Správa prostoru databázových souborů v Azure SQL Database
Platí pro: ![]() Azure SQL Database
Azure SQL Database
Tento článek popisuje různé typy úložného prostoru pro databáze ve službě Azure SQL Database a kroky, které je možné provést, když je potřeba explicitně spravovat přidělený prostor souborů.
Přehled
Ve službě Azure SQL Database existují vzory úloh, kdy přidělení podkladových datových souborů pro databáze může být větší než počet použitých datových stránek. K této podmínce může dojít, když se zvýší využité místo a data se později odstraní. Důvodem je, že dodatečně přidělený prostor souborů se při odstranění dat neuvolní automaticky.
Monitorování využití místa pro soubory a zmenšení datových souborů může být nutné v následujících scénářích:
- Povolení růstu objemu dat v elastickém fondu v případě, že prostor souborů přidělený pro jeho databáze dosáhne maximální velikosti fondu
- Povolení snížení maximální velikosti jednoúčelové databáze nebo elastického fondu
- Povolení změny jednoúčelové databáze nebo elastického fondu na jinou úroveň služby nebo výkonu s nižší maximální velikostí
Poznámka:
Operace zmenšení by se neměly považovat za pravidelnou operaci údržby. Data a soubory protokolů, které se zvětšují z důvodu pravidelných opakovaných obchodních operací, nevyžadují operace zmenšení.
Monitorování využití místa na souborech
Většina metrik prostoru úložiště zobrazených v následujících rozhraních API měří pouze velikost použitých datových stránek:
Následující rozhraní API měří také místo přidělené databázím a elastickým fondům:
- T-SQL: sys.resource_stats
- T-SQL: sys.elastic_pool_resource_stats
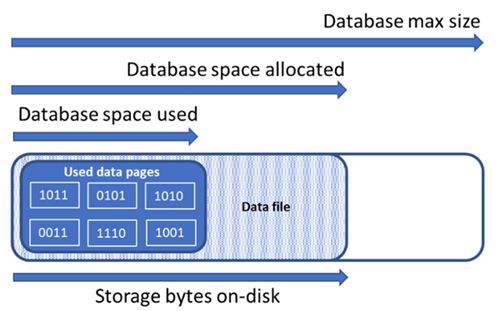
Principy typů prostoru úložiště pro databázi
Pro správu prostoru souborů databáze je důležité porozumět následujícímu množství úložného prostoru.
| Množství v databázi | Definice | Komentáře |
|---|---|---|
| Využité datové místo | Velikost místa použitého k ukládání databázových dat. | Obecně platí, že se při vkládání (odstranění) zvyšuje využité místo (snižuje). V některých případech se využité místo při vkládání nebo odstraňování nemění v závislosti na množství a vzoru dat zapojených do operace a jakékoli fragmentace. Například odstranění jednoho řádku z každé datové stránky nemusí nutně zmenšit využitý prostor. |
| Přidělený datový prostor | Množství formátovaného prostoru pro soubory, které je k dispozici pro ukládání dat databáze. | Přidělený prostor se automaticky zvětšuje, ale po odstranění se nikdy nezmenší. Toto chování zajišťuje, aby budoucí vložení bylo rychlejší, protože není nutné přeformátovat mezery. |
| Přidělený datový prostor, ale nevyužitý | Rozdíl mezi velikostí přiděleného datového prostoru a využitou velikostí datového prostoru. | Tato velikost představuje maximální objem volného prostoru, který je možné získat zpět zmenšením datových souborů databáze. |
| Maximální velikost dat | Maximální množství místa, které lze použít k ukládání databázových dat. | Velikost přiděleného datového prostoru se nemůže zvětšovat nad rámec maximální velikosti dat. |
Následující diagram znázorňuje vztah mezi různými typy prostoru úložiště pro databázi.
Dotazování na jednoúčelovou databázi s informacemi o prostoru souborů
Pomocí následujícího dotazu na sys.database_files vrátíte přidělený prostor databázového souboru a přidělené množství nevyužitého místa. Výsledek dotazu je v megabajtech (MB).
-- Connect to a user database
SELECT file_id, type_desc,
CAST(FILEPROPERTY(name, 'SpaceUsed') AS decimal(19,4)) * 8 / 1024. AS space_used_mb,
CAST(size/128.0 - CAST(FILEPROPERTY(name, 'SpaceUsed') AS int)/128.0 AS decimal(19,4)) AS space_unused_mb,
CAST(size AS decimal(19,4)) * 8 / 1024. AS space_allocated_mb,
CAST(max_size AS decimal(19,4)) * 8 / 1024. AS max_size_mb
FROM sys.database_files;
Principy typů prostoru úložiště pro elastický fond
Pochopení následujících množství prostoru úložiště je důležité pro správu prostoru souborů elastického fondu.
| Množství v elastickém fondu | Definice | Komentáře |
|---|---|---|
| Využité datové místo | Součet datového prostoru používaného všemi databázemi v elastickém fondu. | |
| Přidělený datový prostor | Součet datového prostoru přiděleného všemi databázemi v elastickém fondu. | |
| Přidělený datový prostor, ale nevyužitý | Rozdíl mezi velikostí přiděleného datového prostoru a využitou velikostí datového prostoru používaného všemi databázemi v elastickém fondu. | Tato velikost představuje maximální objem prostoru přiděleného pro elastický fond, který je možné získat zpět zmenšením datových souborů databáze. |
| Maximální velikost dat | Maximální objem datového prostoru, který může elastický fond používat pro všechny své databáze. | Prostor přidělený pro elastický fond by neměl překročit maximální velikost elastického fondu. Pokud k této podmínce dojde, je možné uvolnit místo přidělené nevyužité pomocí zmenšení datových souborů databáze. |
Poznámka:
Chybová zpráva Elastický fond dosáhl limitu úložiště značí, že databázové objekty byly přiděleny dostatek místa pro splnění limitu úložiště elastického fondu, ale v přidělení datového prostoru může být nevyužité místo. Zvažte zvýšení limitu úložiště elastického fondu nebo jako krátkodobé řešení uvolnění datového prostoru pomocí ukázek v části Uvolnit nevyužitý přidělený prostor. Měli byste také vědět o potenciálním negativním dopadu na výkon zmenšení databázových souborů, viz údržba indexů po zmenšení.
Dotazování elastického fondu na informace o prostoru úložiště
K určení velikosti prostoru úložiště elastického fondu můžete použít následující dotazy.
Využitý datový prostor elastického fondu
Upravte následující dotaz tak, aby vrátil množství využitého datového prostoru elastického fondu. Výsledek dotazu je v megabajtech (MB).
-- Connect to master
-- Elastic pool data space used in MB
SELECT TOP 1 avg_storage_percent / 100.0 * elastic_pool_storage_limit_mb AS ElasticPoolDataSpaceUsedInMB
FROM sys.elastic_pool_resource_stats
WHERE elastic_pool_name = 'ep1'
ORDER BY end_time DESC;
Přidělený datový prostor elastického fondu a nevyužitý přidělený prostor
Upravte následující příklady tak, aby vracela tabulku s přiděleným a nevyužitým přiděleným prostorem pro každou databázi v elastickém fondu. Tabulka objednává databáze z těchto databází s největším množstvím nevyužitého přiděleného prostoru na nejmenší množství nevyužitého přiděleného prostoru. Výsledek dotazu je v megabajtech (MB).
Výsledky dotazu pro určení prostoru přiděleného pro každou databázi ve fondu je možné sečíst dohromady a určit tak celkový prostor přidělený elastickému fondu. Přidělený prostor elastického fondu by neměl překročit maximální velikost elastického fondu.
Důležité
Azure SQL Database stále podporuje modul Azure Resource Manageru v PowerShellu, ale veškerý budoucí vývoj je určený pro modul Az.Sql. Modul AzureRM bude dál dostávat opravy chyb až do alespoň prosince 2020. Argumenty pro příkazy v modulu Az a v modulech AzureRm jsou podstatně identické. Další informace o jejich kompatibilitě najdete v tématu Představení nového modulu Az Azure PowerShellu.
Skript PowerShellu vyžaduje modul POWERShellu SQL Serveru – viz Stažení modulu PowerShellu pro instalaci.
