Monitorování normalizovaných RU/s pro kontejner služby Azure Cosmos DB nebo účet
PLATÍ PRO: ![]() NoSQL
NoSQL ![]() MongoDB
MongoDB ![]() Cassandra
Cassandra ![]() Skřítek
Skřítek ![]() Stůl
Stůl
Azure Monitor pro Azure Cosmos DB poskytuje zobrazení metrik pro monitorování vašeho účtu a vytváření řídicích panelů. Metriky služby Azure Cosmos DB se ve výchozím nastavení shromažďují. Tato funkce nevyžaduje, abyste explicitně povolili ani nenakonfigurovali nic.
Definice metriky
Metrika Normalizovaná spotřeba RU je metrika mezi 0 až 100 %, která slouží k měření využití zřízené propustnosti v databázi nebo kontejneru. Metrika se vygeneruje v 1minutových intervalech a definuje se jako maximální využití RU/s napříč všemi rozsahy klíčů oddílů v časovém intervalu. Každý rozsah klíčů oddílu se mapuje na jeden fyzický oddíl a je přiřazen k uchovávání dat pro rozsah možných hodnot hash. Obecně platí, že čím vyšší je procento normalizované spotřeby RU, tím více jste využili zřízenou propustnost. Metriku lze také použít k zobrazení využití jednotlivých rozsahů klíčů oddílů v databázi nebo kontejneru.
Předpokládejme například, že máte kontejner, ve kterém nastavíte maximální propustnost automatického škálování 20 000 RU/s (škáluje se mezi 2000 až 20 000 RU/s) a máte dva rozsahy klíčů oddílů (fyzické oddíly) P1 a P2. Vzhledem k tomu, že Azure Cosmos DB distribuuje zřízenou propustnost rovnoměrně napříč všemi rozsahy klíčů oddílů, může se škálovat P1 a P2 mezi 1000 až 10 000 RU/s. Předpokládejme, že za 1 minutu spotřeboval P1 6000 jednotek žádosti a P2 spotřeboval 8 000 jednotek žádosti. Normalizovaná spotřeba RU P1 je 60 % a 80 % pro P2. Celková normalizovaná spotřeba RU celého kontejneru je MAX(60 %, 80 %) = 80 %.
Pokud vás zajímá, jak se spotřeba jednotek žádosti zobrazuje v intervalu za sekundu spolu s typem operace, můžete použít diagnostické protokoly funkce opt-in a dotazovat se na tabulku PartitionKeyRUConsumption. K získání základního přehledu operací a stavového kódu, který vaše aplikace provádí s prostředkem služby Azure Cosmos DB, můžete použít integrovanou metriku požadavků Azure Monitor Total Requests (API for NoSQL), Mongo Requests, Gremlin Requests nebo Cassandra Requests . Později můžete tyto požadavky filtrovat podle stavového kódu 429 a rozdělit je podle typu operace.
Co očekávat a dělat, když je normalizované RU/s vyšší
Když normalizovaná spotřeba RU dosáhne 100 % pro daný rozsah klíčů oddílu a pokud klient stále odesílá požadavky v daném časovém intervalu 1 sekundy do konkrétního rozsahu klíčů oddílu – obdrží chybu s omezenou rychlostí (429).
To nemusí nutně znamenat problém s vaším prostředkem. Klientské sady SDK služby Azure Cosmos DB a nástroje pro import dat, jako je Azure Data Factory a knihovna bulk Executor, ve výchozím nastavení automaticky opakují požadavky na 429. Obvykle se opakují až 9krát. V důsledku toho se v metrikách může zobrazit 429, ale tyto chyby se nemusí vrátit ani do vaší aplikace.
U produkčních úloh obecně platí, že pokud dochází k chybám 429 u 1 až 5 % požadavků a celková latence je přijatelná, značí to plné využití RU/s. V tomto případě normalizovaná metrika spotřeby RU dosahuje 100 % pouze to, že v dané sekundě použil alespoň jeden rozsah klíčů oddílu veškerou zřízenou propustnost. To je přijatelné, protože celková míra chyb 429 je stále nízká. Nevyžaduje se žádná další akce.
Pokud chcete zjistit, jaké procento požadavků na vaši databázi nebo kontejner způsobilo 429, přejděte v okně účtu služby Azure Cosmos DB na přehledy>žádostí o celkový počet žádostí>podle stavového kódu. Vyfiltrujte konkrétní databázi a kontejner. Pro rozhraní API pro Gremlin použijte metriku Požadavků Gremlin.
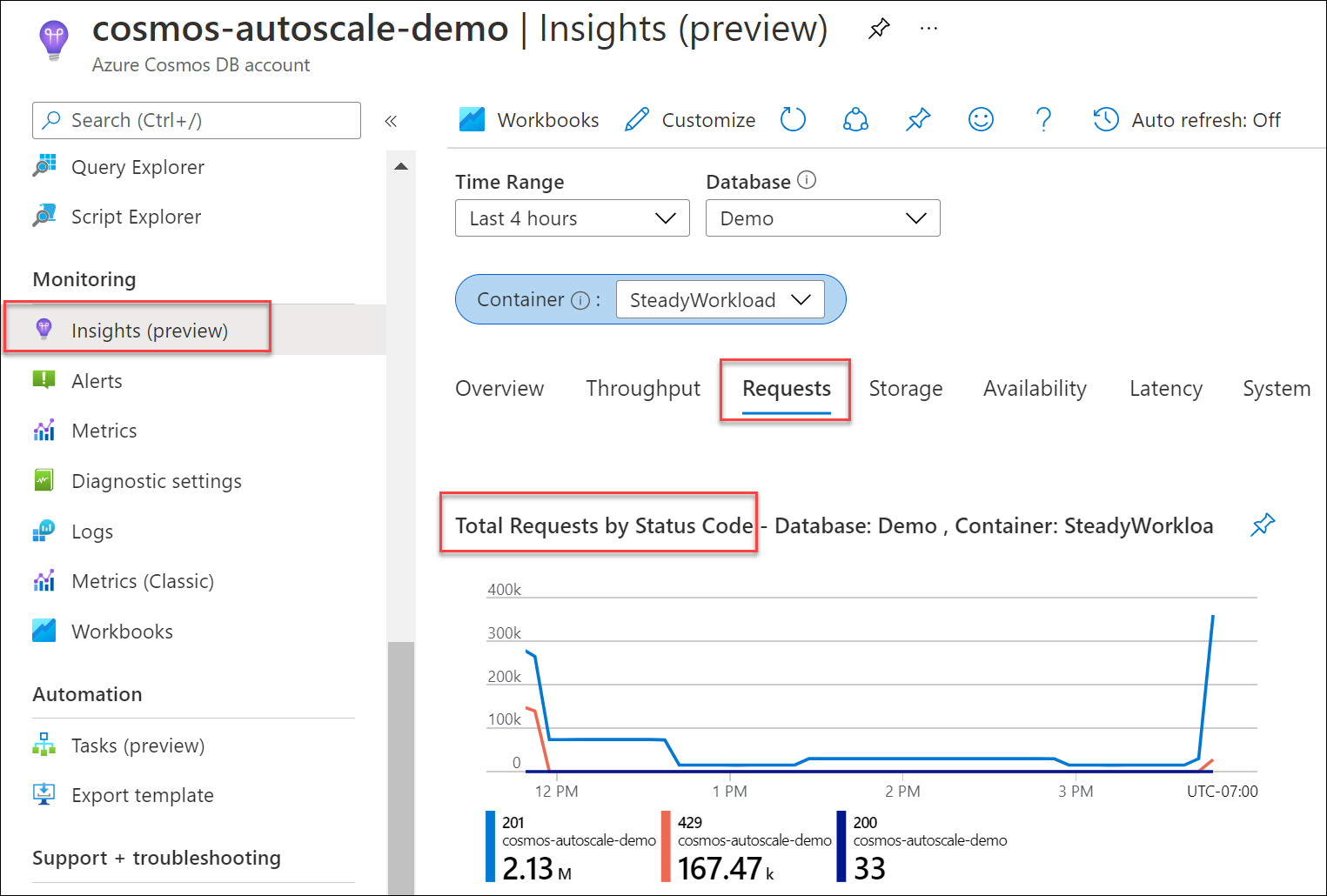
Pokud je normalizovaná metrika spotřeby RU konzistentně 100 % napříč několika rozsahy klíčů oddílů a míra 429s je větší než 5 %, doporučuje se zvýšit propustnost. Pomocí metrik služby Azure Monitor a diagnostických protokolů služby Azure Monitor můžete zjistit, které operace jsou náročné a jaké je jejich využití ve špičce. Postupujte podle článku Osvědčené postupy pro škálování zřízené propustnosti (RU/s)
Není to vždy případ, kdy se zobrazí chyba omezování rychlosti 429, jen proto, že normalizovaná RU dosáhla 100 %. Je to proto, že normalizovaná RU je jedna hodnota, která představuje maximální využití pro všechny rozsahy klíčů oddílů. Jeden rozsah klíčů oddílu může být zaneprázdněný, ale ostatní rozsahy klíčů oddílů můžou obsluhovat požadavky bez problémů. Například jedna operace, jako je uložená procedura, která spotřebovává všechny RU/s v rozsahu klíčů oddílu, povede ke krátkému nárůstu metriky normalizované spotřeby RU. V takových případech nedojde k žádným chybám s okamžitým omezením rychlosti, pokud je celková frekvence požadavků nízká nebo se požadavky provádějí v jiných oddílech v různých rozsazích klíčů oddílů.
Přečtěte si další informace o interpretaci a ladění chyb omezování rychlosti 429.
Monitorování horkých oddílů
Normalizovaná metrika spotřeby RU se dá použít k monitorování, jestli má vaše úloha horký oddíl. Horký oddíl vznikne, když jeden nebo několik logických klíčů oddílu spotřebovává nepřiměřenou částku celkového počtu RU/s z důvodu vyššího objemu požadavků. Příčinou může být návrh klíče oddílu, který nedistribuuje žádosti rovnoměrně. Výsledkem je, že mnoho požadavků je směrováno na malou podmnožinu logických oddílů (což znamená rozsahy klíčů oddílů), které se stanou "horkými". Vzhledem k tomu, že všechna data logického oddílu se nacházejí v jednom rozsahu klíčů oddílu a celkový počet RU/s je rovnoměrně rozdělený mezi všechny rozsahy klíčů oddílů, může horký oddíl vést k 429s a neefektivnímu využití propustnosti.
Jak zjistit, jestli existuje horký oddíl
Pokud chcete ověřit, jestli existuje horký oddíl, přejděte do části Insights>Throughput>Normalized RU Consumption (%) Podle PartitionKeyRangeID. Vyfiltrujte konkrétní databázi a kontejner.
Každý PartitionKeyRangeId se mapuje na jeden fyzický oddíl. Pokud existuje jeden PartitionKeyRangeId, který má výrazně vyšší normalizovanou spotřebu RU než ostatní (například jedna je konzistentně na 100 %, ale ostatní jsou na 30 % nebo méně), může to být znaménko horkého oddílu.
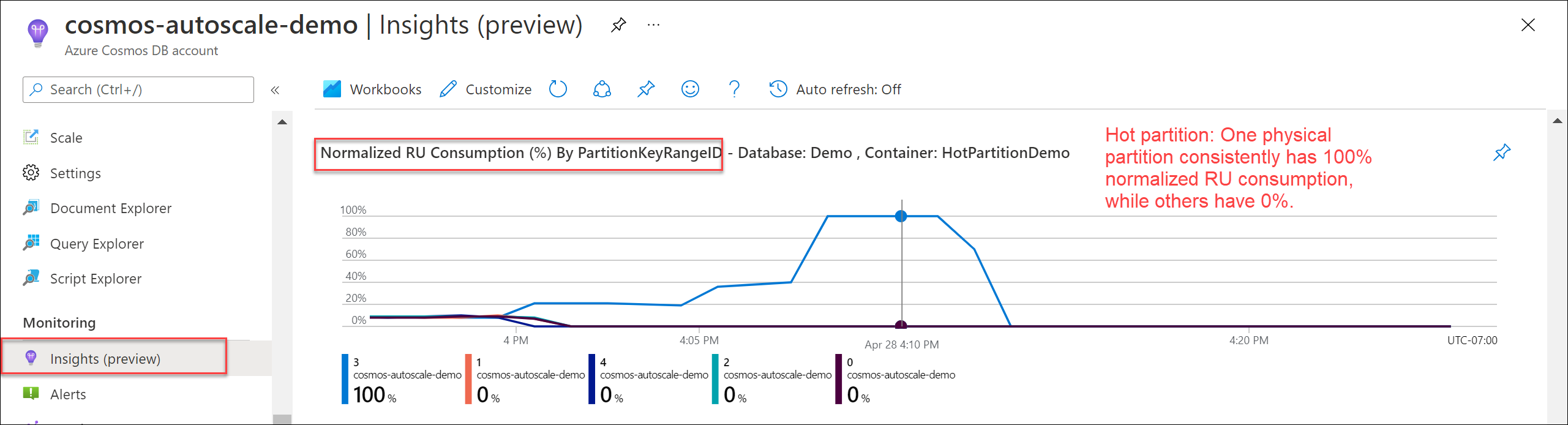
Informace o logických oddílech, které využívají nejvíce RU/s, a doporučených řešení najdete v článku Diagnostika a řešení potíží s příliš velkými výjimkami požadavků služby Azure Cosmos DB (429).
Normalizovaná spotřeba RU a automatické škálování
Normalizovaná metrika spotřeby RU se zobrazí jako 100 %, pokud alespoň 1 rozsah klíčů oddílu používá všechny přidělené RU/s v libovolné sekundě v časovém intervalu. Jednou z běžných otázek, proč je normalizovaná spotřeba RU na 100 %, ale Azure Cosmos DB neškáli škálovat RU/s na maximální propustnost s automatickým škálováním?
Poznámka:
Následující informace popisují aktuální implementaci automatického škálování a můžou se v budoucnu změnit.
Když používáte automatické škálování, Azure Cosmos DB škáluje ru/s pouze na maximální propustnost, pokud je normalizovaná spotřeba RU 100 % pro trvalou nepřetržitou dobu v 5sekundovém intervalu. Tím se zajistí, že logika škálování je pro uživatele nákladově přívětivá, protože zajišťuje, že jednorázové špičky v momentální špičce nevedou k zbytečným škálováním a vyšším nákladům. Pokud dojde k momentální špičce, systém obvykle vertikálně navyšuje kapacitu na vyšší hodnotu, než byla dříve škálovaná na RU/s, ale nižší než maximální počet RU/s.
Předpokládejme například, že máte kontejner s maximální propustností automatického škálování 20 000 RU/s (škáluje se mezi 2000 až 20 000 RU/s) a 2 rozsahy klíčů oddílů. Každý rozsah klíčů oddílu se může škálovat mezi 1 000 až 10 000 RU/s. Vzhledem k tomu, že automatické škálování zřizuje všechny požadované prostředky předem, můžete kdykoli použít až 20 000 RU/s. Řekněme, že máte občasnou špičku provozu, kdy za jednu sekundu je využití jednoho z rozsahů klíčů oddílů 10 000 RU/s. V dalších sekundách se využití vrátí zpět na 1 000 RU/s. Vzhledem k tomu, že metrika normalizované spotřeby RU zobrazuje nejvyšší využití v časovém období napříč všemi oddíly, zobrazí se 100 %. Vzhledem k tomu, že využití bylo pouze 100 % po dobu 1 sekundy, automatické škálování se automaticky nes škáluje na maximum.
V důsledku toho, i když automatické škálování neškáli na maximum, stále jste mohli použít celkový počet DOSTUPNÝCH RU/s. Pokud chcete ověřit spotřebu RU/s, můžete použít diagnostické protokoly funkce opt-in k dotazování na celkovou spotřebu RU/s na úrovni za sekundu napříč všemi rozsahy klíčů oddílů.
CDBPartitionKeyRUConsumption
| where TimeGenerated >= (todatetime('2022-01-28T20:35:00Z')) and TimeGenerated <= todatetime('2022-01-28T20:40:00Z')
| where DatabaseName == "MyDatabase" and CollectionName == "MyContainer"
| summarize sum(RequestCharge) by bin(TimeGenerated, 1sec), PartitionKeyRangeId
| render timechart
Obecně platí, že pokud u produkční úlohy s využitím automatického škálování dochází mezi 1–5 % požadavků s 429s a celková latence je přijatelná, je to signál, že ru/s jsou plně využité. I když normalizovaná spotřeba RU občas dosáhne 100 % a automatické škálování se neškálí na maximální počet RU/s, je to v pořádku, protože celková míra 429s je nízká. Není vyžadována žádná akce.
Tip
Pokud používáte automatické škálování a zjistíte, že normalizovaná spotřeba RU je konzistentně 100 % a konzistentně se škáluje na maximální počet RU/s, je to znamení, že použití ruční propustnosti může být nákladově efektivnější. Pokud chcete zjistit, jestli je pro vaši úlohu nejvhodnější automatické škálování nebo ruční propustnost, podívejte se, jak si vybrat mezi standardní (ruční) a zřízenou propustností automatického škálování. Azure Cosmos DB také odesílá doporučení Azure Advisoru na základě vzorů úloh, které doporučují propustnost ručního nebo automatického škálování.
Zobrazení metriky normalizované spotřeby jednotek žádosti
Přihlaste se k portálu Azure.
V levém navigačním panelu vyberte Monitorování a vyberte Metriky.
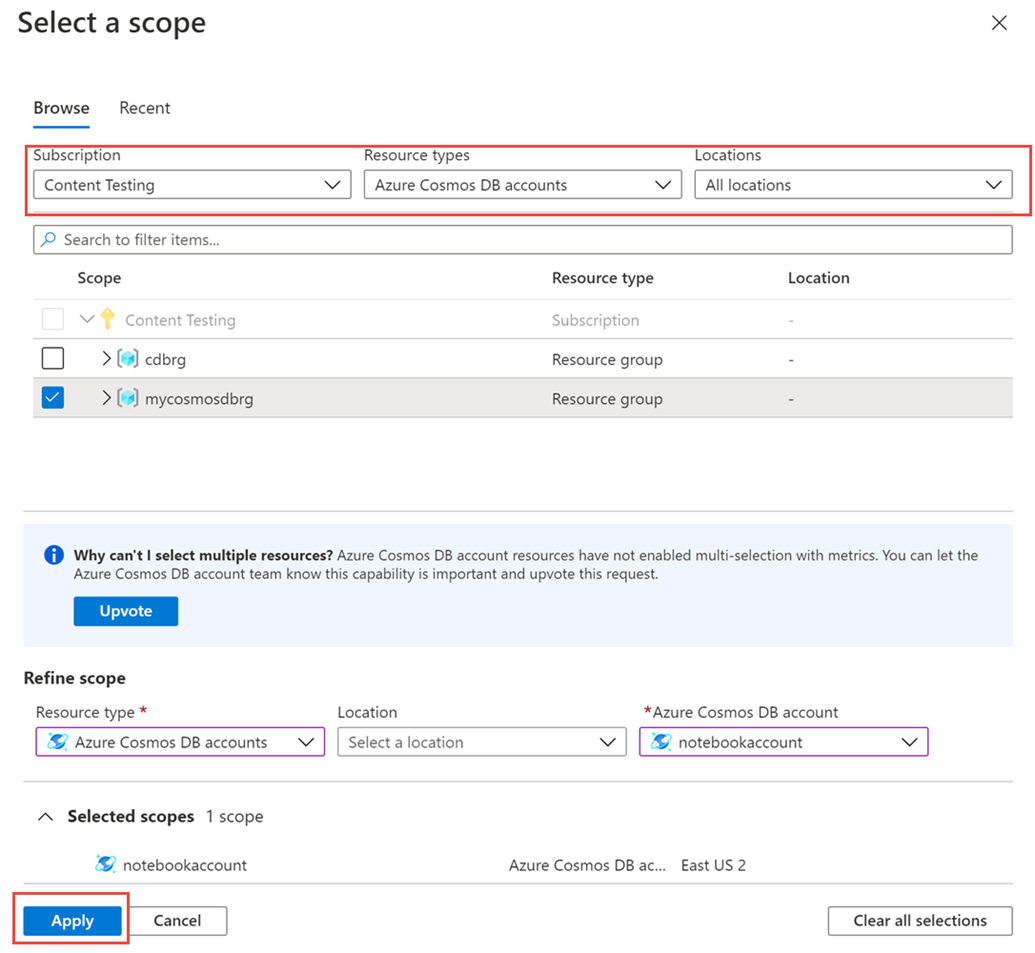
V podokně >Metriky Vyberte prostředek> zvolte požadované předplatné a skupinu prostředků. Jako typ prostředku vyberte účty Služby Azure Cosmos DB, zvolte jeden z existujících účtů služby Azure Cosmos DB a vyberte Použít.
Dále můžete vybrat metriku ze seznamu dostupných metrik. Můžete vybrat metriky specifické pro jednotky žádostí, úložiště, latenci, dostupnost, Cassandra a další. Podrobné informace o všech dostupných metrikách v tomto seznamu najdete v článku Metriky podle kategorií . V tomto příkladu vybereme metriku Normalizovaná spotřeba RU a jako hodnotu agregace max .
Kromě těchto podrobností můžete také vybrat časový rozsah a časové intervaly metrik. Maximálně můžete zobrazit metriky za posledních 30 dnů. Po použití filtru se na základě filtru zobrazí graf.
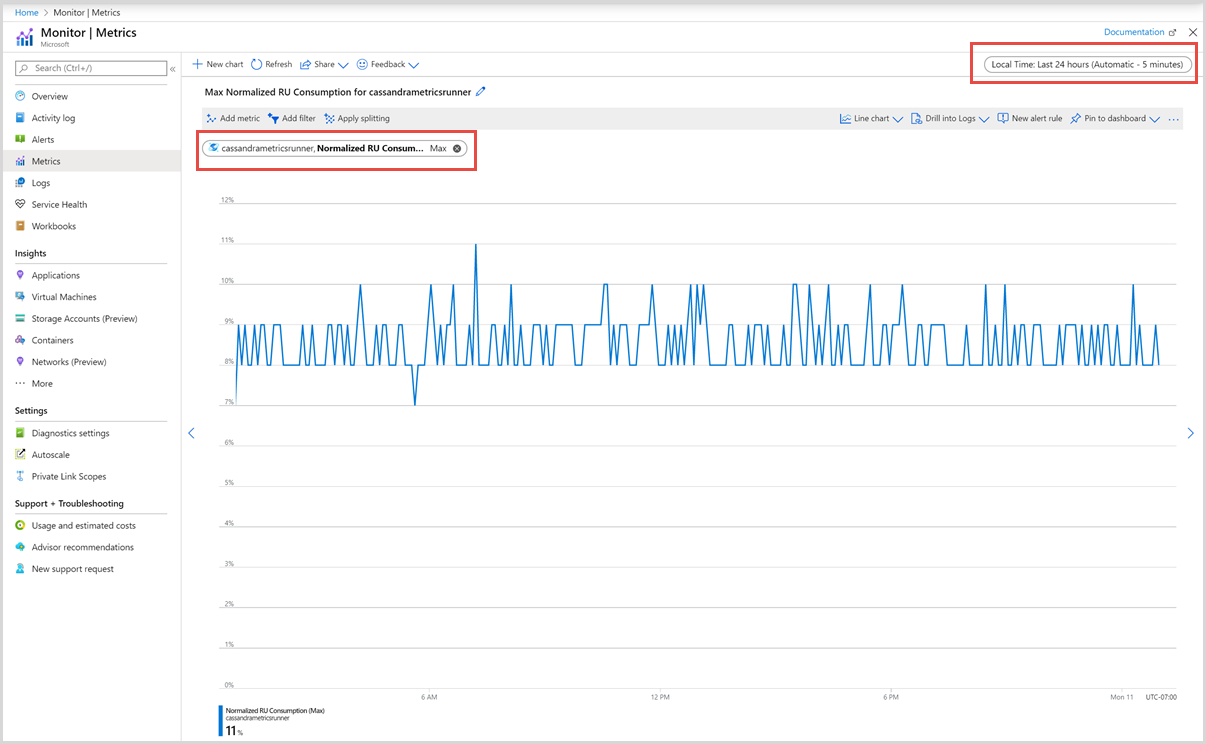
Filtry pro normalizovanou metriku spotřeby RU
Metriky a graf zobrazený také můžete filtrovat podle konkrétního názvu kolekce, DatabaseName, PartitionKeyRangeID a oblasti. Pokud chcete metriky filtrovat, vyberte Přidat filtr a zvolte požadovanou vlastnost, například CollectionName a odpovídající hodnotu, kterou vás zajímají. Graf pak zobrazí normalizovanou metriku spotřeby RU pro kontejner pro vybrané období.
Metriky můžete seskupit pomocí možnosti Použít rozdělení . U databází se sdílenou propustností se v normalizované metrice RU zobrazují data pouze v členitosti databáze, ale nezobrazují se žádná data na kolekci. U databáze se sdílenou propustností se proto při použití rozdělení podle názvu kolekce nezobrazí žádná data.
Normalizovaná metrika spotřeby jednotek žádosti pro každý kontejner se zobrazí, jak je znázorněno na následujícím obrázku:

Další kroky
- Monitorování dat azure Cosmos DB pomocí nastavení diagnostiky v Azure
- Audit operací řídicí roviny služby Azure Cosmos DB
- Diagnostika a řešení potíží s výjimkami kvůli příliš vysoké frekvenci požadavků (429) ve službě Azure Cosmos DB