Nákupní model virtuálních jader – Azure SQL Database
Platí pro: ![]() Azure SQL Database
Azure SQL Database
Tento článek se zabývá nákupním modelem virtuálních jader pro Azure SQL Database.
Přehled
Virtuální jádro (virtuální jádro) představuje logický procesor a nabízí možnost zvolit fyzické charakteristiky hardwaru (například počet jader, paměť a velikost úložiště). Nákupní model založený na virtuálních jádrech poskytuje flexibilitu, kontrolu, transparentnost využití jednotlivých prostředků a jednoduchý způsob, jak převést požadavky na místní úlohy do cloudu. Tento model optimalizuje cenu a umožňuje zvolit výpočetní prostředky, paměť a prostředky úložiště na základě vašich potřeb úloh.
V nákupním modelu založeném na virtuálních jádrech závisí vaše náklady na volbu a využití:
- Úroveň služby
- Hardwarová konfigurace
- Výpočetní prostředky (počet virtuálních jader a velikost paměti)
- Rezervované úložiště databáze
- Skutečné úložiště zálohování
Důležité
Výpočetní prostředky, vstupně-výstupní operace a úložiště dat a protokolů se účtují na databázi nebo elastický fond. Úložiště zálohování se účtuje pro každou databázi. Podrobnosti o cenách najdete na stránce s cenami služby Azure SQL Database.
Porovnání nákupních modelů virtuálních jader a DTU
Nákupní model virtuálních jader používaný službou Azure SQL Database poskytuje oproti nákupnímu modelu založenému na DTU několik výhod:
- Vyšší limity výpočetních prostředků, paměti, vstupně-výstupních operací a úložiště.
- Volba konfigurace hardwaru, která bude lépe odpovídat požadavkům na výpočetní výkon a paměť úlohy.
- Cenové slevy pro Zvýhodněné hybridní využití Azure (AHB)
- Větší transparentnost podrobností o hardwaru, které podporují výpočetní výkon, což usnadňuje plánování migrací z místních nasazení.
- Ceny rezervovaných instancí jsou dostupné jenom pro nákupní model virtuálních jader.
- Vyšší členitost škálování s více dostupnými velikostmi výpočetních prostředků
Nápovědu k výběru nákupních modelů virtuálních jader a DTU najdete v rozdílech mezi nákupními modely založenými na virtuálních jádrech a DTU.
Compute
Nákupní model založený na virtuálních jádrech má zřízenou výpočetní úroveň a bezserverovou výpočetní úroveň. Ve zřízené úrovni výpočetních prostředků odráží náklady na výpočetní prostředky celkovou výpočetní kapacitu nepřetržitě zřízenou pro aplikaci nezávislou na aktivitě úloh. Vyberte přidělení prostředků, které nejlépe vyhovuje potřebám vaší firmy, na základě požadavků na virtuální jádro a paměť a podle potřeby vertikálně navyšte kapacitu prostředků podle potřeby vaší úlohy. Na úrovni výpočetních prostředků bez serveru pro Azure SQL Database se výpočetní prostředky automaticky škálují na základě kapacity úloh a účtují se za využité výpočetní prostředky za sekundu.
Shrnutí:
- Zatímco zřízená výpočetní úroveň poskytuje konkrétní množství výpočetních prostředků, které jsou nepřetržitě zřízené nezávisle na aktivitě úloh, bezserverová výpočetní úroveň automaticky škáluje výpočetní prostředky na základě aktivity úloh.
- I když se zřízená úroveň výpočetních prostředků účtuje za množství výpočetních prostředků zřízených za pevnou cenu za hodinu, bezserverová výpočetní úroveň se účtuje za množství využitých výpočetních prostředků za sekundu.
Bez ohledu na úroveň výpočetních prostředků se na úrovni služby Pro důležité obchodní informace automaticky přidělují tři další sekundární repliky s vysokou dostupností, aby se zajistila vysoká odolnost proti selháním a rychlému převzetí služeb při selhání. Tyto další repliky činí náklady přibližně 2,7krát vyšší, než je na úrovni služby Pro obecné účely. Stejně tak vyšší náklady na úložiště za GB ve vrstvě služby Pro důležité obchodní informace odráží vyšší limity vstupně-výstupních operací a nižší latenci místního úložiště SSD.
Zákazníci v Hyperscale řídí počet dalších replik s vysokou dostupností od 0 do 4, aby získali úroveň odolnosti vyžadovanou aplikacemi a současně kontrolovali náklady.
Další informace o výpočetních prostředcích ve službě Azure SQL Database najdete v tématu Výpočetní prostředky (procesor a paměť).
Omezení prostředků
V případě limitů prostředků virtuálních jader zkontrolujte dostupné konfigurace hardwaru a zkontrolujte limity prostředků pro:
Úložiště dat a protokolů
Následující faktory ovlivňují množství úložiště používaného pro soubory dat a protokolů a platí pro úrovně Pro obecné účely a Pro důležité obchodní informace.
- Každá velikost výpočetních prostředků podporuje konfigurovatelnou maximální velikost dat s výchozím nastavením 32 GB.
- Při konfiguraci maximální velikosti dat se automaticky přidá 30 procent fakturovatelného úložiště pro soubor protokolu.
- Na úrovni
tempdbslužby Pro obecné účely se používá místní úložiště SSD a tyto náklady na úložiště jsou zahrnuté v ceně za virtuální jádro. - Na úrovni
tempdbslužby Pro důležité obchodní informace sdílí místní úložiště SSD se soubory dat a protokolů atempdbnáklady na úložiště jsou zahrnuté v ceně virtuálního jádra. - V úrovních Pro obecné účely a Pro důležité obchodní informace se vám účtuje maximální velikost úložiště nakonfigurovaná pro databázi nebo elastický fond.
- Pro SLUŽBU SQL Database můžete vybrat libovolnou maximální velikost dat mezi 1 GB a maximální podporovanou velikostí úložiště v přírůstcích po 1 GB.
Následující aspekty úložiště platí pro Hyperscale:
- Maximální velikost úložiště dat je nastavená na 128 TB a není konfigurovatelná.
- Účtuje se vám jenom přidělené úložiště dat, ne za maximální úložiště dat.
- Za úložiště protokolů se vám neúčtují poplatky.
tempdbvyužívá místní úložiště SSD a jeho náklady jsou zahrnuté v ceně virtuálních jader. Pokud chcete monitorovat aktuální přidělenou a použitou velikost úložiště dat ve službě SQL Database, použijte metriky služby Azure Monitor allocated_data_storage a úložiště.
Pokud chcete monitorovat aktuální přidělenou a použitou velikost úložiště jednotlivých dat a souborů protokolu v databázi pomocí T-SQL, použijte zobrazení sys.database_files a funkci FILEPROPERTY(... , SpaceUsed).
Tip
Za určitých okolností možná budete muset zmenšit databázi, aby se uvolnilo nevyužité místo. Další informace najdete v tématu Správa prostoru souborů ve službě Azure SQL Database.
Úložiště zálohování
Úložiště pro zálohy databáze je přiděleno pro podporu obnovení k určitému bodu v čase (PITR) a funkcí dlouhodobého uchovávání (LTR) služby SQL Database. Toto úložiště je oddělené od úložiště dat a souborů protokolů a účtuje se samostatně.
- PitR: V úrovních Pro obecné účely a Pro důležité obchodní informace se jednotlivé zálohy databáze zkopírují do úložiště Azure automaticky. Velikost úložiště se dynamicky zvyšuje při vytváření nových záloh. Úložiště se používá úplnými, rozdílovými a transakčními zálohami protokolů. Spotřeba úložiště závisí na rychlosti změny databáze a době uchovávání nakonfigurované pro zálohy. Pro každou databázi můžete nakonfigurovat samostatnou dobu uchovávání mezi 1 a 35 dny pro službu SQL Database. Za příplatek se poskytuje velikost úložiště zálohování, která se rovná nakonfigurované maximální velikosti dat.
- LTR: Můžete také nakonfigurovat dlouhodobé uchovávání úplných záloh po dobu až 10 let. Pokud nastavíte zásadu LTR, tyto zálohy se ukládají v úložišti objektů blob v Azure automaticky, ale můžete řídit, jak často se zálohy kopírují. Pokud chcete splnit různé požadavky na dodržování předpisů, můžete vybrat různá období uchovávání týdenních, měsíčních nebo ročních záloh. Zvolená konfigurace určuje, kolik úložiště se používá pro zálohy LTR. Další informace najdete v tématu Dlouhodobé uchovávání záloh.
Úložiště záloh v Hyperscale najdete v tématu Automatizované zálohování databází Hyperscale.
Úrovně služby
Mezi možnosti úrovně služeb v nákupním modelu virtuálních jader patří Obecné účely, Pro důležité obchodní informace a Hyperscale. Úroveň služby obecně určuje typ a výkon úložiště, vysokou dostupnost a možnosti zotavení po havárii a dostupnost určitých funkcí, jako je OLTP v paměti.
| Případ použití | Obecné použití | Pro důležité obchodní informace | Hyperškálování |
|---|---|---|---|
| Nejlepší pro | Většina obchodních úloh. Nabízí uživatelsky orientované, vyvážené a škálovatelné možnosti výpočtů a úložiště. | Nabízí podnikovým aplikacím nejvyšší odolnost proti chybám pomocí několika sekundárních replik s vysokou dostupností a poskytuje nejvyšší výkon vstupně-výstupních operací. | Široká škála úloh, včetně těchto úloh s vysoce škálovatelnými požadavky na úložiště a škálování čtení. Nabízí vyšší odolnost proti chybám tím, že umožňuje konfiguraci více než jedné sekundární repliky s vysokou dostupností. |
| Velikost výpočetních prostředků | 2 až 128 virtuálních jader | 2 až 128 virtuálních jader | 2 až 128 virtuálních jader |
| Typ úložiště | Vzdálené úložiště úrovně Premium (na instanci) | Superrychlé místní úložiště SSD (na instanci) | Oddělené úložiště s místní mezipamětí SSD (na výpočetní repliku) |
| Velikost úložiště | 1 GB – 4 TB | 1 GB – 4 TB | 10 GB – 128 TB |
| IOPS | 320 IOPS na virtuální jádro s maximálním počtem 16 000 IOPS | 4 000 IOPS na virtuální jádro s maximálním počtem IOPS 327 680 | 327 680 IOPS s maximálním místním SSD Hyperscale je vícevrstvá architektura s ukládáním do mezipaměti na více úrovních. Efektivní IOPS závisí na úloze. |
| Paměť/virtuální jádro | 5,1 GB | 5,1 GB | 5,1 GB nebo 10,2 GB |
| Zálohování | Volba geograficky redundantního, zónově redundantního nebo místně redundantního úložiště zálohování, uchovávání 1–35 dnů (výchozí 7 dnů) Dlouhodobé uchovávání je k dispozici až 10 let |
Volba geograficky redundantního, zónově redundantního nebo místně redundantního úložiště zálohování, uchovávání 1–35 dnů (výchozí 7 dnů) Dlouhodobé uchovávání je k dispozici až 10 let |
Volba místně redundantního úložiště (LRS), zónově redundantního úložiště (ZRS) nebo geograficky redundantního úložiště (GRS) Uchovávání 1–35 dnů (ve výchozím nastavení 7 dnů) s až 10 lety dlouhodobého uchovávání |
| Dostupnost | Jedna replika, žádné repliky pro čtení, zónově redundantní vysoká dostupnost (HA) |
Tři repliky, jedna replika na úrovni čtení, zónově redundantní vysoká dostupnost (HA) |
zónově redundantní vysoká dostupnost (HA) |
| Ceny a fakturace | Za virtuální jádro, rezervované úložiště a úložiště zálohování se účtují poplatky. IOPS se neúčtují. |
Za virtuální jádro, rezervované úložiště a úložiště zálohování se účtují poplatky. IOPS se neúčtují. |
Virtuální jádro pro každou repliku a využité úložiště se účtují. IOPS se neúčtují. |
| Modely slev | Rezervované instance Zvýhodněné hybridní využití Azure (není k dispozici pro předplatná pro vývoj/testování) Předplatná nabídek enterprise a Průběžné platby dle aktuálního využití pro vývoj/testování |
Rezervované instance Zvýhodněné hybridní využití Azure (není k dispozici pro předplatná pro vývoj/testování) Předplatná nabídek enterprise a Průběžné platby dle aktuálního využití pro vývoj/testování |
Zvýhodněné hybridní využití Azure (není k dispozici pro předplatná pro vývoj/testování) 1 Předplatná nabídek enterprise a Průběžné platby dle aktuálního využití pro vývoj/testování |
| Tabulky OLTP v paměti | No | Ano | Ne |
1 Zjednodušená cena pro SQL Database Hyperscale připravujeme. Podrobnosti najdete na blogu s cenami Hyperscale.
Podrobnější informace najdete v omezeních prostředků pro logický server, izolované databáze a databáze ve fondu.
Poznámka:
Další informace o smlouvě o úrovni služeb (SLA) najdete ve smlouvě SLA pro Azure SQL Database.
Pro obecné účely
Model architektury pro úroveň služby Pro obecné účely je založený na oddělení výpočetních prostředků a úložiště. Tento model architektury závisí na vysoké dostupnosti a spolehlivosti služby Azure Blob Storage, která transparentně replikuje databázové soubory a zaručuje, že nedojde k selhání základní infrastruktury.
Následující obrázek znázorňuje čtyři uzly ve standardním modelu architektury s oddělenými výpočetními vrstvami a vrstvami úložiště.
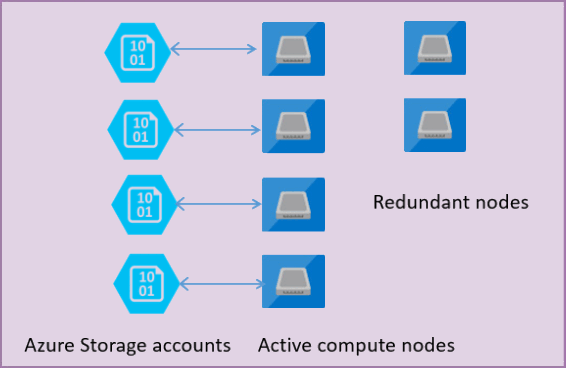
V modelu architektury pro úroveň služby Pro obecné účely existují dvě vrstvy:
- Bezstavová výpočetní vrstva, která spouští
sqlservr.exeproces a obsahuje pouze přechodná data a data uložená v mezipaměti (například plán mezipaměti, fond vyrovnávací paměti, fond columnstore). Tento bezstavový uzel provozuje Azure Service Fabric, který inicializuje proces, řídí stav uzlu a v případě potřeby provádí převzetí služeb při selhání na jiné místo. - Stavová datová vrstva se soubory databáze (.mdf/.ldf), které jsou uložené ve službě Azure Blob Storage. Azure Blob Storage zaručuje, že nedojde ke ztrátě dat žádného záznamu umístěného v žádném databázovém souboru. Azure Storage má integrovanou dostupnost a redundanci dat, která zajišťuje, že každý záznam v souboru protokolu nebo stránce v datovém souboru se zachová i v případě, že proces selže.
Při každém upgradu databázového stroje nebo operačního systému dojde k selhání některé části základní infrastruktury nebo zjištění nějakého kritického problému v sqlservr.exe procesu, Azure Service Fabric přesune bezstavový proces do jiného bezstavového výpočetního uzlu. Existuje sada náhradních uzlů, které čekají na spuštění nové výpočetní služby, pokud dojde k převzetí služeb při selhání primárního uzlu, aby se minimalizovala doba převzetí služeb při selhání. Data ve vrstvě úložiště Azure nejsou ovlivněná a k nově inicializovanému procesu se připojují soubory dat a protokolů. Tento proces zaručuje ve výchozím nastavení 99,99% dostupnost a 99,995% dostupnost, pokud je povolená redundance zóny. Kvůli době přechodu může mít vliv na výkon náročných úloh a skutečnost, že nový uzel začíná studenou mezipamětí.
Kdy zvolit tuto úroveň služby
Úroveň služby Pro obecné účely je výchozí úrovní služby ve službě Azure SQL Database určená pro většinu obecných úloh. Pokud potřebujete plně spravovaný databázový stroj s výchozí smlouvou SLA a latencí úložiště mezi 5 ms a 10 ms, je pro vás úroveň Pro obecné účely dostupná.
Pro důležité obchodní informace
Model vrstvy služby Pro důležité obchodní informace je založený na clusteru procesů databázového stroje. Tento model architektury spoléhá na kvorum uzlů databázového stroje, aby se minimalizoval dopad na výkon vaší úlohy, a to i během aktivit údržby. Upgrady a opravy základního operačního systému, ovladačů a databázového stroje probíhají transparentně s minimálním výpadkem pro koncové uživatele.
V modelu Pro důležité obchodní informace se výpočetní prostředky a úložiště integrují do každého uzlu. Replikace dat mezi procesy databázového stroje na každém uzlu clusteru se čtyřmi uzly dosahuje vysoké dostupnosti, přičemž každý uzel používá místně připojené jednotky SSD jako úložiště dat. Následující diagram znázorňuje, jak Pro důležité obchodní informace úroveň služby organizuje cluster uzlů databázového stroje v replikách skupiny dostupnosti.

Proces databázového stroje i základní soubory .mdf/.ldf jsou umístěné na stejném uzlu s místně připojeným úložištěm SSD a poskytují tak nízkou latenci vaší úlohy. Vysoká dostupnost se implementuje pomocí technologie podobné skupinám dostupnosti AlwaysOn SQL Serveru. Každá databáze je cluster databázových uzlů s jednou primární replikou, která je přístupná pro úlohy zákazníků, a tři sekundární repliky obsahující kopie dat. Primární replika neustále odesílá změny do sekundárních replik, aby se zajistila dostupnost dat na sekundárních replikách, pokud primární z nějakého důvodu selže. Služba Service Fabric zpracovává převzetí služeb při selhání a databázový stroj – jedna sekundární replika se stane primární a vytvoří se nová sekundární replika, která zajistí, že v clusteru je dostatek uzlů. Úloha se automaticky přesměruje na novou primární repliku.
Kromě toho má cluster Pro důležité obchodní informace integrovanou funkci čtení se škálováním na více systémů, která poskytuje bezplatnou repliku jen pro čtení, která slouží ke spouštění dotazů jen pro čtení (například sestav), které nebudou mít vliv na výkon úlohy na primární replice.
Kdy zvolit tuto úroveň služby
Úroveň služby Pro důležité obchodní informace je určená pro aplikace, které vyžadují odpovědi s nízkou latencí z podkladového úložiště SSD (průměr 1–2 ms), rychlejší obnovení, pokud základní infrastruktura selže, nebo vyžadují dotazy, které jsou mimo zatížení, analýzy a dotazy jen pro čtení na bezplatnou čitelnou sekundární repliku primární databáze.
Klíčové důvody, proč byste měli místo úrovně Pro obecné účely zvolit Pro důležité obchodní informace úroveň služby:
- Požadavky na nízkou latenci vstupně-výstupních operací – úlohy, které potřebují konzistentně rychlou odezvu z vrstvy úložiště (průměr 1–2 milisekund), by měly používat Pro důležité obchodní informace vrstvu.
- Úloha s dotazy pro generování sestav a analýzu, kde stačí jedna bezplatná sekundární replika jen pro čtení.
- Vyšší odolnost proti chybám a rychlejší obnovení. V případě selhání systému je databáze v primární instanci zakázaná a jednou ze sekundárních replik se okamžitě stane nová primární databáze pro čtení i zápis připravená ke zpracování dotazů.
- Rozšířená ochrana proti poškození dat Vzhledem k tomu, že úroveň Pro důležité obchodní informace používá repliky databází na pozadí, služba používá automatickou opravu stránky dostupnou se zrcadlováním a skupinami dostupnosti, aby se zmírnit poškození dat. Pokud replika nemůže přečíst stránku kvůli problému s integritou dat, načte se nová kopie stránky z jiné repliky a nahradí nečitelný stránku bez ztráty dat nebo výpadku zákazníka. Tato funkce je dostupná na úrovni Pro obecné účely, pokud má databáze geograficky sekundární repliku.
- Vyšší dostupnost – úroveň Pro důležité obchodní informace v konfiguraci zóny s více dostupnostmi zajišťuje odolnost proti zónovým selháním a vyšší úrovni dostupnosti.
- Rychlé geografické obnovení – Pokud je nakonfigurovaná aktivní geografická replikace, úroveň Pro důležité obchodní informace má zaručený cíl bodu obnovení (RPO) 5 sekund a plánovanou dobu obnovení (RTO) 30 sekund po dobu 100 % nasazených hodin.
Hyperškálování
Úroveň služby Hyperscale je vhodná pro všechny typy úloh. Její nativní architektura cloudu poskytuje nezávisle škálovatelné výpočetní prostředky a úložiště pro podporu široké škály tradičních a moderních aplikací. Výpočetní prostředky a prostředky úložiště v Hyperscale výrazně překračují prostředky dostupné na úrovních Pro obecné účely a Pro důležité obchodní informace.
Další informace najdete v tématu Úroveň služby Hyperscale pro Azure SQL Database.
Kdy zvolit tuto úroveň služby
Úroveň služby Hyperscale odebere mnoho praktických omezení, která se tradičně zobrazují v cloudových databázích. Pokud je většina ostatních databází omezena prostředky dostupnými v jednom uzlu, nemají databáze na úrovni služby Hyperscale žádné takové limity. S flexibilní architekturou úložiště roste databáze Hyperscale podle potřeby – a účtuje se vám jenom kapacita úložiště, kterou používáte.
Kromě pokročilých možností škálování je Hyperscale skvělou volbou pro všechny úlohy, nejen pro velké databáze. Hyperscale umožňuje:
- Zajištění vysoké odolnosti a rychlého zotavení po selhání při řízení nákladů výběrem počtu replik s vysokou dostupností od 0 do 4.
- Zvýšení vysoké dostupnosti povolením redundance zón pro výpočetní prostředky a úložiště
- U často používané části databáze dosáhnete nízké latence vstupně-výstupních operací (průměrně 1–2 milisekund). U menších databází to může platit pro celou databázi.
- Implementujte širokou škálu scénářů škálování čtení na více instancí s pojmenovanými replikami.
- Využijte výhod rychlého škálování bez čekání na zkopírování dat do místního úložiště na nových uzlech.
- Užijte si nepřetržité zálohování databáze s nulovým dopadem a rychlé obnovení.
- Podpora požadavků na provozní kontinuitu s využitím skupin převzetí služeb při selhání a geografické replikace
Hardwarová konfigurace
Mezi běžné konfigurace hardwaru v modelu virtuálních jader patří standard-series (Gen5), Fsv2-series a DC-series. Hyperscale také nabízí možnost pro hardware optimalizovaný pro paměť optimalizovaný pro řadu Premium a Premium. Konfigurace hardwaru definuje limity výpočetních prostředků a paměti a další charakteristiky, které ovlivňují výkon úloh.
Některé hardwarové konfigurace, jako je řada Standard (Gen5), můžou používat více než jeden typ procesoru (CPU), jak je popsáno ve výpočetních prostředcích (procesoru a paměti). Zatímco daná databáze nebo elastický fond mají tendenci zůstat na hardwaru se stejným typem procesoru po dlouhou dobu (obvykle několik měsíců), existují určité události, které můžou způsobit přesun databáze nebo fondu na hardware, který používá jiný typ procesoru.
Databázi nebo fond je možné přesunout pro různé scénáře, mezi které patří mimo jiné:
- Cíl služby se změní.
- Aktuální infrastruktura v datacentru se blíží limitům kapacity.
- Aktuálně používaný hardware se vyřadí z provozu kvůli konci životnosti.
- Je povolená zónově redundantní konfigurace, přesun na jiný hardware kvůli dostupné kapacitě
U některých úloh může přechod na jiný typ procesoru změnit výkon. SQL Database konfiguruje hardware s cílem zajistit předvídatelný výkon úloh i v případě, že se změní typ procesoru, přičemž změny výkonu se udržují v úzkém pásmu. Nicméně v širokém spektru zákaznických úloh ve službě SQL Database a jakmile budou k dispozici nové typy procesorů, je někdy možné vidět výraznější změny výkonu, pokud se databáze nebo fond přesunou na jiný typ procesoru.
Bez ohledu na použitý typ procesoru zůstanou limity prostředků pro databázi nebo elastický fond (například počet jader, paměť, maximální počet vstupně-výstupních operací za sekundu dat, maximální rychlost protokolu a maximální počet souběžných pracovních procesů) stejné, dokud databáze zůstane na stejném cíli služby.
Výpočetní prostředky (procesor a paměť)
Následující tabulka porovnává výpočetní prostředky v různých konfiguracích hardwaru a úrovních výpočetních prostředků:
| Hardwarová konfigurace | Procesor | Memory (Paměť) |
|---|---|---|
| Řada Standard (Gen5) | Zřízené výpočetní prostředky - Intel® E5-2673 v4 (Broadwell) 2,3 GHz, Intel® SP-8160 (Skylake)*, Intel® 8272CL (Cascade Lake) 2,5 GHz*, Intel® Xeon® Platinum 8370C (Ice Lake)*, AMD EPYC 7763v (Milán) procesory – Zřízení až 128 virtuálních jader (hyper-threaded) Bezserverové výpočetní prostředí - Intel® E5-2673 v4 (Broadwell) 2,3 GHz, Intel® SP-8160 (Skylake)*, Intel® 8272CL (Cascade Lake) 2,5 GHz*, Intel® Xeon® Platinum 8370C (Ice Lake)*, AMD EPYC 7763v (Milán) procesory – Automatické škálování až 80 virtuálních jader (hyper-threaded) – Poměr paměti na virtuální jádro se dynamicky přizpůsobuje využití paměti a procesoru na základě poptávky na zatížení a může být až 24 GB na virtuální jádro. Například v daném okamžiku může úloha používat a účtovat 240 GB paměti a pouze 10 virtuálních jader. |
Zřízené výpočetní prostředky – 5,1 GB na virtuální jádro – Zřízení až 625 GB Bezserverové výpočetní prostředí – Automatické škálování až 24 GB na virtuální jádro – Automatické škálování až 240 GB max. |
| Řada Fsv2 | – Procesory Intel® 8168 (Skylake) - Má trvalou všechjádrový turbodmychadlo rychlost 3,4 GHz a maximální rychlost turbodmychadla s jedním jádrem 3,7 GHz. – Zřízení až 72 virtuálních jader (hyper-threaded) |
– 1,9 GB na virtuální jádro – Zřízení až 136 GB |
| Řada DC | – Procesory Intel® Xeon® E-2288G - Obsahuje rozšíření Intel Software Guard (Intel SGX) – Zřízení až 8 virtuálních jader (fyzických) |
4,5 GB na virtuální jádro |
* V zobrazení dynamické správy sys.dm_user_db_resource_governance se generace hardwaru pro databáze používající procesory Intel® SP-8160 (Skylake) zobrazuje jako Gen6, generace hardwaru pro databáze používající Intel® 8272CL (Cascade Lake) se zobrazuje jako Gen7 a generace hardwaru pro databáze používající Intel® Xeon® Platinum 8370C (Ice Lake) nebo AMD® EPYC® 7763v (Milán) se zobrazí jako Gen8. Pro danou velikost výpočetních prostředků a konfiguraci hardwaru jsou limity prostředků stejné bez ohledu na typ procesoru (Intel Broadwell, Skylake, Ice Lake, Cascade Lake nebo AMD Milan).
Další informace najdete v tématu Omezení prostředků pro izolované databáze a elastické fondy.
Informace o výpočetních prostředcích a specifikaci databáze Hyperscale najdete v tématu Výpočetní prostředky Hyperscale.
Řada Standard (Gen5)
- Hardware řady Standard (Gen5) poskytuje vyvážené výpočetní a paměťové prostředky a je vhodný pro většinu databázových úloh.
Hardware řady Standard (Gen5) je k dispozici ve všech veřejných oblastech po celém světě.
Hyperscale premium-series
- Možnosti hardwaru řady Premium používají nejnovější technologii procesoru a paměti od Intelu a AMD. Řada Premium poskytuje zvýšení výkonu výpočetního výkonu vzhledem k hardwaru řady Standard.
- Možnost řady Premium nabízí rychlejší výkon procesoru oproti řadě Standard a vyšší počet maximálních virtuálních jader.
- Možnost optimalizovaná pro paměť řady Premium nabízí dvojité množství paměti vzhledem k řadě Standard.
- Elastické fondy Hyperscale jsou k dispozici pro elastické fondy řady Standard, Premium a Premium-series.
Další informace najdete v blogovém příspěvku řady Hyperscale Premium.
Dostupné oblasti najdete v tématu Dostupnost hyperškálování řady Premium.
Řada Fsv2
- Fsv2-series je hardwarová konfigurace optimalizovaná pro výpočty, která zajišťuje nízkou latenci procesoru a vysokou rychlost hodin pro ty nejnáročnější úlohy procesoru. Podobně jako konfigurace hardwaru řady Hyperscale premium-series využívá fsv2-series nejnovější technologii procesoru a paměti od Intelu a AMD, což zákazníkům umožňuje využívat nejnovější hardware při používání databází a elastických fondů na úrovni služby Pro obecné účely.
- V závislosti na úloze může řada Fsv2 poskytovat vyšší výkon procesoru na virtuální jádro než jiné typy hardwaru. Například velikost výpočetních prostředků Fsv2 s 72 virtuálními jádry může poskytovat vyšší výkon procesoru než 80 virtuálních jader na řadě Standard (Gen5) s nižšími náklady.
- Fsv2 poskytuje méně paměti a
tempdbpočtu virtuálních jader než jiný hardware, takže úlohy citlivé na tyto limity můžou u řady Standard (Gen5) fungovat lépe.
Řada Fsv2 se podporuje pouze na úrovni Pro obecné účely. Oblasti, ve kterých je řada Fsv2 dostupná, najdete v tématu Dostupnost řady Fsv2.
Řada DC
- Hardware řady DC používá procesory Intel s technologií Intel Guard Extensions (Intel SGX).
- Řada DC-series se vyžaduje pro funkci Always Encrypted se zabezpečenými enklávy , které vyžadují silnější ochranu zabezpečení hardwarových enkláv v porovnání s enklávy založenými na virtualizaci.
- Řada DC-series je určená pro úlohy, které zpracovávají citlivá data a vyžadují důvěrné možnosti zpracování dotazů, které poskytuje funkce Always Encrypted se zabezpečenými enklávy.
- Hardware řady DC poskytuje vyvážené výpočetní a paměťové prostředky.
Řada DC-series je podporovaná jenom pro zřízené výpočetní prostředky (bezserverová podpora není podporovaná) a nepodporuje redundanci zón. Oblasti, ve kterých je řada DC-series dostupná, najdete v tématu Dostupnost řady DC.
Typy nabídek Azure podporované řadou DC
Pokud chcete vytvářet databáze nebo elastické fondy na hardwaru řady DC, musí být předplatné placeným typem nabídky, včetně průběžných plateb nebo smlouva Enterprise (EA). Úplný seznam typů nabídek Azure podporovaných řadou DC-series najdete v aktuálních nabídkách bez limitů útraty.
Výběr konfigurace hardwaru
Při vytváření můžete vybrat konfiguraci hardwaru pro databázi nebo elastický fond ve službě SQL Database. Můžete také změnit konfiguraci hardwaru existující databáze nebo elastického fondu.
Výběr konfigurace hardwaru při vytváření služby SQL Database nebo fondu
Podrobné informace najdete v tématu Vytvoření databáze SQL.
Na kartě Základy vyberte odkaz Konfigurovat databázi v části Výpočty a úložiště a pak vyberte odkaz Změnit konfiguraci:

Vyberte požadovanou konfiguraci hardwaru:

Změna konfigurace hardwaru existující služby SQL Database nebo fondu
U databáze na stránce Přehled vyberte odkaz Cenová úroveň :

U fondu na stránce Přehled vyberte Konfigurovat.
Podle kroků změňte konfiguraci a vyberte hardwarovou konfiguraci, jak je popsáno v předchozích krocích.
Dostupnost hardwaru
Informace o hardwaru předchozí generace naleznete v tématu Dostupnost hardwaru předchozí generace.
Řada Standard (Gen5)
Hardware řady Standard (Gen5) je k dispozici ve všech veřejných oblastech po celém světě.
Hyperscale premium-series
Pro izolované databáze a elastické fondy v následujících oblastech je k dispozici hardware optimalizovaný pro úroveň služby Hyperscale premium-series a premium-series:
- Austrálie – východ **
- Austrálie – jihovýchod
- Brazílie – jih **,*
- Kanada – střed **
- Kanada – východ
- Východní Asie
- Evropa – sever **
- Evropa – západ **
- Francie – střed
- Německo – středozápad
- Střední Indie
- Jižní Indie
- Japonsko – východ **
- Japonsko – západ
- Jihovýchodní Asie**
- Švýcarsko – sever
- Švédsko – střed **,*
- Velká Británie – jih **
- Velká Británie – západ *
- USA – střed **
- USA – východ **
- USA – východ 2 **
- USA (střed) – sever
- USA (střed) – jih
- USA – středozápad
- USA – západ 1
- USA – západ 2 **
- USA – západ 3 **
* Hardware optimalizovaný pro paměť řady Premium není v současné době k dispozici.
** Zahrnuje podporu redundance zón.
Řada Fsv2
Řada Fsv2 je dostupná v následujících oblastech:
- Austrálie – střed
- Austrálie – střed 2
- Austrálie – východ
- Austrálie – jihovýchod
- Brazílie – jih
- Střední Kanada
- Východní Asie
- Evropa – sever
- Evropa – západ
- Francie – střed
- Střední Indie
- Jižní Korea – střed
- Korea Jih
- Jižní Afrika – sever
- Southeast Asia
- Spojené království – jih
- Spojené království – západ
- Východ USA
- USA – západ 2
Řada DC
Řada DC je dostupná v následujících oblastech:
- Střední Kanada
- Evropa – západ
- Evropa – sever
- Southeast Asia
- Spojené království – jih
- USA – západ
- Východ USA
Pokud potřebujete dc-series v aktuálně nepodporované oblasti, odešlete žádost o podporu. Na stránce Základy zadejte následující:
- V případě typu Problém vyberte Možnost Technical.< a1/> (Technický).
- Zadejte požadované předplatné hardwaru. Vyberte Další.
- Jako typ služby vyberte SQL Database.
- Jako zdroj vyberte Obecný dotaz.
- V souhrnu zadejte požadovanou dostupnost hardwaru a oblast.
- Pro typ problému vyberte Zabezpečení, Privátní a Dodržování předpisů.
- V podtypu Problém vyberte Možnost Always Encrypted.

Hardware předchozí generace
Gen4
Hardware Gen4 je vyřazený a není k dispozici pro zřizování, škálování nebo snížení kapacity. Migrujte databázi na podporovanou generaci hardwaru pro širší škálu škálovatelnosti virtuálních jader a úložiště, akcelerované síťové služby, nejlepší výkon vstupně-výstupních operací a minimální latenci. Projděte si možnosti hardwaru pro izolované databáze a možnosti hardwaru pro elastické fondy. Další informace najdete v tématu Podpora pro hardware Gen 4 ve službě Azure SQL Database.