$resourceGroupName = "<resourceGroupName>"
$serverName = "<serverName>"
$poolName = "<poolName>"
$userName = "<userName>"
$password = "<password>"
# get list of databases in elastic pool
$databasesInPool = Get-AzSqlElasticPoolDatabase -ResourceGroupName $resourceGroupName `
-ServerName $serverName -ElasticPoolName $poolName
$databaseStorageMetrics = @()
# for each database in the elastic pool, get space allocated in MB and space allocated unused in MB
foreach ($database in $databasesInPool) {
$sqlCommand = "SELECT DB_NAME() as DatabaseName, `
SUM(size/128.0) AS DatabaseDataSpaceAllocatedInMB, `
SUM(size/128.0 - CAST(FILEPROPERTY(name, 'SpaceUsed') AS int)/128.0) AS DatabaseDataSpaceAllocatedUnusedInMB `
FROM sys.database_files `
GROUP BY type_desc `
HAVING type_desc = 'ROWS'"
$serverFqdn = "tcp:" + $serverName + ".database.windows.net,1433"
$databaseStorageMetrics = $databaseStorageMetrics +
(Invoke-Sqlcmd -ServerInstance $serverFqdn -Database $database.DatabaseName `
-Username $userName -Password $password -Query $sqlCommand)
}
# display databases in descending order of space allocated unused
Write-Output "`n" "ElasticPoolName: $poolName"
Write-Output $databaseStorageMetrics | Sort -Property DatabaseDataSpaceAllocatedUnusedInMB -Descending | Format-Table
Následující snímek obrazovky je příkladem výstupu skriptu:

Maximální velikost dat elastického fondu
Upravte následující dotaz T-SQL tak, aby vrátil maximální velikost dat posledního zaznamenaného elastického fondu. Výsledek dotazu je v megabajtech (MB).
-- Connect to master
-- Elastic pools max size in MB
SELECT TOP 1 elastic_pool_storage_limit_mb AS ElasticPoolMaxSizeInMB
FROM sys.elastic_pool_resource_stats
WHERE elastic_pool_name = 'ep1'
ORDER BY end_time DESC;
Uvolnění nevyužitého přiděleného místa
Důležité
Příkazy, které zmenšují databázi, ovlivňují výkon spuštěné databáze. Proto pokud je to možné, spouštějte je v době jejího nízkého využití.
Zmenšení datových souborů
Kvůli potenciálnímu dopadu na výkon databáze Azure SQL Database automaticky nezmenšuje datové soubory. Zákazníci ale můžou datové soubory zmenšovat prostřednictvím samoobslužných služeb najednou podle svého výběru. Tato operace by neměla být pravidelně naplánovaná, ale spíše jednorázová událost v reakci na významné snížení spotřeby využitého místa v datovém souboru.
Tip
Nedoporučujeme zmenšovat datové soubory, pokud normální provoz aplikace způsobí, že soubory časem opět narostou na stejnou velikost.
Ke zmenšení souborů ve službě Azure SQL Database můžete použít příkazy DBCC SHRINKDATABASE nebo DBCC SHRINKFILE příkazy:
DBCC SHRINKDATABASEzmenší všechna data a soubory protokolu v databázi pomocí jednoho příkazu. Příkaz zmenší jeden datový soubor najednou, což může trvat delší dobu pro větší databáze. Zmenší také soubor protokolu, což je obvykle zbytečné, protože Azure SQL Database podle potřeby automaticky zmenšuje soubory protokolů.DBCC SHRINKFILEpříkaz podporuje pokročilejší scénáře:- Podle potřeby může cílit na jednotlivé soubory místo zmenšení všech souborů v databázi.
- Každý
DBCC SHRINKFILEpříkaz může běžet paralelně s jinýmiDBCC SHRINKFILEpříkazy, aby se zmenšil více souborů současně a zkrátil celkový čas zmenšení, na úkor vyššího využití prostředků a vyšší pravděpodobnost blokování uživatelských dotazů, pokud se provádějí během zmenšení.- Zmenšení více datových souborů současně umožňuje rychlejší dokončení operace zmenšení. Pokud používáte souběžné zmenšení datového souboru, můžete pozorovat přechodné blokování jednoho požadavku zmenšení jiným.
- Pokud ocas souboru neobsahuje data, může zmenšit přidělenou velikost souboru mnohem rychleji zadáním argumentu
TRUNCATEONLY. Nevyžaduje přesun dat v rámci souboru.
- Další informace o těchtopříkazch
- Operace zmenšení databáze a souborů se podporují ve verzi Preview pro Hyperscale služby Azure SQL Database. Další informace najdete v tématu Zmenšení služby Azure SQL Database Hyperscale.
Následující příklady musí být spuštěny při připojení k cílové uživatelské databázi, nikoli databáze master .
DBCC SHRINKDATABASE Použití ke zmenšení všech dat a souborů protokolu v dané databázi:
-- Shrink database data space allocated.
DBCC SHRINKDATABASE (N'database_name');
Ve službě Azure SQL Database může databáze mít jeden nebo více datových souborů, které se automaticky vytvoří při růstu dat. Pokud chcete určit rozložení souboru databáze, včetně použité a přidělené velikosti každého souboru, pomocí následujícího ukázkového skriptu zadejte dotaz na sys.database_files zobrazení katalogu:
-- Review file properties, including file_id and name values to reference in shrink commands
SELECT file_id,
name,
CAST(FILEPROPERTY(name, 'SpaceUsed') AS bigint) * 8 / 1024. AS space_used_mb,
CAST(size AS bigint) * 8 / 1024. AS space_allocated_mb,
CAST(max_size AS bigint) * 8 / 1024. AS max_file_size_mb
FROM sys.database_files
WHERE type_desc IN ('ROWS','LOG');
Zmenšení můžete provést pouze u jednoho souboru pomocí DBCC SHRINKFILE příkazu, například:
-- Shrink database data file named 'data_0` by removing all unused at the end of the file, if any.
DBCC SHRINKFILE ('data_0', TRUNCATEONLY);
GO
Mějte na paměti potenciální negativní dopad na výkon zmenšení databázových souborů, viz Údržba indexu po zmenšení.
Zmenšení souboru transakčního protokolu
Služba Azure SQL Database, na rozdíl od datových souborů, automaticky zmenšuje soubor transakčního protokolu, aby zabránila nadměrnému zabírání místa, které vede k chybám způsobeným nedostatkem místa. Většinou není potřeba, aby zákazníci zmenšovali soubor transakčního protokolu.
Pokud se transakční protokol změní na úroveň Premium a Pro důležité obchodní informace, může výrazně přispět k využití místního úložiště směrem k maximálnímu limitu místního úložiště. Pokud je využití místního úložiště blízko limitu, zákazníci se mohou rozhodnout zmenšit transakční protokol pomocí příkazu DBCC SHRINKFILE , jak je znázorněno v následujícím příkladu. Tím se uvolní místní úložiště, jakmile se příkaz dokončí, aniž byste čekali na pravidelnou automatickou operaci zmenšení.
Následující příklad by se měl spustit při připojení k cílové uživatelské databázi, ne databáze master .
-- Shrink the database log file (always file_id 2), by removing all unused space at the end of the file, if any.
DBCC SHRINKFILE (2, TRUNCATEONLY);
Automatické zmenšení
Jako alternativu k ručnímu zmenšení datových souborů je možné pro databázi povolit automatické zmenšení. Automatické zmenšení však může být méně efektivní při uvolnění místa na souboru než DBCC SHRINKDATABASE a DBCC SHRINKFILE.
Ve výchozím nastavení je automatické zmenšení zakázané, což se doporučuje pro většinu databází. Pokud je nutné povolit automatické zmenšení, doporučujeme ho zakázat, jakmile dosáhnete cílů správy prostoru, místo aby byl trvale povolený. Další informace najdete v části Důležité informace o možnosti AUTO_SHRINK.
Automatické zmenšení může být například užitečné v konkrétním scénáři, kdy elastický fond obsahuje mnoho databází, u kterých dochází k významnému růstu a snížení využitého místa v datových souborech, což způsobí, že se fond blíží maximálnímu limitu velikosti. Nejedná se o běžný scénář.
Pokud chcete povolit automatické zmenšení, spusťte při připojení k databázi následující příkaz (ne databázi master ).
-- Enable auto-shrink for the current database.
ALTER DATABASE CURRENT SET AUTO_SHRINK ON;
Další informace o tomto příkazu naleznete v tématu MOŽNOSTI SADY DATABÁZE.
Údržba indexu po zmenšení
Po dokončení operace zmenšení datových souborů se indexy můžou fragmentovat. Tím se snižuje efektivita optimalizace výkonu u určitých úloh, jako jsou dotazy využívající rozsáhlé kontroly. Pokud po dokončení operace zmenšení dojde ke snížení výkonu, zvažte údržbu indexů při opětovném sestavení indexů. Mějte na paměti, že opětovné sestavení indexu vyžaduje volné místo v databázi, a proto může způsobit zvětšení přiděleného prostoru, což snižuje účinek zmenšení.
Další informace o údržbě indexů naleznete v tématu Optimalizace údržby indexů za účelem zlepšení výkonu dotazů a snížení spotřeby prostředků.
Zmenšení velkých databází
Pokud je přidělený prostor databáze ve stovkách gigabajtů nebo vyšších, může zmenšení vyžadovat značné množství času dokončení, často měřené v hodinách nebo dnech u databází s více terabajty. Existují optimalizace procesů a osvědčené postupy, pomocí které můžete tento proces zefektivnit a méně ovlivnit úlohy aplikací.
Zachycení směrného plánu využití místa
Před zahájením zmenšení zachyťte aktuální využité a přidělené místo v každém databázovém souboru spuštěním následujícího dotazu na využití místa:
SELECT file_id,
CAST(FILEPROPERTY(name, 'SpaceUsed') AS bigint) * 8 / 1024. AS space_used_mb,
CAST(size AS bigint) * 8 / 1024. AS space_allocated_mb,
CAST(max_size AS bigint) * 8 / 1024. AS max_size_mb
FROM sys.database_files
WHERE type_desc = 'ROWS';
Po dokončení zmenšení můžete tento dotaz znovu spustit a porovnat výsledek s počátečním směrný plán.
Zkrácení datových souborů
Doporučujeme nejprve spustit zmenšení pro každý datový soubor s parametrem TRUNCATEONLY . Pokud je na konci souboru přiděleno nějaké přidělené, ale nevyužité místo, odebere se rychle a bez přesunu dat. Následující ukázkový příkaz zkrátí datový soubor s file_id 4:
DBCC SHRINKFILE (4, TRUNCATEONLY);
Jakmile se tento příkaz spustí pro každý datový soubor, můžete znovu spustit dotaz využití místa, abyste viděli snížení přiděleného prostoru( pokud existuje). Přidělené místo pro databázi můžete zobrazit také na webu Azure Portal.
Vyhodnocení hustoty stránky indexu
Pokud zkrácení datových souborů nezpůsobilo dostatečné snížení přiděleného prostoru, budete muset zmenšit datové soubory. Jako volitelný, ale doporučený krok byste ale měli nejprve určit průměrnou hustotu stránky pro indexy v databázi. U stejného množství dat se zmenšování dokončí rychleji, pokud je hustota stránky vysoká, protože bude nutné přesunout méně stránek. Pokud je hustota stránky u některých indexů nízká, zvažte údržbu těchto indexů, abyste před zmenšením datových souborů zvýšili hustotu stránky. To také umožní zmenšit dosažení hlubšího snížení přiděleného prostoru úložiště.
Pokud chcete určit hustotu stránky pro všechny indexy v databázi, použijte následující dotaz. Hustota stránky se vyhlásí ve sloupci avg_page_space_used_in_percent .
SELECT OBJECT_SCHEMA_NAME(ips.object_id) AS schema_name,
OBJECT_NAME(ips.object_id) AS object_name,
i.name AS index_name,
i.type_desc AS index_type,
ips.avg_page_space_used_in_percent,
ips.avg_fragmentation_in_percent,
ips.page_count,
ips.alloc_unit_type_desc,
ips.ghost_record_count
FROM sys.dm_db_index_physical_stats(DB_ID(), default, default, default, 'SAMPLED') AS ips
INNER JOIN sys.indexes AS i
ON ips.object_id = i.object_id
AND
ips.index_id = i.index_id
ORDER BY page_count DESC;
Pokud existují indexy s vysokým počtem stránek, které mají hustotu stránky nižší než 60–70 %, zvažte před zmenšením datových souborů opětovné sestavení nebo změna uspořádání těchto indexů.
Poznámka:
U větších databází může dokončení dotazu na zjištění hustoty stránky trvat dlouhou dobu (hodiny). Opětovné sestavení nebo změna uspořádání velkých indexů navíc vyžaduje značné množství času a využití prostředků. Existuje kompromis mezi tím, že strávíte delší dobu strávenou na zvýšení hustoty stránky na jedné straně a snížíte dobu trvání zmenšení a dosáhnete vyšších úspor místa na druhé.
Pokud existuje více indexů s nízkou hustotou stránky, můžete je paralelně znovu sestavit v několika databázových relacích, aby se proces urychlil. Ujistěte se ale, že se tím nedotáčíte limitů prostředků databáze, a ponechte dostatečný prostor pro úlohy aplikací, které by mohly běžet. Monitorování spotřeby prostředků (cpu, vstupně-výstupních operací dat, vstupně-výstupních operací protokolu) na webu Azure Portal nebo pomocí zobrazení sys.dm_db_resource_stats a spuštění dalších paralelních opětovného sestavení pouze v případě, že využití prostředků v každé z těchto dimenzí zůstává podstatně nižší než 100 %. Pokud využití procesoru, vstupně-výstupních operací dat nebo vstupně-výstupních operací protokolů činí 100 %, můžete vertikálně navýšit kapacitu databáze, aby měla více jader procesoru a zvýšila propustnost vstupně-výstupních operací. To může umožnit další paralelní opětovné sestavení, aby se proces dokončil rychleji.
Ukázkový příkaz pro opětovné sestavení indexu
Následuje ukázkový příkaz k opětovnému sestavení indexu a zvýšení hustoty stránky pomocí příkazu ALTER INDEX :
ALTER INDEX [index_name] ON [schema_name].[table_name]
REBUILD WITH (FILLFACTOR = 100, MAXDOP = 8,
ONLINE = ON (WAIT_AT_LOW_PRIORITY (MAX_DURATION = 5 MINUTES, ABORT_AFTER_WAIT = NONE)),
RESUMABLE = ON);
Tento příkaz zahájí online a obnovitelné opětovné sestavení indexu. To umožňuje souběžným úlohám pokračovat v používání tabulky, zatímco probíhá opětovné sestavení, a pokud dojde k přerušení opětovného sestavení z nějakého důvodu, můžete obnovit opětovné sestavení. Tento typ opětovného sestavení je však pomalejší než offline opětovné sestavení, které blokuje přístup k tabulce. Pokud během opětovného sestavení nemusí k tabulce přistupovat žádné jiné úlohy, nastavte ONLINE a odeberte klauzuli a RESUMABLE OFF odeberte ji WAIT_AT_LOW_PRIORITY .
Další informace o údržbě indexů najdete v tématu Optimalizace údržby indexů za účelem zlepšení výkonu dotazů a snížení spotřeby prostředků.
Zmenšení více datových souborů
Jak už jsme uvedli dříve, zmenšení s přesunem dat je dlouhotrvající proces. Pokud databáze obsahuje více datových souborů, můžete proces urychlit zmenšením několika datových souborů paralelně. Uděláte to tak, že otevřete více databázových relací a použijete DBCC SHRINKFILE je pro každou relaci s jinou file_id hodnotou. Podobně jako při opětovném sestavení indexů se ujistěte, že máte před spuštěním každého nového příkazu paralelního zmenšení dostatek prostředků (CPU, Vstupně-výstupních operací dat, vstupně-výstupních operací protokolu).
Následující ukázkový příkaz zmenší datový soubor s file_id 4 a pokusí se zmenšit přidělenou velikost na 52 000 MB přesunutím stránek v souboru:
DBCC SHRINKFILE (4, 52000);
Pokud chcete zmenšit přidělené místo pro soubor na minimum, spusťte příkaz bez zadání cílové velikosti:
DBCC SHRINKFILE (4);
Pokud úloha běží souběžně se zmenšením, může začít využívat prostor úložiště uvolněný zmenšením před dokončením zmenšení a zkrátí soubor. V takovém případě nebude možné zmenšit přidělené místo určenému cíli.
Tento problém můžete zmírnit zmenšením jednotlivých souborů v menších krocích. To znamená, že v DBCC SHRINKFILE příkazu nastavíte cíl, který je o něco menší než aktuální přidělený prostor pro soubor, jak je vidět ve výsledcích dotazu využití prostoru podle směrného plánu. Pokud je například přidělený prostor pro soubor s file_id 4 je 200 000 MB a chcete ho zmenšit na 100 000 MB, můžete nejprve nastavit cíl na 170 000 MB:
DBCC SHRINKFILE (4, 170000);
Po dokončení tohoto příkazu se soubor zkrátí a zmenší jeho přidělenou velikost na 170 000 MB. Potom můžete tento příkaz zopakovat, nastavit cíl jako první na 140 000 MB, pak na 110 000 MB atd., dokud se soubor nesmaže na požadovanou velikost. Pokud se příkaz dokončí, ale soubor není zkrácený, použijte menší kroky, například 15 000 MB místo 30 000 MB.
Pokud chcete monitorovat průběh zmenšení pro všechny souběžně spuštěné relace zmenšení, můžete použít následující dotaz:
SELECT command,
percent_complete,
status,
wait_resource,
session_id,
wait_type,
blocking_session_id,
cpu_time,
reads,
CAST(((DATEDIFF(s,start_time, GETDATE()))/3600) AS varchar) + ' hour(s), '
+ CAST((DATEDIFF(s,start_time, GETDATE())%3600)/60 AS varchar) + 'min, '
+ CAST((DATEDIFF(s,start_time, GETDATE())%60) AS varchar) + ' sec' AS running_time
FROM sys.dm_exec_requests AS r
LEFT JOIN sys.databases AS d
ON r.database_id = d.database_id
WHERE r.command IN ('DbccSpaceReclaim','DbccFilesCompact','DbccLOBCompact','DBCC');
Poznámka:
Průběh zmenšení může být nelineární a hodnota ve percent_complete sloupci může zůstat prakticky beze změny po dlouhou dobu, i když stále probíhá zmenšení.
