu
Běžná použití pro upozornění prohledávání protokolů:
- Výstraha, když se najde konkrétní událost nebo vzor událostí z protokolu událostí Systému Windows nebo Syslogu Tato pravidla upozornění obvykle měří řádky tabulky vrácené dotazem.
- Výstraha založená na výpočtu číselných dat na více počítačích Tato pravidla upozornění obvykle měří výpočet číselného sloupce ve výsledcích dotazu.
Zdroje dat pro upozornění prohledávání protokolů:
- Všechna data shromážděná v pracovním prostoru služby Log Analytics
Pravidla upozornění na škálování
Vzhledem k tomu, že můžete mít mnoho virtuálních počítačů, které vyžadují stejné monitorování, nechcete pro každou z nich vytvářet jednotlivá pravidla upozornění. Také chcete zajistit, aby existovaly různé strategie pro omezení počtu pravidel upozornění, která potřebujete spravovat, v závislosti na typu pravidla. Každá z těchto strategií závisí na pochopení cílového prostředku pravidla upozornění.
Pravidla upozornění metrik
Virtuální počítače podporují více pravidel upozornění na metriky prostředků, jak je popsáno v tématu Monitorování více prostředků. Tato funkce umožňuje vytvořit jedno pravidlo upozornění na metriku, které platí pro všechny virtuální počítače ve skupině prostředků nebo předplatném ve stejné oblasti.
Začněte doporučenými upozorněními a vytvořte pro každý z nich odpovídající pravidlo pomocí předplatného nebo skupiny prostředků jako cílového prostředku. Pokud máte počítače v několika oblastech, musíte pro každou oblast vytvořit duplicitní pravidla.
Při identifikaci požadavků na více pravidel upozornění na metriky použijte stejnou strategii pomocí předplatného nebo skupiny prostředků jako cílový prostředek:
- Minimalizujte počet pravidel upozornění, která potřebujete spravovat.
- Ujistěte se, že se automaticky použijí na všechny nové počítače.
Pravidla upozornění prohledávání protokolu
Pokud nastavíte cílový prostředek pravidla upozornění prohledávání protokolu na konkrétní počítač, dotazy jsou omezené na data přidružená k tomuto počítači, což vám poskytne jednotlivá upozornění. Toto uspořádání vyžaduje samostatné pravidlo upozornění pro každý počítač.
Pokud nastavíte cílový prostředek pravidla upozornění prohledávání protokolu na pracovní prostor služby Log Analytics, budete mít přístup ke všem datům v daném pracovním prostoru. Z tohoto důvodu můžete upozorňovat na data ze všech počítačů v pracovní skupině jediným pravidlem. Toto uspořádání vám umožňuje vytvořit pro všechny počítače jednu výstrahu. Dimenze pak můžete použít k vytvoření samostatné výstrahy pro každý počítač.
Můžete například chtít upozornit, když se v protokolu událostí Systému Windows vytvoří nějaká událost. Nejdřív musíte vytvořit pravidlo shromažďování dat, jak je popsáno v části Shromažďování dat pomocí agenta služby Azure Monitor, abyste tyto události odeslali do Event tabulky v pracovním prostoru služby Log Analytics. Pak vytvoříte pravidlo upozornění, které se na tuto tabulku dotazuje pomocí pracovního prostoru jako cílového prostředku a podmínky zobrazené na následujícím obrázku.
Dotaz vrátí záznam pro všechny chybové zprávy na libovolném počítači. Použijte možnost Rozdělit podle dimenzí a určete _ResourceId, aby pravidlo vytvořilo upozornění pro každý počítač, pokud se ve výsledcích vrátí více počítačů.
