Kopírování dat do Azure Data Exploreru nebo z Azure Data Exploreru pomocí služby Azure Data Factory nebo Synapse Analytics
PLATÍ PRO:  Azure Data Factory Azure Synapse Analytics
Azure Data Factory Azure Synapse Analytics
Tip
Vyzkoušejte si službu Data Factory v Microsoft Fabric, řešení pro analýzy typu all-in-one pro podniky. Microsoft Fabric zahrnuje všechno od přesunu dat až po datové vědy, analýzy v reálném čase, business intelligence a vytváření sestav. Přečtěte si, jak začít používat novou zkušební verzi zdarma.
Tento článek popisuje, jak pomocí aktivity kopírování v kanálech Azure Data Factory a Synapse Analytics kopírovat data do Azure Data Exploreru nebo z Azure Data Exploreru. Vychází z článku s přehledem aktivity kopírování, který nabízí obecný přehled aktivity kopírování.
Tip
Další informace o integraci Azure Data Exploreru se službou obecně najdete v tématu Integrace Azure Data Exploreru.
Podporované funkce
Tento konektor Azure Data Exploreru je podporovaný pro následující funkce:
| Podporované funkce | IR |
|---|---|
| aktivita Copy (zdroj/jímka) | (1) (2) |
| Mapování toku dat (zdroj/jímka) | (1) |
| Aktivita Lookup | (1) (2) |
(1) Prostředí Azure Integration Runtime (2) Místní prostředí Integration Runtime
Do Azure Data Exploreru můžete kopírovat data z libovolného podporovaného zdrojového úložiště dat. Data z Azure Data Exploreru můžete také zkopírovat do libovolného podporovaného úložiště dat jímky. Seznam úložišť dat, která aktivita kopírování podporuje jako zdroje nebo jímky, najdete v tabulce Podporované úložiště dat.
Poznámka:
Kopírování dat do Nebo z Azure Data Exploreru prostřednictvím místního úložiště dat pomocí místního prostředí Integration Runtime se podporuje ve verzi 3.14 a novější.
Pomocí konektoru Azure Data Exploreru můžete provést následující akce:
- Kopírování dat pomocí ověřování tokenu aplikace Microsoft Entra s instančním objektem
- Jako zdroj načtěte data pomocí dotazu KQL (Kusto).
- Jako jímku připojte data k cílové tabulce.
Začínáme
Tip
Návod ke konektoru Azure Data Exploreru najdete v tématu Kopírování dat do a z Azure Data Exploreru a hromadného kopírování z databáze do Azure Data Exploreru.
K provedení aktivita Copy s kanálem můžete použít jeden z následujících nástrojů nebo sad SDK:
- Nástroj pro kopírování dat
- Azure Portal
- Sada .NET SDK
- Sada Python SDK
- Azure PowerShell
- Rozhraní REST API
- Šablona Azure Resource Manageru
Vytvoření propojené služby do Azure Data Exploreru pomocí uživatelského rozhraní
Pomocí následujícího postupu vytvořte propojenou službu s Azure Data Explorerem v uživatelském rozhraní webu Azure Portal.
Přejděte na kartu Správa v pracovním prostoru Azure Data Factory nebo Synapse a vyberte Propojené služby a pak klikněte na Nový:
Vyhledejte Průzkumníka a vyberte konektor Azure Data Exploreru (Kusto).
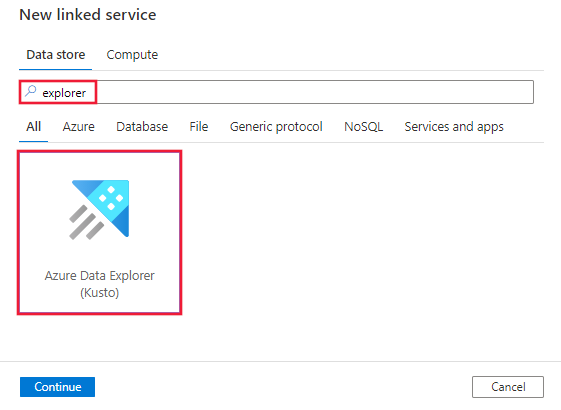
Nakonfigurujte podrobnosti o službě, otestujte připojení a vytvořte novou propojenou službu.
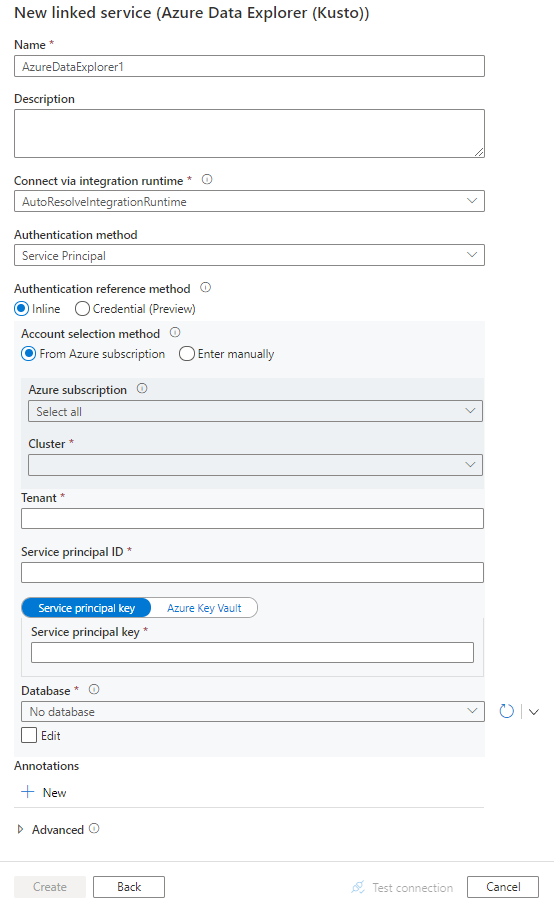
Podrobnosti konfigurace konektoru
Následující části obsahují podrobnosti o vlastnostech, které slouží k definování entit specifických pro konektor Azure Data Exploreru.
Vlastnosti propojené služby
Konektor Azure Data Exploreru podporuje následující typy ověřování. Podrobnosti najdete v odpovídajících částech:
- Ověřování instančních objektů
- Ověřování spravované identity přiřazené systémem
- Ověřování spravované identity přiřazené uživatelem
Ověřování instančního objektu
Pokud chcete použít ověřování instančního objektu, získejte instanční objekt pomocí následujícího postupu a udělte oprávnění:
Zaregistrujte aplikaci na platformě Microsoft Identity Platform. Postup najdete v tématu Rychlý start: Registrace aplikace na platformě Microsoft Identity Platform. Poznamenejte si tyto hodnoty, které použijete k definování propojené služby:
- ID aplikace
- Klíč aplikace
- ID tenanta
Udělte instančnímu objektu správná oprávnění v Azure Data Exploreru. Podrobné informace o rolích a oprávněních a o správě oprávnění najdete v tématu Správa databázových oprávnění Azure Data Exploreru. Obecně platí, že musíte:
- Jako zdroj udělte databázi alespoň roli prohlížeče databáze.
- Jako jímku udělte databázi alespoň roli uživatele databáze.
Poznámka:
Při vytváření uživatelského rozhraní se ve výchozím nastavení používá váš přihlašovací uživatelský účet k výpisu clusterů, databází a tabulek Azure Data Exploreru. Objekty pomocí instančního objektu můžete zobrazit kliknutím na rozevírací seznam vedle tlačítka pro aktualizaci nebo ručně zadat název, pokud nemáte oprávnění k těmto operacím.
Propojená služba Azure Data Explorer podporuje následující vlastnosti:
| Vlastnost | Popis | Povinní účastníci |
|---|---|---|
| type | Vlastnost type musí být nastavena na AzureDataExplorer. | Ano |
| endpoint | Adresa URL koncového bodu clusteru Azure Data Exploreru s formátem jako https://<clusterName>.<regionName>.kusto.windows.net. |
Ano |
| database | Název databáze. | Ano |
| tenant | Zadejte informace o tenantovi (název domény nebo ID tenanta), pod kterým se vaše aplikace nachází. To se v Kusto připojovací řetězec označuje jako ID autority. Načtěte ho tak, že najedete myší v pravém horním rohu webu Azure Portal. | Ano |
| servicePrincipalId | Zadejte ID klienta aplikace. To se v Kusto připojovací řetězec označuje jako ID klienta aplikace Microsoft Entra. | Ano |
| servicePrincipalKey | Zadejte klíč aplikace. To se v Kusto připojovací řetězec označuje jako "Klíč aplikace Microsoft Entra". Označte toto pole jako securestring pro bezpečné uložení nebo odkazování na zabezpečená data uložená ve službě Azure Key Vault. | Ano |
| connectVia | Prostředí Integration Runtime , které se má použít pro připojení k úložišti dat. Pokud je vaše úložiště dat v privátní síti, můžete použít prostředí Azure Integration Runtime nebo místní prostředí Integration Runtime. Pokud není zadaný, použije se výchozí prostředí Azure Integration Runtime. | No |
Příklad: Použití ověřování pomocí instančního klíče
{
"name": "AzureDataExplorerLinkedService",
"properties": {
"type": "AzureDataExplorer",
"typeProperties": {
"endpoint": "https://<clusterName>.<regionName>.kusto.windows.net ",
"database": "<database name>",
"tenant": "<tenant name/id e.g. microsoft.onmicrosoft.com>",
"servicePrincipalId": "<service principal id>",
"servicePrincipalKey": {
"type": "SecureString",
"value": "<service principal key>"
}
}
}
}
Ověřování spravované identity přiřazené systémem
Další informace o spravovaných identitách pro prostředky Azure najdete v tématu Spravované identity pro prostředky Azure.
Pokud chcete použít ověřování spravované identity přiřazené systémem, přidělte oprávnění následujícím postupem:
Načtěte informace o spravované identitě zkopírováním hodnoty ID objektu spravované identity vygenerovaného společně s pracovním prostorem objektu pro vytváření nebo Synapse.
Udělte spravované identitě správná oprávnění v Azure Data Exploreru. Podrobné informace o rolích a oprávněních a o správě oprávnění najdete v tématu Správa databázových oprávnění Azure Data Exploreru. Obecně platí, že musíte:
- Jako zdroj udělte vaší databázi roli Čtenář databáze.
- Jako jímku udělte databázovému ingestoru a databázovému prohlížeči role pro vaši databázi.
Poznámka:
Při vytváření uživatelského rozhraní se váš přihlašovací uživatelský účet použije k výpisu clusterů, databází a tabulek Azure Data Exploreru. Pokud nemáte oprávnění k těmto operacím, zadejte ho ručně.
Propojená služba Azure Data Explorer podporuje následující vlastnosti:
| Vlastnost | Popis | Povinní účastníci |
|---|---|---|
| type | Vlastnost type musí být nastavena na AzureDataExplorer. | Ano |
| endpoint | Adresa URL koncového bodu clusteru Azure Data Exploreru s formátem jako https://<clusterName>.<regionName>.kusto.windows.net. |
Ano |
| database | Název databáze. | Ano |
| connectVia | Prostředí Integration Runtime , které se má použít pro připojení k úložišti dat. Pokud je vaše úložiště dat v privátní síti, můžete použít prostředí Azure Integration Runtime nebo místní prostředí Integration Runtime. Pokud není zadaný, použije se výchozí prostředí Azure Integration Runtime. | No |
Příklad: Použití ověřování spravované identity přiřazené systémem
{
"name": "AzureDataExplorerLinkedService",
"properties": {
"type": "AzureDataExplorer",
"typeProperties": {
"endpoint": "https://<clusterName>.<regionName>.kusto.windows.net ",
"database": "<database name>",
}
}
}
Ověřování spravované identity přiřazené uživatelem
Další informace o spravovaných identitách pro prostředky Azure najdete v tématu Spravované identity pro prostředky Azure.
Pokud chcete použít ověřování spravované identity přiřazené uživatelem, postupujte takto:
Vytvořte jednu nebo více spravovaných identit přiřazených uživatelem a udělte oprávnění v Azure Data Exploreru. Podrobné informace o rolích a oprávněních a o správě oprávnění najdete v tématu Správa databázových oprávnění Azure Data Exploreru. Obecně platí, že musíte:
- Jako zdroj udělte databázi alespoň roli prohlížeče databáze.
- Jako jímku udělte databázi alespoň roli databázového ingestoru .
Přiřaďte jedné nebo více spravovaných identit přiřazených uživatelem k pracovnímu prostoru datové továrny nebo Synapse a vytvořte přihlašovací údaje pro každou spravovanou identitu přiřazenou uživatelem.
Propojená služba Azure Data Explorer podporuje následující vlastnosti:
| Vlastnost | Popis | Povinní účastníci |
|---|---|---|
| type | Vlastnost type musí být nastavena na AzureDataExplorer. | Ano |
| endpoint | Adresa URL koncového bodu clusteru Azure Data Exploreru s formátem jako https://<clusterName>.<regionName>.kusto.windows.net. |
Ano |
| database | Název databáze. | Ano |
| přihlašovací údaje | Jako objekt přihlašovacích údajů zadejte spravovanou identitu přiřazenou uživatelem. | Ano |
| connectVia | Prostředí Integration Runtime , které se má použít pro připojení k úložišti dat. Pokud je vaše úložiště dat v privátní síti, můžete použít prostředí Azure Integration Runtime nebo místní prostředí Integration Runtime. Pokud není zadaný, použije se výchozí prostředí Azure Integration Runtime. | No |
Příklad: Použití ověřování spravované identity přiřazené uživatelem
{
"name": "AzureDataExplorerLinkedService",
"properties": {
"type": "AzureDataExplorer",
"typeProperties": {
"endpoint": "https://<clusterName>.<regionName>.kusto.windows.net ",
"database": "<database name>",
"credential": {
"referenceName": "credential1",
"type": "CredentialReference"
}
}
}
}
Vlastnosti datové sady
Úplný seznam oddílů a vlastností dostupných pro definování datových sad najdete v tématu Datové sady. Tato část obsahuje seznam vlastností, které datová sada Azure Data Exploreru podporuje.
Pokud chcete kopírovat data do Azure Data Exploreru, nastavte vlastnost typu datové sady na AzureDataExplorerTable.
Podporují se následující vlastnosti:
| Vlastnost | Popis | Povinní účastníci |
|---|---|---|
| type | Vlastnost typu musí být nastavena na AzureDataExplorerTable. | Ano |
| table | Název tabulky, na kterou odkazuje propojená služba. | Ano pro jímku; Ne pro zdroj |
Příklad vlastností datové sady:
{
"name": "AzureDataExplorerDataset",
"properties": {
"type": "AzureDataExplorerTable",
"typeProperties": {
"table": "<table name>"
},
"schema": [],
"linkedServiceName": {
"referenceName": "<Azure Data Explorer linked service name>",
"type": "LinkedServiceReference"
}
}
}
Vlastnosti aktivity kopírování
Úplný seznam oddílů a vlastností dostupných pro definování aktivit najdete v tématu Kanály a aktivity. Tato část obsahuje seznam vlastností, které podporují zdroje a jímky Azure Data Exploreru.
Azure Data Explorer jako zdroj
Pokud chcete kopírovat data z Azure Data Exploreru, nastavte vlastnost typu ve zdroji aktivita Copy na AzureDataExplorerSource. Ve zdrojové části aktivity kopírování jsou podporovány následující vlastnosti:
| Vlastnost | Popis | Povinní účastníci |
|---|---|---|
| type | Vlastnost typu zdroje aktivity kopírování musí být nastavena na: AzureDataExplorerSource | Ano |
| query | Požadavek jen pro čtení zadaný ve formátu KQL. Jako referenci použijte vlastní dotaz KQL. | Ano |
| queryTimeout | Doba čekání před vypršením časového limitu požadavku dotazu. Výchozí hodnota je 10 min (00:10:00); Povolená maximální hodnota je 1 hodina (01:00:00). | No |
| noTruncation | Určuje, zda chcete zkrátit vrácenou sadu výsledků. Ve výchozím nastavení se výsledek zkrátí po 500 000 záznamech nebo po 64 megabajtech (MB). Zkrácení důrazně doporučujeme, aby se zajistilo správné chování aktivity. | No |
Poznámka:
Ve výchozím nastavení má zdroj Azure Data Exploreru limit velikosti 500 000 záznamů nebo 64 MB. Pokud chcete načíst všechny záznamy bez zkrácení, můžete zadat set notruncation; na začátku dotazu. Další informace najdete v tématu Omezení dotazů.
Příklad:
"activities":[
{
"name": "CopyFromAzureDataExplorer",
"type": "Copy",
"typeProperties": {
"source": {
"type": "AzureDataExplorerSource",
"query": "TestTable1 | take 10",
"queryTimeout": "00:10:00"
},
"sink": {
"type": "<sink type>"
}
},
"inputs": [
{
"referenceName": "<Azure Data Explorer input dataset name>",
"type": "DatasetReference"
}
],
"outputs": [
{
"referenceName": "<output dataset name>",
"type": "DatasetReference"
}
]
}
]
Azure Data Explorer jako jímka
Pokud chcete kopírovat data do Azure Data Exploreru, nastavte vlastnost typu v jímce aktivity kopírování na AzureDataExplorerSink. V části jímky aktivity kopírování jsou podporovány následující vlastnosti:
| Vlastnost | Popis | Povinní účastníci |
|---|---|---|
| type | Vlastnost typu jímky aktivity kopírování musí být nastavena na: AzureDataExplorerSink. | Ano |
| ingestionMappingName | Název předem vytvořeného mapování v tabulce Kusto Pokud chcete namapovat sloupce ze zdroje do Azure Data Exploreru (který platí pro všechna podporovaná zdrojová úložiště a formáty, včetně formátů CSV/JSON/Avro), můžete použít mapování sloupců aktivity kopírování (implicitně podle názvu nebo explicitně podle konfigurace) a/nebo mapování Azure Data Exploreru. | No |
| additionalProperties | Taška vlastností, která se dá použít k určení libovolných vlastností příjmu dat, které ještě jímka Azure Data Exploreru nenastavuje. Konkrétně může být užitečné při zadávání značek příjmu dat. Další informace najdete v dokumentaci k ingestování dat v Azure Data. | No |
Příklad:
"activities":[
{
"name": "CopyToAzureDataExplorer",
"type": "Copy",
"typeProperties": {
"source": {
"type": "<source type>"
},
"sink": {
"type": "AzureDataExplorerSink",
"ingestionMappingName": "<optional Azure Data Explorer mapping name>",
"additionalProperties": {<additional settings for data ingestion>}
}
},
"inputs": [
{
"referenceName": "<input dataset name>",
"type": "DatasetReference"
}
],
"outputs": [
{
"referenceName": "<Azure Data Explorer output dataset name>",
"type": "DatasetReference"
}
]
}
]
Mapování vlastností toku dat
Při transformaci dat při mapování toku dat můžete číst a zapisovat do tabulek v Azure Data Exploreru. Další informace najdete v tématu transformace zdroje a transformace jímky v mapování toků dat. Jako typ zdroje a jímky můžete použít datovou sadu Azure Data Exploreru nebo vloženou datovou sadu .
Transformace zdroje
Následující tabulka uvádí vlastnosti podporované zdrojem Azure Data Exploreru. Tyto vlastnosti můžete upravit na kartě Možnosti zdroje.
| Název | Popis | Povinní účastníci | Povolené hodnoty | Vlastnost skriptu toku dat |
|---|---|---|---|---|
| Table | Pokud jako vstup vyberete tabulku, tok dat načte všechna data z tabulky zadané v datové sadě Azure Data Exploreru nebo ve zdrojových možnostech při použití vložené datové sady. | No | String | (pouze pro vloženou datovou sadu) tableName |
| Dotaz | Požadavek jen pro čtení zadaný ve formátu KQL. Jako referenci použijte vlastní dotaz KQL. | No | String | query |
| Timeout | Doba čekání před vypršením časového limitu požadavku dotazu. Výchozí hodnota je 172000 (2 dny) | No | Celé číslo | timeout |
Příklady zdrojového skriptu Azure Data Exploreru
Pokud jako typ zdroje použijete datovou sadu Azure Data Exploreru, přidružený skript toku dat:
source(allowSchemaDrift: true,
validateSchema: false,
query: 'table | take 10',
format: 'query') ~> AzureDataExplorerSource
Pokud používáte vloženou datovou sadu, přidružený skript toku dat je:
source(allowSchemaDrift: true,
validateSchema: false,
format: 'query',
query: 'table | take 10',
store: 'azuredataexplorer') ~> AzureDataExplorerSource
Transformace jímky
Následující tabulka uvádí vlastnosti podporované jímkou Azure Data Exploreru. Tyto vlastnosti můžete upravit na kartě Nastavení . Při použití vložené datové sady se zobrazí další nastavení, která jsou stejná jako vlastnosti popsané v části vlastností datové sady.
| Název | Popis | Povinní účastníci | Povolené hodnoty | Vlastnost skriptu toku dat |
|---|---|---|---|---|
| Akce tabulky | Určuje, zda se mají před zápisem znovu vytvořit nebo odebrat všechny řádky z cílové tabulky. - Žádné: V tabulce se neprovede žádná akce. - Znovu vytvořte: Tabulka se přehodí a znovu vytvoří. Vyžaduje se při dynamickém vytváření nové tabulky. - Zkrácení: Odeberou se všechny řádky z cílové tabulky. |
No | true nebo false |
obnovit truncate |
| Skripty pre a post SQL | Zadejte několik skriptů řídicích příkazů Kusto, které se spustí před (před zpracováním) a po (po zpracování) dat zapisují do databáze jímky. | No | String | preSQLs; postSQLs |
| Timeout | Doba čekání před vypršením časového limitu požadavku dotazu. Výchozí hodnota je 172000 (2 dny) | No | Celé číslo | timeout |
Příklady skriptů jímky Azure Data Exploreru
Pokud jako typ jímky použijete datovou sadu Azure Data Exploreru, přidružený skript toku dat:
IncomingStream sink(allowSchemaDrift: true,
validateSchema: false,
format: 'table',
preSQLs:['pre SQL scripts'],
postSQLs:['post SQL script'],
skipDuplicateMapInputs: true,
skipDuplicateMapOutputs: true) ~> AzureDataExplorerSink
Pokud používáte vloženou datovou sadu, přidružený skript toku dat je:
IncomingStream sink(allowSchemaDrift: true,
validateSchema: false,
format: 'table',
store: 'azuredataexplorer',
skipDuplicateMapInputs: true,
skipDuplicateMapOutputs: true) ~> AzureDataExplorerSink
Vlastnosti aktivity vyhledávání
Související obsah
Seznam úložišť dat, která aktivita kopírování podporuje jako zdroje a jímky, najdete v podporovaných úložištích dat.
Přečtěte si další informace o kopírování dat z Azure Data Factory a Synapse Analytics do Azure Data Exploreru.