Po dokončení zmenšení všech datových souborů znovu spusťte dotaz na využití místa (nebo se podívejte na azure Portal), abyste zjistili výsledné snížení přidělené velikosti úložiště. Pokud je stále velký rozdíl mezi využitým prostorem a přiděleným prostorem, můžete znovu sestavit indexy , jak je popsáno výše. To může dočasně zvětšit přidělený prostor, ale zmenšení datových souborů po opětovném sestavení indexů by mělo vést k hlubšímu snížení přiděleného prostoru.
Přechodné chyby během zmenšení
Někdy může příkaz zmenšení selhat s různými chybami, jako jsou vypršení časových limitů a zablokování. Obecně platí, že tyto chyby jsou přechodné a nedochází k nim znovu, pokud se stejný příkaz opakuje. Pokud se zmenšování nezdaří s chybou, průběh, který zatím provedl při přesouvání datových stránek, se zachová a stejný příkaz pro zmenšení souboru můžete spustit znovu.
Následující ukázkový skript ukazuje, jak můžete spustit zmenšování ve smyčce opakování, abyste mohli automaticky opakovat až konfigurovatelný počet výskytů chyby časového limitu nebo chyby zablokování. Tento přístup k opakování se vztahuje na mnoho dalších chyb, ke kterým může dojít během zmenšení.
DECLARE @RetryCount int = 3; -- adjust to configure desired number of retries
DECLARE @Delay char(12);
-- Retry loop
WHILE @RetryCount >= 0
BEGIN
BEGIN TRY
DBCC SHRINKFILE (1); -- adjust file_id and other shrink parameters
-- Exit retry loop on successful execution
SELECT @RetryCount = -1;
END TRY
BEGIN CATCH
-- Retry for the declared number of times without raising an error if deadlocked or timed out waiting for a lock
IF ERROR_NUMBER() IN (1205, 49516) AND @RetryCount > 0
BEGIN
SELECT @RetryCount -= 1;
PRINT CONCAT('Retry at ', SYSUTCDATETIME());
-- Wait for a random period of time between 1 and 10 seconds before retrying
SELECT @Delay = '00:00:0' + CAST(CAST(1 + RAND() * 8.999 AS decimal(5,3)) AS varchar(5));
WAITFOR DELAY @Delay;
END
ELSE -- Raise error and exit loop
BEGIN
SELECT @RetryCount = -1;
THROW;
END
END CATCH
END;
Kromě časových limitů a zablokování může dojít ke zmenšení chyb kvůli určitým známým problémům.
Vrácené chyby a kroky pro zmírnění rizik jsou následující:
- Číslo chyby: 49503, chybová zpráva: %.*ls: Stránka %d:%d nelze přesunout, protože se jedná o stránku úložiště trvalých verzí mimo řádek. Důvod blokování stránky: %ls. Časové razítko blokování stránky: %I64d
K této chybě dochází v případě dlouhotrvajících aktivních transakcí, které mají vygenerované verze řádků v trvalém úložišti verzí (PVS). Stránky, které obsahují tyto verze řádků, nelze přesunout zmenšením, a proto nemůže pokračovat a selže s touto chybou.
Pokud chcete tyto dlouhotrvající transakce zmírnit, musíte počkat, až se tyto dlouhotrvající transakce dokončí. Alternativně můžete identifikovat a ukončit tyto dlouhotrvající transakce, ale to může ovlivnit vaši aplikaci, pokud nezpracuje selhání transakcí řádně. Jedním ze způsobů, jak najít dlouhotrvající transakce, je spuštěním následujícího dotazu v databázi, ve které jste spustili příkaz shrink:
-- Transactions sorted by duration
SELECT st.session_id,
dt.database_transaction_begin_time,
DATEDIFF(second, dt.database_transaction_begin_time, CURRENT_TIMESTAMP) AS transaction_duration_seconds,
dt.database_transaction_log_bytes_used,
dt.database_transaction_log_bytes_reserved,
st.is_user_transaction,
st.open_transaction_count,
ib.event_type,
ib.parameters,
ib.event_info
FROM sys.dm_tran_database_transactions AS dt
INNER JOIN sys.dm_tran_session_transactions AS st
ON dt.transaction_id = st.transaction_id
OUTER APPLY sys.dm_exec_input_buffer(st.session_id, default) AS ib
WHERE dt.database_id = DB_ID()
ORDER BY transaction_duration_seconds DESC;
Transakci můžete ukončit pomocí KILL příkazu a zadáním přidružené session_id hodnoty z výsledku dotazu:
KILL 4242; -- replace 4242 with the session_id value from query results
Upozornění
Ukončení transakce může negativně ovlivnit úlohy.
Po ukončení nebo dokončení dlouhotrvajících transakcí se už po nějaké době nevyčistí interní úloha na pozadí, která už nebude potřebovat verze řádků. Pomocí následujícího dotazu můžete monitorovat velikost PVS a měřit průběh čištění. Spusťte dotaz v databázi, ve které jste spustili příkaz shrink:
SELECT pvss.persistent_version_store_size_kb / 1024. / 1024 AS persistent_version_store_size_gb,
pvss.online_index_version_store_size_kb / 1024. / 1024 AS online_index_version_store_size_gb,
pvss.current_aborted_transaction_count,
pvss.aborted_version_cleaner_start_time,
pvss.aborted_version_cleaner_end_time,
dt.database_transaction_begin_time AS oldest_transaction_begin_time,
asdt.session_id AS active_transaction_session_id,
asdt.elapsed_time_seconds AS active_transaction_elapsed_time_seconds
FROM sys.dm_tran_persistent_version_store_stats AS pvss
LEFT JOIN sys.dm_tran_database_transactions AS dt
ON pvss.oldest_active_transaction_id = dt.transaction_id
AND
pvss.database_id = dt.database_id
LEFT JOIN sys.dm_tran_active_snapshot_database_transactions AS asdt
ON pvss.min_transaction_timestamp = asdt.transaction_sequence_num
OR
pvss.online_index_min_transaction_timestamp = asdt.transaction_sequence_num
WHERE pvss.database_id = DB_ID();
Jakmile se velikost PVS hlášená persistent_version_store_size_gb ve sloupci výrazně zmenší v porovnání s původní velikostí, mělo by opětovné zmenšování proběhnout úspěšně.
- Číslo chyby: 5223, chybová zpráva: %.*ls: Prázdná stránka %d:%d nelze uvolnit.
K této chybě může dojít, pokud dochází k probíhajícím operacím údržby indexů, například ALTER INDEX. Po dokončení těchto operací zkuste příkaz zmenšit znovu.
Pokud tato chyba přetrvává, je možné, že přidružený index bude potřeba znovu vytvořit. Pokud chcete najít index, který se má znovu sestavit, spusťte následující dotaz ve stejné databázi, ve které jste spustili příkaz shrink:
SELECT OBJECT_SCHEMA_NAME(pg.object_id) AS schema_name,
OBJECT_NAME(pg.object_id) AS object_name,
i.name AS index_name,
p.partition_number
FROM sys.dm_db_page_info(DB_ID(), <file_id>, <page_id>, default) AS pg
INNER JOIN sys.indexes AS i
ON pg.object_id = i.object_id
AND
pg.index_id = i.index_id
INNER JOIN sys.partitions AS p
ON pg.partition_id = p.partition_id;
Před spuštěním tohoto dotazu nahraďte <file_id> a <page_id> zástupné symboly skutečnými hodnotami z chybové zprávy, kterou jste obdrželi. Pokud je například zpráva Prázdná stránka 1:62669 nelze uvolnit, pak <file_id> je 1 a <page_id> je 62669.
Znovu sestavte index identifikovaný dotazem a zkuste příkaz shrink zopakovat.
- Číslo chyby: 5201, chybová zpráva: DBCC SHRINKDATABASE: ID souboru %d ID databáze %d bylo vynecháno, protože soubor nemá dostatek volného místa pro uvolnění paměti.
Tato chyba znamená, že datový soubor nelze dále zmenšit. Můžete přejít k dalšímu datovému souboru.
Související obsah
Informace o maximální velikosti databáze najdete tady:
- Omezení nákupního modelu založeného na virtuálních jádrech služby Azure SQL Database pro jednu databázi
- Limity prostředků pro jednoúčelové databáze využívající nákupní model založený na jednotkách DTU
- Omezení nákupního modelu založeného na virtuálních jádrech azure SQL Database pro elastické fondy
- Omezení prostředků pro elastické fondy pomocí nákupního modelu založeného na DTU