Skupina dostupnosti AlwaysOn na SQL Serveru na virtuálních počítačích Azure
Platí pro: ![]() SQL Server na virtuálním počítači Azure
SQL Server na virtuálním počítači Azure
Tento článek představuje skupiny dostupnosti AlwaysOn (AG) pro SQL Server na virtuálních počítačích Azure.
Začněte kurzem skupiny dostupnosti.
Přehled
Skupiny dostupnosti AlwaysOn na virtuálních počítačích Azure jsou podobné skupinám dostupnosti AlwaysOn místně a spoléhají na základní cluster s podporou převzetí služeb při selhání Windows Serveru. Vzhledem k tomu, že jsou virtuální počítače hostované v Azure, existuje několik dalších aspektů, jako je redundance virtuálních počítačů a směrování provozu v síti Azure.
Následující diagram znázorňuje skupinu dostupnosti pro SQL Server na virtuálních počítačích Azure:
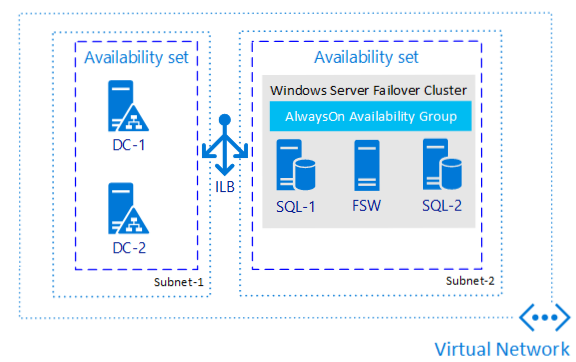
Poznámka:
Nyní je možné pomocí služby Azure Migrate lift and shift your availability group solution to SQL Server to SQL Server on Azure VMs. Další informace najdete v tématu Migrace skupiny dostupnosti.
Redundance virtuálních počítačů
Kvůli zvýšení redundance a vysoké dostupnosti by virtuální počítače s SQL Serverem měly být buď ve stejné skupině dostupnosti, nebo v různých zónách dostupnosti.
Umístění sady virtuálních počítačů do stejné skupiny dostupnosti chrání před výpadky v datovém centru způsobeném selháním vybavení (virtuální počítače v rámci skupiny dostupnosti nesdílejí prostředky) nebo z aktualizací (virtuální počítače v rámci skupiny dostupnosti se neaktualizují současně).
Zóny dostupnosti chránit před selháním celého datového centra, přičemž každá zóna představuje sadu datových center v rámci oblasti. Díky zajištění umístění prostředků do různých Zóny dostupnosti nemůže žádný výpadek na úrovni datového centra převést všechny virtuální počítače do offline režimu.
Při vytváření virtuálních počítačů Azure musíte zvolit mezi konfigurací skupin dostupnosti a Zóny dostupnosti. Virtuální počítač Azure se nemůže účastnit obojího.
I když Zóny dostupnosti může poskytovat lepší dostupnost než skupiny dostupnosti (99,99 % vs. 99,95 %), měli byste zvážit také výkon. Virtuální počítače v rámci skupiny dostupnosti se dají umístit do skupiny umístění bezkontaktní komunikace, která zaručuje, že jsou blízko sebe a minimalizují latenci sítě mezi nimi. Virtuální počítače umístěné v různých Zóny dostupnosti mají mezi nimi větší latenci sítě, což může zvýšit dobu potřebnou k synchronizaci dat mezi primárními a sekundárními replikami. To může způsobit zpoždění primární repliky a také zvýšit pravděpodobnost ztráty dat v případě neplánovaného převzetí služeb při selhání. Je důležité otestovat navrhované řešení při zatížení a zajistit, aby splňovala smlouvy SLA pro výkon i dostupnost.
Připojení
Pokud chcete odpovídat místnímu prostředí pro připojení k naslouchacímu procesu skupiny dostupnosti, nasaďte virtuální počítače s SQL Serverem do několika podsítí ve stejné virtuální síti. Několik podsítí neguje potřebu další závislosti na Azure Load Balanceru nebo názvu distribuované sítě (DNN) pro směrování provozu do naslouchacího procesu.
Pokud nasadíte virtuální počítače s SQL Serverem do jedné podsítě, můžete nakonfigurovat název virtuální sítě (VNN) a Azure Load Balancer nebo název distribuované sítě (DNN) pro směrování provozu do naslouchacího procesu skupiny dostupnosti. Projděte si rozdíly mezi těmito dvěma sítěmi a pak nasaďte název distribuované sítě (DNN) nebo název virtuální sítě (VNN) pro vaši skupinu dostupnosti.