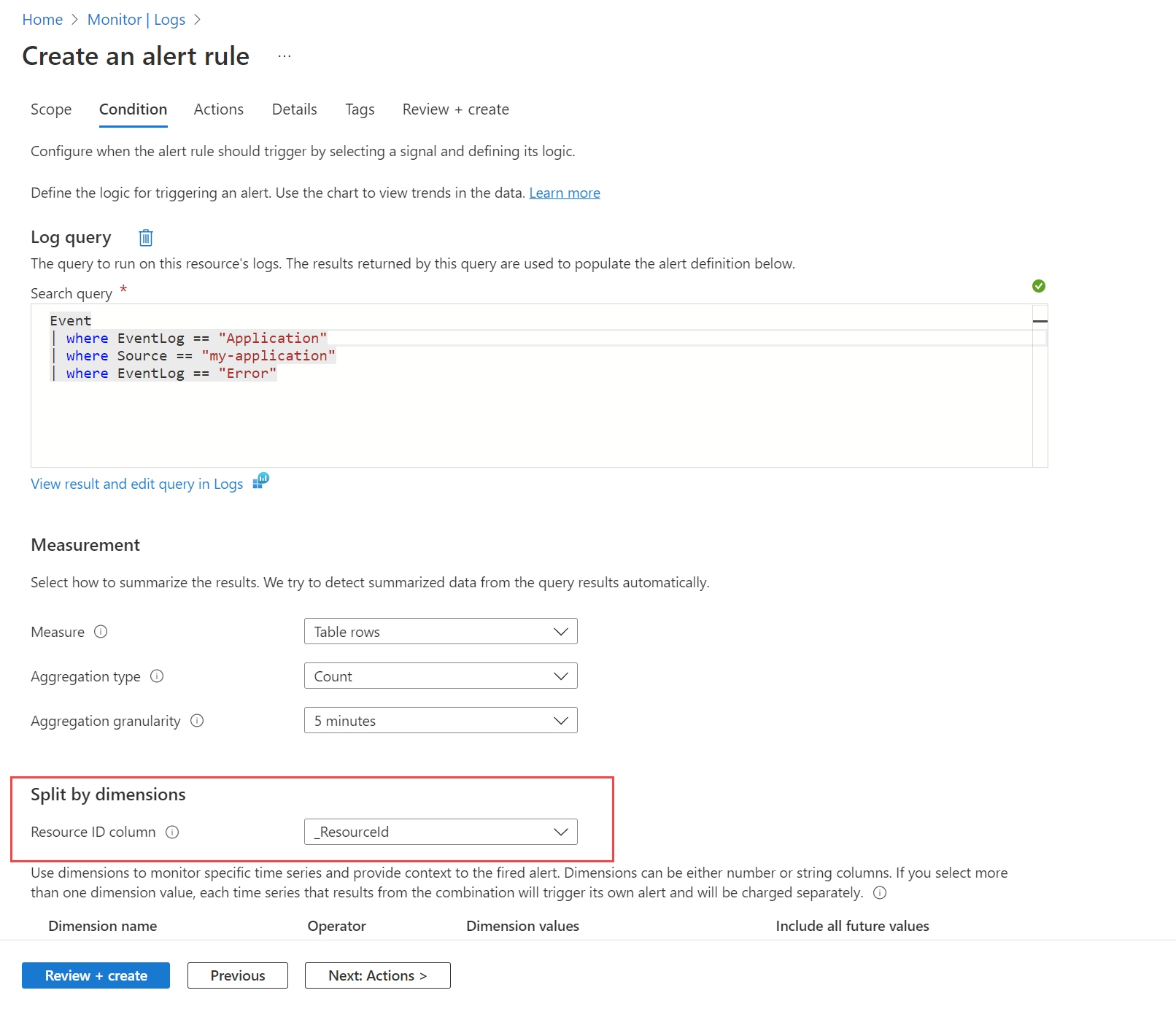
Dimenze
V závislosti na informacích, které chcete do výstrahy zahrnout, budete možná muset rozdělit pomocí různých dimenzí. V tomto případě se ujistěte, že se v dotazu projektují potřebné dimenze pomocí operátoru projektu nebo rozšíření . Nastavte pole sloupce ID zdroje na Nedělit a zahrnout do seznamu všechny smysluplné dimenze. Ujistěte se, že je vybrána možnost Zahrnout všechny budoucí hodnoty , aby byla zahrnuta jakákoli hodnota vrácená z dotazu.
