Modelování dat grafů pomocí služby Azure Cosmos DB pro Apache Gremlin
PLATÍ PRO: ![]() Skřítek
Skřítek
Tento článek obsahuje doporučení pro použití datových modelů grafů. Tyto osvědčené postupy jsou nezbytné pro zajištění škálovatelnosti a výkonu grafového databázového systému při vývoji dat. Efektivní datový model je zvlášť důležitý pro rozsáhlé grafy.
Požadavky
Proces popsaný v této příručce vychází z následujících předpokladů:
- Identifikují se entity v problémovém prostoru. Tyto entity mají být pro každý požadavek atomicky využity. Jinými slovy, databázový systém není navržený tak, aby načítal data jedné entity v několika požadavcích na dotazy.
- Existuje znalost požadavků na čtení a zápis pro databázový systém. Tyto požadavky řídí optimalizace potřebné pro datový model grafu.
- Principy standardu grafu vlastností Apache Tinkerpop jsou dobře pochopitelné.
Kdy potřebuji grafovou databázi?
Řešení grafové databáze je možné optimálně použít, pokud entity a relace v datové doméně mají některou z následujících charakteristik:
- Entity jsou vysoce propojené prostřednictvím popisných relací. Výhodou v tomto scénáři je, že relace zůstávají v úložišti.
- Existují cyklické relace nebo entity odkazované na sebe. Tento model je často výzvou při použití relačních nebo dokumentových databází.
- Mezi entitami se dynamicky vyvíjejí vztahy . Tento model se vztahuje zejména na hierarchická nebo stromová data s mnoha úrovněmi.
- Mezi entitami jsou relace M:N.
- U entit i relací existují požadavky na zápis a čtení.
Pokud jsou výše uvedená kritéria splněná, přístup k grafové databázi pravděpodobně poskytuje výhody pro složitost dotazů, škálovatelnost datového modelu a výkon dotazů.
Dalším krokem je určení, jestli se graf použije k analytickým nebo transakčním účelům. Pokud je graf určený k použití pro náročné výpočetní úlohy a zpracování dat, je vhodné prozkoumat konektor Spark služby Cosmos DB a knihovnu GraphX.
Jak používat objekty grafu
Standard grafu vlastností Apache Tinkerpop definuje dva typy objektů: vrcholy a hrany.
Níže jsou uvedené osvědčené postupy pro vlastnosti v objektech grafu:
| Objekt | Vlastnost | Type | Notes |
|---|---|---|---|
| vrcholové | ID | String | Jedinečně vynucuje každý oddíl. Pokud při vložení není zadaná hodnota, uloží se automaticky vygenerovaný identifikátor GUID. |
| vrcholové | Popisek | String | Tato vlastnost slouží k definování typu entity, kterou vrchol představuje. Pokud není zadaná hodnota, použije se výchozí vrchol hodnoty. |
| vrcholové | Vlastnosti | String, boolean, numeric | Seznam samostatných vlastností uložených jako páry klíč-hodnota v každém vrcholu. |
| vrcholové | Klíč oddílu | String, boolean, numeric | Tato vlastnost definuje, kde jsou uloženy vrcholy a jeho odchozí hrany. Přečtěte si další informace o dělení grafu. |
| Edge | ID | String | Jedinečně vynucuje každý oddíl. Automaticky vygenerováno ve výchozím nastavení. Hrany obvykle nemusí být jedinečně načteny POMOCÍ ID. |
| Edge | Popisek | String | Tato vlastnost slouží k definování typu relace, kterou mají dva vrcholy. |
| Edge | Vlastnosti | String, boolean, numeric | Seznam samostatných vlastností uložených jako páry klíč-hodnota v jednotlivých hraničních zařízeních. |
Poznámka:
Hrany nevyžadují hodnotu klíče oddílu, protože hodnota se automaticky přiřadí na základě jejich zdrojového vrcholu. Další informace najdete v článku Použití děleného grafu ve službě Azure Cosmos DB.
Pokyny pro modelování entit a vztahů
Následující pokyny vám pomůžou přistupovat k modelování dat pro grafovou databázi Azure Cosmos DB pro Apache Gremlin . Tyto pokyny předpokládají, že existuje existující definice datové domény a dotazů na ni.
Poznámka:
Následující kroky se zobrazují jako doporučení. Před zvážením modelu jako připraveného pro produkční prostředí byste ho měli vyhodnotit a otestovat. Doporučení jsou navíc specifická pro implementaci rozhraní Gremlin API služby Azure Cosmos DB.
Modelování vrcholů a vlastností
Prvním krokem datového modelu grafu je mapování každé identifikované entity na objekt vrcholu. Mapování 1:1 všech entit na vrcholy by mělo být počátečním krokem a může se změnit.
Jedním z běžných nástrah je mapování vlastností jedné entity jako samostatných vrcholů. Podívejte se na následující příklad, ve kterém je stejná entita reprezentována dvěma různými způsoby:
Vlastnosti založené na vrcholech: V tomto přístupu entita používá tři samostatné vrcholy a dvě hrany k popisu svých vlastností. I když tento přístup může snížit redundanci, zvyšuje složitost modelu. Zvýšení složitosti modelu může vést k vyšší latenci, složitosti dotazů a výpočetním nákladům. Tento model může také představovat výzvy při dělení.
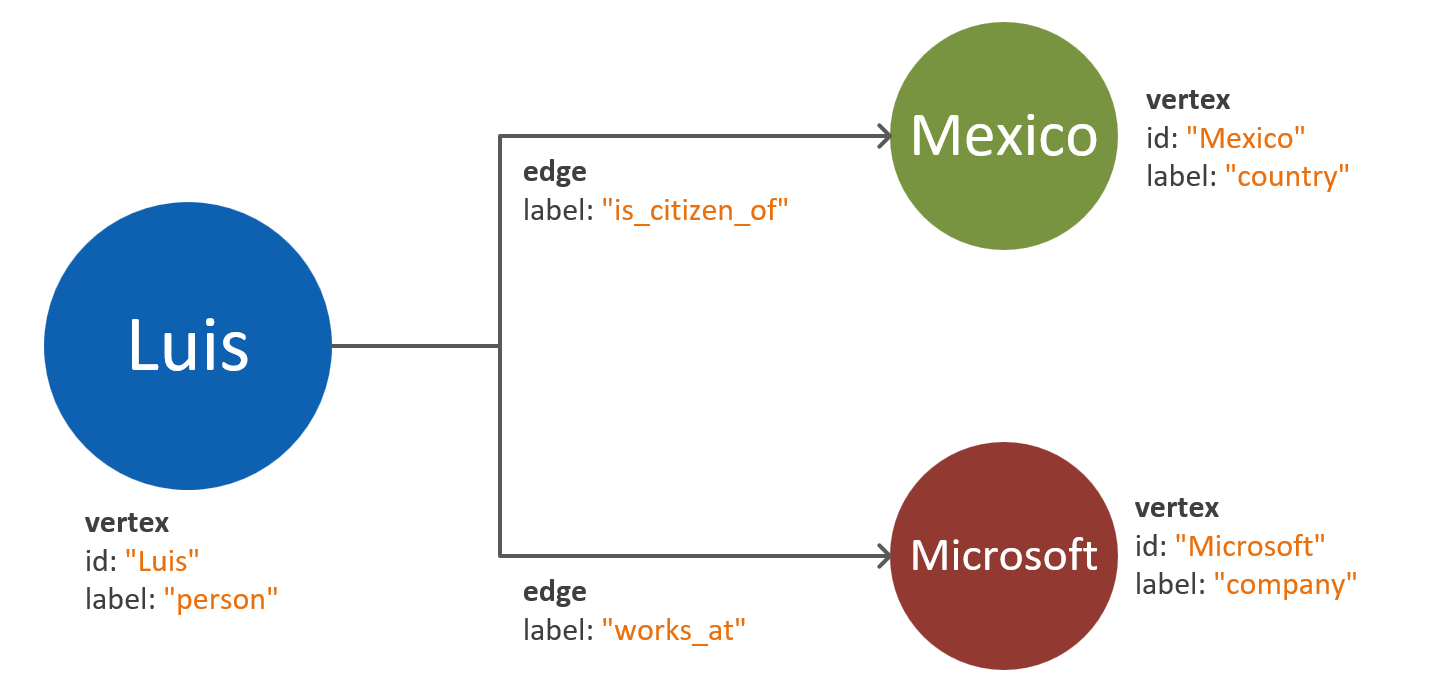
Vrcholy vložené do vlastností: Tento přístup využívá seznam párů klíč-hodnota k reprezentaci všech vlastností entity uvnitř vrcholu. Tento přístup snižuje složitost modelu, což vede k jednodušším dotazům a nákladově efektivnějším procházením.

Poznámka:
Předchozí diagramy znázorňují zjednodušený grafový model, který porovnává pouze dva způsoby dělení vlastností entity.
Model vrcholů vložených vlastností obecně poskytuje výkonnější a škálovatelný přístup. Výchozí přístup k novému datovému modelu grafu by se měl přiklonit k tomuto vzoru.
Existují však scénáře, kdy odkazování na vlastnost může přinést výhody. Pokud se například odkazovaná vlastnost často aktualizuje. Pomocí samostatného vrcholu můžete reprezentovat vlastnost, která se neustále mění, aby se minimalizovalo množství operací zápisu, které aktualizace vyžaduje.
Modely relací s hraničními směry
Po modelování vrcholů je možné přidat hrany, které označují vztahy mezi nimi. Prvním aspektem, který je potřeba vyhodnotit, je směr relace.
Objekty Edge mají výchozí směr, za kterým následuje procházení při použití out() nebo outE() funkcí. Použití tohoto přirozeného směru vede k efektivní operaci, protože všechny vrcholy jsou uloženy s jejich odchozími hrany.
Procházení v opačném směru okraje pomocí in() funkce ale vždy vede k dotazu napříč oddíly. Přečtěte si další informace o dělení grafu. Pokud je potřeba funkci neustále procházet in() , doporučujeme přidat hrany v obou směrech.
Směr okraje můžete určit pomocí .to() kroku Gremlin nebo .from() predikátů .addE() . Nebo pomocí knihovny Bulk Executor pro rozhraní Gremlin API.
Poznámka:
Objekty Edge mají ve výchozím nastavení směr.
Popisky relací
Použití popisků vztahů může zlepšit efektivitu operací překladu hraničních zařízení. Tento vzor můžete použít následujícími způsoby:
- K označení relace použijte jiné než obecné termíny.
- Přidružte popisek zdrojového vrcholu k popisku cílového vrcholu s názvem relace.
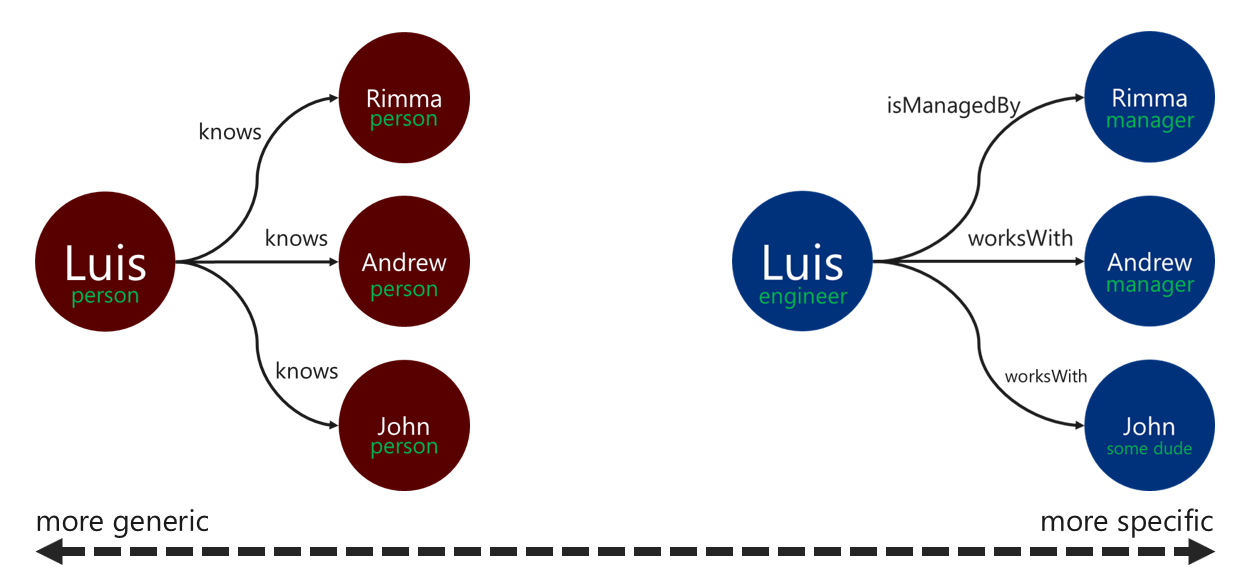
Konkrétnější popisek, který procházení používá k filtrování okrajů, tím lépe. Toto rozhodnutí může mít významný vliv i na náklady na dotazy. Náklady na dotazy můžete kdykoli vyhodnotit pomocí kroku executionProfile.
Další kroky
- Podívejte se na seznam podporovaných kroků Gremlin.
- Seznamte se s dělením grafových databází pro zpracování rozsáhlých grafů.
- Vyhodnoťte dotazy Gremlin pomocí kroku profilu spuštění.
- Datový model návrhu grafů třetích stran