Ingestování dat z Apache Kafka do Azure Data Explorer
Apache Kafka je distribuovaná streamovací platforma pro vytváření datových kanálů streamování v reálném čase, které spolehlivě přemísťují data mezi systémy nebo aplikacemi. Kafka Connect je nástroj pro škálovatelné a spolehlivé streamování dat mezi Apache Kafka a dalšími datovými systémy. Jímka Kusto Kafka slouží jako konektor ze systému Kafka a nevyžaduje použití kódu. Stáhněte si jar konektoru jímky z úložiště Git nebo z centra konektoru Confluent.
Tento článek ukazuje, jak ingestovat data pomocí systému Kafka pomocí samostatného nastavení Dockeru, aby se zjednodušilo nastavení clusteru Kafka a konektoru Kafka.
Další informace najdete v tématu Podrobnosti o úložišti Git a verzi konektoru.
Požadavky
- Předplatné Azure. Vytvořte si bezplatný účet Azure.
- Azure Data Explorer clusteru a databáze s výchozími zásadami mezipaměti a uchovávání informací nebodatabází KQL v Microsoft Fabric.
- Rozhraní příkazového řádku Azure.
- Docker a Docker Compose.
Vytvoření instančního objektu Microsoft Entra
Instanční objekt Microsoft Entra lze vytvořit prostřednictvím Azure Portal nebo programově, jako v následujícím příkladu.
Tento instanční objekt bude identita, kterou konektor použije k zápisu dat do tabulky v Kusto. Později tomuto instančnímu objektu udělíte oprávnění pro přístup k prostředkům Kusto.
Přihlaste se ke svému předplatnému Azure přes Azure CLI. Pak se ověřte v prohlížeči.
az loginZvolte předplatné pro hostování objektu zabezpečení. Tento krok je potřeba, pokud máte více předplatných.
az account set --subscription YOUR_SUBSCRIPTION_GUIDVytvořte instanční objekt. V tomto příkladu se instanční objekt nazývá
my-service-principal.az ad sp create-for-rbac -n "my-service-principal" --role Contributor --scopes /subscriptions/{SubID}Z vrácených dat JSON zkopírujte
appIdpassword, atenantpro budoucí použití.{ "appId": "1234abcd-e5f6-g7h8-i9j0-1234kl5678mn", "displayName": "my-service-principal", "name": "my-service-principal", "password": "1234abcd-e5f6-g7h8-i9j0-1234kl5678mn", "tenant": "1234abcd-e5f6-g7h8-i9j0-1234kl5678mn" }
Vytvořili jste aplikaci Microsoft Entra a instanční objekt.
Vytvoření cílové tabulky
V prostředí dotazu vytvořte tabulku s názvem
Stormspomocí následujícího příkazu:.create table Storms (StartTime: datetime, EndTime: datetime, EventId: int, State: string, EventType: string, Source: string)Pomocí následujícího příkazu vytvořte odpovídající mapování
Storms_CSV_Mappingtabulek pro ingestované data:.create table Storms ingestion csv mapping 'Storms_CSV_Mapping' '[{"Name":"StartTime","datatype":"datetime","Ordinal":0}, {"Name":"EndTime","datatype":"datetime","Ordinal":1},{"Name":"EventId","datatype":"int","Ordinal":2},{"Name":"State","datatype":"string","Ordinal":3},{"Name":"EventType","datatype":"string","Ordinal":4},{"Name":"Source","datatype":"string","Ordinal":5}]'Vytvořte v tabulce zásadu dávkového příjmu pro konfigurovatelnou latenci příjmu dat ve frontě.
Tip
Zásady dávkování příjmu dat jsou optimalizátorem výkonu a obsahují tři parametry. První splněná podmínka aktivuje příjem dat do tabulky Azure Data Explorer.
.alter table Storms policy ingestionbatching @'{"MaximumBatchingTimeSpan":"00:00:15", "MaximumNumberOfItems": 100, "MaximumRawDataSizeMB": 300}'Pomocí instančního objektu z části Vytvoření Microsoft Entra instančního objektu udělte oprávnění pro práci s databází.
.add database YOUR_DATABASE_NAME admins ('aadapp=YOUR_APP_ID;YOUR_TENANT_ID') 'AAD App'
Spuštění testovacího prostředí
Následující cvičení je navržené tak, aby vám poskytlo zkušenosti s vytvářením dat, nastavením konektoru Kafka a streamováním těchto dat do Azure Data Explorer s konektorem. Pak se můžete podívat na ingestované údaje.
Klonování úložiště Git
Naklonujte úložiště Git testovacího prostředí.
Vytvořte na počítači místní adresář.
mkdir ~/kafka-kusto-hol cd ~/kafka-kusto-holNaklonujte úložiště.
cd ~/kafka-kusto-hol git clone https://github.com/Azure/azure-kusto-labs cd azure-kusto-labs/kafka-integration/dockerized-quickstart
Obsah klonovaného úložiště
Spuštěním následujícího příkazu vypište obsah klonovaného úložiště:
cd ~/kafka-kusto-hol/azure-kusto-labs/kafka-integration/dockerized-quickstart
tree
Výsledkem tohoto hledání je:
├── README.md
├── adx-query.png
├── adx-sink-config.json
├── connector
│ └── Dockerfile
├── docker-compose.yaml
└── storm-events-producer
├── Dockerfile
├── StormEvents.csv
├── go.mod
├── go.sum
├── kafka
│ └── kafka.go
└── main.go
Kontrola souborů v klonovaném úložišti
Následující části popisují důležité části souborů ve stromu souborů výše.
adx-sink-config.json
Tento soubor obsahuje soubor vlastností jímky Kusto, ve kterém aktualizujete konkrétní podrobnosti o konfiguraci:
{
"name": "storm",
"config": {
"connector.class": "com.microsoft.azure.kusto.kafka.connect.sink.KustoSinkConnector",
"flush.size.bytes": 10000,
"flush.interval.ms": 10000,
"tasks.max": 1,
"topics": "storm-events",
"kusto.tables.topics.mapping": "[{'topic': 'storm-events','db': '<enter database name>', 'table': 'Storms','format': 'csv', 'mapping':'Storms_CSV_Mapping'}]",
"aad.auth.authority": "<enter tenant ID>",
"aad.auth.appid": "<enter application ID>",
"aad.auth.appkey": "<enter client secret>",
"kusto.ingestion.url": "https://ingest-<name of cluster>.<region>.kusto.windows.net",
"kusto.query.url": "https://<name of cluster>.<region>.kusto.windows.net",
"key.converter": "org.apache.kafka.connect.storage.StringConverter",
"value.converter": "org.apache.kafka.connect.storage.StringConverter"
}
}
Nahraďte hodnoty následujících atributů podle nastavení Azure Data Explorer: , , ( kusto.tables.topics.mapping název databáze), kusto.ingestion.urla kusto.query.url. aad.auth.appkeyaad.auth.appidaad.auth.authority
Konektor – Dockerfile
Tento soubor obsahuje příkazy pro vygenerování image Dockeru pro instanci konektoru. Zahrnuje stažení konektoru z adresáře vydání úložiště Git.
Adresář Storm-events-producer
Tento adresář obsahuje program Go, který čte místní soubor "StormEvents.csv" a publikuje data do tématu Kafka.
docker-compose.yaml
version: "2"
services:
zookeeper:
image: debezium/zookeeper:1.2
ports:
- 2181:2181
kafka:
image: debezium/kafka:1.2
ports:
- 9092:9092
links:
- zookeeper
depends_on:
- zookeeper
environment:
- ZOOKEEPER_CONNECT=zookeeper:2181
- KAFKA_ADVERTISED_LISTENERS=PLAINTEXT://localhost:9092
kusto-connect:
build:
context: ./connector
args:
KUSTO_KAFKA_SINK_VERSION: 1.0.1
ports:
- 8083:8083
links:
- kafka
depends_on:
- kafka
environment:
- BOOTSTRAP_SERVERS=kafka:9092
- GROUP_ID=adx
- CONFIG_STORAGE_TOPIC=my_connect_configs
- OFFSET_STORAGE_TOPIC=my_connect_offsets
- STATUS_STORAGE_TOPIC=my_connect_statuses
events-producer:
build:
context: ./storm-events-producer
links:
- kafka
depends_on:
- kafka
environment:
- KAFKA_BOOTSTRAP_SERVER=kafka:9092
- KAFKA_TOPIC=storm-events
- SOURCE_FILE=StormEvents.csv
Spuštění kontejnerů
V terminálu spusťte kontejnery:
docker-compose upAplikace producenta začne do
storm-eventstématu odesílat události. Měly by se zobrazit protokoly podobné následujícím protokolům:.... events-producer_1 | sent message to partition 0 offset 0 events-producer_1 | event 2007-01-01 00:00:00.0000000,2007-01-01 00:00:00.0000000,13208,NORTH CAROLINA,Thunderstorm Wind,Public events-producer_1 | events-producer_1 | sent message to partition 0 offset 1 events-producer_1 | event 2007-01-01 00:00:00.0000000,2007-01-01 05:00:00.0000000,23358,WISCONSIN,Winter Storm,COOP Observer ....Pokud chcete zkontrolovat protokoly, spusťte následující příkaz v samostatném terminálu:
docker-compose logs -f | grep kusto-connect
Spuštění konektoru
Ke spuštění konektoru použijte volání Kafka Connect REST.
V samostatném terminálu spusťte úlohu jímky pomocí následujícího příkazu:
curl -X POST -H "Content-Type: application/json" --data @adx-sink-config.json http://localhost:8083/connectorsStav zkontrolujete spuštěním následujícího příkazu v samostatném terminálu:
curl http://localhost:8083/connectors/storm/status
Konektor začne zařadit procesy příjmu dat do fronty do Azure Data Explorer.
Poznámka
Pokud máte problémy s konektorem protokolu, vytvořte problém.
Dotazování a kontrola dat
Potvrzení příjmu dat
Počkejte, až data dorazí do
Stormstabulky. Pokud chcete přenos dat potvrdit, zkontrolujte počet řádků:Storms | countOvěřte, že v procesu příjmu dat nedochází k žádným selháním:
.show ingestion failuresJakmile uvidíte data, vyzkoušejte několik dotazů.
Vytváření dotazů na data
Pokud chcete zobrazit všechny záznamy, spusťte následující dotaz:
StormsPoužití
whereaprojectk filtrování konkrétních dat:Storms | where EventType == 'Drought' and State == 'TEXAS' | project StartTime, EndTime, Source, EventIdsummarizePoužijte operátor:Storms | summarize event_count=count() by State | where event_count > 10 | project State, event_count | render columnchart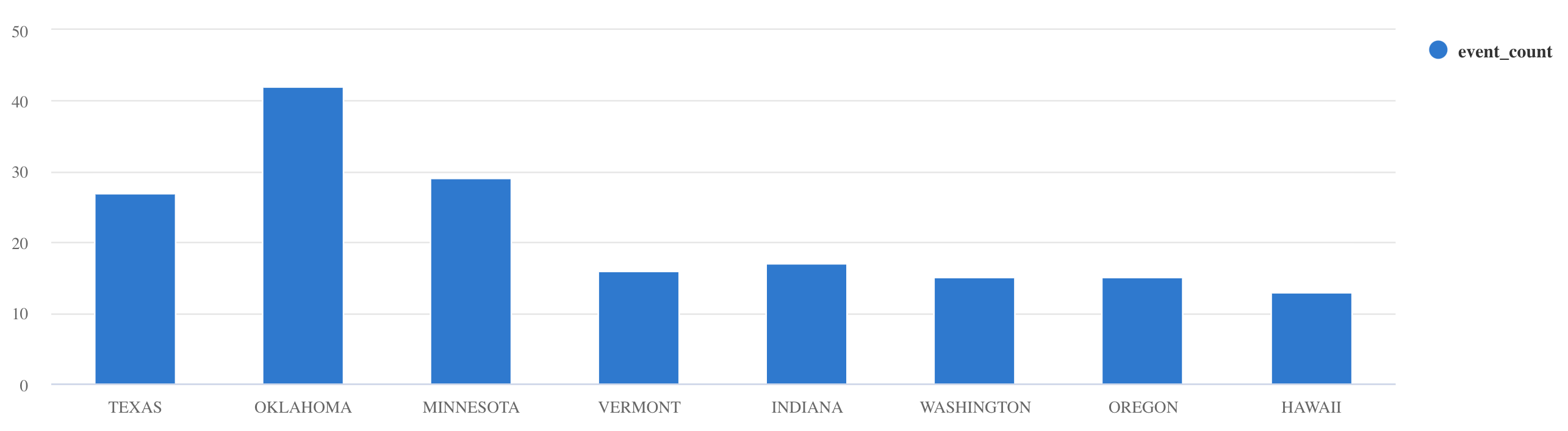
Další příklady dotazů a pokyny najdete v tématu Psaní dotazů v KQL a dotazovací jazyk Kusto dokumentaci.
Resetovat
Pokud chcete resetovat, proveďte následující kroky:
- Zastavení kontejnerů (
docker-compose down -v) - Odstranit (
drop table Storms) - Opětovné vytvoření
Stormstabulky - Opětovné vytvoření mapování tabulek
- Restartování kontejnerů (
docker-compose up)
Vyčištění prostředků
Pokud chcete odstranit prostředky Azure Data Explorer, použijte příkaz az cluster delete nebo az Kusto database delete:
az kusto cluster delete -n <cluster name> -g <resource group name>
az kusto database delete -n <database name> --cluster-name <cluster name> -g <resource group name>
Ladění konektoru jímky Kafka
Vylaďte konektor jímky Kafka tak, aby fungoval se zásadami dávkování příjmu dat:
- Od 1 MB vylaďte limit velikosti jímky
flush.size.bytesKafka od 1 MB a zvyšte ho o 10 MB nebo 100 MB. - Při použití jímky Kafka se data agregují dvakrát. Na straně konektoru se data agregují podle nastavení vyprázdnění a na straně služby Azure Data Explorer podle zásad dávkování. Pokud je doba dávkování příliš krátká a konektor ani služba nemohou ingestovat žádná data, musí se doba dávkování prodloužit. Nastavte velikost dávkování na 1 GB a podle potřeby ji zvětšete nebo zmenšete o 100 MB. Pokud je například velikost vyprázdnění 1 MB a velikost zásad dávkování je 100 MB, po agregaci dávky 100 MB konektorem jímky Kafka služba Azure Data Explorer ingestuje dávku o velikosti 100 MB. Pokud je čas zásad dávkování 20 sekund a konektor Jímky Kafka vyprázdní 50 MB za 20 sekund, služba ingestuje dávku o 50 MB.
- Škálování můžete provést přidáním instancí a oddílů Kafka. Zvyšte
tasks.maxpočet oddílů. Pokud máte dostatek dat k vytvoření objektu blob o velikostiflush.size.bytesnastavení, vytvořte oddíl. Pokud je objekt blob menší, dávka se zpracuje při dosažení časového limitu, takže oddíl nebude mít dostatečnou propustnost. Velký počet oddílů znamená vyšší režijní náklady na zpracování.
Související obsah
- Přečtěte si další informace o architektuře velkých objemů dat.
- Zjistěte, jak ingestovat ukázková data ve formátu JSON do Azure Data Explorer.
- Další testovací prostředí Kafka: