Migrace služby Azure SQL Database z modelu založeného na DTU na model založený na virtuálních jádrech
Platí pro: ![]() Azure SQL Database
Azure SQL Database
Tento článek popisuje, jak migrovat databázi ve službě Azure SQL Database z nákupního modelu založeného na DTU na nákupní model založený na virtuálních jádrech.
Migrace databáze
Migrace databáze z nákupního modelu založeného na DTU na nákupní model založený na virtuálních jádrech se podobá škálování mezi cíli služby v úrovních služby Basic, Standard a Premium s podobnou dobou trvání a minimálními výpadky na konci procesu migrace. Databázi migrovanou na nákupní model založený na virtuálních jádrech je možné kdykoli migrovat zpět do nákupního modelu založeného na DTU pomocí stejných kroků s výjimkou databází migrovaných na úroveň služby Hyperscale .
Databázi můžete migrovat do jiného nákupního modelu pomocí webu Azure Portal, PowerShellu, Azure CLI a Jazyka Transact-SQL.
Pokud chcete migrovat databázi na jiný nákupní model pomocí webu Azure Portal, postupujte takto:
Přejděte do databáze SQL na webu Azure Portal.
V části Nastavení vyberte Výpočty a úložiště.
Pomocí rozevíracího seznamu v části Úroveň služby vyberte nový nákupní model a úroveň služby:
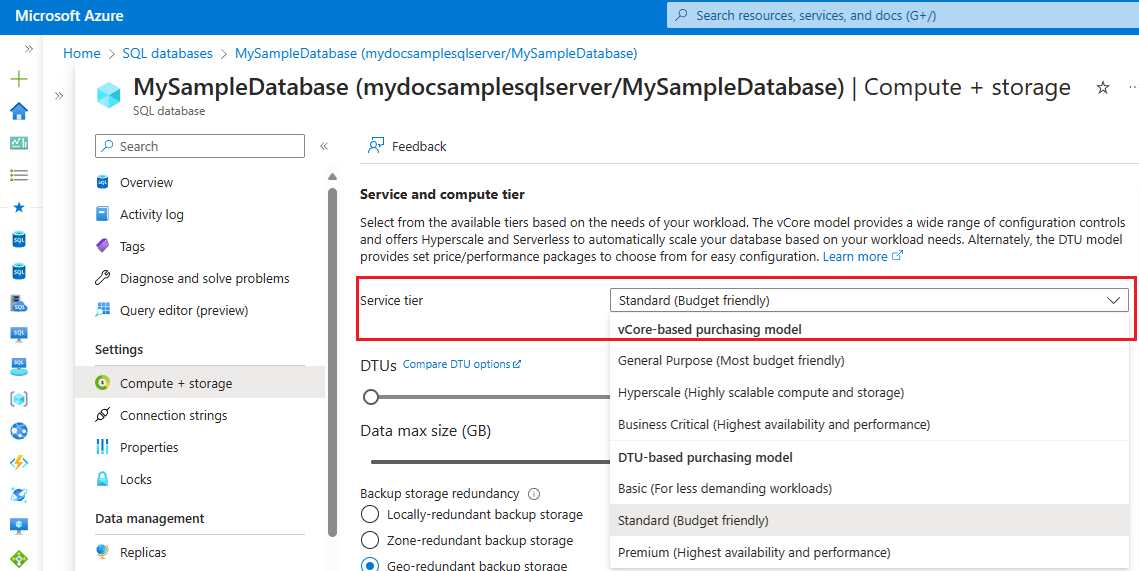

Volba úrovně služby a cíle služby virtuálních jader
U většiny scénářů migrace DTU na virtuální jádra, databází a elastických fondů na úrovni služby Basic a Standard se mapují na úroveň služby Pro obecné účely . Databáze a elastické fondy na úrovni služby Premium se mapují na úroveň služby Pro důležité obchodní informace. V závislosti na scénáři aplikace a požadavcích se úroveň služby Hyperscale často dá použít jako cíl migrace pro databáze a elastické fondy ve všech úrovních služby DTU.
Pokud chcete zvolit cíl služby nebo velikost výpočetních prostředků pro migrovanou databázi v modelu virtuálních jader, můžete použít základní, ale přibližné pravidlo: každých 100 DTU na úrovni Basic nebo Standard vyžaduje alespoň 1 virtuální jádro a každých 125 DTU na úrovni Premium vyžaduje alespoň 1 virtuální jádro.
Tip
Toto pravidlo je přibližné, protože nebere v úvahu konkrétní typ hardwaru používaného pro databázi DTU nebo elastický fond.
V modelu DTU může systém vybrat jakoukoli dostupnou hardwarovou konfiguraci pro vaši databázi nebo elastický fond. V modelu DTU máte navíc nepřímou kontrolu nad počtem virtuálních jader (logických procesorů) výběrem vyšších nebo nižších hodnot DTU nebo eDTU.
V modelu virtuálních jader musí zákazníci explicitně zvolit konfiguraci hardwaru i počet virtuálních jader (logické procesory). I když model DTU tyto volby nenabízí, typ hardwaru a počet logických procesorů používaných pro každou databázi a elastický fond se zveřejňují prostřednictvím zobrazení dynamické správy. To umožňuje přesněji určit odpovídající cíl služby virtuálních jader.
Následující přístup používá tyto informace k určení cíle služby virtuálních jader s podobným přidělením prostředků k získání podobné úrovně výkonu po migraci na model virtuálních jader.
Mapování DTU na virtuální jádra
Následující dotaz Transact-SQL při spuštění v kontextu databáze DTU, která se má migrovat, vrátí odpovídající (pravděpodobně zlomkový) počet virtuálních jader v každé konfiguraci hardwaru v modelu virtuálních jader. Toto číslo můžete zaokrouhlit na nejbližší počet virtuálních jader dostupných pro databáze a elastické fondy v každé konfiguraci hardwaru v modelu virtuálních jader. Zákazníci můžou zvolit cíl služby virtuálních jader, který je nejblíže své databázi DTU nebo elastickému fondu.
Ukázkové scénáře migrace pomocí tohoto přístupu jsou popsány v části Příklady .
Tento dotaz spusťte v kontextu databáze, která se má migrovat, a ne v master databázi. Při migraci elastického fondu spusťte dotaz v kontextu jakékoli databáze ve fondu.
;WITH dtu_vcore_map
AS (
SELECT rg.slo_name,
CAST(DATABASEPROPERTYEX(DB_NAME(), 'Edition') AS NVARCHAR(40)) COLLATE DATABASE_DEFAULT AS dtu_service_tier,
CASE
WHEN slo.slo_name LIKE '%SQLG4%' THEN 'Gen4' --Gen4 is retired.
WHEN slo.slo_name LIKE '%SQLGZ%' THEN 'Gen4' --Gen4 is retired.
WHEN slo.slo_name LIKE '%SQLG5%' THEN 'standard_series'
WHEN slo.slo_name LIKE '%SQLG6%' THEN 'standard_series'
WHEN slo.slo_name LIKE '%SQLG7%' THEN 'standard_series'
WHEN slo.slo_name LIKE '%GPGEN8%' THEN 'standard_series'
END COLLATE DATABASE_DEFAULT AS dtu_hardware_gen,
s.scheduler_count * CAST(rg.instance_cap_cpu / 100. AS DECIMAL(3, 2)) AS dtu_logical_cpus,
CAST((jo.process_memory_limit_mb / s.scheduler_count) / 1024. AS DECIMAL(4, 2)) AS dtu_memory_per_core_gb
FROM sys.dm_user_db_resource_governance AS rg
CROSS JOIN (
SELECT COUNT(1) AS scheduler_count
FROM sys.dm_os_schedulers
WHERE status COLLATE DATABASE_DEFAULT = 'VISIBLE ONLINE'
) AS s
CROSS JOIN sys.dm_os_job_object AS jo
CROSS APPLY (SELECT UPPER(rg.slo_name) COLLATE DATABASE_DEFAULT AS slo_name) slo
WHERE rg.dtu_limit > 0
AND DB_NAME() COLLATE DATABASE_DEFAULT <> 'master'
AND rg.database_id = DB_ID()
)
SELECT dtu_logical_cpus,
dtu_memory_per_core_gb,
dtu_service_tier,
CASE
WHEN dtu_service_tier = 'Basic' THEN 'General Purpose'
WHEN dtu_service_tier = 'Standard' THEN 'General Purpose or Hyperscale'
WHEN dtu_service_tier = 'Premium' THEN 'Business Critical or Hyperscale'
END AS vcore_service_tier,
CASE
WHEN dtu_hardware_gen = 'Gen4' THEN dtu_logical_cpus * 1.7
WHEN dtu_hardware_gen = 'standard_series' THEN dtu_logical_cpus
END AS standard_series_vcores,
5.05 AS standard_series_memory_per_core_gb,
CASE
WHEN dtu_hardware_gen = 'Gen4' THEN dtu_logical_cpus
WHEN dtu_hardware_gen = 'standard_series' THEN dtu_logical_cpus * 0.8
END AS Fsv2_vcores,
1.89 AS Fsv2_memory_per_core_gb,
CASE
WHEN dtu_hardware_gen = 'Gen4' THEN dtu_logical_cpus * 1.4
WHEN dtu_hardware_gen = 'standard_series' THEN dtu_logical_cpus * 0.9
END AS M_vcores,
29.4 AS M_memory_per_core_gb
FROM dtu_vcore_map;
Další faktory
Kromě počtu virtuálních jader (logických procesorů) a typu hardwaru může ovlivnit výběr cíle služby virtuálních jader několik dalších faktorů:
Mapování dotazů Transact-SQL odpovídá cílům služby DTU a virtuálních jader z hlediska kapacity procesoru, takže výsledky jsou přesnější pro úlohy vázané na procesor.
