Správa indexování ve službě Azure Cosmos DB pro MongoDB
PLATÍ PRO: ![]() MongoDB
MongoDB
Azure Cosmos DB pro MongoDB využívá základní funkce správy indexů služby Azure Cosmos DB. Tento článek se zaměřuje na přidání indexů pomocí služby Azure Cosmos DB pro MongoDB. Indexy jsou specializované datové struktury, které dotazují data zhruba o řád rychleji.
Indexování pro server MongoDB verze 3.6 a vyšší
Server Azure Cosmos DB pro MongoDB verze 3.6 nebo novější automaticky indexuje _id pole a klíč horizontálního oddílu (pouze v horizontálně dělených kolekcích). Rozhraní API automaticky vynucuje jedinečnost pole na klíč horizontálního _id oddílu.
Rozhraní API pro MongoDB se chová jinak než ve službě Azure Cosmos DB for NoSQL, které ve výchozím nastavení indexuje všechna pole.
Úprava zásad indexování
Doporučujeme upravit zásady indexování v Průzkumníku dat na webu Azure Portal. V Průzkumníku dat můžete přidat jedno pole a zástupné kóty z editoru zásad indexování:

Poznámka:
Složené indexy nemůžete vytvářet pomocí editoru zásad indexování v Průzkumníku dat.
Typy indexů
Jedno pole
Indexy můžete vytvořit na libovolném poli. Pořadí řazení indexu s jedním polem nezáleží. Následující příkaz vytvoří index pole name:
db.coll.createIndex({name:1})
Stejný index jednoho pole můžete vytvořit na name webu Azure Portal:
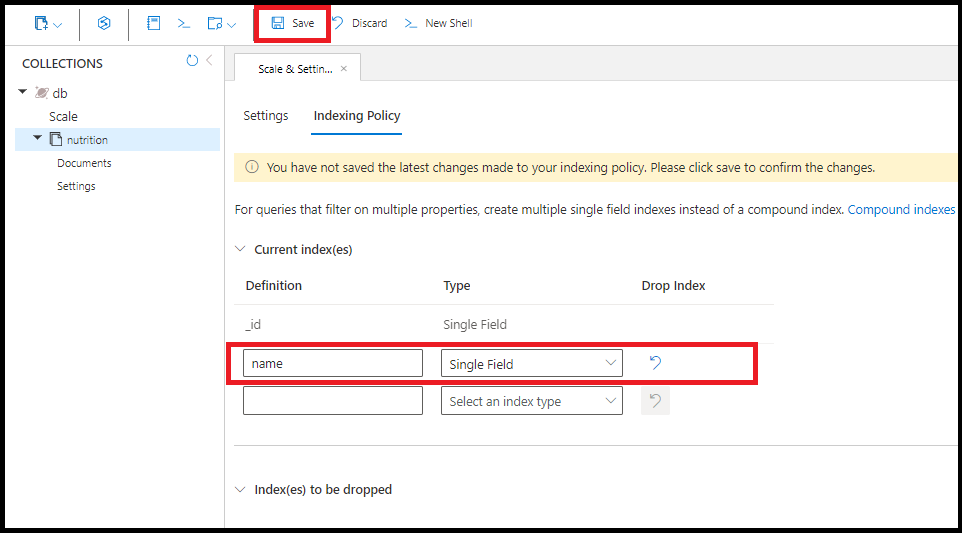
Jeden dotaz používá více indexů s jedním polem, pokud je k dispozici. Pro každou kolekci můžete vytvořit až 500 indexů s jedním polem.
Složené indexy (server MongoDB verze 3.6+)
V rozhraní API pro MongoDB se vyžadují složené indexy, pokud váš dotaz potřebuje možnost řadit na více polích najednou. U dotazů s více filtry, které není potřeba řadit, vytvořte místo složeného indexu více indexů s jedním polem, abyste ušetřili náklady na indexování.
Složený index nebo indexy s jedním polem pro každé pole ve složeného indexu mají stejný výkon pro filtrování v dotazech.
Složené indexy v vnořených polí nejsou ve výchozím nastavení podporovány kvůli omezením polí. Pokud vnořené pole neobsahuje pole, funguje index podle očekávání. Pokud vaše vnořené pole obsahuje pole (kdekoli na cestě), bude tato hodnota v indexu ignorována.
Například složený index obsahující people.dylan.age v tomto případě funguje, protože v cestě není žádné pole:
{
"people": {
"dylan": {
"name": "Dylan",
"age": "25"
},
"reed": {
"name": "Reed",
"age": "30"
}
}
}
Stejný složený index v tomto případě nefunguje, protože v cestě je pole:
{
"people": [
{
"name": "Dylan",
"age": "25"
},
{
"name": "Reed",
"age": "30"
}
]
}
Tuto funkci můžete pro svůj databázový účet povolit povolením funkce EnableUniqueCompoundNestedDocs.
Poznámka:
Složené indexy nelze vytvářet v polích.
Následující příkaz vytvoří složený index polí name a age:
db.coll.createIndex({name:1,age:1})
Složené indexy můžete použít k efektivnímu řazení na více polích najednou, jak je znázorněno v následujícím příkladu:
db.coll.find().sort({name:1,age:1})
Předchozí složený index můžete také použít k efektivnímu řazení dotazu s opačným pořadím řazení u všech polí. Tady je příklad:
db.coll.find().sort({name:-1,age:-1})
Posloupnost cest ve složeného indexu se ale musí přesně shodovat s dotazem. Tady je příklad dotazu, který by vyžadoval další složený index:
db.coll.find().sort({age:1,name:1})
Indexy s více klíči
Azure Cosmos DB vytváří indexy s více klíči pro indexování obsahu uloženého v polích. Pokud indexujete pole s maticovou hodnotou, Azure Cosmos DB automaticky indexuje každý prvek v poli.
Geoprostorové indexy
Mnoho geoprostorových operátorů bude těžit z geoprostorových indexů. Azure Cosmos DB pro MongoDB v současné době podporuje 2dsphere indexy. Rozhraní API zatím nepodporuje 2d indexy.
Tady je příklad vytvoření geoprostorového indexu v location poli:
db.coll.createIndex({ location : "2dsphere" })
Textové indexy
Azure Cosmos DB pro MongoDB v současné době nepodporuje textové indexy. Pro dotazy na vyhledávání textu na řetězce byste měli použít integraci služby Azure AI Search se službou Azure Cosmos DB.
Indexy se zástupnými znaky
Indexy se zástupnými znamény můžete použít k podpoře dotazů na neznámá pole. Představme si, že máte kolekci, která obsahuje data o rodinách.
Tady je část ukázkového dokumentu v této kolekci:
"children": [
{
"firstName": "Henriette Thaulow",
"grade": "5"
}
]
Tady je další příklad, tentokrát s mírně odlišnou sadou vlastností v children:
"children": [
{
"familyName": "Merriam",
"givenName": "Jesse",
"pets": [
{ "givenName": "Goofy" },
{ "givenName": "Shadow" }
]
},
{
"familyName": "Merriam",
"givenName": "John",
}
]
V této kolekci můžou mít dokumenty mnoho různých možných vlastností. Pokud chcete indexovat všechna data v children poli, máte dvě možnosti: vytvořte samostatné indexy pro každou jednotlivou vlastnost nebo vytvořte jeden index se zástupnými znaky pro celé children pole.
Vytvoření indexu se zástupným znakem
Následující příkaz vytvoří index zástupných znaků pro všechny vlastnosti v rámci children:
db.coll.createIndex({"children.$**" : 1})
Na rozdíl od MongoDB můžou indexy se zástupnými cardy podporovat více polí v predikátech dotazů. Pokud místo vytvoření samostatného indexu pro každou vlastnost použijete jeden index se zástupnými znaky, nebude výkon dotazů nijak jiný.
Pomocí syntaxe zástupných znaků můžete vytvořit následující typy indexů:
- Jedno pole
- Geoprostorové
Indexování všech vlastností
Tady je postup, jak vytvořit index se zástupným znakem pro všechna pole:
db.coll.createIndex( { "$**" : 1 } )
Indexy se zástupnými znaky můžete vytvořit také pomocí Průzkumníka dat na webu Azure Portal:
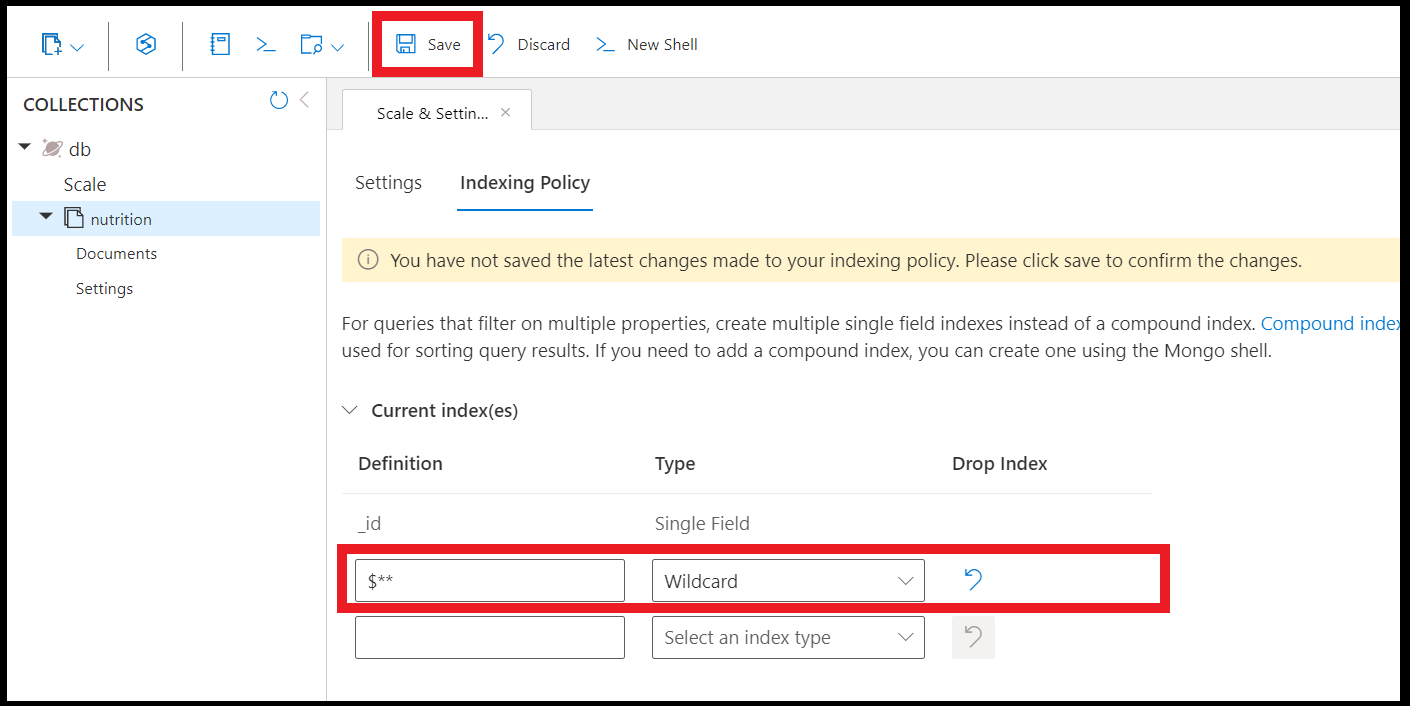
Poznámka:
Pokud právě začínáte s vývojem, důrazně doporučujeme začít se zástupným znakem u všech polí. To může zjednodušit vývoj a usnadnit optimalizaci dotazů.
Dokumenty s mnoha poli můžou mít vysoké poplatky za jednotku žádosti (RU) za zápisy a aktualizace. Pokud tedy máte úlohu s velkým počtem zápisů, měli byste se rozhodnout pro jednotlivé cesty indexování, a ne k použití indexů se zástupnými cardy.
Poznámka:
Podpora jedinečného indexu existujících kolekcí s daty je dostupná ve verzi Preview. Tuto funkci můžete pro svůj databázový účet povolit povolením funkce EnableUniqueIndexReIndex.
Omezení
Indexy se zástupnými čáry nepodporují žádný z následujících typů nebo vlastností indexu:
- Složená
- TTL
- Jedinečný
Na rozdíl od MongoDB nemůžete ve službě Azure Cosmos DB pro MongoDB používat indexy se zástupnými znaky pro:
Vytvořit index se zástupnými znaky, který zahrnuje několik konkrétních polí
db.coll.createIndex( { "$**" : 1 }, { "wildcardProjection " : { "children.givenName" : 1, "children.grade" : 1 } } )Vytvořit index se zástupnými znaky, který vylučuje několik konkrétních polí
db.coll.createIndex( { "$**" : 1 }, { "wildcardProjection" : { "children.givenName" : 0, "children.grade" : 0 } } )
Jako alternativu můžete vytvořit několik indexů se zástupnými znaky.
Vlastnosti indexu
Následující operace jsou běžné pro účty obsluhující protokol wire protocol verze 4.0 a účty obsluhující starší verze. Další informace o podporovaných indexech a indexovaných vlastnostech.
Jedinečné indexy
Jedinečné indexy jsou užitečné pro vynucení, že dva nebo více dokumentů neobsahuje stejnou hodnotu pro indexovaná pole.
Následující příkaz vytvoří jedinečný index pole student_id:
globaldb:PRIMARY> db.coll.createIndex( { "student_id" : 1 }, {unique:true} )
{
"_t" : "CreateIndexesResponse",
"ok" : 1,
"createdCollectionAutomatically" : false,
"numIndexesBefore" : 1,
"numIndexesAfter" : 4
}
V případě horizontálně dělených kolekcí musíte zadat klíč horizontálního oddílu (oddílu) pro vytvoření jedinečného indexu. Jinými slovy, všechny jedinečné indexy v horizontálně dělené kolekci jsou složené indexy, kde jedním z polí je klíč horizontálního dělení. Prvním polem v pořadí by měl být klíč horizontálního dělení.
Následující příkazy vytvoří horizontálně dělenou kolekci coll (klíč horizontálního oddílu je university) s jedinečným indexem polí student_id a university:
globaldb:PRIMARY> db.runCommand({shardCollection: db.coll._fullName, key: { university: "hashed"}});
{
"_t" : "ShardCollectionResponse",
"ok" : 1,
"collectionsharded" : "test.coll"
}
globaldb:PRIMARY> db.coll.createIndex( { "university" : 1, "student_id" : 1 }, {unique:true});
{
"_t" : "CreateIndexesResponse",
"ok" : 1,
"createdCollectionAutomatically" : false,
"numIndexesBefore" : 3,
"numIndexesAfter" : 4
}
V předchozím příkladu vynechání "university":1 klauzule vrátí chybu s následující zprávou:
cannot create unique index over {student_id : 1.0} with shard key pattern { university : 1.0 }
Omezení
Jedinečné indexy je potřeba vytvořit, když je kolekce prázdná.
Jedinečné indexy v vnořených polí nejsou ve výchozím nastavení podporovány kvůli omezením polí. Pokud vnořené pole neobsahuje matici, index bude fungovat podle očekávání. Pokud vaše vnořené pole obsahuje pole (kdekoli na cestě), bude tato hodnota ignorována v jedinečném indexu a jedinečnost se pro tuto hodnotu nezachová.
Například jedinečný index pro people.tom.age bude v tomto případě fungovat, protože v cestě není žádné pole:
{ "people": { "tom": { "age": "25" }, "mark": { "age": "30" } } }
ale v tomto případě nebude fungovat, protože v cestě je pole:
{ "people": { "tom": [ { "age": "25" } ], "mark": [ { "age": "30" } ] } }
Tuto funkci můžete pro svůj databázový účet povolit povolením funkce EnableUniqueCompoundNestedDocs.
Indexy TTL
Pokud chcete povolit vypršení platnosti dokumentu v konkrétní kolekci, musíte vytvořit index TTL (Time to Live). Index TTL je index pole _ts s expireAfterSeconds hodnotou.
Příklad:
globaldb:PRIMARY> db.coll.createIndex({"_ts":1}, {expireAfterSeconds: 10})
Předchozí příkaz odstraní všechny dokumenty v db.coll kolekci, které nebyly změněny za posledních 10 sekund.
Poznámka:
Pole _ts je specifické pro službu Azure Cosmos DB a není přístupné z klientů MongoDB. Jedná se o rezervovanou (systémovou) vlastnost, která obsahuje časové razítko poslední úpravy dokumentu.
Sledování průběhu indexu
Verze 3.6 nebo novější služby Azure Cosmos DB pro MongoDB podporuje currentOp() příkaz ke sledování průběhu indexu v instanci databáze. Tento příkaz vrátí dokument, který obsahuje informace o probíhajících operacích v instanci databáze. Pomocí currentOp příkazu můžete sledovat všechny probíhající operace v nativní databázi MongoDB. Ve službě Azure Cosmos DB pro MongoDB tento příkaz podporuje pouze sledování operace indexu.
Tady je několik příkladů, které ukazují, jak pomocí příkazu sledovat průběh indexu currentOp :
Získejte průběh indexu pro kolekci:
db.currentOp({"command.createIndexes": <collectionName>, "command.$db": <databaseName>})Získejte průběh indexu pro všechny kolekce v databázi:
db.currentOp({"command.$db": <databaseName>})Získejte průběh indexu pro všechny databáze a kolekce v účtu služby Azure Cosmos DB:
db.currentOp({"command.createIndexes": { $exists : true } })
Příklady výstupu průběhu indexu
Podrobnosti o průběhu indexu zobrazují procento průběhu aktuální operace indexu. Tady je příklad, který ukazuje formát výstupního dokumentu pro různé fáze průběhu indexu:
Operace indexu v kolekci "foo" a "bar" databáze, která je dokončena 60 procent, bude mít následující výstupní dokument. Pole
Inprog[0].progress.totalzobrazuje 100 jako procento dokončení cíle.{ "inprog" : [ { ………………... "command" : { "createIndexes" : foo "indexes" :[ ], "$db" : bar }, "msg" : "Index Build (background) Index Build (background): 60 %", "progress" : { "done" : 60, "total" : 100 }, …………..….. } ], "ok" : 1 }Pokud se operace indexu právě spustila v kolekci "foo" a "pruhové" databázi, může výstupní dokument zobrazit 0 % průběhu, dokud nedosáhne měřitelné úrovně.
{ "inprog" : [ { ………………... "command" : { "createIndexes" : foo "indexes" :[ ], "$db" : bar }, "msg" : "Index Build (background) Index Build (background): 0 %", "progress" : { "done" : 0, "total" : 100 }, …………..….. } ], "ok" : 1 }Po dokončení probíhající operace indexu se ve výstupním dokumentu zobrazí prázdné
inprogoperace.{ "inprog" : [], "ok" : 1 }
Aktualizace indexu na pozadí
Bez ohledu na hodnotu zadanou pro vlastnost Index pozadí se aktualizace indexu vždy provádějí na pozadí. Vzhledem k tomu, že aktualizace indexu spotřebovávají jednotky žádostí (RU) s nižší prioritou než jiné databázové operace, změny indexu nebudou mít za následek žádné výpadky pro zápisy, aktualizace nebo odstranění.
Při přidávání nového indexu to nemá žádný vliv na dostupnost čtení. Po dokončení transformace indexu budou dotazy využívat pouze nové indexy. Během transformace indexu bude dotazovací modul dál používat existující indexy, takže během transformace indexování budete sledovat podobný výkon čtení, který jste zaznamenali před zahájením změny indexování. Při přidávání nových indexů také neexistuje riziko neúplných nebo nekonzistentních výsledků dotazu.
Při odebírání indexů a okamžitého spouštění dotazů, které mají filtry na vyřazených indexech, můžou být výsledky nekonzistentní a neúplné, dokud se transformace indexu nedokončí. Pokud odeberete indexy, dotazovací modul neposkytuje konzistentní nebo úplné výsledky, když dotazy filtrují tyto nově odebrané indexy. Většina vývojářů indexy neodstraní a pak se je okamžitě pokusí dotazovat, takže v praxi je tato situace nepravděpodobné.
Poznámka:
Průběh indexu můžete sledovat.
Příkaz ReIndex
Příkaz reIndex znovu vytvoří všechny indexy v kolekci. V některých výjimečných případech může být spuštěním reIndex příkazu vyřešen výkon dotazů nebo jiných problémů s indexem v kolekci. Pokud máte problémy s indexováním, doporučujeme znovu vytvořit indexy pomocí reIndex příkazu.
Příkaz můžete spustit reIndex pomocí následující syntaxe:
db.runCommand({ reIndex: <collection> })
Pomocí následující syntaxe můžete zkontrolovat, jestli spuštění příkazu reIndex zlepší výkon dotazů ve vaší kolekci:
db.runCommand({"customAction":"GetCollection",collection:<collection>, showIndexes:true})
Ukázkový výstup:
{
"database" : "myDB",
"collection" : "myCollection",
"provisionedThroughput" : 400,
"indexes" : [
{
"v" : 1,
"key" : {
"_id" : 1
},
"name" : "_id_",
"ns" : "myDB.myCollection",
"requiresReIndex" : true
},
{
"v" : 1,
"key" : {
"b.$**" : 1
},
"name" : "b.$**_1",
"ns" : "myDB.myCollection",
"requiresReIndex" : true
}
],
"ok" : 1
}
Pokud reIndex se zvýší výkon dotazů, bude argument requiresReIndex pravdivý. Pokud reIndex výkon dotazů nezlepšíte, tato vlastnost se vynechá.
Migrace kolekcí s využitím indexů
V současné době můžete vytvořit jedinečné indexy pouze v případě, že kolekce neobsahuje žádné dokumenty. Oblíbené nástroje pro migraci MongoDB se po importu dat pokusí vytvořit jedinečné indexy. Pokud chcete tento problém obejít, můžete místo povolení nástroje pro migraci ručně vytvořit odpovídající kolekce a jedinečné indexy. (Toto chování mongorestore můžete dosáhnout pomocí příznaku --noIndexRestore v příkazovém řádku.)
Indexování pro MongoDB verze 3.2
Dostupné funkce indexování a výchozí hodnoty se liší pro účty Služby Azure Cosmos DB, které jsou kompatibilní s verzí 3.2 přenosového protokolu MongoDB. Můžete zkontrolovat verzi účtu a upgradovat na verzi 3.6.
Pokud používáte verzi 3.2, tato část popisuje klíčové rozdíly ve verzích 3.6 nebo novější.
Vrácení výchozích indexů (verze 3.2)
Na rozdíl od verze 3.6 nebo novější služby Azure Cosmos DB pro MongoDB verze 3.2 indexuje všechny vlastnosti ve výchozím nastavení. Pomocí následujícího příkazu můžete tyto výchozí indexy pro kolekci (coll):
> db.coll.dropIndexes()
{ "_t" : "DropIndexesResponse", "ok" : 1, "nIndexesWas" : 3 }
Po vyřazení výchozích indexů můžete přidat další indexy stejně jako ve verzi 3.6 nebo novější.
Složené indexy (verze 3.2)
Složené indexy obsahují odkazy na více polí dokumentu. Pokud chcete vytvořit složený index, upgradujte na verzi 3.6 nebo 4.0.
Indexy se zástupnými znaky (verze 3.2)
Pokud chcete vytvořit zástupný index, upgradujte na verzi 4.0 nebo 3.6.
Další kroky
- Indexování ve službě Azure Cosmos DB
- Vypršení platnosti dat ve službě Azure Cosmos DB automaticky s časem do provozu
- Další informace o vztahu mezi dělením a indexováním najdete v článku o dotazování kontejneru Azure Cosmos DB.
- Pokoušíte se naplánovat kapacitu migrace do služby Azure Cosmos DB? Informace o stávajícím databázovém clusteru můžete použít k plánování kapacity.
- Pokud víte, že je počet virtuálních jader a serverů ve vašem existujícím databázovém clusteru, přečtěte si informace o odhadu jednotek žádostí pomocí virtuálních jader nebo virtuálních procesorů.
- Pokud znáte typické sazby požadavků pro vaši aktuální úlohu databáze, přečtěte si informace o odhadu jednotek žádostí pomocí plánovače kapacity služby Azure Cosmos DB.