Automatizace replikace změn schématu v Synchronizace dat SQL Azure
Platí pro: ![]() Azure SQL Database
Azure SQL Database
Důležité
Synchronizace dat SQL budou vyřazeny 30. září 2027. Zvažte migraci na alternativní řešení replikace nebo synchronizace dat.
Synchronizace dat SQL umožňuje uživatelům synchronizovat data mezi databázemi ve službě Azure SQL Database a instancemi SQL Serveru jedním směrem nebo v obou směrech. Jedním z aktuálních omezení Synchronizace dat SQL je nedostatek podpory pro replikaci změn schématu. Pokaždé, když změníte schéma tabulky, musíte změny použít ručně ve všech koncových bodech, včetně centra a všech členů, a pak aktualizovat schéma synchronizace.
Tento článek představuje řešení pro automatickou replikaci změn schématu do všech koncových bodů Synchronizace dat SQL.
- Toto řešení používá trigger DDL ke sledování změn schématu.
- Trigger vloží příkazy změn schématu do tabulky sledování.
- Tato sledovací tabulka se synchronizuje se všemi koncovými body pomocí služby Synchronizace dat.
- Triggery DML po vložení slouží k použití změn schématu na ostatních koncových bodech.
Tento článek používá ALTER TABLE jako příklad změny schématu, ale toto řešení funguje také pro jiné typy změn schématu.
Než začnete implementovat automatizovanou replikaci změn schématu ve vašem synchronizačním prostředí, přečtěte si tento článek pečlivě, zejména části týkající se řešení potíží a dalších aspektů. Některé databázové operace můžou narušit řešení popsané v tomto článku. K řešení těchto problémů může být potřeba další znalosti domény SQL Serveru a jazyka Transact-SQL.
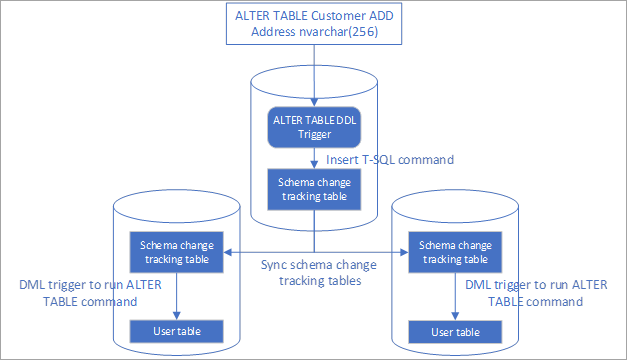
Nastavení automatizované replikace změn schématu
Vytvoření tabulky pro sledování změn schématu
Vytvořte tabulku pro sledování změn schématu ve všech databázích ve skupině synchronizace:
CREATE TABLE SchemaChanges (
ID bigint IDENTITY(1,1) PRIMARY KEY,
SqlStmt nvarchar(max),
[Description] nvarchar(max)
)
Tato tabulka obsahuje sloupec identity ke sledování pořadí změn schématu. V případě potřeby můžete přidat další pole pro protokolování dalších informací.
Vytvoření tabulky pro sledování historie změn schématu
Na všech koncových bodech vytvořte tabulku pro sledování ID naposledy použitého příkazu změny schématu.
CREATE TABLE SchemaChangeHistory (
LastAppliedId bigint PRIMARY KEY
)
GO
INSERT INTO SchemaChangeHistory VALUES (0)
Vytvoření triggeru ALTER TABLE DDL v databázi, ve které se provádějí změny schématu
Vytvořte trigger DDL pro operace ALTER TABLE. Tento trigger je potřeba vytvořit pouze v databázi, kde se provádějí změny schématu. Aby nedocházelo ke konfliktům, povolte změny schématu pouze v jedné databázi ve skupině synchronizace.
CREATE TRIGGER AlterTableDDLTrigger
ON DATABASE
FOR ALTER_TABLE
AS
-- You can add your own logic to filter ALTER TABLE commands instead of replicating all of them.
IF NOT (EVENTDATA().value('(/EVENT_INSTANCE/SchemaName)[1]', 'nvarchar(512)') like 'DataSync')
INSERT INTO SchemaChanges (SqlStmt, Description)
VALUES (EVENTDATA().value('(/EVENT_INSTANCE/TSQLCommand/CommandText)[1]', 'nvarchar(max)'), 'From DDL trigger')
Trigger vloží záznam do tabulky sledování změn schématu pro každý příkaz ALTER TABLE. Tento příklad přidá filtr, aby se zabránilo replikaci změn schématu provedených ve schématu DataSync, protože je s největší pravděpodobností provádí služba Synchronizace dat. Pokud chcete replikovat jenom určité typy změn schématu, přidejte další filtry.
Můžete také přidat další triggery pro replikaci dalších typů změn schématu. Můžete například vytvořit CREATE_PROCEDURE, ALTER_PROCEDURE a DROP_PROCEDURE triggery pro replikaci změn do uložených procedur.
Vytvoření triggeru na jiných koncových bodech pro použití změn schématu během vkládání
Tato aktivační událost spustí příkaz změny schématu při synchronizaci s jinými koncovými body. Tento trigger je potřeba vytvořit na všech koncových bodech, s výjimkou toho, kde se provádějí změny schématu (to znamená v databázi, kde se trigger AlterTableDDLTrigger DDL vytvoří v předchozím kroku).
CREATE TRIGGER SchemaChangesTrigger
ON SchemaChanges
AFTER INSERT
AS
DECLARE @lastAppliedId bigint
DECLARE @id bigint
DECLARE @sqlStmt nvarchar(max)
SELECT TOP 1 @lastAppliedId=LastAppliedId FROM SchemaChangeHistory
SELECT TOP 1 @id = id, @SqlStmt = SqlStmt FROM SchemaChanges WHERE id > @lastAppliedId ORDER BY id
IF (@id = @lastAppliedId + 1)
BEGIN
EXEC sp_executesql @SqlStmt
UPDATE SchemaChangeHistory SET LastAppliedId = @id
WHILE (1 = 1)
BEGIN
SET @id = @id + 1
IF exists (SELECT id FROM SchemaChanges WHERE ID = @id)
BEGIN
SELECT @sqlStmt = SqlStmt FROM SchemaChanges WHERE ID = @id
EXEC sp_executesql @SqlStmt
UPDATE SchemaChangeHistory SET LastAppliedId = @id
END
ELSE
BREAK;
END
END
Tato aktivační událost se spustí po vložení a zkontroluje, jestli má aktuální příkaz běžet dál. Logika kódu zajišťuje, že se nepřeskočil žádný příkaz změny schématu a všechny změny se použijí i v případě, že je vložení mimo pořadí.
Synchronizace tabulky sledování změn schématu se všemi koncovými body
Tabulku sledování změn schématu můžete synchronizovat se všemi koncovými body pomocí existující skupiny synchronizace nebo nové skupiny synchronizace. Ujistěte se, že změny v tabulce sledování je možné synchronizovat se všemi koncovými body, zejména pokud používáte jednosměrnou synchronizaci.
Tabulku historie změn schématu nesynchronizujete, protože tato tabulka udržuje jiný stav v různých koncových bodech.
Použití změn schématu ve skupině synchronizace
Replikují se pouze změny schématu provedené v databázi, ve které je vytvořena aktivační událost DDL. Změny schématu provedené v jiných databázích se nereplikují.
Po replikaci změn schématu do všech koncových bodů je také potřeba provést další kroky k aktualizaci schématu synchronizace, aby se spustilo nebo přestalo synchronizovat nové sloupce.
Přidání nových sloupců
Proveďte změnu schématu.
Vyhněte se změnám dat, ve kterých jsou nové sloupce zahrnuté, dokud nedokončíte krok, který trigger vytvoří.
Počkejte, až se změny schématu použijí na všechny koncové body.
Aktualizujte schéma databáze a přidejte nový sloupec do schématu synchronizace.
Data v novém sloupci se synchronizují během další operace synchronizace.
Odebrání sloupců
Odeberte sloupce ze schématu synchronizace. Synchronizace dat přestane synchronizovat data v těchto sloupcích.
Proveďte změnu schématu.
Aktualizujte schéma databáze.
Aktualizace datových typů
Proveďte změnu schématu.
Počkejte, až se změny schématu použijí na všechny koncové body.
Aktualizujte schéma databáze.
Pokud nové a staré datové typy nejsou plně kompatibilní – například pokud změníte na
intbigint– synchronizace může selhat před dokončením kroků, které vytvoří triggery. Synchronizace proběhne úspěšně po opakování.
Přejmenování sloupců nebo tabulek
Přejmenování sloupců nebo tabulek Synchronizace dat přestane fungovat. Vytvořte novou tabulku nebo sloupec, znovu vyplňte data a potom místo přejmenování odstraňte starou tabulku nebo sloupec.
Jiné typy změn schématu
U jiných typů změn schématu – například vytvoření uložených procedur nebo vyřazení indexu – aktualizace schématu synchronizace není nutná.
Řešení potíží s automatizovanou replikací změn schématu
Logika replikace popsaná v tomto článku přestane v některých situacích fungovat, například pokud jste provedli změnu schématu v místní databázi, která není ve službě Azure SQL Database podporovaná. V takovém případě synchronizace tabulky sledování změn schématu selže. Tento problém potřebujete vyřešit ručně:
Zakažte trigger DDL a vyhněte se dalším změnám schématu, dokud se problém nevyřeší.
V databázi koncových bodů, kde k problému dochází, zakažte trigger AFTER INSERT na koncovém bodu, kde se změna schématu nedá provést. Tato akce umožňuje synchronizaci příkazu změny schématu.
Aktivace synchronizace pro synchronizaci tabulky sledování změn schématu
V databázi koncových bodů, kde k problému dochází, zadejte dotaz na tabulku historie změn schématu a získejte ID posledního použitého příkazu změny schématu.
Dotazem na tabulku sledování změn schématu zobrazíte seznam všech příkazů s ID větší než hodnota ID, kterou jste získali v předchozím kroku.
a. Ignorujte tyto příkazy, které nelze spustit v databázi koncového bodu. Potřebujete řešit nekonzistence schématu. Pokud má nekonzistence vliv na vaši aplikaci, vraťte původní změny schématu.
b. Ručně použijte tyto příkazy, které by se měly použít.
Aktualizujte tabulku historie změn schématu a nastavte ID naposledy použité na správnou hodnotu.
Pečlivě zkontrolujte, jestli je schéma aktuální.
V druhém kroku znovu povolte trigger AFTER INSERT.
V prvním kroku znovu povolte trigger DDL zakázaný.
Pokud chcete vyčistit záznamy v tabulce sledování změn schématu, použijte místo funkce TRUNCATE delete. Sloupec identity v tabulce sledování změn schématu nikdy nepředávejte pomocí DBCC CHECKIDENT. Můžete vytvořit nové tabulky sledování změn schématu a aktualizovat název tabulky v triggeru DDL, pokud je vyžadováno obnovení.
Ostatní úvahy
Uživatelé databáze, kteří konfigurují centrální a členské databáze, musí mít dostatečná oprávnění ke spuštění příkazů pro změnu schématu.
Do triggeru DDL můžete přidat další filtry, které replikují pouze změnu schématu ve vybraných tabulkách nebo operacích.
Změny schématu můžete provádět pouze v databázi, ve které je vytvořen trigger DDL.
Pokud provádíte změnu v databázi SQL Serveru, ujistěte se, že je změna schématu podporovaná ve službě Azure SQL Database.
Pokud se změny schématu provádějí v jiných databázích než v databázi, ve které je vytvořen trigger DDL, změny se nereplikují. Pokud se chcete tomuto problému vyhnout, můžete vytvořit triggery DDL, které zablokují změny v jiných koncových bodech.
Pokud potřebujete změnit schéma tabulky sledování změn schématu, před provedením změny zakažte trigger DDL a pak změnu použijte ručně u všech koncových bodů. Aktualizace schématu v triggeru AFTER INSERT ve stejné tabulce nefunguje.
Sloupec identity nepředávejte pomocí DBCC CHECKIDENT.
Nepoužívejte funkci TRUNCATE k vyčištění dat v tabulce sledování změn schématu.
Související obsah
- Co je Synchronizace dat SQL pro Azure?
- Kurz: Nastavení Synchronizace dat SQL mezi databázemi v Azure SQL Database a SQL Server
- Použití PowerShellu k synchronizaci dat mezi několika databázemi ve službě Azure SQL Database
- Použití PowerShellu k synchronizaci dat mezi SQL Database a SQL Serverem
- Synchronizace dat Agent pro Synchronizace dat SQL
- Osvědčené postupy pro Synchronizaci dat SQL Azure
- Monitorování a ladění výkonu ve službě Azure SQL Database a azure SQL Managed Instance
- Řešení potíží s funkcí Synchronizace dat SQL
- Použití PowerShellu k aktualizaci schématu synchronizace v existující skupině synchronizace