Odolnost a zotavení po havárii ve službě Azure Web PubSub
Odolnost a zotavení po havárii jsou běžnou potřebou online systémů. Služba Azure Web PubSub již zaručuje 99,9% dostupnost, ale stále se jedná o regionální službu. Pokud dojde k výpadku v celé oblasti, je důležité, aby služba pokračovala ve zpracování zpráv v reálném čase v jiné oblasti.
Pro regionální zotavení po havárii doporučujeme následující dva přístupy:
- Povolte geografickou replikaci (snadný způsob). Tato funkce bude automaticky zpracovávat regionální převzetí služeb při selhání. Pokud je tato možnost povolená, zůstane jenom jedna instance Azure SignalR a žádné změny kódu se nezavádějí. Podrobnosti najdete v geografické replikaci .
- Využití více koncových bodů V tomto dokumentu se dozvíte, jak to udělat.
Architektura s vysokou dostupností pro službu Web PubSub
Při používání služby Web PubSub existují dva typické vzory:
- Jedním z nich je model klient-server, který klienti odesílají události na server a server odesílají zprávy klientům.
- Dalším je model klienta, který klienti pub/sub zprávy prostřednictvím služby Web PubSub do jiných klientů.
Následující části popisují různé způsoby, jak tyto dva vzory provést zotavení po havárii.
Architektura s vysokou dostupností pro model klient-server
Pokud chcete zajistit odolnost mezi oblastmi pro službu Web PubSub, musíte nastavit více instancí služby v různých oblastech. Takže když je jedna oblast mimo provoz, ostatní je možné použít jako zálohu.
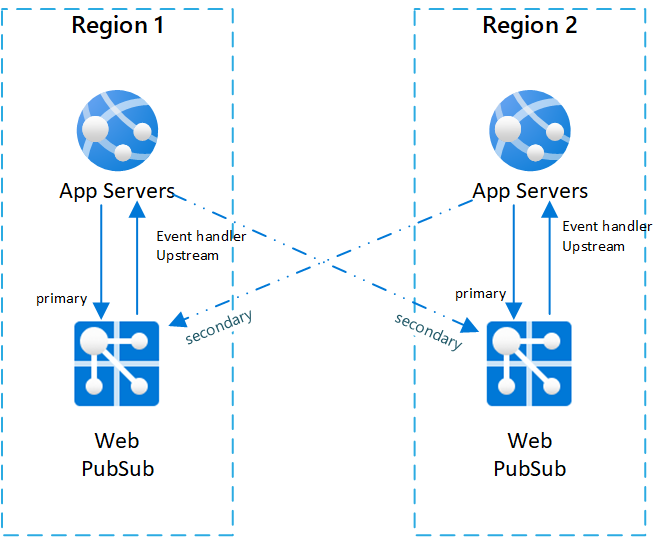
Jedním z typických nastavení scénáře mezi oblastmi je mít dva (nebo více) dvojic instancí služby Web PubSub a aplikačních serverů.
Uvnitř každého párového aplikačního serveru a služby Web PubSub se nachází ve stejné oblasti a služba Web PubSub nastaví obslužnou rutinu události upstream na aplikační server ve stejné oblasti.
Abychom lépe ilustroval architekturu, voláme službu Web PubSub primární službou na aplikační server ve stejné dvojici. A jako sekundární služby aplikačního serveru voláme služby Web PubSub v jiných párech.
Aplikační server může pomocí rozhraní API pro kontrolu stavu služby zjistit, jestli jsou primární a sekundární služby v pořádku nebo ne. Například pro službu Web PubSub s názvem demovrátí koncový bod https://demo.webpubsub.azure.com/api/health hodnotu 200, pokud je služba v pořádku. Aplikační server může pravidelně volat koncové body nebo volat koncové body na vyžádání a zkontrolovat, jestli jsou koncové body v pořádku. Klienti WebSocket obvykle vyjednávají s aplikačním serverem nejprve, aby získali adresu URL připojení ke službě Web PubSub a aplikace používá tento krok vyjednávání k převzetí služeb při selhání klientů do jiných sekundárních služeb, které jsou v pořádku. Podrobný postup:
- Když klient vyjedná s aplikačním serverem, měl by aplikační server vracet pouze primární koncové body služby Web PubSub, takže v normálním případě se klienti připojují jenom k primárním koncovým bodům.
- Když je primární instance nižší, vyjednat by měl vrátit sekundární koncový bod, který je v pořádku, aby klient stále mohl vytvářet připojení a klient se připojuje k sekundárnímu koncovému bodu.
- Když je primární instance vzhůru, vyjednat by měl vrátit primární koncový bod, který je v pořádku, aby se teď klienti mohli připojit k primárnímu koncovému bodu.
- Při vysílánízpráv aplikačního serveru by měl vysílat zprávy všem koncovým bodům, které jsou v pořádku, včetně primárního i sekundárního.
- Aplikační server může zavřít připojení připojená k sekundárním koncovým bodům, aby se klienti znovu připojili k primárnímu koncovému bodu, který je v pořádku.
Díky této topologii se zprávy z jednoho serveru stále dají doručit všem klientům, protože všechny aplikační servery a instance služby Web PubSub jsou vzájemně propojené.
Zatím jsme strategii neintegrovanou do sady SDK, takže prozatím aplikace potřebuje tuto strategii implementovat sama.
Stručně řečeno, co je potřeba implementovat na straně aplikace:
- Kontrola stavu Aplikace může buď zkontrolovat, jestli je služba v pořádku, pomocí rozhraní API pro kontrolu stavu služby pravidelně na pozadí nebo na vyžádání pro každé volání vyjednávat .
- Logika vyjednávání Aplikace ve výchozím nastavení vrací primární koncový bod, který je v pořádku. Když je primární koncový bod dole, aplikace vrátí sekundární koncový bod, který je v pořádku.
- Logika vysílání Když se zprávy odesílají více klientům, musí aplikace zajistit, aby vysílala zprávy do všech koncových bodů, které jsou v pořádku .
Níže je diagram znázorňující takovou topologii:
Posloupnost převzetí služeb při selhání a osvědčený postup
Teď máte správnou systémovou topologii. Kdykoli je jedna instance služby Web PubSub mimo provoz, bude online provoz směrován do jiných instancí. Tady je to, co se stane, když je primární instance mimo provoz (a po nějaké době se obnoví):
- Primární instance služby je ukončená, všichni klienti připojení k této instanci budou vyřazeni.
- Noví klienti nebo znovu připojte klienta k aplikačnímu serveru
- Aplikační server zjistí, že primární instance služby je v provozu, a vyjednání přestane vracet tento koncový bod a začne vracet sekundární koncový bod, který je v pořádku.
- Klienti se připojují k sekundární instanci.
- Teď sekundární instance přebírá veškerý online provoz. Všechny zprávy ze serveru do klientů se stále dají doručovat, protože sekundární jsou připojené ke všem aplikačním serverům. Zprávy událostí klienta na server se ale odesílají pouze na nadřazený aplikační server ve stejné oblasti.
- Jakmile se primární instance obnoví a znovu online, aplikační server zjistí, že primární instance je v pořádku. Funkce Negotiate teď vrátí znovu primární koncový bod, takže se noví klienti připojí zpět k primárnímu. Stávající klienti se ale neodpojí a budou pokračovat v připojení k sekundárnímu počítači, dokud se neodpojí.
Následující diagramy znázorňují, jak se převzetí služeb při selhání provádí:
Obr.1 Před převzetím služeb při selhání 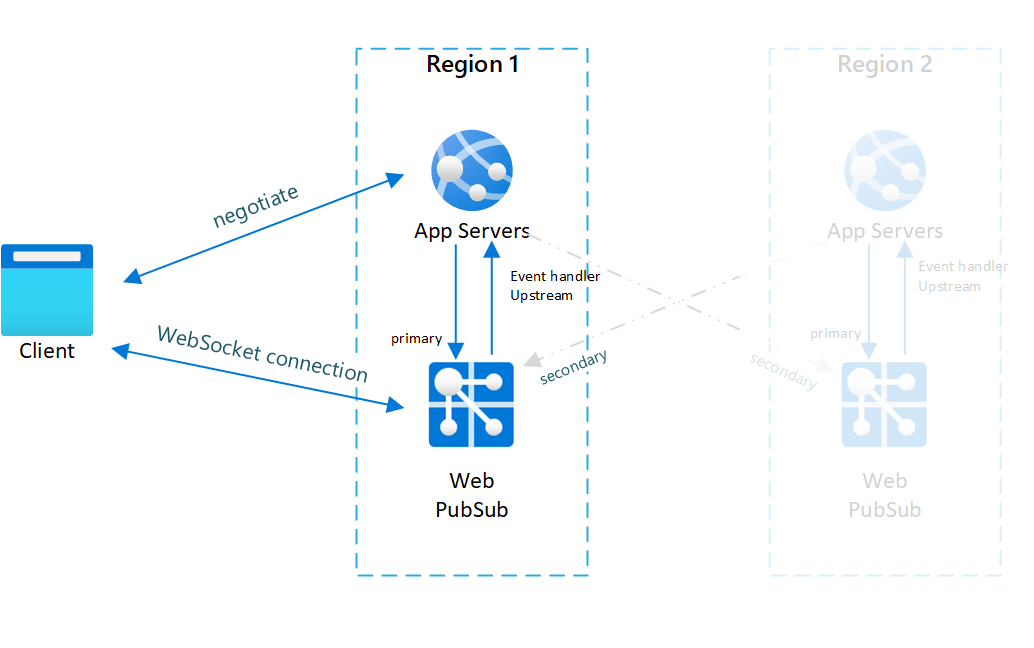
Obr.2 Po převzetí služeb při selhání 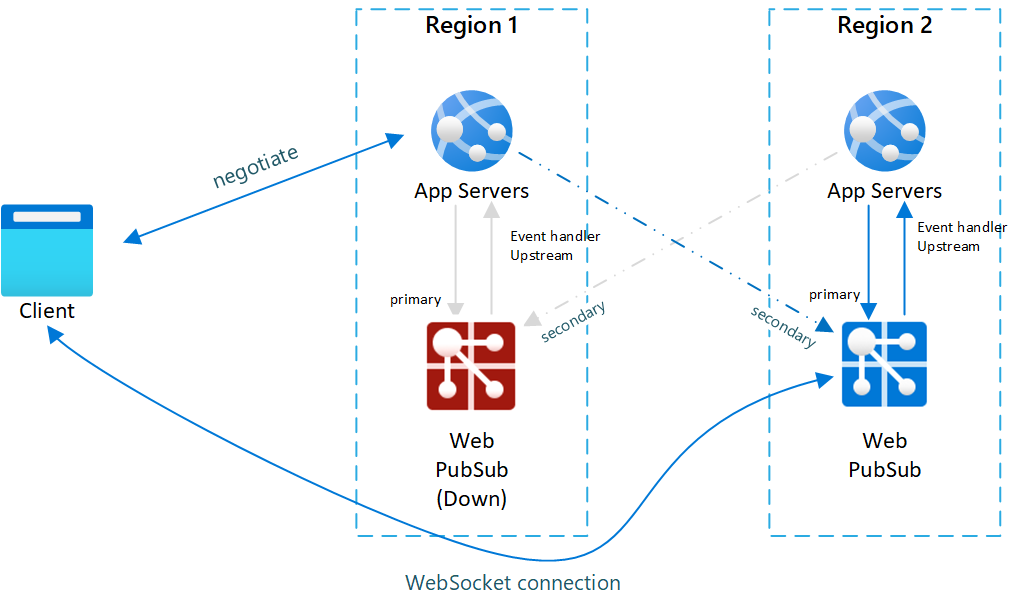
Obr.3 Krátký čas po obnovení primárního 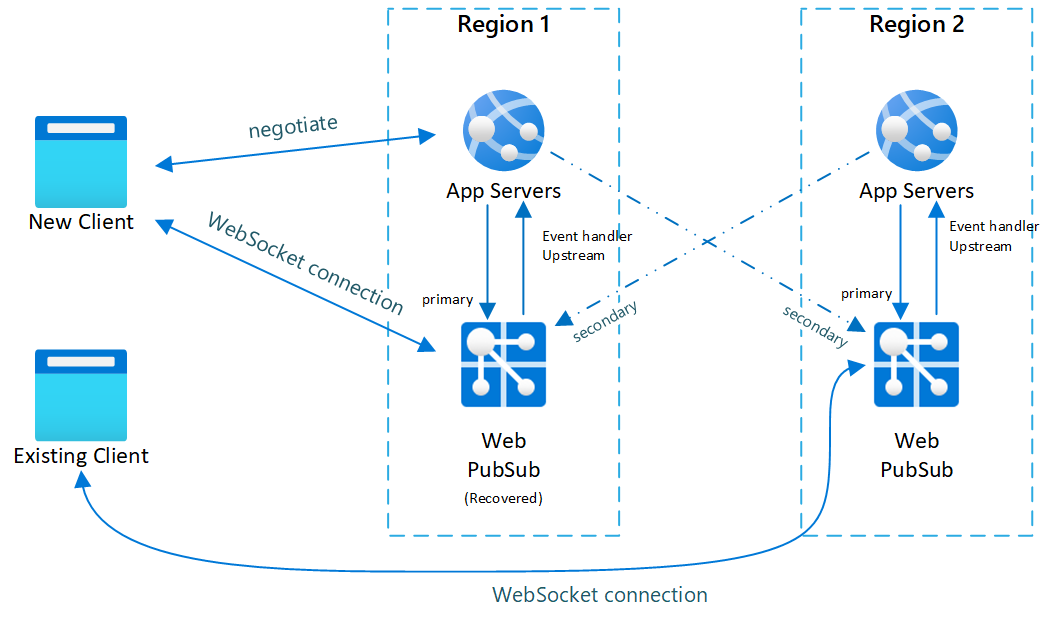
V normálním případě se můžete podívat jenom na primární aplikační server a službu Web PubSub, která má online provoz (modře).
Po převzetí služeb při selhání se stane aktivní také sekundární aplikační server a služba Web PubSub. Jakmile je primární služba Web PubSub opět online, budou se noví klienti připojovat k primární webové pubSub. Stávající klienti se ale stále připojují k sekundárnímu, takže obě instance mají provoz.
Po odpojení všech stávajících klientů se váš systém vrátí do normálního stavu (obr. 1).
Implementace architektury s vysokou dostupností napříč oblastmi má dva hlavní vzory:
- První z nich je mít dvojici aplikačního serveru a instance služby Web PubSub, která přebírá veškerý online provoz, a má další dvojici jako zálohu (označovanou jako aktivní/pasivní, znázorněná na obr. 1).
- Druhým je mít dva (nebo více) párů aplikačních serverů a instancí služby Web PubSub, z nichž každá je součástí online provozu a slouží jako záloha pro jiné páry (označované jako aktivní/aktivní, podobně jako obr. 3).
Služba Web PubSub podporuje oba vzory. Hlavním rozdílem je způsob implementace aplikačních serverů. Pokud jsou aplikační servery aktivní/pasivní, služba Web PubSub bude také aktivní/pasivní (protože primární aplikační server vrátí pouze primární instanci služby Web PubSub). Pokud jsou aplikační servery aktivní nebo aktivní, služba Web PubSub bude také aktivní/aktivní (protože všechny aplikační servery vrátí své vlastní primární instance Web PubSub, takže všechny z nich můžou získat provoz).
Mějte na vědomí, které vzory se rozhodnete použít, budete muset připojit každou instanci služby Web PubSub k aplikačnímu serveru jako primární roli.
Vzhledem k povaze připojení WebSocket (je to dlouhé připojení), klienti budou mít za sebou výpadky připojení, když dojde k havárii a převzetí služeb při selhání. Tyto případy budete muset zpracovat na straně klienta, aby bylo transparentní pro koncové zákazníky. Po zavření připojení se například znovu připojte.
Architektura s vysokou dostupností pro model klienta
U modelu klienta není v současné době možné podporovat zotavení po havárii s nulovým výpadkem pomocí více instancí. Pokud máte požadavky na vysokou dostupnost, zvažte použití geografické replikace.
Jak otestovat převzetí služeb při selhání
Postupujte podle kroků pro aktivaci převzetí služeb při selhání:
- Na kartě Sítě pro primární prostředek na portálu zakažte přístup k veřejné síti. Pokud má prostředek povolenou privátní síť, zamítejte veškerý provoz pomocí pravidel řízení přístupu.
- Restartujte primární prostředek.
Další kroky
V tomto článku jste zjistili, jak nakonfigurovat aplikaci tak, aby dosáhla odolnosti pro službu Web PubSub.
Pomocí těchto prostředků můžete začít vytvářet vlastní aplikaci: