Pokyny k zotavení po havárii – Azure SQL Managed Instance
Platí pro: ![]() Azure SQL Managed Instance
Azure SQL Managed Instance
Azure SQL Managed Instance poskytuje špičkovou záruku vysoké dostupnosti minimálně 99,99 % pro podporu široké škály aplikací, včetně klíčového cíle, které musí být vždy dostupné. Spravovaná instance Azure SQL má také klíčové funkce provozní kontinuity, které můžete provést pro rychlé zotavení po havárii v případě regionálního výpadku. Tento článek obsahuje cenné informace ke kontrole před nasazením aplikace.
I když neustále usilujeme o zajištění vysoké dostupnosti, v některých případech dochází k výpadkům služby Azure SQL Managed Instance, které způsobují nedostupnost vaší databáze a tím ovlivní vaši aplikaci. Když naše monitorování služeb zjistí problémy, které způsobují rozsáhlé chyby připojení, chyby nebo problémy s výkonem, služba automaticky deklaruje výpadek, který vás bude informovat.
Výpadek služby
V případě výpadku služby Azure SQL Managed Instance najdete další podrobnosti týkající se výpadku na následujících místech:
Banner webu Azure Portal
Pokud je vaše předplatné identifikované jako ovlivněné, na webu Azure Portal se zobrazí upozornění na výpadek problému se službou:
Nápověda a podpora a řešení potíží
Když vytvoříte lístek podpory z nápovědy a podpory nebo podpory a řešení potíží, najdete informace o jakýchkoli problémech, které mají vliv na vaše prostředky. Pokud chcete zobrazit další informace a souhrn dopadu, vyberte Zobrazit podrobnosti o výpadku. Na stránce Nová žádost o podporu je také upozornění.
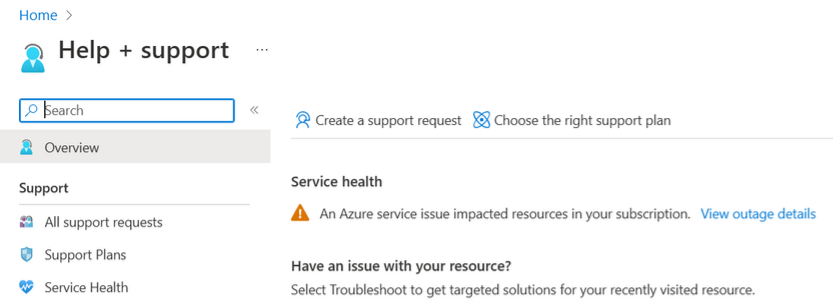
Stav služby
Stránka Service Health na webu Azure Portal obsahuje informace o stavu datového centra Azure globálně. Na panelu hledání na webu Azure Portal vyhledejte stav služby a pak zobrazte problémy se službou v kategorii Aktivní události . Stav jednotlivých prostředků můžete zobrazit také na stránce Stav prostředku libovolného prostředku v nabídce Nápověda . Následuje ukázkový snímek obrazovky se stránkou Service Health s informacemi o aktivním problému se službou v jihovýchodní Asii:

E-mailové oznámení
Pokud jste nastavili upozornění, odešle se e-mailové oznámení, když
azure-noreply@microsoft.comvýpadek služby ovlivní vaše předplatné a prostředek. Text e-mailu obvykle začíná upozorněním protokolu aktivit ... aktivoval problém se službou pro předplatné Azure.... Další informace o upozorněních na stav služby najdete v tématu Příjem upozornění protokolu aktivit na oznámeních služby Azure pomocí webu Azure Portal.


Kdy zahájit zotavení po havárii během výpadku
V případě výpadku služby, který má vliv na prostředky aplikace, zvažte následující postupy:
Týmy Azure pracují usilovně na obnovení dostupnosti služeb co nejrychleji, ale v závislosti na původní příčině může někdy trvat hodiny. Pokud vaše aplikace dokáže tolerovat významné výpadky, stačí počkat na dokončení obnovení. V takovém případě se nevyžaduje žádná akce na vaší straně. Stav jednotlivých prostředků můžete zobrazit na stránce Stav prostředku libovolného prostředku v nabídce Nápověda . Informace o výpadcích najdete na stránce Resource Health a nejnovější informace o výpadku. Po obnovení oblasti se obnoví dostupnost vaší aplikace.
Obnovení do jiné oblasti Azure může vyžadovat změnu aplikačních připojovací řetězec nebo použití přesměrování DNS a může vést ke ztrátě trvalých dat. Zotavení po havárii by se proto mělo provést pouze v případě, že doba trvání výpadku se blíží cíli doby obnovení vaší aplikace (RTO). Když je aplikace nasazená do produkčního prostředí, měli byste provést pravidelné monitorování stavu aplikace a potvrdit, že obnovení je zaručené pouze v případě, že dojde k dlouhodobému selhání připojení z aplikační vrstvy do databáze. V závislosti na odolnosti vaší aplikace vůči výpadkům a možné obchodní odpovědnosti se můžete rozhodnout, jestli chcete počkat, až se služba obnoví nebo zahájí zotavení po havárii sami.