U stejného typu hardwaru a stejného počtu virtuálních jader jsou limity prostředků propustnosti vstupně-výstupních operací a transakčních protokolů pro databáze virtuálních jader často vyšší než u databází DTU. U úloh vázaných na vstupně-výstupní operace může být možné snížit počet virtuálních jader v modelu virtuálních jader, aby se dosáhlo stejné úrovně výkonu. Skutečné limity prostředků pro databáze DTU a virtuální jádra se zveřejňují v zobrazení sys.dm_user_db_resource_governance . Porovnání těchto hodnot mezi databází nebo fondem DTU, které se mají migrovat, a databází nebo fondem virtuálních jader s přibližně odpovídajícím cílem služby vám může pomoct přesněji vybrat cíl služby virtuálních jader.
Dotaz mapování také vrátí velikost paměti na jádro pro databázi DTU nebo elastický fond, který se má migrovat, a pro každou konfiguraci hardwaru v modelu virtuálních jader. Zajištění podobné nebo vyšší celkové paměti po migraci na virtuální jádro je důležité pro úlohy, které k dosažení dostatečného výkonu vyžadují velkou mezipaměť dat paměti, nebo úlohy, které vyžadují udělení velké paměti pro zpracování dotazů. U takových úloh může být nutné v závislosti na skutečném výkonu zvýšit počet virtuálních jader, aby se získala dostatečná celková paměť.
Při výběru cíle služby virtuálních jader je potřeba zvážit historické využití prostředků databáze DTU. Databáze DTU s konzistentně nevyužitými prostředky procesoru můžou potřebovat méně virtuálních jader než počet vrácený mapovacím dotazem. Naopak databáze DTU, kde konzistentně vysoké využití procesoru způsobuje nedostatečný výkon úloh, můžou vyžadovat více virtuálních jader, než vrací dotaz.
Pokud migrujete databáze s přerušovanými nebo nepředvídatelnými vzory využití, zvažte použití bezserverové výpočetní úrovně pro výpočetní úroveň služby Azure SQL Database . Maximální počet souběžných pracovních procesů v bezserverové verzi je 75 % limitu zřízeného výpočetního výkonu pro stejný počet nakonfigurovaných maximálních virtuálních jader. Maximální velikost paměti dostupná v bezserverové verzi je 3 GB, kolikrát je nakonfigurovaný maximální počet virtuálních jader, což je menší než paměť na jádro pro zřízené výpočetní prostředky. Například maximální paměť Gen5 je 120 GB, když je v bezserverové konfiguraci 40 virtuálních jader vs. 204 GB zřízeného výpočetního výkonu 40 virtuálních jader.
V modelu virtuálních jader se podporovaná maximální velikost databáze může lišit v závislosti na hardwaru. U velkých databází zkontrolujte podporované maximální velikosti v modelu virtuálních jader pro izolované databáze a elastické fondy.
U elastických fondů platí omezení prostředků pro elastické fondy využívající nákupní model DTU a modely virtuálních jader rozdíly v maximálním podporovaném počtu databází na fond. Měli byste to zvážit při migraci elastických fondů s mnoha databázemi.
Některé konfigurace hardwaru nemusí být dostupné v každé oblasti. Zkontrolujte dostupnost v části Konfigurace hardwaru pro SLUŽBU SQL Database.
