Přehled kontinuity podnikových procesů s Azure SQL Managed Instance
Platí pro: ![]() Azure SQL Managed Instance
Azure SQL Managed Instance
Tento článek obsahuje přehled možností provozní kontinuity a zotavení po havárii služby Azure SQL Managed Instance, které popisují možnosti a doporučení pro zotavení z rušivých událostí, které můžou vést ke ztrátě dat nebo způsobit nedostupnost vaší instance a aplikace. Zjistěte, co dělat, když chyba uživatele nebo aplikace ovlivňuje integritu dat, zónu dostupnosti Azure nebo oblast dojde k výpadku nebo že vaše aplikace vyžaduje údržbu.
Přehled
Kontinuita podnikových procesů ve službě Azure SQL Managed Instance odkazuje na mechanismy, zásady a postupy, které vaší firmě umožňují pokračovat v provozu v případě přerušení tím, že poskytuje dostupnost, vysokou dostupnost a zotavení po havárii.
Ve většině případů služba SQL Managed Instance zpracovává rušivé události, ke kterým může dojít v cloudovém prostředí, a udržuje vaše aplikace a obchodní procesy spuštěné. Existuje však několik rušivých událostí, kdy zmírnění může nějakou dobu trvat, například:
- Uživatel omylem odstraní nebo aktualizuje řádek v tabulce.
- Útočník se zlými úmysly úspěšně odstraní data nebo zahodí databázi.
- Katastrofická přírodní katastrofa přebírá datacentrum nebo zónu dostupnosti nebo oblast.
- Vzácné výpadky datacentra, zóny dostupnosti nebo oblasti způsobené změnou konfigurace, chybou softwaru nebo selháním hardwarových komponent.
Dostupnost
Spravovaná instance Azure SQL nabízí základní příslib odolnosti a spolehlivosti, který ho chrání před selháním softwaru nebo hardwaru. Zálohy databáze jsou automatizované, aby chránily vaše data před poškozením nebo náhodným odstraněním. Jako platforma jako služba (PaaS) poskytuje služba Azure SQL Managed Instance dostupnost jako funkci mimo dostupnost se smlouvou SLA s nejlepší dostupností 99,99 %.
Vysoká dostupnost
Pokud chcete dosáhnout vysoké dostupnosti v cloudovém prostředí Azure, povolte redundanci zón, aby instance používala zóny dostupnosti k zajištění odolnosti proti zónovým selháním. Řada oblastí Azure poskytuje zóny dostupnosti, které jsou oddělené skupiny datových center v rámci oblasti, které mají nezávislou infrastrukturu napájení, chlazení a sítě. Zóny dostupnosti jsou navržené tak, aby poskytovaly regionální služby, kapacitu a vysokou dostupnost ve zbývajících zónách, pokud dojde k výpadku jedné zóny. Povolením redundance zón je instance odolná vůči selhání zónového hardwaru a softwaru a obnovení je pro aplikace transparentní. Pokud je povolená vysoká dostupnost, služba Azure SQL Managed Instance dokáže poskytovat smlouvu SLA s vyšší dostupností 99,99 %.
Zotavení po havárii
Pokud chcete dosáhnout vyšší dostupnosti a redundance napříč oblastmi, můžete povolit možnosti zotavení po havárii, které rychle obnoví instanci z závažného regionálního selhání. Možnosti zotavení po havárii se službou Azure SQL Managed Instance jsou:
- Skupiny převzetí služeb při selhání umožňují průběžnou synchronizaci mezi primární a sekundární instancí. Skupiny převzetí služeb při selhání poskytují koncové body naslouchacího procesu jen pro čtení a jen pro čtení, které zůstávají beze změny, takže aktualizace aplikací připojovací řetězec po převzetí služeb při selhání není nutná.
- Geografické obnovení umožňuje zotavení z regionálního výpadku obnovením z geograficky replikovaných záloh, když nemůžete získat přístup k databázi v primární oblasti vytvořením nové databáze v jakékoli existující instanci v jakékoli oblasti Azure.
Funkce, které poskytují kontinuitu podnikových procesů
Například existují čtyři hlavní potenciální scénáře přerušení. Následující tabulka uvádí funkce provozní kontinuity služby SQL Managed Instance, které můžete použít ke zmírnění potenciálního scénáře přerušení podnikání:
| Scénář přerušení podnikání | Funkce provozní kontinuity |
|---|---|
| Selhání místního hardwaru nebo softwaru, které ovlivňují databázový uzel. | Kvůli zmírnění selhání místního hardwaru a softwaru zahrnuje spravovaná instance SQL architekturu dostupnosti, která zaručuje automatické obnovení z těchto selhání s až 99,99% dostupností SLA. |
| Poškození nebo odstranění dat obvykle způsobuje chyba aplikace nebo lidská chyba. Taková selhání jsou specifická pro aplikaci a služba je obvykle nedokáže rozpoznat. | Kvůli ochraně vaší firmy před ztrátou dat služba SQL Managed Instance automaticky vytváří týdenní úplné zálohy databáze, rozdílové zálohy databází každých 12 nebo 24 hodin a zálohy transakčních protokolů každých 5 až 10 minut. Ve výchozím nastavení se zálohy ukládají v geograficky redundantním úložišti po dobu sedmi dnů a podporují konfigurovatelnou dobu uchovávání záloh pro obnovení k určitému bodu v čase až 35 dnů. Odstraněnou databázi můžete obnovit do bodu, kdy byla odstraněna, pokud instance nebyla odstraněna, nebo pokud jste nakonfigurovali dlouhodobé uchovávání. |
| Vzácné výpadky datového centra nebo zóny dostupnosti, které můžou být způsobeny událostí přírodní katastrofy, změnou konfigurace, chybou softwaru nebo selháním hardwarové komponenty. | Pokud chcete zmírnit výpadek na úrovni datového centra nebo zóny dostupnosti, povolte redundanci zón pro službu SQL Managed Instance, aby používala azure Zóny dostupnosti a poskytovala redundanci napříč několika fyzickými zónami v rámci oblasti Azure. Povolení redundance zón zajišťuje odolnost spravované instance vůči zónovým selháním až s 99,99% smlouvou SLA s vysokou dostupností. |
| Výjimečný výpadek oblasti ovlivňuje všechny zóny dostupnosti a datacentra, která ji tvoří, pravděpodobně způsobená katastrofickou přírodní katastrofou. | Pokud chcete zmírnit výpadky v celé oblasti, povolte zotavení po havárii pomocí jedné z možností: – Průběžná synchronizace dat se skupinami převzetí služeb při selhání do replik v sekundární oblasti používané pro převzetí služeb při selhání. – Nastavení redundance úložiště zálohování na geograficky redundantní úložiště záloh pro použití geografického obnovení. |
RTO a RPO
Při vývoji plánu provozní kontinuity porozumíte maximální přijatelné době před tím, než se aplikace plně obnoví po rušivé události. Čas potřebný k úplnému obnovení aplikace se označuje jako plánovaná doba obnovení (RTO). Také porozumíte maximálnímu období nedávných aktualizací dat (časový interval), které může aplikace tolerovat ztrátu při obnovení z neplánované rušivé události. Potenciální ztráta dat se označuje jako cíl bodu obnovení (RPO).
Následující tabulka porovnává cíle bodu obnovení (RPO) a RTO jednotlivých možností provozní kontinuity:
| Možnost provozní kontinuity | RTO (výpadek) | RPO (ztráta dat) |
|---|---|---|
| Vysoká dostupnost (použití redundance zón) |
Obvykle méně než 30 sekund | 0 |
| Zotavení po havárii (použití skupin převzetí služeb při selhání se zásadami převzetí služeb při selhání spravované zákazníkem) |
Obvykle méně než 60 sekund | Je rovno nebo větší než 0 (závisí na změnách dat před rušivým událostí, která nebyla replikována) |
| Zotavení po havárii (použití geografického obnovení) |
12 hodin | 1 hodina |
Kontrolní seznamy provozní kontinuity
Referenční doporučení k maximalizaci dostupnosti a dosažení vyšší kontinuity podnikových procesů najdete v tématu:
- Kontrolní seznam k dostupnosti
- Kontrolní seznam k vysoké dostupnosti
- Kontrolní seznam pro zotavení po havárii
Obnovení databáze ve stejné oblasti Azure
Automatické zálohy databáze můžete použít k obnovení databáze k určitému bodu v čase v minulosti. Tímto způsobem se můžete zotavit z poškození dat způsobených lidskými chybami. Obnovení k určitému bodu v čase umožňuje vytvořit novou databázi do stejné instance nebo jiné instance, která představuje stav dat před poškozenou událostí. Operace obnovení je velikost datové operace, která také závisí na aktuální úloze cílové instance. Obnovení velmi velké nebo velmi aktivní databáze může trvat déle. Další informace o době obnovení najdete v tématu Doba obnovení databáze.
Pokud maximální podporovaná doba uchovávání záloh pro obnovení k určitému bodu v čase (PITR) pro vaši aplikaci nestačí, můžete ji prodloužit konfigurací zásad dlouhodobého uchovávání (LTR) pro databáze. Další informace najdete v tématu Dlouhodobé uchovávání záloh.
Obnovení databáze do existující instance
I když je to vzácné, může mít datacentrum Azure výpadek. Při výpadku dojde k narušení provozu, které může trvat jen několik minut nebo až několik hodin.
- Jednou z možností je počkat, až se instance vrátí do online režimu, když dojde k výpadku datacentra. To funguje pro aplikace, které si mohou dovolit mít svou databázi offline. Například vývojový projekt nebo bezplatná zkušební verze, na které nemusíte neustále pracovat. Pokud dojde k výpadku datového centra, nevíte, jak dlouho může výpadek trvat, takže tato možnost funguje jenom v případě, že nějakou dobu databázi nepotřebujete.
- Pokud používáte geograficky redundantní úložiště (GRS) nebo geograficky zónově redundantní úložiště (GZRS), je další možností obnovení databáze do jakékoli spravované instance SQL v jakékoli oblasti Azure pomocí geograficky redundantních záloh databáze (geografické obnovení). Geografické obnovení používá jako zdroj geograficky redundantní zálohu a dá se použít k obnovení databáze k poslednímu dostupnému bodu v čase, i když je databáze nebo datacentrum nedostupné kvůli výpadku. Dostupné zálohování najdete ve spárované oblasti.
- Nakonec se můžete rychle zotavit z výpadku, pokud jste nakonfigurovali geografickou sekundární oblast pomocí skupiny převzetí služeb při selhání pro vaši instanci pomocí zákazníka (doporučeno) nebo převzetí služeb při selhání spravovaného Microsoftem. I když samotné převzetí služeb při selhání trvá jen několik sekund, aktivace geografického převzetí služeb při selhání spravované microsoftem trvá aspoň 1 hodinu, pokud je nakonfigurovaná. To je nezbytné k zajištění, aby převzetí služeb při selhání bylo odůvodněno škálováním výpadku. Převzetí služeb při selhání může také vést ke ztrátě nedávno změněných dat kvůli povaze asynchronní replikace mezi spárovanými oblastmi.
Při vývoji plánu provozní kontinuity musíte pochopit maximální přijatelnou dobu úplného zotavení aplikace po ničivé události. Doba potřebná k úplnému obnovení aplikace se označuje jako cíl doby obnovení (RTO). Musíte také pochopit maximální období nedávných aktualizací dat (časový interval), které může aplikace tolerovat ztrátu při obnovení z neplánované rušivé události. Potenciální ztráta dat se označuje jako cíl bodu obnovení (RPO).
Různé metody obnovení nabízejí různé úrovně RPO a RTO. Můžete zvolit konkrétní metodu obnovení nebo použít kombinaci metod k dosažení úplného obnovení aplikace.
Skupiny převzetí služeb při selhání použijte, pokud vaše aplikace splňuje některá z těchto kritérií:
- Je zvlášť důležitá.
- Má smlouvu o úrovni služeb (SLA), která neumožňuje 12 hodin nebo více výpadků.
- Výpadek může vést k finanční odpovědnosti.
- Má vysokou míru změny dat a 1 hodina ztráty dat není přijatelná.
- Další náklady na aktivní geografickou replikaci jsou nižší než potenciální finanční závazky a související ztráta podnikání.
V závislosti na požadavcích vaší aplikace se můžete rozhodnout použít kombinaci záloh databáze a skupin převzetí služeb při selhání.
Následující části obsahují přehled kroků pro obnovení pomocí záloh databáze nebo skupin převzetí služeb při selhání.
Příprava na výpadek
Bez ohledu na funkce provozní kontinuity, které používáte, musíte:
- Identifikujte a připravte cílovou instanci, včetně pravidel brány firewall protokolu IP sítě, přihlášení a
masteroprávnění na úrovni databáze. - Určení přesměrování klientů a klientských aplikací na novou instanci
- Zdokumentovat další závislosti, například nastavení auditování a výstrahy
Pokud se správně nepřipravíte, přenesení aplikací do režimu online po převzetí služeb při selhání nebo obnovení databáze trvá delší dobu a pravděpodobně také vyžaduje řešení potíží v době stresu – špatná kombinace.
Převzetí služeb při selhání do geograficky replikované sekundární instance
Pokud jako mechanismus obnovení používáte skupiny převzetí služeb při selhání, můžete nakonfigurovat zásady automatického převzetí služeb při selhání. Po zahájení převzetí služeb při selhání se sekundární instance stane novou primární instancí připravenou zaznamenávat nové transakce a reagovat na dotazy – s minimální ztrátou dat pro data, která ještě nebyla replikována.
Poznámka:
Když se datové centrum vrátí zpět do online režimu, původní primární server se automaticky znovu připojí k nové primární instanci, aby se stala sekundární instancí. Pokud potřebujete přemístit primární server zpět do původní oblasti, můžete plánované převzetí služeb při selhání zahájit ručně (navrácení služeb po obnovení).
Provedení geografického obnovení
Pokud používáte automatizované zálohy s geograficky redundantním úložištěm (výchozí možnost úložiště při vytváření instance), můžete databázi obnovit pomocí geografického obnovení. Obnovení se obvykle provádí do 12 hodin – při ztrátě dat do jedné hodiny určeného při posledním vytvoření a replikaci zálohy protokolu. Dokud se obnovení nedokončí, databáze není schopná zaznamenávat žádné transakce ani reagovat na dotazy. Upozorňujeme, že geografické obnovení obnoví pouze databázi k poslednímu dostupnému bodu v čase.
Poznámka:
Pokud se datové centrum vrátí do online režimu před přepnutím aplikace na obnovenou databázi, můžete obnovení zrušit.
Provedení úloh po převzetí služeb při selhání nebo obnovení
Po obnovení s použitím libovolného mechanismu musíte provést následující dodatečné úlohy, abyste pro uživatele zprovoznili své aplikace:
- Přesměrujte klienty a klientské aplikace na novou instanci a obnovenou databázi.
- Ujistěte se, že jsou pro připojení uživatelů zavedená příslušná pravidla brány firewall protokolu IP sítě.
- Ujistěte se, že jsou zavedená příslušná přihlášení a
masteroprávnění na úrovni databáze (nebo použijte uživatele s omezením). - Podle potřeby nakonfigurujte auditování.
- Podle potřeby nakonfigurujte upozornění.
Poznámka:
Pokud používáte skupinu převzetí služeb při selhání a připojujete se k instanci pomocí naslouchacího procesu pro čtení i zápis, přesměrování po převzetí služeb při selhání proběhne automaticky a transparentně do aplikace.
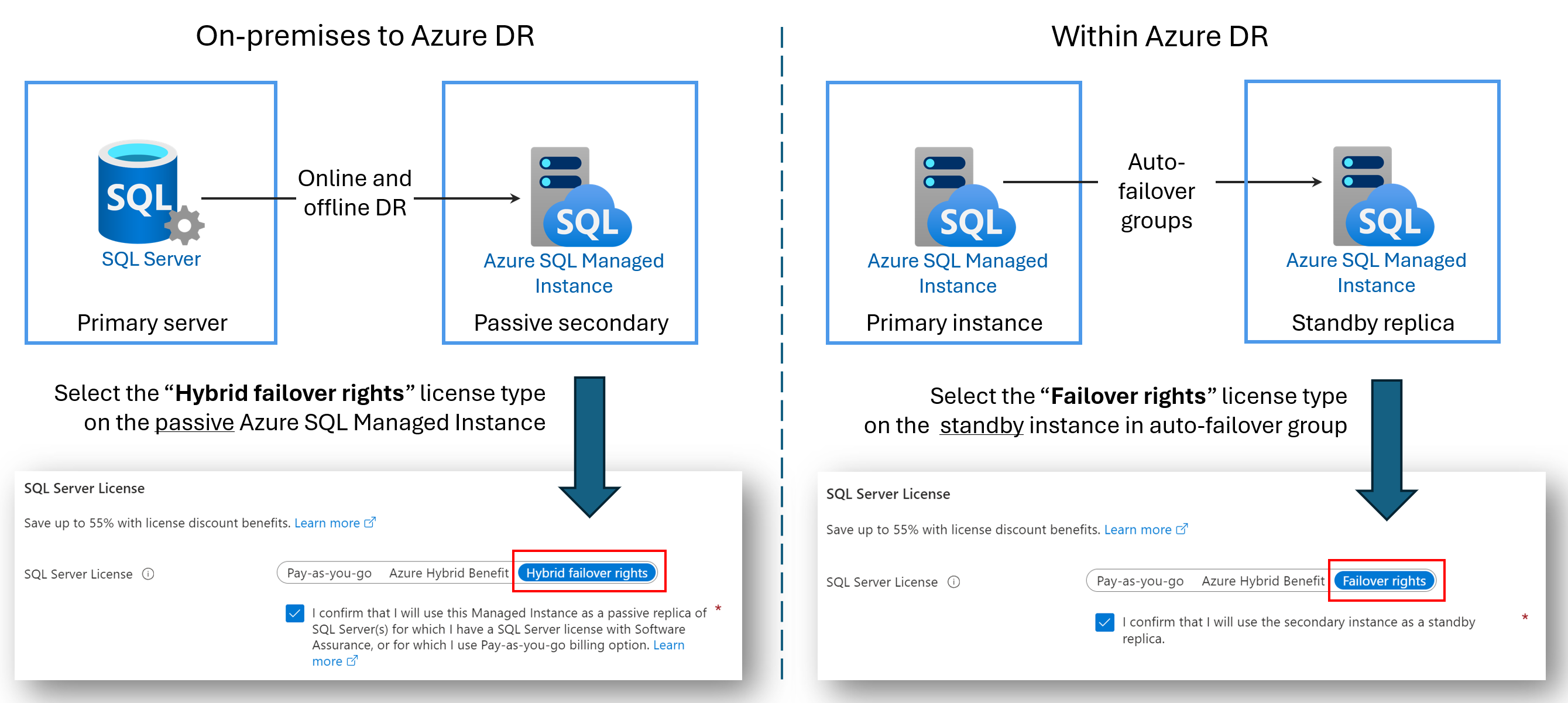
Repliky zotavení po havárii bez licence
Náklady na licencování můžete ušetřit konfigurací sekundární služby Azure SQL Managed Instance pouze pro zotavení po havárii (DR). Tato výhoda je dostupná, pokud používáte skupinu převzetí služeb při selhání mezi dvěma spravovanými instancemi SQL nebo jste nakonfigurovali hybridní propojení mezi SQL Serverem a spravovanou instancí Azure SQL. Pokud sekundární instance nemá žádné úlohy čtení ani zápisu a je pouze pasivní pohotovostní režim zotavení po havárii, nebudou se vám účtovat náklady na licencování virtuálních jader využívané sekundární instancí.
Když určíte sekundární instanci pouze pro zotavení po havárii a v instanci nejsou spuštěné žádné úlohy čtení nebo zápisu, Microsoft vám poskytne počet virtuálních jader, které jsou licencované primární instanci bez dalších poplatků za výhodu práv převzetí služeb při selhání. Stále se vám účtuje výpočetní prostředky a úložiště, které sekundární instance používá. Přesné podmínky zvýhodnění hybridního převzetí služeb při selhání najdete v licenčních podmínkách SQL Serveru online v části Sql Server – Práva převzetí služeb při selhání.
Název výhody závisí na vašem scénáři:
- Práva hybridního převzetí služeb při selhání pro pasivní repliku: Pokud konfigurujete propojení mezi SQL Serverem a službou Azure SQL Managed Instance, můžete využít zvýhodnění práv hybridního převzetí služeb při selhání a ušetřit náklady na licencování virtuálních jader pro pasivní sekundární repliku.
- Práva k převzetí služeb při selhání pro pohotovostní repliku: Při konfiguraci skupiny převzetí služeb při selhání mezi dvěma spravovanými instancemi můžete využít výhodu práv převzetí služeb při selhání a ušetřit náklady na licencování virtuálních jader pro pohotovostní sekundární repliku.
Následující diagram znázorňuje výhodu pro každý scénář:
Další kroky
Další informace o funkcích provozní kontinuity najdete v tématu Automatizované zálohování a skupiny převzetí služeb při selhání. Informace o zotavení po havárii najdete v tématu Obnovení databáze a povolení redundance zón pro službu Azure SQL Managed Instance.