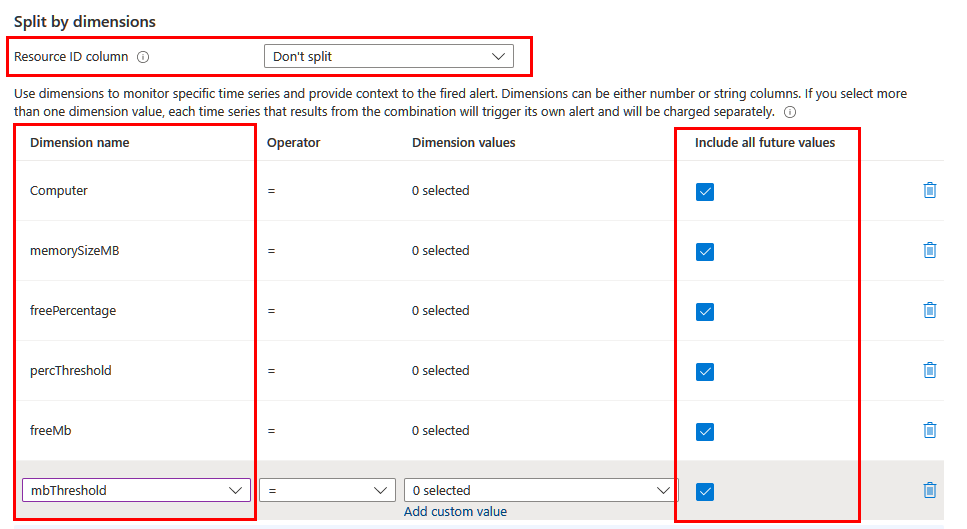
Dynamické prahové hodnoty
Další výhodou použití pravidel upozornění prohledávání protokolu je možnost zahrnout do dotazu složitou logiku pro určení prahové hodnoty. Prahovou hodnotu můžete pevně zakódovat, použít u všech prostředků nebo ji dynamicky vypočítat na základě některého pole nebo počítané hodnoty. Prahová hodnota se použije pouze na prostředky podle konkrétních podmínek. Můžete například vytvořit výstrahu na základě dostupné paměti, ale pouze pro počítače s určitým množstvím celkové paměti.
Běžná pravidla upozornění
Následující část uvádí běžná pravidla upozornění pro virtuální počítače ve službě Azure Monitor. Pro každou z nich jsou k dispozici podrobnosti o upozorněních metrik a upozorněních prohledávání protokolu. Pokyny k typu výstrahy, které se mají použít, najdete v tématu Typy výstrah. Pokud proces vytváření pravidel upozornění ve službě Azure Monitor neznáte, přečtěte si pokyny k vytvoření nového pravidla upozornění.
Poznámka:
Podrobnosti o zde uvedených upozorněních prohledávání protokolů využívají data shromážděná pomocí přehledů virtuálních počítačů, která poskytuje sadu běžných čítačů výkonu pro klientský operační systém. Tento název je nezávislý na typu operačního systému.
Dostupnost počítače
Jedním z nejběžnějších požadavků na monitorování virtuálního počítače je vytvořit upozornění, pokud se zastaví. Nejlepší metodou je vytvoření pravidla upozornění na metriku ve službě Azure Monitor pomocí metriky dostupnosti virtuálního počítače, která je aktuálně ve verzi Public Preview. Podrobné informace o této metrice najdete v tématu Vytvoření pravidla upozornění na dostupnost pro virtuální počítač Azure.
Pravidlo upozornění je omezeno na jeden signál protokolu aktivit. Takže pro každou podmínku musí být vytvořeno jedno pravidlo upozornění. Například "spustí nebo zastaví virtuální počítač" vyžaduje dvě pravidla upozornění. Pokud ale chcete být upozorněni při restartování virtuálního počítače, je potřeba jenom jedno pravidlo upozornění.
Jak je popsáno v pravidlech upozornění škálování, vytvořte pravidlo upozornění na dostupnost pomocí předplatného nebo skupiny prostředků jako cílového prostředku. Pravidlo platí pro více virtuálních počítačů, včetně nových počítačů, které vytvoříte po pravidlu upozornění.
Prezenčních signálů agenta
Prezenční signál agenta se mírně liší od výstrahy počítače, která není k dispozici, protože spoléhá na agenta služby Azure Monitor k odeslání prezenčních signálů. Prezenční signál agenta vás může upozornit, pokud je počítač spuštěný, ale agent nereaguje.
Pravidla upozornění metrik
Metrika s názvem Prezenční signál je součástí každého pracovního prostoru služby Log Analytics. Každý virtuální počítač připojený k danému pracovnímu prostoru odesílá hodnotu metriky prezenčních signálů každou minutu. Vzhledem k tomu, že počítač je dimenze metriky, můžete aktivovat výstrahu, když jakýkoli počítač neodešle prezenčních signálů. Nastavte typ agregace na Počet a prahovou hodnotu tak, aby odpovídala členitosti vyhodnocení.
Pravidla upozornění prohledávání protokolu
Upozornění prohledávání protokolů používají tabulku prezenčních signálů, která by měla mít záznam prezenčních signálů každou minutu z každého počítače.
Použijte pravidlo s následujícím dotazem:
Heartbeat
| summarize TimeGenerated=max(TimeGenerated) by Computer, _ResourceId
| extend Duration = datetime_diff('minute',now(),TimeGenerated)
| summarize MinutesSinceLastHeartbeat = min(Duration) by Computer, bin(TimeGenerated,5m), _ResourceId
Upozornění procesoru
Tato část popisuje výstrahy procesoru.
Pravidla upozornění metrik
| Cíl | Metrika |
|---|---|
| Hostitelský počítač | Procento procesoru (zahrnuté v doporučených upozorněních) |
| Host ve Windows | \Informace o procesoru(_Total)% čas procesoru |
| Host v Linuxu | cpu/usage_active |
Pravidla upozornění prohledávání protokolu
Využití procesoru
InsightsMetrics
| where Origin == "vm.azm.ms"
| where Namespace == "Processor" and Name == "UtilizationPercentage"
| summarize CPUPercentageAverage = avg(Val) by bin(TimeGenerated, 15m), Computer, _ResourceId
Upozornění na paměť
Tato část popisuje upozornění na paměť.
Pravidla upozornění metrik
| Cíl | Metrika |
|---|---|
| Hostitelský počítač | Dostupné bajty paměti (Preview) (zahrnuté v doporučených výstrahách) |
| Host ve Windows | \Paměť % potvrzených bajtů, které se používají \Memory\Available Bytes |
| Host v Linuxu | mem/available mem/available_percent |
Pravidla upozornění prohledávání protokolu
Poznámka:
Pokud potřebujete zadat výstrahu na jeden disk, můžete ho přidat do dotazu: | where parse_json(Tags).["vm.azm.ms/mountId"] == "C:"Dostupná paměť v MB
InsightsMetrics
| where Origin == "vm.azm.ms"
| where Namespace == "Memory" and Name == "AvailableMB"
| summarize AvailableMemoryInMBAverage = avg(Val) by bin(TimeGenerated, 15m), Computer, _ResourceId
Dostupná paměť v procentech
InsightsMetrics
| where Origin == "vm.azm.ms"
| where Namespace == "Memory" and Name == "AvailableMB"
| extend TotalMemory = toreal(todynamic(Tags)["vm.azm.ms/memorySizeMB"]) | extend AvailableMemoryPercentage = (toreal(Val) / TotalMemory) * 100.0
| summarize AvailableMemoryInPercentageAverage = avg(AvailableMemoryPercentage) by bin(TimeGenerated, 15m), Computer, _ResourceId
Upozornění na disky
Tato část popisuje upozornění na disky.
Pravidla upozornění metrik
| Cíl | Metrika |
|---|---|
| Host ve Windows | \Logický disk(_Total)% volného místa \Logický disk(_Total)\Volné megabajty |
| Host v Linuxu | disk/free disk/free_percent |
Pravidla upozornění prohledávání protokolu
Použitý logický disk – všechny disky v každém počítači
InsightsMetrics
| where Origin == "vm.azm.ms"
| where Namespace == "LogicalDisk" and Name == "FreeSpacePercentage"
| summarize LogicalDiskSpacePercentageFreeAverage = avg(Val) by bin(TimeGenerated, 15m), Computer, _ResourceId
Použitý logický disk – jednotlivé disky
InsightsMetrics
| where Origin == "vm.azm.ms"
| where Namespace == "LogicalDisk" and Name == "FreeSpacePercentage"
| extend Disk=tostring(todynamic(Tags)["vm.azm.ms/mountId"])
| summarize LogicalDiskSpacePercentageFreeAverage = avg(Val) by bin(TimeGenerated, 15m), Computer, _ResourceId, Disk
IOPS logického disku
InsightsMetrics
| where Origin == "vm.azm.ms"
| where Namespace == "LogicalDisk" and Name == "TransfersPerSecond"
| extend Disk=tostring(todynamic(Tags)["vm.azm.ms/mountId"])
| summarize DiskIOPSAverage = avg(Val) by bin(TimeGenerated, 15m), Computer, _ResourceId, Disk
Přenos dat logického disku
InsightsMetrics
| where Origin == "vm.azm.ms"
| where Namespace == "LogicalDisk" and Name == "BytesPerSecond"
| extend Disk=tostring(todynamic(Tags)["vm.azm.ms/mountId"])
| summarize DiskBytesPerSecondAverage = avg(Val) by bin(TimeGenerated, 15m), Computer, _ResourceId, Disk
Upozornění sítě
Pravidla upozornění metrik
| Cíl | Metrika |
|---|---|
| Hostitelský počítač | Total Network In Total, Network Out Total (zahrnuté v doporučených výstrahách) |
| Host ve Windows | \Síťové rozhraní\Bajty odeslané/s \Logický disk(_Total)\Volné megabajty |
| Host v Linuxu | disk/free disk/free_percent |
Pravidla upozornění prohledávání protokolu
Přijatá síťová rozhraní – všechna rozhraní
InsightsMetrics
| where Origin == "vm.azm.ms"
| where Namespace == "Network" and Name == "ReadBytesPerSecond"
| summarize BytesReceivedAverage = avg(Val) by bin(TimeGenerated, 15m), Computer, _ResourceId
Přijatá síťová rozhraní – jednotlivá rozhraní
InsightsMetrics
| where Origin == "vm.azm.ms"
| where Namespace == "Network" and Name == "ReadBytesPerSecond"
| extend NetworkInterface=tostring(todynamic(Tags)["vm.azm.ms/networkDeviceId"])
| summarize BytesReceievedAverage = avg(Val) by bin(TimeGenerated, 15m), Computer, _ResourceId, NetworkInterface
Odesílaná síťová rozhraní – všechna rozhraní
InsightsMetrics
| where Origin == "vm.azm.ms"
| where Namespace == "Network" and Name == "WriteBytesPerSecond"
| summarize BytesSentAverage = avg(Val) by bin(TimeGenerated, 15m), Computer, _ResourceId
Odesílaná síťová rozhraní – jednotlivá rozhraní
InsightsMetrics
| where Origin == "vm.azm.ms"
| where Namespace == "Network" and Name == "WriteBytesPerSecond"
| extend NetworkInterface=tostring(todynamic(Tags)["vm.azm.ms/networkDeviceId"])
| summarize BytesSentAverage = avg(Val) by bin(TimeGenerated, 15m), Computer, _ResourceId, NetworkInterface
Události Windows a Linuxu
Následující ukázka vytvoří výstrahu při vytvoření konkrétní události systému Windows. K vytvoření samostatné výstrahy pro každý počítač používá pravidlo upozornění na měření metriky.
Vytvořte pravidlo upozornění na konkrétní událost systému Windows. Tento příklad ukazuje událost v protokolu aplikace. Zadejte prahovou hodnotu 0 a po sobě jdoucích porušení větších než 0.
Event | where EventLog == "Application" | where EventID == 123 | summarize NumberOfEvents = count() by Computer, bin(TimeGenerated, 15m)Vytvořte pravidlo upozornění na události Syslogu s konkrétní závažností. Následující příklad ukazuje události autorizace chyb. Zadejte prahovou hodnotu 0 a po sobě jdoucích porušení větších než 0.
Syslog | where Facility == "auth" | where SeverityLevel == "err" | summarize NumberOfEvents = count() by Computer, bin(TimeGenerated, 15m)
Vlastní čítače výkonu
Vytvořte upozornění na maximální hodnotu čítače.
Perf | where CounterName == "My Counter" | summarize AggregatedValue = max(CounterValue) by ComputerVytvořte upozornění na průměrnou hodnotu čítače.
Perf | where CounterName == "My Counter" | summarize AggregatedValue = avg(CounterValue) by Computer
Další kroky
Analýza dat monitorování shromážděných pro virtuální počítače