Pokyny pro změnu velikosti DTU pro virtuální jádra uvedené v této části vám pomůžou s počátečním odhadem cíle cílové databázové služby.
Optimální konfigurace cílové databáze je závislá na úlohách. Abyste tedy po migraci dosáhli optimálního poměru ceny a výkonu, možná budete muset použít flexibilitu modelu virtuálních jader, abyste upravili počet virtuálních jader, konfiguraci hardwaru a úrovně služeb a výpočetních prostředků. Možná budete také muset upravit parametry konfigurace databáze, jako je maximální stupeň paralelismu, nebo změnit úroveň kompatibility databáze, aby se povolila nedávná vylepšení databázového stroje.
Příklady migrace DTU na virtuální jádra
Poznámka:
Hodnoty v následujících příkladech jsou určené pouze pro ilustraci. Skutečné hodnoty vrácené v popsaných scénářích se můžou lišit.
Migrace databáze Standard S9
Dotaz mapování vrátí následující výsledek (některé sloupce se nezobrazují kvůli stručnosti):
| dtu_logical_cpus | dtu_memory_per_core_gb | standard_series_vcores | standard_series_memory_per_core_gb |
|---|---|---|---|
| 24,00 | 5.40 | 24.000 | 5,05 |
Vidíme, že standardní databáze DTU má 24 logických procesorů (virtuálních jader) s 5,4 GB paměti na virtuální jádro. Přímá shoda s databází pro obecné účely 2 virtuálních jader na hardwaru řady Standard (Gen5) GP_Gen5_24 cíle služby virtuálních jader.
Migrace databáze Standard S0
Dotaz mapování vrátí následující výsledek (některé sloupce se nezobrazují kvůli stručnosti):
| dtu_logical_cpus | dtu_memory_per_core_gb | standard_series_vcores | standard_series_memory_per_core_gb |
|---|---|---|---|
| 0.25 | 1.3 | 0.500 | 5,05 |
Vidíme, že databáze DTU má ekvivalent 0,25 logických procesorů (virtuálních jader) s 1,3 GB paměti na virtuální jádro. Nejmenší cíle služby virtuálních jader v konfiguraci hardwaru řady Standard (Gen5) GP_Gen5_2 poskytují více výpočetních prostředků než databáze Standard S0, takže přímá shoda není možná. Preferuje se možnost GP_Gen5_2 . Pokud je navíc úloha vhodná pro bezserverovou výpočetní úroveň, bude GP_S_Gen5_1 blíže odpovídat.
Migrace databáze Premium P15
Dotaz mapování vrátí následující výsledek (některé sloupce se nezobrazují kvůli stručnosti):
| dtu_logical_cpus | dtu_memory_per_core_gb | standard_series_vcores | standard_series_memory_per_core_gb |
|---|---|---|---|
| 42.00 | 4.86 | 42.000 | 5,05 |
Vidíme, že databáze DTU má 42 logických procesorů (virtuálních jader) s 4,86 GB paměti na virtuální jádro. I když neexistuje cíl služby virtuálních jader se 42 jádry, cíl služby BC_Gen5_40 je téměř ekvivalentní z hlediska kapacity procesoru a paměti a je to dobrá shoda.
Migrace elastického fondu Basic 200 eDTU
Dotaz mapování vrátí následující výsledek (některé sloupce se nezobrazují kvůli stručnosti):
| dtu_logical_cpus | dtu_memory_per_core_gb | standard_series_vcores | standard_series_memory_per_core_gb |
|---|---|---|---|
| 4,00 | 5.40 | 4.000 | 5,05 |
Vidíme, že elastický fond DTU má 4 logické procesory (virtuální jádra) s 5,4 GB paměti na virtuální jádro. Hardware řady Standard vyžaduje 4 virtuální jádra, ale tento cíl služby podporuje maximálně 200 databází na fond, zatímco elastický fond Basic 200 eDTU podporuje až 500 databází. Pokud má elastický fond, který se má migrovat, více než 200 databází, musí být odpovídající cíl služby virtuálních jader GP_Gen5_6, který podporuje až 500 databází.
Migrace geograficky replikovaných databází
Migrace z modelu založeného na DTU na nákupní model založený na virtuálních jádrech se podobá upgradu nebo downgradu vztahů geografické replikace mezi databázemi v úrovních služeb Standard a Premium. Během migrace nemusíte zastavovat geografickou replikaci pro úrovně Služby pro obecné účely a Pro důležité obchodní informace, ale musíte postupovat podle těchto pravidel sekvencování:
- Při upgradu musíte nejprve upgradovat sekundární databázi a pak upgradovat primární databázi.
- Při downgradu přejděte zpět do pořadí: nejprve musíte downgradovat primární databázi a pak downgradovat sekundární databázi.
Pokud chcete migrovat na úroveň služby Hyperscale, je potřeba dočasně odebrat geografickou replikaci. Další informace najdete v tématu Migrace existující databáze do Hyperscale.
Pokud používáte geografickou replikaci mezi dvěma elastickými fondy, doporučujeme určit jeden fond jako primární a druhý jako sekundární. V takovém případě byste při migraci elastických fondů měli použít stejné pokyny pro sekvencování. Pokud ale máte elastické fondy, které obsahují jak primární, tak sekundární databáze, zacházíte s fondem s vyšším využitím jako sekvencováním a odpovídajícím způsobem postupujte podle pravidel sekvencování.
Následující tabulka obsahuje pokyny pro konkrétní scénáře migrace:
| Aktuální úroveň služby | Cílová úroveň služby | Typ migrace | Akce uživatele |
|---|---|---|---|
| Standard | Pro obecné účely | Boční | Může migrovat v libovolném pořadí, ale musí zajistit odpovídající velikost virtuálních jader, jak je popsáno výše. |
| Premium | Pro důležité obchodní informace | Boční | Může migrovat v libovolném pořadí, ale musí zajistit odpovídající velikost virtuálních jader, jak je popsáno výše. |
| Standard | Pro důležité obchodní informace | Upgrade | Musí nejprve migrovat sekundární |
| Pro důležité obchodní informace | Standard | Downgrade | Nejprve je nutné migrovat primární |
| Premium | Pro obecné účely | Downgrade | Nejprve je nutné migrovat primární |
| Pro obecné účely | Premium | Upgrade | Musí nejprve migrovat sekundární |
| Pro důležité obchodní informace | Pro obecné účely | Downgrade | Nejprve je nutné migrovat primární |
| Pro obecné účely | Pro důležité obchodní informace | Upgrade | Musí nejprve migrovat sekundární |
| Standard | Hyperškálování | Boční | Geografická replikace, která se má vypnout před migrací na Hyperscale |
| Premium | Hyperškálování | Boční | Geografická replikace, která se má vypnout před migrací na Hyperscale |
Migrace skupin převzetí služeb při selhání
Migrace skupin převzetí služeb při selhání s více databázemi vyžaduje individuální migraci primárních a sekundárních databází. Během tohoto procesu platí stejné aspekty a pravidla sekvencování. Po převodu databází na nákupní model založený na virtuálních jádrech zůstane skupina převzetí služeb při selhání platná se stejným nastavením zásad.
Vytvoření sekundární databáze geografické replikace
Sekundární databázi geografické replikace (geograficky sekundární) můžete vytvořit pouze pomocí stejné úrovně služby, jakou jste použili pro primární databázi. Pro databáze s vysokou rychlostí generování protokolů doporučujeme vytvořit geografickou sekundární oblast se stejnou velikostí výpočetních prostředků jako primární.
Pokud v elastickém fondu vytvoříte geografickou sekundární oblast pro jednu primární databázi, ujistěte se, že maxVCore nastavení fondu odpovídá velikosti výpočetních prostředků primární databáze. Pokud vytvoříte geografickou sekundární oblast pro primární v jiném elastickém fondu, doporučujeme, aby fondy měly stejná maxVCore nastavení.
Použití kopírování databáze k migraci z DTU na virtuální jádro
Kopírování databáze vytvoří transakční konzistentní snímek dat v určitém okamžiku po spuštění operace kopírování. Nesynchronizuje data mezi zdrojem a cílem po tomto bodu v čase.
Libovolnou databázi s velikostí výpočetních prostředků založenou na DTU můžete zkopírovat do databáze s výpočetní velikostí založenou na virtuálních jádrech pomocí PowerShellu, Azure CLI nebo Transact-SQL bez omezení nebo speciálního sekvencování, pokud cílová velikost výpočetních prostředků podporuje maximální velikost databáze zdrojové databáze. Kopírování databáze do jiné úrovně služby se na webu Azure Portal nepodporuje.