Správa rozpočtů, nákladů a kvót pro Azure Machine Learning v organizačním měřítku
Když spravujete náklady na výpočetní prostředky, které vzniknou na Učení Azure Machine, v organizaci se škálou mnoha úloh, mnoha týmů a uživatelů, existuje celá řada problémů správy a optimalizace, které je potřeba projít.
V tomto článku představujeme osvědčené postupy pro optimalizaci nákladů, správu rozpočtů a sdílení kvót pomocí služby Azure Machine Učení. Tyto osvědčené postupy vycházejí ze zkušeností a poznatků získaných při vedení interních týmů Microsoftu věnujících se strojovému učení a při spolupráci s našimi zákazníky. Získáte následující informace:
- Optimalizujte výpočetní prostředky tak, aby splňovaly požadavky na úlohy.
- Využijte nejlepší využití rozpočtu týmu.
- Plánování, správa a sdílení rozpočtů, nákladů a kvót na podnikové úrovni
Optimalizace výpočetních prostředků tak, aby splňovaly požadavky na úlohy
Když spustíte nový projekt strojového učení, může být potřeba průzkumná práce, abyste získali dobrý přehled o požadavcích na výpočetní prostředky. Tato část obsahuje doporučení, jak určit správnou volbu skladové položky virtuálního počítače pro trénování, odvozování nebo jako pracovní stanici, ze které můžete pracovat.
Určení velikosti výpočetních prostředků pro trénování
Požadavky na hardware pro trénovací úlohu se můžou lišit od projektu po projekt. Pro splnění těchto požadavků nabízí Azure Machine Učení compute různé typy virtuálních počítačů:
- Pro obecné účely: Vyvážený poměr procesoru k paměti.
- Optimalizováno pro paměť: Vysoký poměr paměti k procesoru.
- Optimalizované pro výpočty: Vysoký poměr procesoru k paměti.
- Vysokovýkonné výpočetní prostředí: Zajištění výkonu, škálovatelnosti a efektivity nákladů pro různé úlohy HPC z reálného světa
- Instance s grafickými procesory: Specializované virtuální počítače cílené na náročné vykreslování grafiky a úpravy videa a také trénování a odvozování modelů (ND) s hloubkovým učením.
Možná ještě nevíte, jaké jsou vaše požadavky na výpočetní prostředky. V tomto scénáři doporučujeme začít s některou z následujících nákladově efektivních výchozích možností. Tyto možnosti jsou určené pro zjednodušené testování a trénovací úlohy.
| Typ | Velikost virtuálního počítače | Specifikace |
|---|---|---|
| Procesor | Standard_DS3_v2 | 4 jádra, 14 gigabajty (GB) RAM, 28 GB úložiště |
| GPU | Standard_NC6 | 6 jader, 56 gigabajtů (GB) RAM, 380 GB úložiště, NVIDIA Tesla K80 GPU |
Pokud chcete získat nejlepší velikost virtuálního počítače pro váš scénář, může se skládat ze zkušební verze a chyby. Tady je několik aspektů, které je potřeba vzít v úvahu.
- Pokud potřebujete procesor:
- Pokud trénujete na velkých datových sadách, použijte virtuální počítač optimalizovaný pro paměť.
- Pokud provádíte odvozování v reálném čase nebo jiné úlohy citlivé na latenci, použijte výpočetní optimalizovaný virtuální počítač.
- K urychlení trénování používejte virtuální počítač s více jádry a pamětí RAM.
- Pokud potřebujete GPU, informace o výběru virtuálního počítače najdete v velikostech virtuálních počítačů optimalizovaných pro GPU.
- Pokud provádíte distribuované trénování, použijte velikosti virtuálních počítačů, které mají více GPU.
- Pokud provádíte distribuované trénování na více uzlech, použijte gpu s připojením NVLink.
Když vyberete typ virtuálního počítače a skladovou položku, které nejlépe vyhovují vašim úlohám, vyhodnoťte srovnatelné skladové položky virtuálních počítačů jako kompromis mezi výkonem procesoru a GPU a cenami. Z hlediska správy nákladů může úloha přiměřeně dobře fungovat na několika skladových po úrovních.
Některé GPU, jako je řada SÍŤOVÝch adaptérů, zejména NC_Promo SKU, mají podobné schopnosti jako jiné GPU, jako je nízká latence a schopnost paralelně spravovat více výpočetních úloh. Jsou k dispozici za snížené ceny v porovnání s některými dalšími GRAFICKÝmi procesory. Zvážení výběru skladových položek virtuálních počítačů k úloze může výrazně ušetřit náklady na konci.
Připomenutí důležitosti pro využití spočívá v registraci většího počtu gpu, které nemusí nutně probíhat s rychlejšími výsledky. Místo toho se ujistěte, že jsou gpu plně využité. Například pečlivě zkontrolujte potřebu NVIDIA CUDA. I když se může vyžadovat pro vysoce výkonné spouštění GPU, vaše úloha na něm nemusí záviset.
Určení velikosti výpočetních prostředků pro odvozování
Požadavky na výpočetní prostředky pro scénáře odvozování se liší od trénovacích scénářů. Dostupné možnosti se liší podle toho, jestli váš scénář vyžaduje offline odvozování v dávce nebo vyžaduje online odvozování v reálném čase.
V případě scénářů odvozování v reálném čase zvažte následující návrhy:
- Pomocí možností profilace v modelu pomocí služby Azure Machine Učení určete, kolik procesoru a paměti je potřeba modelu přidělit při nasazování jako webové služby.
- Pokud provádíte odvozování v reálném čase, ale nepotřebujete vysokou dostupnost, nasaďte je do služby Azure Container Instances (bez výběru skladové položky).
- Pokud provádíte odvozování v reálném čase, ale potřebujete vysokou dostupnost, nasaďte ji do služby Azure Kubernetes Service.
- Pokud používáte tradiční modely strojového učení a přijímáte < 10 dotazů za sekundu, začněte skladovou jednotkou procesoru. Skladové položky řady F-series často dobře fungují.
- Pokud používáte modely hlubokého učení a přijímáte > 10 dotazů za sekundu, vyzkoušejte SKU GPU NVIDIA (NCasT4_v3 často dobře funguje) s Tritonem.
V případě scénářů dávkového odvozování zvažte následující návrhy:
- Pokud pro dávkové odvozování používáte kanály Učení Azure Machine, postupujte podle pokynů v tématu Určení velikosti výpočetních prostředků pro trénování a zvolte počáteční velikost virtuálního počítače.
- Optimalizujte náklady a výkon horizontálním škálováním. Jednou z klíčových metod optimalizace nákladů a výkonu je paralelizace úlohy pomocí kroku paralelního spuštění ve službě Azure Machine Učení. Tento krok kanálu umožňuje paralelně spouštět úlohu pomocí mnoha menších uzlů, což umožňuje horizontální škálování. Pro paralelizaci je ale režijní náklady. V závislosti na úloze a stupni paralelismu, kterého lze dosáhnout, může nebo nemusí být volbou krok paralelního spuštění.
Určení velikosti výpočetní instance
Pro interaktivní vývoj se doporučuje výpočetní instance služby Azure Machine Učení. Nabídka výpočetní instance (CI) přináší výpočetní prostředky s jedním uzlem, které jsou vázané na jednoho uživatele, a lze je použít jako cloudovou pracovní stanici.
Některé organizace nepovolují používání produkčních dat na místních pracovních stanicích, mají vynucená omezení pro prostředí pracovní stanice nebo omezují instalaci balíčků a závislostí v podnikovém IT prostředí. Výpočetní instanci lze použít jako pracovní stanici k vyřešení tohoto omezení. Nabízí zabezpečené prostředí s přístupem k produkčním datům a běží na imagích s oblíbenými balíčky a nástroji pro datové vědy předinstalované.
Při spuštění výpočetní instance se uživateli účtují výpočetní prostředky virtuálního počítače, Load Balancer úrovně Standard (včetně pravidel pro vyrovnávání zatížení a odchozích přenosů a zpracování dat), disk s operačním systémem (disk spravovaný ssd úrovně Premium P10), dočasný disk (typ dočasného disku závisí na zvolené velikosti virtuálního počítače) a veřejnou IP adresu. Pokud chcete ušetřit náklady, doporučujeme uživatelům zvážit:
- Spusťte a zastavte výpočetní instanci, když se nepoužívá.
- Práce s ukázkou dat ve výpočetní instanci a horizontálním navýšením kapacity výpočetních clusterů pro práci s celou sadou dat
- Během vývoje nebo testování můžete odesílat úlohy experimentování v místním cílovém výpočetním režimu v výpočetní instanci nebo když při odesílání úloh v plném měřítku přepnete na sdílenou výpočetní kapacitu. Například mnoho epoch, úplná sada dat a vyhledávání hyperparametrů.
Pokud výpočetní instanci zastavíte, zastaví fakturaci za výpočetní hodiny virtuálního počítače, dočasný disk a náklady na zpracování dat Load Balanceru úrovně Standard. Všimněte si, že uživatel stále platí za disk s operačním systémem a Load Balancer úrovně Standard obsahoval pravidla pro vyrovnávání zatížení a odchozí spojení i v případě, že je výpočetní instance zastavená. Všechna data uložená na disku s operačním systémem se uchovávají prostřednictvím zastavení a restartování.
Vyladění zvolené velikosti virtuálního počítače monitorováním využití výpočetních prostředků
Informace o využití a využití výpočetních prostředků azure Učení můžete zobrazit prostřednictvím služby Azure Monitor. Můžete zobrazit podrobnosti o nasazení a registraci modelu, podrobnosti kvóty, jako jsou aktivní a nečinné uzly, podrobnosti o spuštění, jako jsou zrušená a dokončená spuštění, a využití výpočetních prostředků pro využití GPU a procesoru.
Na základě přehledů z podrobností monitorování můžete lépe naplánovat nebo upravit využití prostředků napříč týmem. Pokud si například všimnete velkého počtu nečinných uzlů za poslední týden, můžete s odpovídajícími vlastníky pracovního prostoru aktualizovat konfiguraci výpočetního clusteru, abyste zabránili těmto dodatečným nákladům. Výhody analýzy vzorů využití můžou pomoct s prognózováním nákladů a vylepšení rozpočtu.
K těmto metrikám se dostanete přímo z webu Azure Portal. Přejděte do pracovního prostoru Azure Machine Učení a v části Monitorování na levém panelu vyberte Metriky. Pak můžete vybrat podrobnosti o tom, co chcete zobrazit, jako jsou metriky, agregace a časové období. Další informace najdete na stránce dokumentace k monitorování služby Azure Machine Učení.
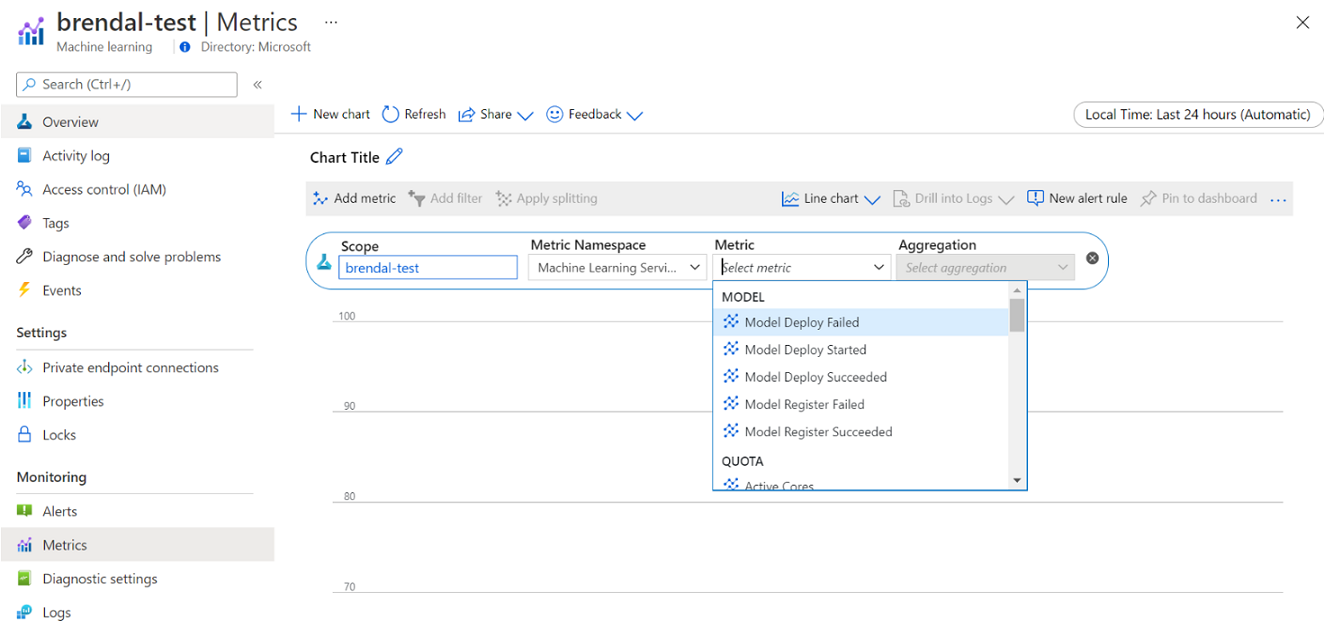
Přepínání mezi místním cloudovým výpočetním prostředím, jedním uzlem a cloudovým výpočetním prostředím s více uzly během vývoje
V průběhu životního cyklu strojového učení existují různé požadavky na výpočetní prostředky a nástroje. Azure Machine Učení je možné s využitím sady SDK a rozhraní příkazového řádku z prakticky jakékoli upřednostňované konfigurace pracovní stanice použít ke splnění těchto požadavků.
Pokud chcete ušetřit náklady a pracovat produktivně, doporučujeme:
- Naklonujte základ kódu experimentování místně pomocí Gitu a odešlete úlohy do cloudového výpočetního prostředí pomocí sady Azure Machine Učení SDK nebo rozhraní příkazového řádku.
- Pokud je vaše datová sada velká, zvažte správu vzorku dat na místní pracovní stanici a zachování úplné datové sady v cloudovém úložišti.
- Parametrizujte základ kódu experimentování, abyste mohli nakonfigurovat spouštění úloh s různým počtem epoch nebo datových sad různých velikostí.
- Nezakódujte cestu ke složce vaší datové sady. Pak můžete snadno použít stejný základ kódu s různými datovými sadami a v kontextu místního a cloudového spouštění.
- Spouštění úloh experimentování v místním cílovém výpočetním režimu při vývoji nebo testování nebo při přepnutí na sdílenou kapacitu výpočetního clusteru při odesílání úloh v plném měřítku
- Pokud je vaše datová sada velká, můžete pracovat s ukázkou dat na místní pracovní stanici nebo pracovní stanici výpočetní instance a současně škálovat na cloudový výpočetní výkon ve službě Azure Machine Učení pracovat s celou sadou dat.
- Pokud provádění úloh trvá delší dobu, zvažte optimalizaci základu kódu pro distribuované trénování, aby bylo možné horizontálně horizontálně navyšovat kapacitu.
- Navrhněte distribuované trénovací úlohy pro elasticitu uzlů, abyste umožnili flexibilní použití výpočetních prostředků s jedním uzlem a více uzly a usnadnili používání výpočetních prostředků, které je možné předem připravit.
Kombinování výpočetních typů pomocí kanálů azure machine Učení
Při orchestraci pracovních postupů strojového učení můžete kanál definovat několika kroky. Každý krok v kanálu může běžet na vlastním typu výpočetních prostředků. To vám umožní optimalizovat výkon a náklady tak, aby splňovaly různé výpočetní požadavky v rámci životního cyklu strojového učení.
Nejlepší využití rozpočtu týmu
I když rozhodnutí o přidělování rozpočtu můžou být mimo rozsah kontroly nad individuálním týmem, je tým obvykle oprávněn používat přidělený rozpočet podle svých nejlepších potřeb. Tým může dosáhnout vyššího využití clusteru, snížení celkových nákladů a využití většího počtu výpočetních hodin ze stejného rozpočtu díky obchodování s prioritou úloh a nákladům. To může mít za následek vyšší produktivitu týmu.
Optimalizace nákladů na sdílené výpočetní prostředky
Klíčem k optimalizaci nákladů na sdílené výpočetní prostředky je zajistit, aby se používaly k plné kapacitě. Tady je několik tipů pro optimalizaci nákladů na sdílené prostředky:
- Pokud používáte výpočetní instance, zapněte je jenom v případě, že máte kód ke spuštění. Vypněte je, když se nepoužívají.
- Při použití výpočetních clusterů nastavte minimální počet uzlů na 0 a maximální počet uzlů na číslo, které se vyhodnocuje na základě omezení rozpočtu. Pomocí cenové kalkulačky Azure můžete vypočítat náklady na plné využití jednoho uzlu virtuálního počítače vybrané skladové položky virtuálního počítače. Automatické škálování vertikálně snížit kapacitu všech výpočetních uzlů, když ho nikdo nepoužívá. Vertikálně navýšit kapacitu až na počet uzlů, pro které máte rozpočet. Automatické škálování můžete nakonfigurovat tak, aby vertikálně snížit kapacitu všech výpočetních uzlů.
- Monitorujte využití prostředků, jako je využití procesoru a využití GPU při trénování modelů. Pokud se prostředky plně nepoužívají, upravte kód tak, aby lépe používal prostředky, nebo vertikálně navyšte kapacitu na menší nebo levnější velikosti virtuálních počítačů.
- Vyhodnoťte, jestli můžete pro svůj tým vytvořit sdílené výpočetní prostředky, abyste se vyhnuli nedostatečné efektivitě výpočetních prostředků způsobených operacemi škálování clusteru.
- Optimalizace zásad automatického škálování výpočetního clusteru na základě metrik využití
- Pomocí kvót pracovního prostoru můžete řídit množství výpočetních prostředků, ke kterým mají jednotlivé pracovní prostory přístup.
Zavedení priority plánování vytvořením clusterů pro více skladových položek virtuálních počítačů
V rámci kvót a rozpočtových omezení musí tým vymážit včasné provádění úloh oproti nákladům, aby se zajistilo, že důležité úlohy běží včas a rozpočet se použije nejlepším možným způsobem.
Pro zajištění nejlepšího využití výpočetních prostředků se doporučuje, aby týmy vytvářely clustery různých velikostí a s nízkou prioritou a vyhrazenými prioritami virtuálních počítačů. Výpočty s nízkou prioritou využívají nadbytečnou kapacitu v Azure, a proto mají snížené sazby. Na nevýhodě se tyto počítače dají předcházet, kdykoli přijde žádost o vyšší prioritu.
Pomocí clusterů s různou velikostí a prioritou je možné zavést koncept priority plánování. Pokud například experimentální a produkční úlohy soutěží o stejnou kvótu GPU NC , může mít produkční úloha přednost před experimentální úlohou. V takovém případě spusťte produkční úlohu ve vyhrazeném výpočetním clusteru a experimentální úlohu na výpočetním clusteru s nízkou prioritou. Když kvóta klesne na krátkou dobu, experimentální úloha se zastaví ve prospěch produkční úlohy.
Vedle priority virtuálního počítače zvažte spouštění úloh na různých skladových posílacích virtuálních počítačů. Spuštění úlohy na instanci virtuálního počítače s GPU P40 může trvat déle než v GPU V100. Vzhledem k tomu, že instance virtuálních počítačů V100 můžou být plně využité nebo plně využité kvóty, může být doba dokončení V40 stále rychlejší z hlediska propustnosti úlohy. Můžete také zvážit spouštění úloh s nižší prioritou u méně výkonných a levnějších instancí virtuálních počítačů z hlediska správy nákladů.
Předčasné ukončení spuštění v případě, že se trénování nekonverguje
Když průběžně experimentujete a vylepšujete model podle směrného plánu, možná spouštíte různá spuštění experimentů, z nichž každá má mírně odlišné konfigurace. U jednoho spuštění můžete upravit vstupní datové sady. U jiného spuštění můžete provést změnu hyperparametru. Ne všechny změny můžou být stejně účinné jako ostatní. Brzy zjistíte, že změna nemá zamýšlený vliv na kvalitu trénování modelu. Pokud chcete zjistit, jestli se trénování nekonverguje, sledujte průběh trénování během běhu. Například protokolováním metrik výkonu po každé epochě trénování. Zvažte předčasné ukončení úlohy, abyste uvolnili prostředky a rozpočet na další zkušební verzi.
Plánování, správa a sdílení rozpočtů, nákladů a kvót
S tím, jak organizace roste počet případů použití strojového učení a týmů, vyžaduje zvýšenou provozní vyspělost z IT a financí a také koordinaci mezi jednotlivými týmy strojového učení, aby se zajistily efektivní operace. Správa kapacity a kvót na podnikové úrovni je důležitá k řešení nedostatku výpočetních prostředků a k překonání režijních nákladů na správu.
Tato část popisuje osvědčené postupy pro plánování, správu a sdílení rozpočtů, nákladů a kvót v podnikovém měřítku. Je založená na učení od správy mnoha školicích prostředků GPU pro interní strojové učení v Microsoftu.
Principy výdajů na prostředky s využitím služby Azure Machine Učení
Jednou z největších výzev jako správce pro plánování potřeb výpočetních prostředků je začít s novými historickými informacemi jako odhadem směrného plánu. V praktickém smyslu začne většina projektů od malého rozpočtu jako první krok.
Abyste pochopili, odkud rozpočet směřuje, je důležité vědět, odkud náklady Učení Azure Machine pocházejí:
- Azure Machine Učení poplatky jenom za využitou výpočetní infrastrukturu a nepřidává příplatek za výpočetní náklady.
- Když se vytvoří pracovní prostor azure machine Učení, vytvoří se také několik dalších prostředků pro povolení služby Azure Machine Učení: Key Vault, Přehledy aplikací, Azure Storage a Azure Container Registry. Tyto prostředky se používají ve službě Azure Machine Učení a za tyto prostředky platíte.
- Ke spravovaným výpočetním prostředkům jsou spojené náklady, jako jsou trénovací clustery, výpočetní instance a spravované koncové body odvozování. S těmito spravovanými výpočetními prostředky se účtují následující náklady na infrastrukturu: virtuální počítače, virtuální síť, nástroj pro vyrovnávání zatížení, šířka pásma a úložiště.
Sledování vzorů útraty a lepší vytváření sestav pomocí značek
Správa istrátory často chtějí mít možnost sledovat náklady na různé prostředky v Učení Azure Machine. Označování je přirozené řešení tohoto problému a je v souladu s obecným přístupem používaným Azure a mnoha dalšími poskytovateli cloudových služeb. Díky podpoře značek teď uvidíte rozpis nákladů na úrovni výpočetních prostředků, takže získáte přístup k podrobnějšímu zobrazení, které vám pomůže s lepším monitorováním nákladů, lepším vykazováním a větší transparentností.
Označování umožňuje umístit přizpůsobené značky do pracovních prostorů a výpočetních prostředků (ze šablon Azure Resource Manageru a studio Azure Machine Learning) a dále filtrovat tyto prostředky ve službě Microsoft Cost Management na základě těchto značek a sledovat vzorce útraty. Tuto funkci je možné nejlépe využít ve scénářích s interními poplatky. Kromě toho můžou být značky užitečné pro zachycení metadat nebo podrobností spojených s výpočetními prostředky, jako je projekt, tým nebo určitý fakturační kód. Díky tomu je označování velmi přínosné pro měření, kolik peněz utrácíte na různých zdrojích, a proto získáte hlubší přehled o vašich nákladech a výdajích napříč týmy nebo projekty.
Existují také značky vložené do systému umístěné na výpočetních prostředcích, které umožňují filtrovat na stránce Analýza nákladů podle značky "Typ výpočetních prostředků", abyste viděli podrobný rozpis celkových výdajů a zjistili, jakou kategorii výpočetních prostředků může přisoudovat většina vašich nákladů. To je užitečné zejména pro získání lepšího přehledu o vašich trénovacích vzorech oproti odvozování nákladů.
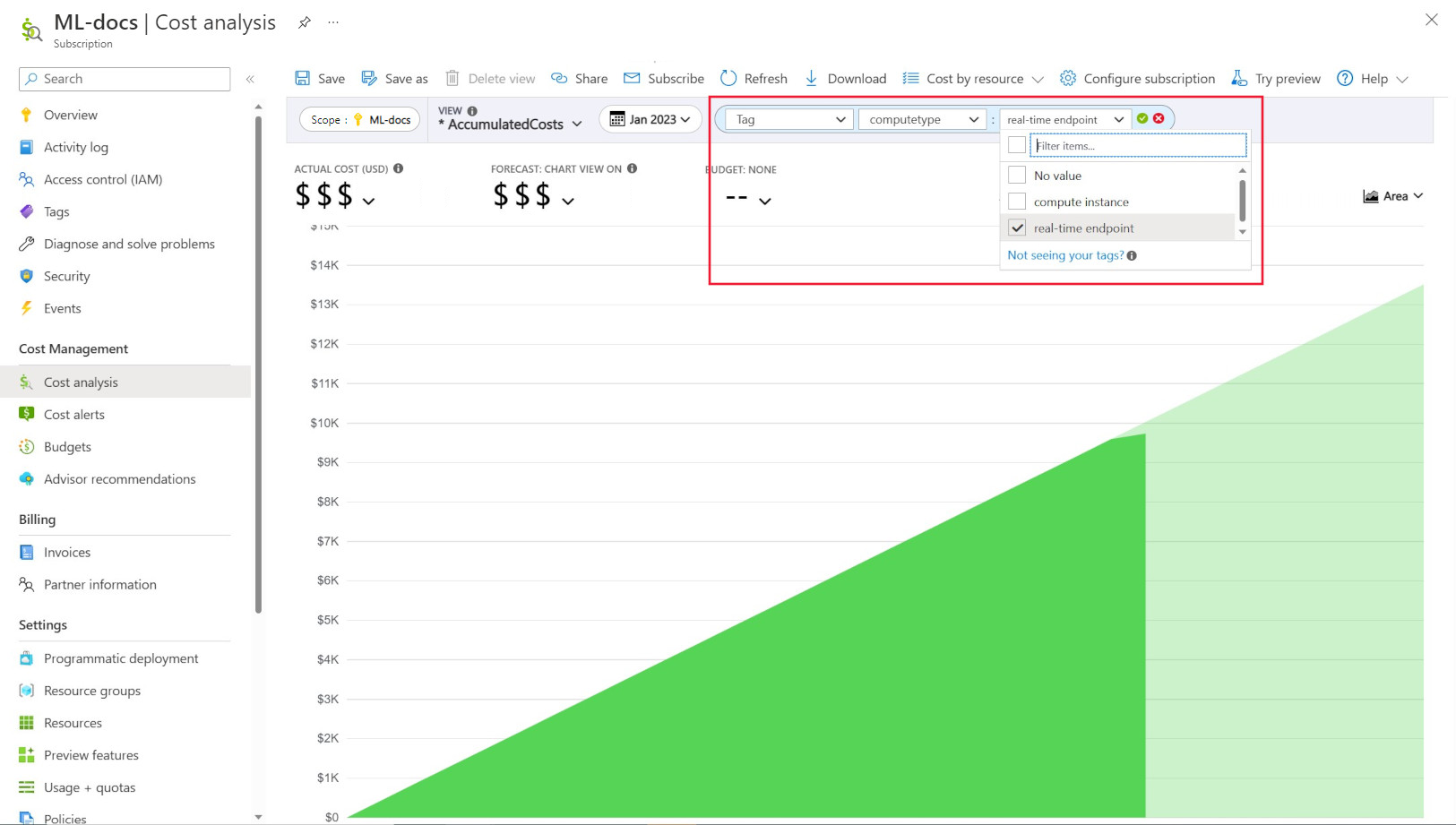
Řízení a omezení využití výpočetních prostředků podle zásad
Když spravujete prostředí Azure s mnoha úlohami, může být náročné zachovat přehled výdajů na prostředky. Azure Policy může pomoct řídit a řídit útraty za prostředky omezením konkrétních vzorů využití v prostředí Azure.
Pro službu Azure Machine Učení doporučujeme nastavit zásady tak, aby umožňovaly pouze použití konkrétních skladových položek virtuálních počítačů. Zásady můžou pomoct zabránit a řídit výběr drahých virtuálních počítačů. Zásady se dají použít také k vynucení využití skladových položek virtuálních počítačů s nízkou prioritou.
Přidělení a správa kvót na základě obchodní priority
Azure umožňuje nastavit limity pro přidělování kvót u předplatného a na úrovni pracovního prostoru azure machine Učení. Omezení toho, kdo může spravovat kvótu prostřednictvím řízení přístupu na základě role v Azure (RBAC), může pomoct zajistit využití prostředků a předvídatelnost nákladů.
Dostupnost kvóty GPU může být v rámci vašich předplatných málo. Pokud chcete zajistit vysoké využití kvót napříč úlohami, doporučujeme sledovat, jestli se kvóta nejlépe používá a přiřazuje napříč úlohami.
V Microsoftu se pravidelně zjišťuje, jestli se kvóty GPU nejlépe používají a přidělují napříč týmy strojového učení vyhodnocením potřeb kapacity podle obchodní priority.
Předem potvrdit kapacitu
Pokud máte dobrý odhad, kolik výpočetních prostředků se použije v příštím roce nebo dalších několika letech, můžete si koupit rezervované instance virtuálních počítačů Azure se slevou. Existují roční nebo tříleté nákupní podmínky. Vzhledem k tomu, že se zlevní rezervované instance virtuálních počítačů Azure, můžou se v porovnání s průběžnými platbami výrazně ušetřit náklady.
Azure Machine Učení podporuje rezervované výpočetní instance. Slevy se automaticky použijí na spravované výpočetní prostředky azure Učení.
Správa uchovávání dat
Při každém spuštění kanálu strojového učení je možné zprostředkující datové sady vygenerovat v každém kroku kanálu pro ukládání dat do mezipaměti a opakované použití. Růst dat jako výstup těchto kanálů strojového učení se může stát problematickou součástí organizace, která spouští mnoho experimentů strojového učení.
Datoví vědci obvykle netrávit čas čištěním přechodných datových sad, které se generují. V průběhu času se sčítá množství vygenerovaných dat. Azure Storage nabízí možnost zvýšit správu životního cyklu dat. Pomocí správy životního cyklu služby Azure Blob Storage můžete nastavit obecné zásady pro přesun dat, která se nepoužívají, do studenějších úrovní úložiště a ušetřit náklady.
Aspekty optimalizace nákladů na infrastrukturu
Sítě
Náklady na sítě Azure se účtují z odchozí šířky pásma z datacentra Azure. Všechna příchozí data do datacentra Azure jsou zdarma. Klíčem ke snížení nákladů na síť je nasazení všech prostředků ve stejné oblasti datacentra, kdykoli je to možné. Pokud můžete nasadit pracovní prostor Azure Machine Učení a výpočetní prostředky ve stejné oblasti, ve které jsou vaše data, můžete dosáhnout nižších nákladů a vyššího výkonu.
Možná budete chtít mít privátní připojení mezi místní sítí a sítí Azure, abyste měli hybridní cloudové prostředí. ExpressRoute vám to umožňuje, ale vzhledem k vysokým nákladům na ExpressRoute může být cenově výhodnější přejít z nastavení hybridního cloudu a přesunout všechny prostředky do cloudu Azure.
Azure Container Registry
Mezi určující faktory optimalizace nákladů pro Azure Container Registry patří:
- Požadovaná propustnost pro stahování imagí Dockeru z registru kontejneru do služby Azure Machine Učení
- Požadavky na funkce podnikového zabezpečení, jako je Azure Private Link
V produkčních scénářích, kde je vyžadováno vysoké propustnosti nebo podnikové zabezpečení, se doporučuje skladová položka Azure Container Registry úrovně Premium.
Pro scénáře vývoje/testování, ve kterých je propustnost a zabezpečení méně kritické, doporučujeme skladovou položku Standard nebo skladovou položku Premium.
Pro službu Azure Machine Učení se nedoporučuje základní skladová položka služby Azure Container Registry. Nedoporučuje se kvůli nízké propustnosti a nedostatku zahrnutého úložiště, které je možné rychle překročit v imagích Dockeru v Azure Machine Učení relativně velké velikosti (1+GB).
Při výběru oblastí Azure zvažte dostupnost výpočetního typu.
Při výběru oblasti výpočetních prostředků mějte na paměti dostupnost výpočetní kvóty. Oblíbené a větší oblasti, jako jsou USA – východ, USA – západ a Západní Evropa, mají tendenci mít vyšší výchozí hodnoty kvót a větší dostupnost většiny procesorů a GPU v porovnání s některými dalšími oblastmi s přísnějšími omezeními kapacity.
Další informace
Další kroky
Další informace o uspořádání a nastavení prostředí Azure Machine Učení najdete v tématu Uspořádání a nastavení Učení prostředí Azure Machine.
Další informace o osvědčených postupech ve službě Machine Učení DevOps se službou Azure Machine Učení najdete v průvodci DevOps pro strojové učení.