Kopírování dat z Amazon Redshiftu pomocí služby Azure Data Factory nebo Synapse Analytics
PLATÍ PRO:  Azure Data Factory Azure Synapse Analytics
Azure Data Factory Azure Synapse Analytics
Tip
Vyzkoušejte si službu Data Factory v Microsoft Fabric, řešení pro analýzy typu all-in-one pro podniky. Microsoft Fabric zahrnuje všechno od přesunu dat až po datové vědy, analýzy v reálném čase, business intelligence a vytváření sestav. Přečtěte si, jak začít používat novou zkušební verzi zdarma.
Tento článek popisuje, jak pomocí aktivity kopírování v kanálech Azure Data Factory a Synapse Analytics kopírovat data z Amazon Redshiftu. Vychází z článku s přehledem aktivity kopírování, který představuje obecný přehled aktivity kopírování.
Podporované funkce
Tento konektor Amazon Redshift je podporovaný pro následující funkce:
| Podporované funkce | IR |
|---|---|
| aktivita Copy (zdroj/-) | (1) (2) |
| Aktivita Lookup | (1) (2) |
(1) Prostředí Azure Integration Runtime (2) Místní prostředí Integration Runtime
Seznam úložišť dat podporovaných jako zdroje nebo jímky aktivitou kopírování najdete v tabulce Podporované úložiště dat.
Konkrétně tento konektor Amazon Redshift podporuje načítání dat z Redshiftu pomocí dotazu nebo integrované podpory funkce UNLOAD redshiftu.
Konektor podporuje verze Windows v tomto článku.
Tip
Pokud chcete dosáhnout nejlepšího výkonu při kopírování velkých objemů dat z Redshiftu, zvažte použití integrované funkce Redshift UNLOAD prostřednictvím AmazonU S3. Podrobnosti najdete v části Použití funkce UNLOAD ke kopírování dat z oddílu Amazon Redshift .
Požadavky
- Pokud kopírujete data do místního úložiště dat pomocí místního prostředí Integration Runtime, udělte prostředí Integration Runtime (použijte IP adresu počítače) přístup ke clusteru Amazon Redshift. Pokyny najdete v tématu Autorizace přístupu ke clusteru .
- Pokud kopírujete data do úložiště dat Azure, přečtěte si téma Rozsahy IP adres datového centra Azure pro výpočetní IP adresu a rozsahy SQL používané datovými centry Azure.
Začínáme
K provedení aktivita Copy s kanálem můžete použít jeden z následujících nástrojů nebo sad SDK:
- Nástroj pro kopírování dat
- Azure Portal
- Sada .NET SDK
- Sada Python SDK
- Azure PowerShell
- Rozhraní REST API
- Šablona Azure Resource Manageru
Vytvoření propojené služby pro Amazon Redshift pomocí uživatelského rozhraní
Pomocí následujícího postupu vytvořte propojenou službu s Amazon Redshift v uživatelském rozhraní webu Azure Portal.
Přejděte na kartu Správa v pracovním prostoru Azure Data Factory nebo Synapse a vyberte Propojené služby a pak klikněte na Nový:
Vyhledejte Amazon a vyberte konektor Amazon Redshift.
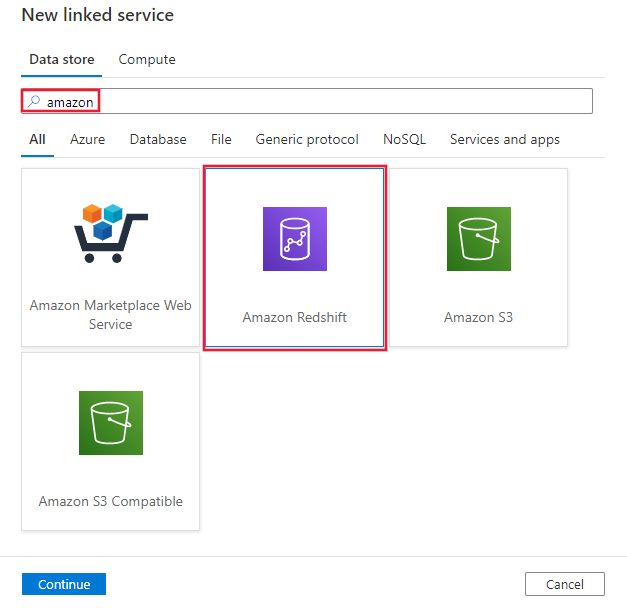
Nakonfigurujte podrobnosti o službě, otestujte připojení a vytvořte novou propojenou službu.
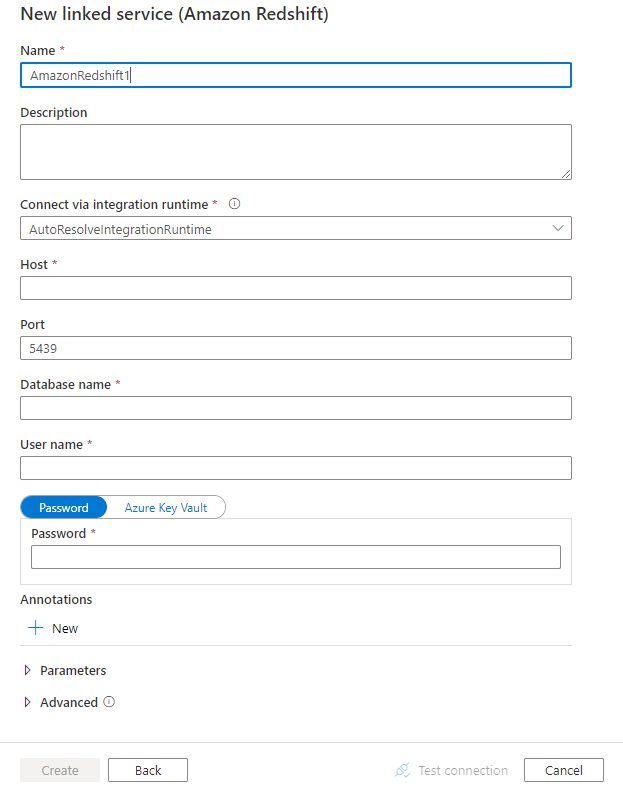
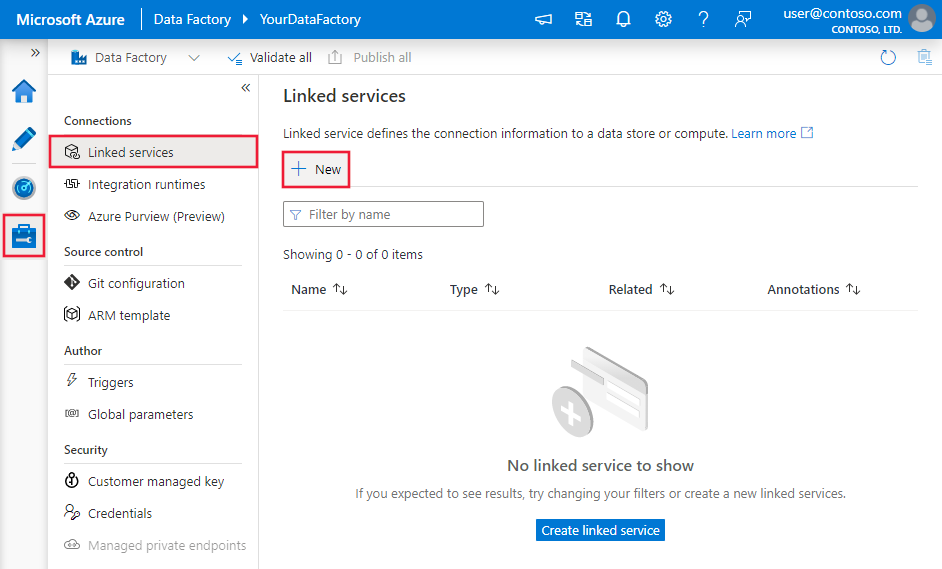
Podrobnosti konfigurace konektoru
Následující části obsahují podrobnosti o vlastnostech, které slouží k definování entit služby Data Factory specifických pro konektor Amazon Redshift.
Vlastnosti propojené služby
Propojená služba Amazon Redshift podporuje následující vlastnosti:
| Vlastnost | Popis | Povinní účastníci |
|---|---|---|
| type | Vlastnost typu musí být nastavená na: AmazonRedshift. | Ano |
| server | IP adresa nebo název hostitele serveru Amazon Redshift. | Ano |
| port | Počet portu TCP, který server Amazon Redshift používá k naslouchání klientským připojením. | Ne, výchozí hodnota je 5439 |
| database | Název databáze Amazon Redshift. | Ano |
| username | Jméno uživatele, který má přístup k databázi. | Ano |
| Heslo | Heslo pro uživatelský účet. Označte toto pole jako securestring, abyste ho mohli bezpečně uložit, nebo odkazovat na tajný klíč uložený ve službě Azure Key Vault. | Ano |
| connectVia | Prostředí Integration Runtime , které se má použít pro připojení k úložišti dat. Můžete použít prostředí Azure Integration Runtime nebo místní prostředí Integration Runtime (pokud je vaše úložiště dat umístěné v privátní síti). Pokud není zadaný, použije výchozí prostředí Azure Integration Runtime. | No |
Příklad:
{
"name": "AmazonRedshiftLinkedService",
"properties":
{
"type": "AmazonRedshift",
"typeProperties":
{
"server": "<server name>",
"database": "<database name>",
"username": "<username>",
"password": {
"type": "SecureString",
"value": "<password>"
}
},
"connectVia": {
"referenceName": "<name of Integration Runtime>",
"type": "IntegrationRuntimeReference"
}
}
}
Vlastnosti datové sady
Úplný seznam oddílů a vlastností dostupných pro definování datových sad najdete v článku o datových sadách . Tato část obsahuje seznam vlastností podporovaných datovou sadou Amazon Redshift.
Pokud chcete kopírovat data z Amazon Redshiftu, podporují se následující vlastnosti:
| Vlastnost | Popis | Povinní účastníci |
|---|---|---|
| type | Vlastnost typu datové sady musí být nastavená na: AmazonRedshiftTable. | Ano |
| schema | Název schématu | Ne (pokud je zadán dotaz ve zdroji aktivity) |
| table | Název tabulky. | Ne (pokud je zadán dotaz ve zdroji aktivity) |
| tableName | Název tabulky se schématem Tato vlastnost je podporována pro zpětnou kompatibilitu. Používejte schema a table pro nové úlohy. |
Ne (pokud je zadán dotaz ve zdroji aktivity) |
Příklad
{
"name": "AmazonRedshiftDataset",
"properties":
{
"type": "AmazonRedshiftTable",
"typeProperties": {},
"schema": [],
"linkedServiceName": {
"referenceName": "<Amazon Redshift linked service name>",
"type": "LinkedServiceReference"
}
}
}
Pokud jste používali RelationalTable zadaná datová sada, je stále podporovaná tak, jak je, zatímco se navrhuje, abyste mohli použít novou datovou sadu.
Vlastnosti aktivity kopírování
Úplný seznam oddílů a vlastností dostupných pro definování aktivit najdete v článku Pipelines . Tato část obsahuje seznam vlastností podporovaných zdrojem Amazon Redshift.
Amazon Redshift jako zdroj
Pokud chcete kopírovat data z Amazon Redshiftu, nastavte typ zdroje v aktivitě kopírování na AmazonRedshiftSource. Ve zdrojové části aktivity kopírování jsou podporovány následující vlastnosti:
| Vlastnost | Popis | Povinní účastníci |
|---|---|---|
| type | Vlastnost typu zdroje aktivity kopírování musí být nastavena na: AmazonRedshiftSource | Ano |
| query | Ke čtení dat použijte vlastní dotaz. Například: vyberte * z tabulky MyTable. | Ne (pokud je v datové sadě zadán název tabulky) |
| redshiftUnloadSettings | Skupina vlastností při použití Amazon Redshift UNLOAD. | No |
| s3LinkedServiceName | Odkazuje na Amazon S3 k použití jako dočasné úložiště zadáním názvu propojené služby typu AmazonS3. | Ano, pokud používáte FUNKCI UNLOAD |
| bucketName | Označte kontejner S3 pro uložení dočasných dat. Pokud není k dispozici, služba ji automaticky vygeneruje. | Ano, pokud používáte FUNKCI UNLOAD |
Příklad: Zdroj Amazon Redshift v aktivitě kopírování pomocí FUNKCE UNLOAD
"source": {
"type": "AmazonRedshiftSource",
"query": "<SQL query>",
"redshiftUnloadSettings": {
"s3LinkedServiceName": {
"referenceName": "<Amazon S3 linked service>",
"type": "LinkedServiceReference"
},
"bucketName": "bucketForUnload"
}
}
Přečtěte si další informace o tom, jak pomocí funkce UNLOAD efektivně kopírovat data z Amazon Redshiftu z další části.
Kopírování dat z Amazon Redshiftu pomocí funkce UNLOAD
UNLOAD je mechanismus, který poskytuje Amazon Redshift, který může uvolnit výsledky dotazu do jednoho nebo více souborů ve službě Amazon Simple Storage Service (Amazon S3). Amazon doporučuje kopírovat velké datové sady z Redshiftu.
Příklad: Kopírování dat z Amazon Redshiftu do Azure Synapse Analytics pomocí UNLOAD, fázované kopie a PolyBase
U tohoto ukázkového případu použití aktivita kopírování uvolní data z Amazon Redshiftu do AmazonU S3, jak je nakonfigurované v redshiftUnloadSettings, a pak zkopíruje data z AmazonU S3 do Azure Blob, jak je uvedeno v části "stagingSettings", a nakonec pomocí PolyBase načtěte data do Azure Synapse Analytics. Veškerý dočasný formát se zpracovává správně aktivitou kopírování.

"activities":[
{
"name": "CopyFromAmazonRedshiftToSQLDW",
"type": "Copy",
"inputs": [
{
"referenceName": "AmazonRedshiftDataset",
"type": "DatasetReference"
}
],
"outputs": [
{
"referenceName": "AzureSQLDWDataset",
"type": "DatasetReference"
}
],
"typeProperties": {
"source": {
"type": "AmazonRedshiftSource",
"query": "select * from MyTable",
"redshiftUnloadSettings": {
"s3LinkedServiceName": {
"referenceName": "AmazonS3LinkedService",
"type": "LinkedServiceReference"
},
"bucketName": "bucketForUnload"
}
},
"sink": {
"type": "SqlDWSink",
"allowPolyBase": true
},
"enableStaging": true,
"stagingSettings": {
"linkedServiceName": "AzureStorageLinkedService",
"path": "adfstagingcopydata"
},
"dataIntegrationUnits": 32
}
}
]
Mapování datových typů pro Amazon Redshift
Při kopírování dat z Amazon Redshiftu se následující mapování používají z datových typů Amazon Redshift k dočasným datovým typům používaným interně v rámci služby. Informace o tom, jak aktivita kopírování mapuje zdrojové schéma a datový typ na jímku, najdete v mapování schématu schématu a datového typu schématu schématu a datového typu.
| Datový typ Amazon Redshift | Dočasný datový typ služby |
|---|---|
| BIGINT | Int64 |
| BOOLEOVSKÝ | String |
| UKLÍZEČKA | Řetězcové |
| DATE | DateTime |
| DESETINNÝ | Desetinné číslo |
| DVOJITÁ PŘESNOST | Hodnota s dvojitou přesností |
| CELÉ ČÍSLO | Int32 |
| REÁLNÝ | Jeden |
| SMALLINT | Int16 |
| TEXT | String |
| ČASOVÉ RAZÍTKO | DateTime |
| VARCHAR | String |
Vlastnosti aktivity vyhledávání
Podrobnosti o vlastnostech najdete v aktivitě Vyhledávání.
Související obsah
Seznam úložišť dat podporovaných jako zdroje a jímky aktivitou kopírování najdete v podporovaných úložištích dat.