Většina funkcí SQL Serveru pracuje transparentně se skupinami dostupnosti při používání sítě DNN, ale existují určité funkce, které mohou vyžadovat zvláštní pozornost. Další informace najdete v tématu Interoperabilita skupiny dostupnosti a sítě DNN.
Kromě toho mezi funkcemi naslouchacího procesu VNN a naslouchacího procesu DNN existují určité rozdíly v chování, které je důležité si uvědomit:
- Čas převzetí služeb při selhání: Doba převzetí služeb při selhání je rychlejší při použití naslouchacího procesu DNN, protože není potřeba čekat, až nástroj pro vyrovnávání zatížení sítě zjistí událost selhání a změní jeho směrování.
- Existující připojení: Připojení vytvořená ke konkrétní databázi v rámci skupiny dostupnosti při selhání se zavře, ale ostatní připojení k primární replice zůstanou otevřená, protože síť DNN zůstane online během procesu převzetí služeb při selhání. Liší se od tradičního prostředí VNN, kde se všechna připojení k primární replice obvykle zavírají, když skupina dostupnosti převezme služby při selhání, naslouchací proces přejde do režimu offline a primární replika přejde do sekundární role. Při použití naslouchacího procesu DNN možná budete muset upravit aplikační připojovací řetězec, abyste zajistili, že se připojení při převzetí služeb při selhání přesměrují na novou primární repliku.
- Otevřené transakce: Otevření transakcí proti databázi ve skupině dostupnosti při selhání se zavře a vrátí zpět a budete muset ručně znovu připojit. Například v aplikaci SQL Server Management Studio zavřete okno dotazu a otevřete nový.
Poznámka:
Pokud máte ve stejném clusteru více skupin AG nebo FCI a používáte buď naslouchací proces DNN, nebo naslouchací proces VNN, potřebuje každá skupina dostupnosti nebo FCI vlastní nezávislý spojovací bod.
Nastavení naslouchacího procesu VNN v Azure vyžaduje nástroj pro vyrovnávání zatížení. Nástroje pro vyrovnávání zatížení v Azure mají dvě hlavní možnosti: externí (veřejné) nebo interní. Externí (veřejný) nástroj pro vyrovnávání zatížení je přístupný z internetu a je přidružený k veřejné virtuální IP adrese, která je přístupná přes internet. Interní nástroj pro vyrovnávání zatížení podporuje pouze klienty ve stejné virtuální síti. U některého typu nástroje pro vyrovnávání zatížení je nutné povolit direct server Return.
Ke každé replice dostupnosti se stále můžete připojit samostatně tak, že se připojíte přímo k instanci služby. Vzhledem k tomu, že skupiny dostupnosti jsou zpětně kompatibilní s klienty zrcadlení databáze, můžete se připojit k replikám dostupnosti, jako jsou partneři zrcadlení databáze, pokud jsou repliky nakonfigurované podobně jako zrcadlení databáze:
- Existuje jedna primární replika a jedna sekundární replika.
- Sekundární replika je nakonfigurovaná jako nečitelná (možnost Čtení sekundární nastavená na Ne).
Následuje příklad klienta připojovací řetězec, který odpovídá této konfiguraci zrcadlení databáze pomocí ADO.NET nebo nativního klienta SQL Serveru:
Data Source=ReplicaServer1;Failover Partner=ReplicaServer2;Initial Catalog=AvailabilityDatabase;
Další informace o připojení klienta najdete tady:
- Použití klíčových slov připojovacího řetězce s nativním klientem SQL Serveru
- Připojení klientů k relaci zrcadlení databáze (SQL Server)
- Připojení k naslouchacímu procesu skupiny dostupnosti v hybridním IT
- Naslouchací procesy skupiny dostupnosti, připojení klienta a převzetí služeb při selhání aplikací (SQL Server)
- Použití připojovacích řetězců zrcadlení databáze se skupinami dostupnosti
Jedna podsíť vyžaduje nástroj pro vyrovnávání zatížení.
Když vytvoříte naslouchací proces skupiny dostupnosti v tradičním místním clusteru Windows Serveru s podporou převzetí služeb při selhání (WSFC), vytvoří se záznam DNS pro naslouchací proces s adresou IP, kterou zadáte, a tato IP adresa se mapuje na adresu MAC aktuální primární repliky v tabulkách přepínačů a směrovačů protokolu ARP v místní síti. Cluster to dělá pomocí gratuitous ARP (GARP), kde vysílá nejnovější mapování IP-to-MAC na síť při každém výběru nového primárního serveru po převzetí služeb při selhání. V tomto případě je IP adresa pro naslouchací proces a mac je aktuální primární repliky. GARP vynutí aktualizaci položek tabulky protokolu ARP pro přepínače a směrovače a pro všechny uživatele, kteří se připojují k IP adrese naslouchacího procesu, se bezproblémově směrují na aktuální primární repliku.
Z bezpečnostních důvodů není povolené vysílání v jakémkoli veřejném cloudu (Azure, Google, AWS), takže využití arps a GARPs v Azure se nepodporuje. Pokud chcete tento rozdíl překonat v síťových prostředích, virtuální počítače s SQL Serverem v jedné skupině dostupnosti podsítě spoléhají na nástroje pro vyrovnávání zatížení při směrování provozu na příslušné IP adresy. Nástroje pro vyrovnávání zatížení se konfigurují s front-endovou IP adresou, která odpovídá naslouchacímu procesu, a port sondy se přiřadí tak, aby se Nástroj pro vyrovnávání zatížení pravidelně dotazoval na stav replik ve skupině dostupnosti. Vzhledem k tomu, že na sondu TCP reaguje pouze virtuální počítač s primární replikou SQL Serveru, příchozí provoz se pak směruje na virtuální počítač, který úspěšně reaguje na sondu. Kromě toho je odpovídající port sondy nakonfigurovaný jako IP adresa clusteru WSFC, aby primární replika reagovala na sondu TCP.
Skupiny dostupnosti nakonfigurované v jedné podsíti musí ke směrování provozu do příslušné repliky použít nástroj pro vyrovnávání zatížení nebo název distribuované sítě (DNN). Abyste se těmto závislostem vyhnuli, nakonfigurujte skupinu dostupnosti ve více podsítích, aby naslouchací proces skupiny dostupnosti byl nakonfigurovaný s IP adresou pro repliku v každé podsíti a mohl odpovídajícím způsobem směrovat provoz.
Pokud jste skupinu dostupnosti už vytvořili v jedné podsíti, můžete ji migrovat do prostředí s více podsítěmi.
Mechanismus zapůjčení
Knihovna DLL prostředků skupiny dostupnosti pro SQL Server určuje stav skupiny dostupnosti na základě mechanismu zapůjčení skupiny dostupnosti a detekce stavu AlwaysOn. Knihovna DLL prostředků skupiny dostupnosti zveřejňuje stav prostředků prostřednictvím operace IsAlive . Monitorování prostředků se dotazuje isAlive v intervalu prezenčních signálů clusteru, který je nastavený hodnotami clusteru CrossSubnetDelay a SameSubnetDelay . Na primárním uzlu služba clusteru zahájí převzetí služeb při selhání vždy, když volání IsAlive knihovny DLL prostředku vrátí, že skupina dostupnosti není v pořádku.
Knihovna DLL prostředků skupiny dostupnosti monitoruje stav interních komponent SYSTÉMU SQL Server. Sp_server_diagnostics hlásí stav těchto komponent SQL Serveru v intervalu řízeném HealthCheckTimeout.
Na rozdíl od jiných mechanismů převzetí služeb při selhání hraje instance SQL Serveru aktivní roli v mechanismu zapůjčení. Mechanismus zapůjčení se používá jako ověřování LooksAlive mezi hostitelem prostředků clusteru a procesem SQL Serveru. Tento mechanismus se používá k zajištění, že obě strany (služba clusteru a služba SQL Serveru) jsou často v kontaktu, kontrolují stav sebe navzájem a nakonec brání situaci rozděleného mozku.
Při konfiguraci skupiny dostupnosti ve virtuálních počítačích Azure je často potřeba tyto prahové hodnoty nakonfigurovat jinak, než by se nakonfigurovaly v místním prostředí. Pokud chcete nakonfigurovat nastavení prahových hodnot podle osvědčených postupů pro virtuální počítače Azure, prohlédni si osvědčené postupy clusteru.
Konfigurace sítě
Nasaďte virtuální počítače s SQL Serverem do několika podsítí, kdykoli je to možné, abyste se vyhnuli závislosti na Azure Load Balanceru nebo názvu distribuované sítě (DNN) pro směrování provozu do naslouchacího procesu skupiny dostupnosti.
V clusteru s podporou převzetí služeb při selhání virtuálního počítače Azure doporučujeme pro každý server (uzel clusteru) jednu síťovou kartu. Sítě Azure mají fyzickou redundanci, což v clusteru s podporou převzetí služeb při selhání virtuálního počítače Azure nepotřebuje další síťové karty. Přestože zpráva o ověření clusteru vydává upozornění, že uzly jsou dostupné jenom v jedné síti, toto upozornění je možné bezpečně ignorovat v clusterech s podporou převzetí služeb při selhání virtuálních počítačů Azure.
Základní skupina dostupnosti
Protože základní skupina dostupnosti neumožňuje více než jednu sekundární repliku a sekundární replika nemá přístup ke čtení, můžete použít zrcadlení databáze připojovací řetězec pro základní skupiny dostupnosti. Použití připojovací řetězec eliminuje potřebu mít naslouchací procesy. Odebrání závislosti na naslouchacím procesu je užitečné pro skupiny dostupnosti na virtuálních počítačích Azure, protože eliminuje potřebu nástroje pro vyrovnávání zatížení nebo přidání dalších IP adres do nástroje pro vyrovnávání zatížení, pokud máte více naslouchacích procesů pro další databáze.
Pokud se například chcete explicitně připojit pomocí protokolu TCP/IP k databázi skupiny dostupnosti AdventureWorks na Replica_A nebo Replica_B základní skupiny dostupnosti (nebo jakékoli skupiny dostupnosti, která má pouze jednu sekundární repliku a přístup pro čtení není v sekundární replice povolen), klientská aplikace může poskytnout následující zrcadlení databáze připojovací řetězec pro úspěšné připojení ke skupině dostupnosti.
Server=Replica_A; Failover_Partner=Replica_B; Database=AdventureWorks; Network=dbmssocn
Možnosti nasazení
Tip
Eliminujte potřebu služby Azure Load Balancer nebo názvu distribuované sítě (DNN) pro vaši skupinu dostupnosti AlwaysOn vytvořením virtuálních počítačů s SQL Serverem v několika podsítích ve stejné virtuální síti Azure.
Existuje několik možností nasazení skupiny dostupnosti na SQL Server na virtuálních počítačích Azure, některé s větší automatizací než jiné.
Následující tabulka obsahuje porovnání dostupných možností:
| Azure Portal | Azure CLI / PowerShell | Šablony Rychlý start | Ručně (jedna podsíť) | Ručně (více podsítí) | |
|---|---|---|---|---|---|
| Verze SQL Serveru | 2016 + | 2016 + | 2016 + | 2012 + | 2012 + |
| Edice SQL Serveru | Enterprise | Enterprise | Enterprise | Enterprise, Standard | Enterprise, Standard |
| Verze Windows Serveru | 2016 + | 2016 + | 2016 + | Vše | Vše |
| Vytvoří cluster za vás | Yes | Ano | Ano | No | No |
| Vytvoří skupinu dostupnosti a naslouchací proces za vás | Yes | No | No | No | No |
| Vytvoří nezávisle naslouchací proces a nástroj pro vyrovnávání zatížení | – | Ne | No | Ano | – |
| Je možné pomocí této metody vytvořit naslouchací proces DNN? | – | Ne | No | Ano | – |
| Konfigurace kvora WSFC | Disk s kopií cloudu | Disk s kopií cloudu | Disk s kopií cloudu | Vše | Vše |
| Zotavení po havárii s více oblastmi | No | No | No | Ano | Yes |
| Podpora více podsítí | Yes | No | No | Není k dispozici | Ano |
| Podpora existující služby AD | Yes | Ano | Ano | Ano | Yes |
| Zotavení po havárii s více zónami ve stejné oblasti | Yes | Ano | Ano | Ano | Yes |
| Distribuovaná skupina dostupnosti bez AD | No | No | No | Ano | Yes |
| Distribuovaná skupina dostupnosti bez clusteru | No | No | No | Ano | Yes |
| Vyžaduje nástroj pro vyrovnávání zatížení nebo DNN | No | Ano | Ano | Ano | Ne |
Další kroky
Začněte tím, že si prohlédnete osvědčené postupy HADR a pak skupinu dostupnosti nasadíte ručně pomocí kurzu skupiny dostupnosti.
Další informace najdete v následujících tématech: