Kurz: Návrh řídicího panelu analýzy v reálném čase pomocí služby Azure Cosmos DB for PostgreSQL
PLATÍ PRO: ![]() Azure Cosmos DB for PostgreSQL (využívající rozšíření databáze Citus do PostgreSQL)
Azure Cosmos DB for PostgreSQL (využívající rozšíření databáze Citus do PostgreSQL)
V tomto kurzu se pomocí služby Azure Cosmos DB for PostgreSQL naučíte:
- Vytvoření clusteru
- Vytvoření schématu pomocí nástroje psql
- Tabulky horizontálních oddílů napříč uzly
- Generování ukázkových dat
- Provádění souhrnů
- Dotazování nezpracovaných a agregovaných dat
- Vypršení platnosti dat
Požadavky
Pokud ještě nemáte předplatné Azure, vytvořte si napřed bezplatný účet.
Vytvoření clusteru
Přihlaste se k webu Azure Portal a následujícím postupem vytvořte cluster Azure Cosmos DB for PostgreSQL:
Na webu Azure Portal přejděte do části Vytvoření clusteru Azure Cosmos DB for PostgreSQL.
Ve formuláři Vytvoření clusteru Azure Cosmos DB for PostgreSQL:
Vyplňte požadované informace na kartě Základní informace.
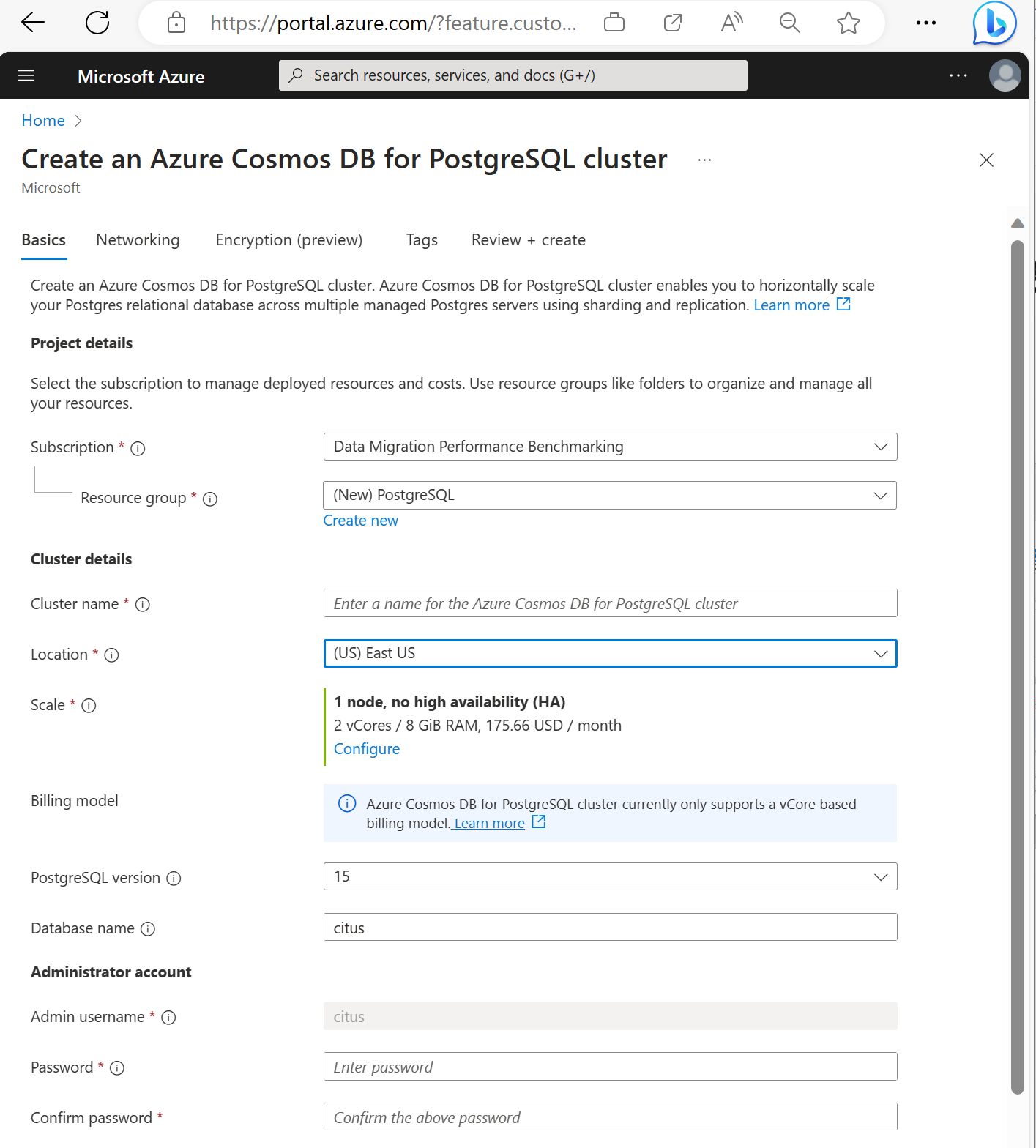
Většina možností je intuitivní, mějte však na paměti následující skutečnosti:
- Název clusteru určuje název DNS, který vaše aplikace používají pro připojení, ve formuláři
<node-qualifier>-<clustername>.<uniqueID>.postgres.cosmos.azure.com. - Můžete zvolit hlavní verzi PostgreSQL, například 15. Azure Cosmos DB for PostgreSQL vždy podporuje nejnovější verzi Citus pro vybranou hlavní verzi Postgres.
- Uživatelské jméno správce musí mít hodnotu
citus. - Název databáze můžete nechat na výchozí hodnotě citus nebo definovat jediný název databáze. Po zřízení clusteru není možné přejmenovat databázi.
- Název clusteru určuje název DNS, který vaše aplikace používají pro připojení, ve formuláři
Vyberte Další: Sítě v dolní části obrazovky.
Na obrazovce Sítě vyberte Povolit veřejný přístup ze služeb a prostředků Azure v rámci Azure k tomuto clusteru.
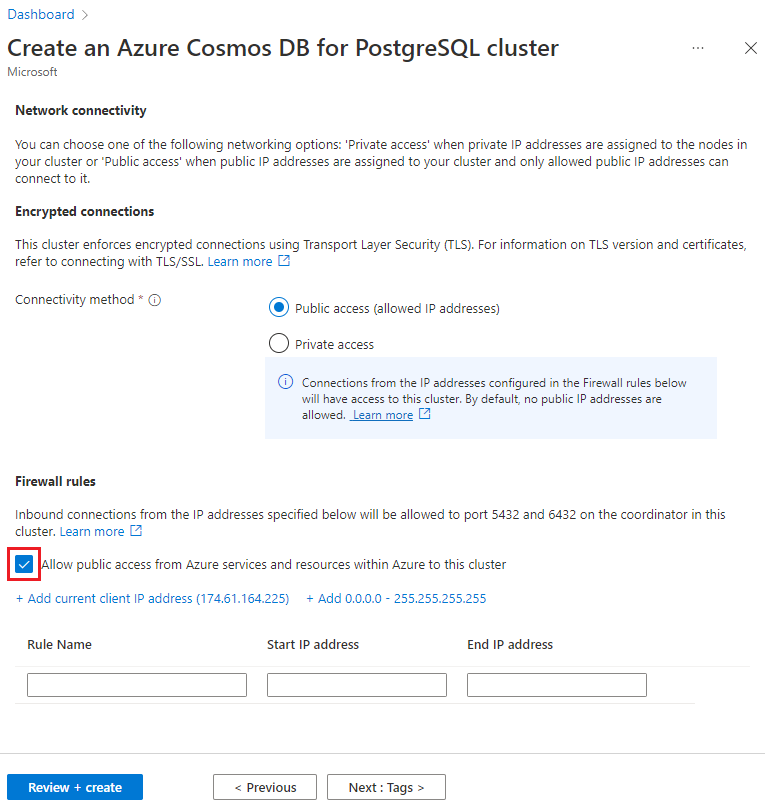
Vyberte Zkontrolovat a vytvořit a po ověření výběrem možnosti Vytvořit cluster vytvořte.
Zřizování trvá několik minut. Stránka se přesměruje na monitorování nasazení. Jakmile se stav změní z Nasazení probíhá na Nasazení se dokončilo, vyberte Přejít k prostředku.
Vytvoření schématu pomocí nástroje psql
Po připojení ke službě Azure Cosmos DB for PostgreSQL pomocí psql můžete provést některé základní úlohy. Tento kurz vás provede ingestováním ingestování provozních dat z webové analýzy a následným uvedením dat do poskytování řídicích panelů v reálném čase na základě těchto dat.
Pojďme vytvořit tabulku, která bude využívat všechna naše nezpracovaná data webového provozu. V terminálu psql spusťte následující příkazy:
CREATE TABLE http_request (
site_id INT,
ingest_time TIMESTAMPTZ DEFAULT now(),
url TEXT,
request_country TEXT,
ip_address TEXT,
status_code INT,
response_time_msec INT
);
Vytvoříme také tabulku, která bude obsahovat agregace za minutu, a tabulku, která udržuje pozici poslední kumulativní aktualizace. V psql spusťte také následující příkazy:
CREATE TABLE http_request_1min (
site_id INT,
ingest_time TIMESTAMPTZ, -- which minute this row represents
error_count INT,
success_count INT,
request_count INT,
average_response_time_msec INT,
CHECK (request_count = error_count + success_count),
CHECK (ingest_time = date_trunc('minute', ingest_time))
);
CREATE INDEX http_request_1min_idx ON http_request_1min (site_id, ingest_time);
CREATE TABLE latest_rollup (
minute timestamptz PRIMARY KEY,
CHECK (minute = date_trunc('minute', minute))
);
Nově vytvořené tabulky teď můžete zobrazit v seznamu tabulek pomocí tohoto příkazu psql:
\dt
Tabulky horizontálních oddílů napříč uzly
Nasazení služby Azure Cosmos DB for PostgreSQL ukládá řádky tabulky na různých uzlech na základě hodnoty sloupce určeného uživatelem. Tento "distribuční sloupec" označuje způsob horizontálního dělení dat mezi uzly.
Pojďme nastavit distribuční sloupec tak, aby byl site_id, klíč horizontálního oddílu. V psql spusťte tyto funkce:
SELECT create_distributed_table('http_request', 'site_id');
SELECT create_distributed_table('http_request_1min', 'site_id');
Důležité
Distribuce tabulek nebo použití horizontálního dělení založeného na schématu je nezbytná k využití funkcí výkonu služby Azure Cosmos DB for PostgreSQL. Pokud tabulky nebo schémata nedistribuujete, pracovní uzly nemůžou pomoct spouštět dotazy týkající se jejich dat.
Generování ukázkových dat
Náš cluster by teď měl být připravený k ingestování některých dat. Následující příkaz můžeme spustit místně z našeho psql připojení a průběžně vkládat data.
DO $$
BEGIN LOOP
INSERT INTO http_request (
site_id, ingest_time, url, request_country,
ip_address, status_code, response_time_msec
) VALUES (
trunc(random()*32), clock_timestamp(),
concat('http://example.com/', md5(random()::text)),
('{China,India,USA,Indonesia}'::text[])[ceil(random()*4)],
concat(
trunc(random()*250 + 2), '.',
trunc(random()*250 + 2), '.',
trunc(random()*250 + 2), '.',
trunc(random()*250 + 2)
)::inet,
('{200,404}'::int[])[ceil(random()*2)],
5+trunc(random()*150)
);
COMMIT;
PERFORM pg_sleep(random() * 0.25);
END LOOP;
END $$;
Dotaz vloží přibližně osm řádků za sekundu. Řádky jsou uloženy na různých pracovních uzlech, jak je směruje distribuční sloupec, site_id.
Poznámka:
Nechte dotaz generování dat spuštěný a otevřete druhé připojení psql pro zbývající příkazy v tomto kurzu.
Dotaz
Azure Cosmos DB for PostgreSQL umožňuje paralelní zpracování dotazů několika uzlů za účelem zrychlení. Například databáze vypočítá agregace, jako je SUMA a POČET na pracovních uzlech, a zkombinuje výsledky do konečné odpovědi.
Tady je dotaz pro počítání webových požadavků za minutu spolu s několika statistikami. Zkuste ho spustit v psql a sledujte výsledky.
SELECT
site_id,
date_trunc('minute', ingest_time) as minute,
COUNT(1) AS request_count,
SUM(CASE WHEN (status_code between 200 and 299) THEN 1 ELSE 0 END) as success_count,
SUM(CASE WHEN (status_code between 200 and 299) THEN 0 ELSE 1 END) as error_count,
SUM(response_time_msec) / COUNT(1) AS average_response_time_msec
FROM http_request
WHERE date_trunc('minute', ingest_time) > now() - '5 minutes'::interval
GROUP BY site_id, minute
ORDER BY minute ASC;
Sesouvání dat
Předchozí dotaz funguje dobře v počátečních fázích, ale jeho výkon se snižuje při škálování dat. I při distribuovaném zpracování je rychlejší předem vypočítat data, než je opakovaně přepočítat.
Díky pravidelnému shrnutí nezpracovaných dat do agregované tabulky můžeme zajistit, aby náš řídicí panel zůstal rychlý. Můžete experimentovat s dobou trvání agregace. Použili jsme tabulku agregace za minutu, ale místo toho můžete rozdělit data na 5, 15 nebo 60 minut.
Pro snadnější spuštění tohoto uvedení ho umístíme do funkce plpgsql. Spuštěním těchto příkazů v psql vytvořte rollup_http_request funkci.
-- initialize to a time long ago
INSERT INTO latest_rollup VALUES ('10-10-1901');
-- function to do the rollup
CREATE OR REPLACE FUNCTION rollup_http_request() RETURNS void AS $$
DECLARE
curr_rollup_time timestamptz := date_trunc('minute', now());
last_rollup_time timestamptz := minute from latest_rollup;
BEGIN
INSERT INTO http_request_1min (
site_id, ingest_time, request_count,
success_count, error_count, average_response_time_msec
) SELECT
site_id,
date_trunc('minute', ingest_time),
COUNT(1) as request_count,
SUM(CASE WHEN (status_code between 200 and 299) THEN 1 ELSE 0 END) as success_count,
SUM(CASE WHEN (status_code between 200 and 299) THEN 0 ELSE 1 END) as error_count,
SUM(response_time_msec) / COUNT(1) AS average_response_time_msec
FROM http_request
-- roll up only data new since last_rollup_time
WHERE date_trunc('minute', ingest_time) <@
tstzrange(last_rollup_time, curr_rollup_time, '(]')
GROUP BY 1, 2;
-- update the value in latest_rollup so that next time we run the
-- rollup it will operate on data newer than curr_rollup_time
UPDATE latest_rollup SET minute = curr_rollup_time;
END;
$$ LANGUAGE plpgsql;
S naší funkcí ji spusťte, aby se data shrnula:
SELECT rollup_http_request();
S našimi daty v předem agregované podobě můžeme zadávat dotazy na souhrnnou tabulku, abychom získali stejnou sestavu jako dříve. Spusťte tento dotaz:
SELECT site_id, ingest_time as minute, request_count,
success_count, error_count, average_response_time_msec
FROM http_request_1min
WHERE ingest_time > date_trunc('minute', now()) - '5 minutes'::interval;
Vypršení platnosti starých dat
Kumulativní aktualizace zrychlovají dotazy, ale stále potřebujeme vypršení platnosti starých dat, aby nedošlo k nákladům na nevázané úložiště. Rozhodněte se, jak dlouho chcete uchovávat data pro každou členitost, a pomocí standardních dotazů odstraňte data s vypršenou platností. V následujícím příkladu jsme se rozhodli uchovávat nezpracovaná data pro jeden den a agregace za minutu po dobu jednoho měsíce:
DELETE FROM http_request WHERE ingest_time < now() - interval '1 day';
DELETE FROM http_request_1min WHERE ingest_time < now() - interval '1 month';
V produkčním prostředí můžete tyto dotazy zabalit do funkce a volat je každou minutu v úloze cron.
Vyčištění prostředků
V předchozích krocích jste vytvořili prostředky Azure v clusteru. Pokud v budoucnu tyto prostředky nepotřebujete, odstraňte cluster. Stiskněte tlačítko Odstranit na stránce Přehled clusteru. Po zobrazení výzvy na místní stránce potvrďte název clusteru a klikněte na poslední tlačítko Odstranit .
Další kroky
V tomto kurzu jste zjistili, jak zřídit cluster. Připojili jste se k němu pomocí psql, vytvořili jste schéma a distribuovaná data. Naučili jste se dotazovat data v nezpracované podobě, pravidelně je agregovat, dotazovat se na agregované tabulky a ukončit platnost starých dat.
- Informace o typech uzlů clusteru
- Určení nejlepší počáteční velikosti clusteru