Pokyny k zotavení po výpadku
Pokud se výpadek služby Azure SQL Managed Instance v oblasti po delší dobu nezmírní a ovlivňuje smlouvu o úrovni služeb vaší aplikace (SLA), zvažte následující kroky:
Převzetí služeb při selhání (bez ztráty dat) do geograficky replikované sekundární instance
Pokud jsou povolené skupiny převzetí služeb při selhání, na webu Azure Portal zkontrolujte, jestli je stav prostředku primární a sekundární instance online . Pokud ano, rovina dat pro primární i sekundární instanci je v pořádku.
Spuštění převzetí služeb při selhání skupin převzetí služeb při selhání do sekundární oblasti pomocí:
Poznámka:
Převzetí služeb při selhání vyžaduje úplnou synchronizaci dat před přepnutím rolí a nemá za následek ztrátu dat. V závislosti na typu výpadku služby neexistuje žádná záruka, že převzetí služeb při selhání bez ztráty dat bude úspěšné, ale stojí za to vyzkoušet jako první možnost obnovení.
Vynucené převzetí služeb při selhání (potenciální ztráta dat) do geograficky replikované sekundární instance
Pokud převzetí služeb při selhání neproběhne úspěšně a dojde k chybám nebo pokud primární databáze není online, pečlivě zvažte vynucené převzetí služeb při selhání s potenciální ztrátou dat do sekundární oblasti.
K zahájení vynuceného převzetí služeb při selhání použijte:
- Azure Portal , ale zvolte možnost Vynucené převzetí služeb při selhání.
- PowerShell , ale použijte
--allow-data-loss. - Azure CLI , ale použijte
-AllowDataLoss.
Geografické obnovení
Pokud jste nepovolili skupiny převzetí služeb při selhání, můžete jako poslední možnost použít geografické obnovení k obnovení z výpadku. Geografické obnovení používá jako zdroj geograficky replikované zálohy. Databázi můžete obnovit v libovolné instanci v libovolné oblasti Azure z nejnovějších geograficky replikovaných záloh. Geografické obnovení můžete požádat, i když došlo k výpadku instance nebo celé oblasti nepřístupné.
Další informace o geografických obnoveních prostřednictvím Azure CLI, webu Azure Portal, PowerShellu nebo rozhraní REST API najdete v tématu Geografické obnovení.
Konfigurace databáze po obnovení
Pokud k zotavení z výpadku používáte geografické převzetí služeb při selhání nebo geografické obnovení, musíte se ujistit, že je připojení k nové instanci správně nakonfigurované, aby bylo možné obnovit normální funkci aplikace. Toto je kontrolní seznam úkolů, které vám pomůžou připravit obnovenou produkční databázi.
Důležité
Doporučujeme provést pravidelné postupy strategie zotavení po havárii , abyste ověřili odolnost aplikace a také všechny provozní aspekty postupu obnovení. Ostatní vrstvy infrastruktury aplikací můžou vyžadovat změnu konfigurace. Další informace o krocích odolné architektury najdete v kontrolním seznamu pro vysokou dostupnost a zotavení po havárii.
Aktualizace připojovací řetězec
- Pokud používáte geografické obnovení, musíte se ujistit, že je připojení k nové instanci správně nakonfigurované, aby bylo možné obnovit normální funkci aplikace. Vzhledem k tomu, že obnovená databáze se nachází v jiné instanci, musíte aktualizovat připojovací řetězec aplikace tak, aby odkazovala na tento server. Další informace o změně připojovací řetězec najdete v příslušném vývojovém jazyce pro knihovnu připojení.
- Pokud k zotavení ze výpadku používáte skupiny převzetí služeb při selhání a používáte naslouchací procesy jen pro čtení a čtení ve vaší aplikaci připojovací řetězec, není potřeba žádná další akce, protože připojení se automaticky přesměrují na nový primární server.
Konfigurace pravidel brány firewall
Ujistěte se, že pravidla skupiny zabezpečení sítě a směrovací tabulky nakonfigurovaná pro sekundární instanci odpovídají pravidlům nakonfigurovaným v primární instanci. Další informace najdete v konfiguraci podsítě podporované službou.
Konfigurace přihlášení a uživatelů databáze
Vytvořte přihlášení, která musí být v databázi v master sekundární instanci, a zajistěte, aby tato přihlášení měla příslušná oprávnění v master databázi( pokud existuje).
Nastavení upozornění telemetrie
Ujistěte se, že se vaše stávající nastavení pravidla upozornění aktualizuje tak, aby se mapuje na novou primární instanci. Další informace o pravidlech upozornění databáze najdete v tématu Příjem oznámení o upozorněních a sledování stavu služby.
Povolení auditování
Pokud jste na primární instanci nakonfigurovali auditování, nastavte ho stejně jako v sekundární instanci. Další informace najdete v tématu Auditování Azure SQL pro službu Azure SQL Managed Instance.
Související obsah
Další informace najdete tady:
- Scénáře kontinuity
- Automatizované zálohy
- Obnovte databázi ze záloh iniciovaných službou.
- Skupiny převzetí služeb při selhání
- Pokyny pro zotavení po havárii
- Kontrolní seznam pro vysokou dostupnost a zotavení po havárii
- Zónově redundantní databáze