Vytváření řešení provozní kontinuity a zotavení po havárii s využitím služby Azure Data Explorer
Tento článek podrobně popisuje, jak se můžete připravit na regionální výpadek Azure tím, že replikujete prostředky Azure Data Exploreru, správu a příjem dat v různých oblastech Azure. Tady je příklad příjmu dat pomocí služby Azure Event Hubs. Optimalizace nákladů je popsána také pro různé konfigurace architektury. Podrobnější informace o aspektech architektury a řešeních zotavení najdete v přehledu kontinuity podnikových procesů.
Příprava na regionální výpadek Azure za účelem ochrany dat
Azure Data Explorer nepodporuje automatickou ochranu proti výpadku celé oblasti Azure. K tomuto narušení může dojít během přírodní katastrofy, jako je zemětřesení. Pokud potřebujete řešení pro situaci zotavení po havárii, proveďte následující kroky, abyste zajistili kontinuitu podnikových procesů. V těchto krocích replikujete clustery, správu a příjem dat ve dvou spárovaných oblastech Azure.
- Vytvořte dva nebo více nezávislých clusterů ve dvou spárovaných oblastech Azure.
- Replikujte všechny aktivity správy, jako je vytváření nových tabulek nebo správa rolí uživatelů v každém clusteru.
- Ingestování dat do každého clusteru paralelně
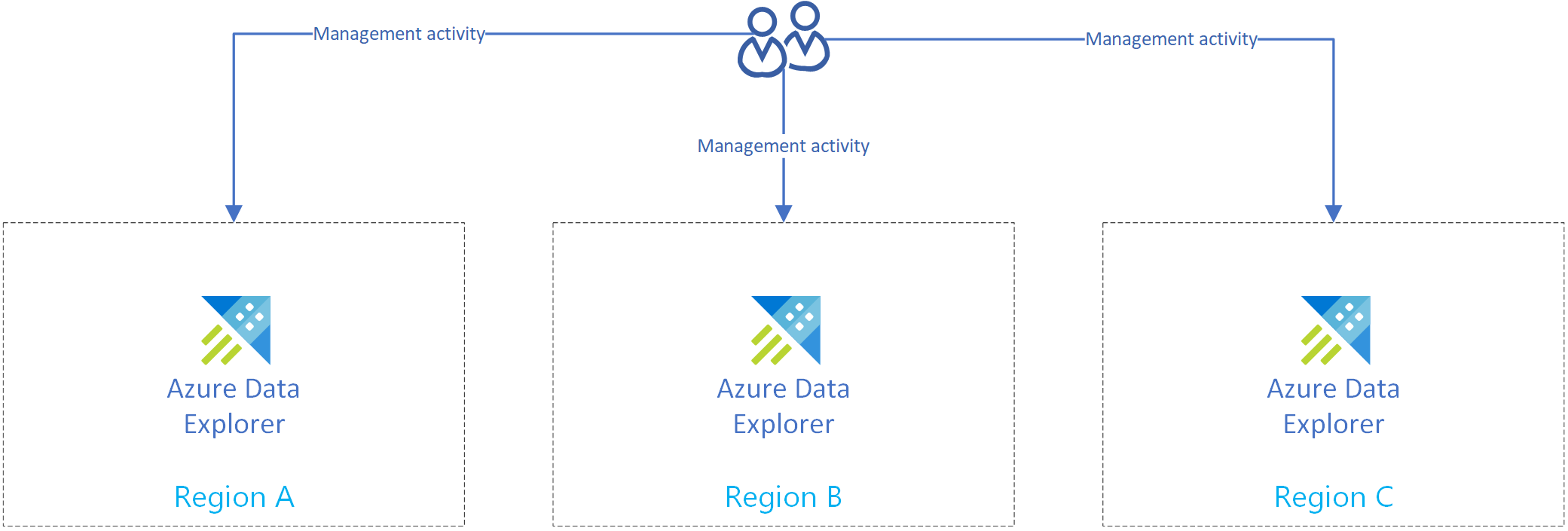
Vytvoření několika nezávislých clusterů
Vytvořte více než jeden cluster Azure Data Exploreru ve více než jedné oblasti. Ujistěte se, že se ve spárovaných oblastech Azure vytvoří aspoň dva z těchto clusterů.
Následující obrázek znázorňuje repliky, tři clustery ve třech různých oblastech.

Replikace aktivit správy
Replikujte aktivity správy tak, aby měly v každé replice stejnou konfiguraci clusteru.
Vytvořte na každé replice stejné:
- Databáze: K vytvoření nové databáze můžete použít Azure Portal nebo jednu z našich sad SDK .
- Tabulky
- Mapování
- Zásady
Spravujte ověřování a autorizaci na každé replice.
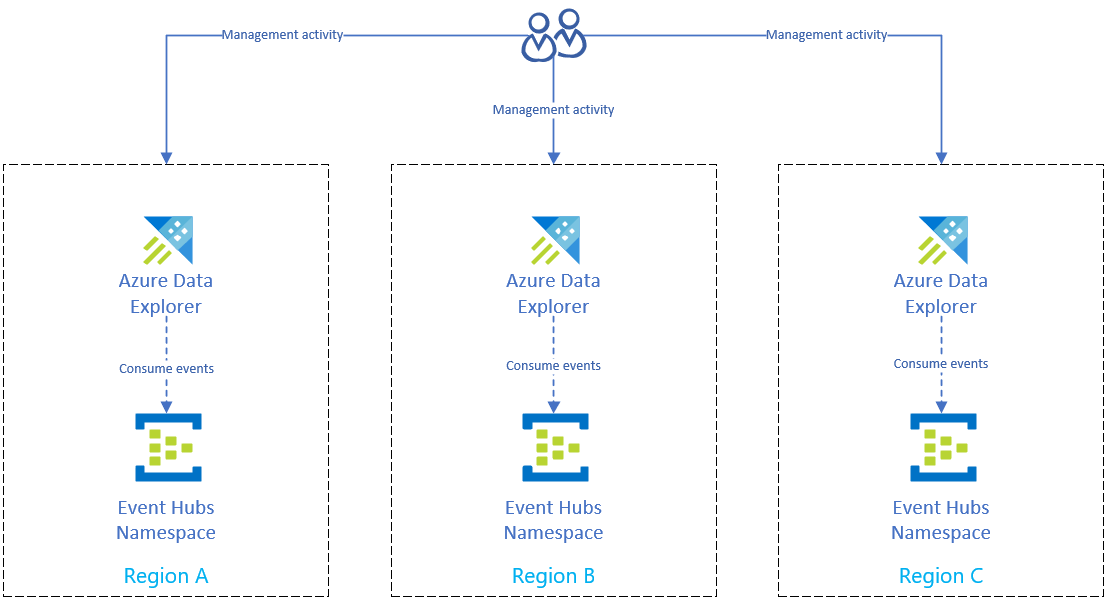
Řešení zotavení po havárii s využitím příjmu dat centra událostí
Po dokončení přípravy na oblastní výpadek Azure za účelem ochrany dat se data a správa distribuují do několika oblastí. Pokud dojde k výpadku v jedné oblasti, Azure Data Explorer bude moct používat další repliky.
Nastavení příjmu dat pomocí centra událostí
Pokud chcete ingestovat data ze služby Azure Event Hubs do clusteru Azure Data Exploreru v jednotlivých oblastech, nejprve replikujte nastavení služby Azure Event Hubs v každé oblasti. Pak nakonfigurujte repliku Azure Data Exploreru jednotlivých oblastí tak, aby ingestovala data z příslušné služby Event Hubs.
Poznámka:
Příjem dat prostřednictvím služby Azure Event Hubs, IoT Hubu nebo úložiště je robustní. Pokud cluster není po určitou dobu dostupný, zachytí se později a vloží všechny čekající zprávy nebo objekty blob. Tento proces spoléhá na vytváření kontrolních bodů.
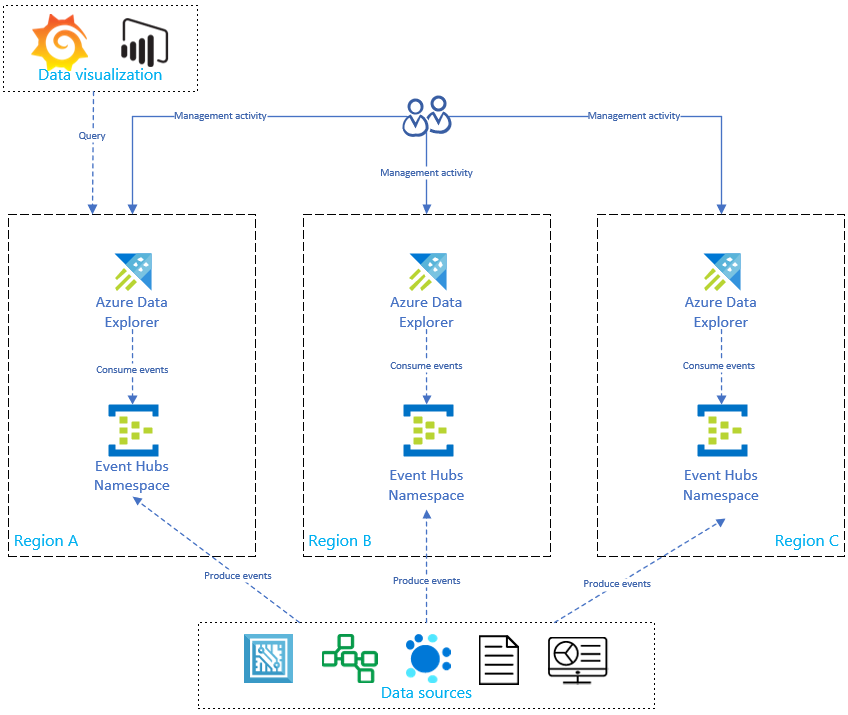
Jak je znázorněno v následujícím diagramu, vaše zdroje dat vytvářejí události do center událostí ve všech oblastech a každá replika Azure Data Exploreru události využívá. Komponenty vizualizace dat, jako jsou Power BI, Grafana nebo webové aplikace založené na sadě SDK, se můžou dotazovat na jednu z replik.
Optimalizace nákladů
Teď jste připraveni optimalizovat repliky pomocí některých z následujících metod:
- Vytvoření konfigurace obnovení dat na vyžádání
- Spuštění a zastavení replik
- Implementace vysoce dostupné aplikační služby
- Optimalizace nákladů v konfiguraci aktivní-aktivní
Vytvoření konfigurace obnovení dat na vyžádání
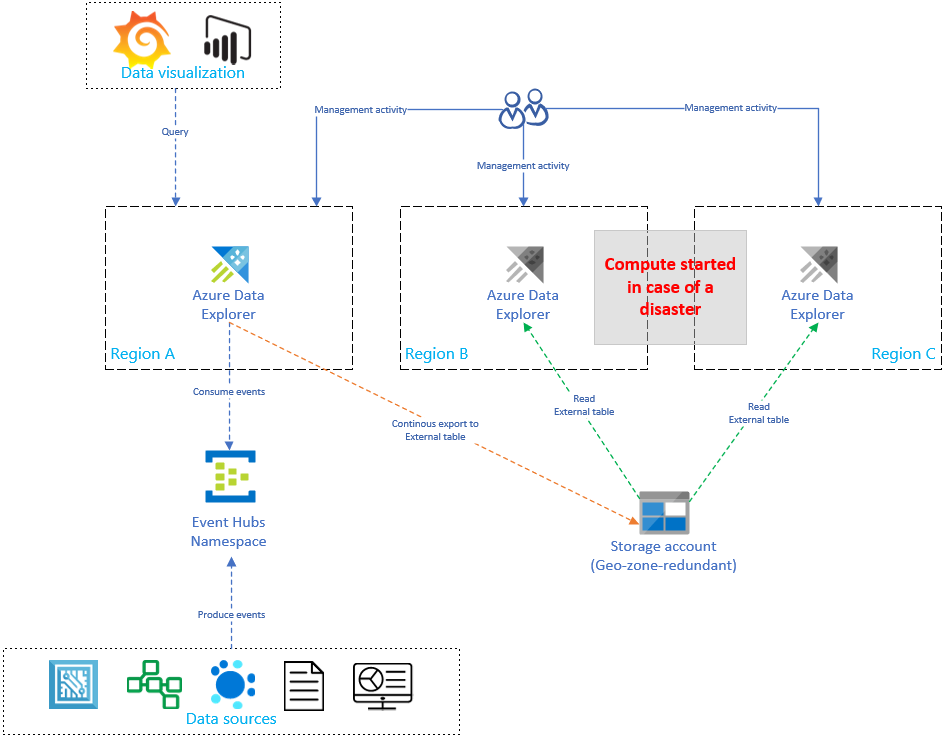
Replikace a aktualizace instalace Azure Data Exploreru lineárně zvýší náklady s počtem replik. Pokud chcete optimalizovat náklady, můžete implementovat variantu architektury, která vyrovnává čas, převzetí služeb při selhání a náklady. V konfiguraci obnovení dat na vyžádání byla optimalizace nákladů implementována zavedením pasivních replik Azure Data Exploreru. Tyto repliky jsou zapnuté pouze v případě, že dojde k havárii v primární oblasti (například oblast A). Repliky v oblastech B a C nemusí být aktivní 24/7, což výrazně snižuje náklady. Ve většině případů ale výkon těchto replik nebude tak dobrý jako primární cluster. Další informace najdete v tématu Konfigurace obnovení dat na vyžádání.
Na obrázku níže pouze jeden cluster ingestuje data z centra událostí. Primární cluster v oblasti A provádí průběžný export všech dat do účtu úložiště. Sekundární repliky mají přístup k datům pomocí externích tabulek.
Spuštění a zastavení replik
Sekundární repliky můžete spustit a zastavit pomocí jedné z následujících metod:
Tlačítko Zastavit na kartě Přehled na webu Azure Portal Další informace najdete v tématu Zastavení a restartování clusteru.
Azure CLI:
az kusto cluster stop --name=<clusterName> --resource-group=<rgName> --subscription=<subscriptionId>"
Implementace vysoce dostupné aplikační služby
Vytvoření klienta BCDR služby Aplikace Azure
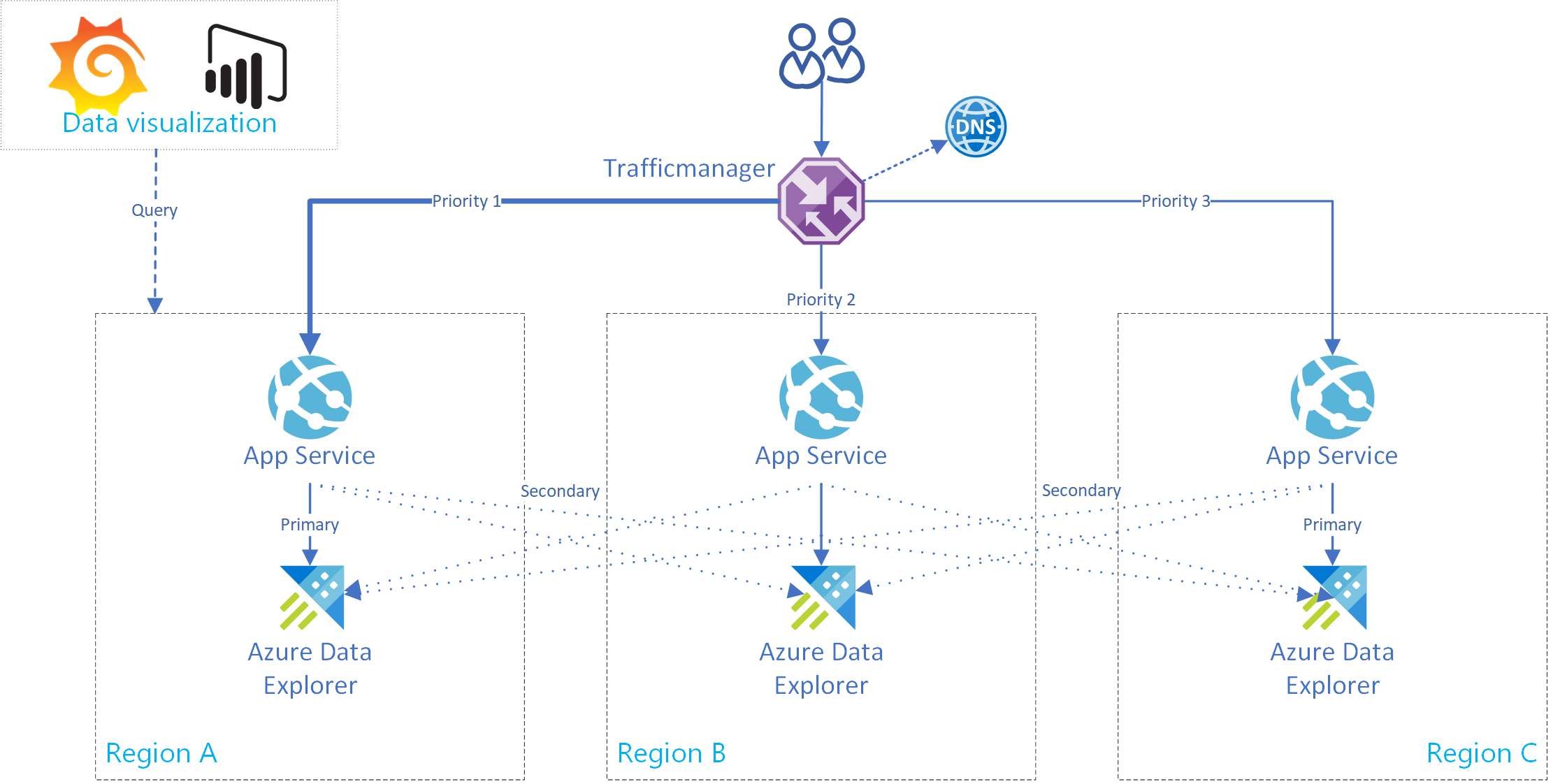
V této části se dozvíte, jak vytvořit službu Aplikace Azure, která podporuje připojení k jednomu primárnímu a několika sekundárním clusterům Azure Data Exploreru. Následující obrázek znázorňuje nastavení služby Aplikace Azure Service.
Tip
Pokud máte více připojení mezi replikami ve stejné službě, získáte vyšší dostupnost. Toto nastavení není užitečné jenom v případech oblastních výpadků.
Tento často používaný kód použijte pro službu App Service. Pro implementaci klienta s více clustery byla vytvořena třída AdxBcdrClient . Každý dotaz spuštěný pomocí tohoto klienta se odešle jako první do primárního clusteru. Pokud dojde k selhání, dotaz se odešle do sekundárních replik.
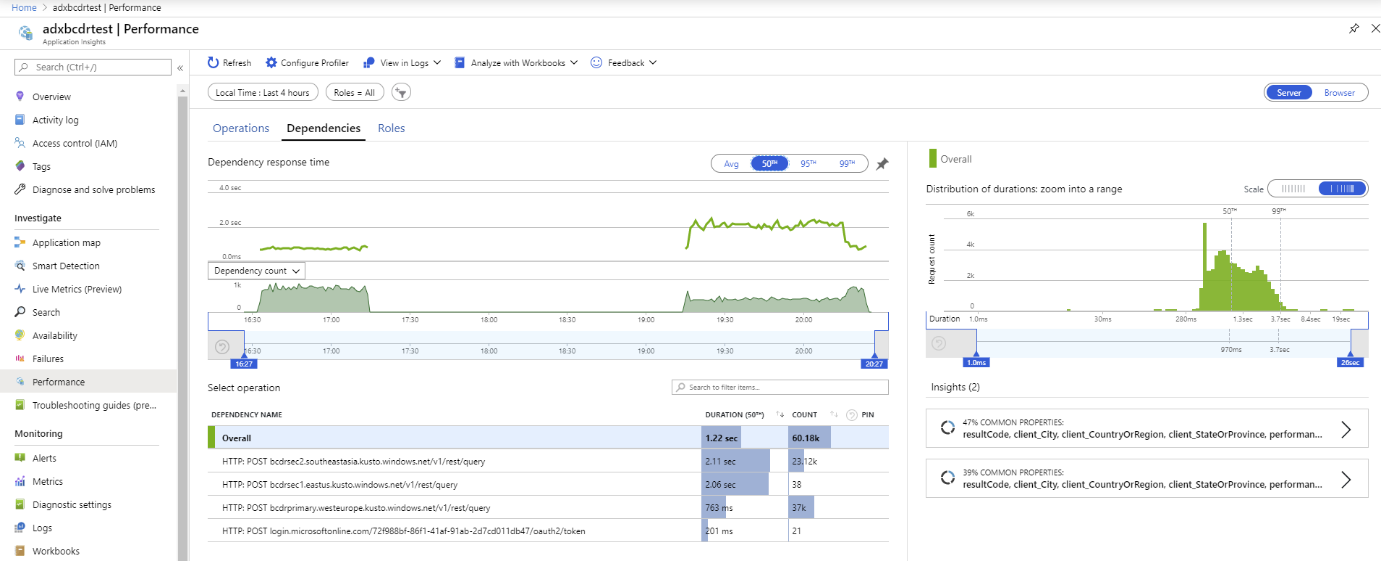
Pomocí vlastních metrik Application Insights můžete měřit výkon a distribuci požadavků na primární a sekundární clustery.
Otestování klienta BCDR služby Aplikace Azure
Spustili jsme test s využitím několika replik Azure Data Exploreru. Po simulovaném výpadku primárního a sekundárního clusteru můžete vidět, že klient BCDR služby App Service se chová podle očekávání.
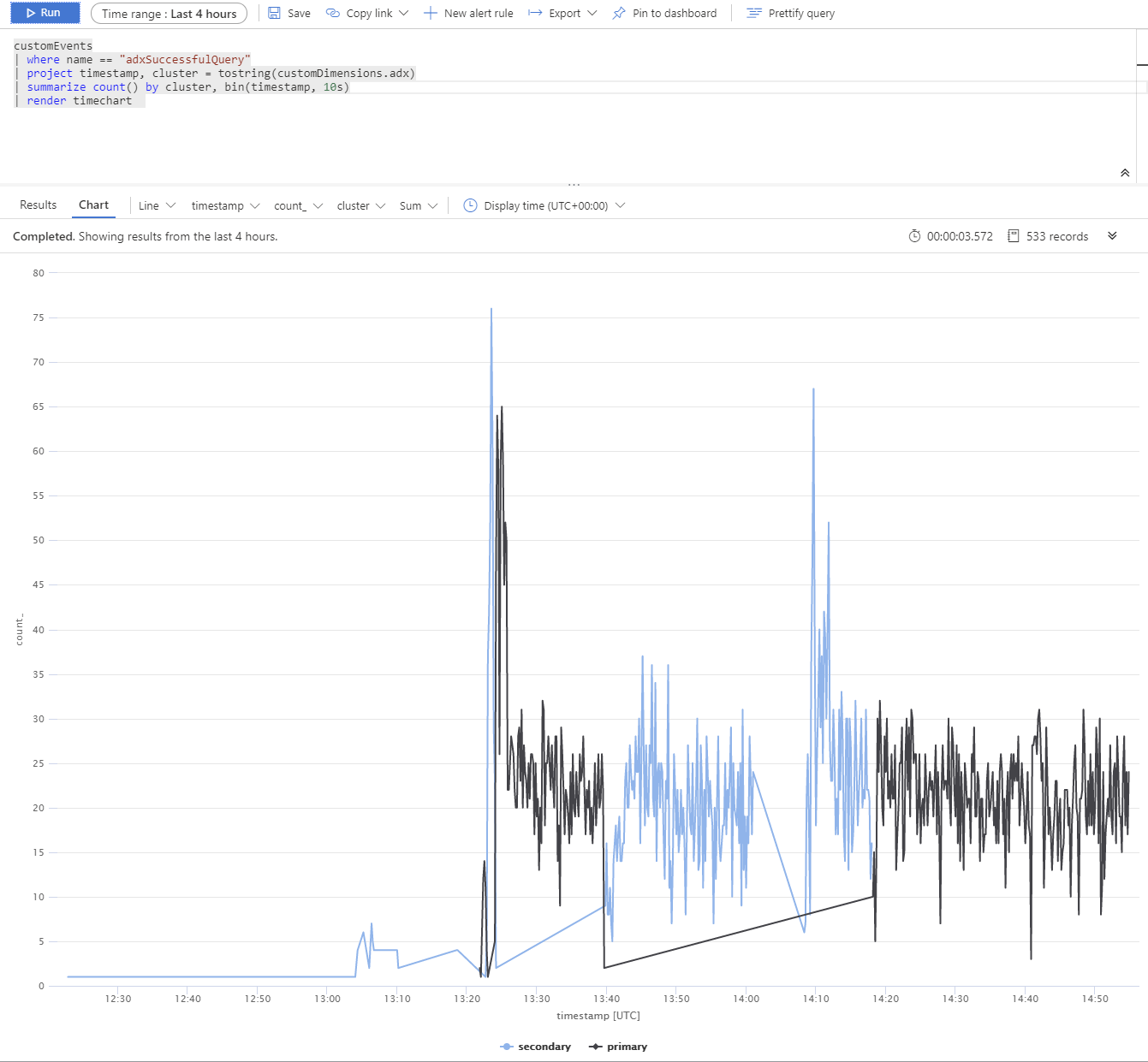
Clustery Azure Data Exploreru se distribuují napříč Západní Evropou (primární 2xD14v2), Jihovýchodní Asie a USA – východ (2xD11v2).
Poznámka:
Pomalejší doba odezvy je způsobená různými skladovými jednotkami a dotazy napříč planetami.
Provádění dynamického nebo statického směrování
Pro dynamické nebo statické směrování požadavků použijte metody směrování Azure Traffic Manageru. Azure Traffic Manager je nástroj pro vyrovnávání zatížení provozu založený na DNS, který umožňuje distribuovat provoz služby App Service. Tento provoz je optimalizovaný pro služby napříč globálními oblastmi Azure a zároveň poskytuje vysokou dostupnost a rychlost odezvy.
Můžete také použít směrování založené na službě Azure Front Door. Porovnání těchto dvou metod najdete v tématu Vyrovnávání zatížení se sadou pro doručování aplikací Azure.
Optimalizace nákladů v konfiguraci aktivní-aktivní
Použití konfigurace aktivní-aktivní pro zotavení po havárii zvyšuje náklady lineárně. Náklady zahrnují uzly, úložiště, revize a zvýšené síťové náklady na šířku pásma.
Optimalizace nákladů s využitím optimalizovaného automatického škálování
Pomocí funkce optimalizovaného automatického škálování můžete nakonfigurovat horizontální škálování sekundárních clusterů. Měly by být dimenze, aby mohly zpracovat zatížení příjmu dat. Jakmile primární cluster není dostupný, sekundární clustery získají větší provoz a škálují se podle konfigurace.
Použití optimalizovaného automatického škálování v tomto příkladu uložilo přibližně 50 % nákladů ve srovnání se stejným horizontálním a vertikálním škálováním na všech replikách.