Kopírování dat do indexu Azure AI Search pomocí služby Azure Data Factory nebo Synapse Analytics
PLATÍ PRO:  Azure Data Factory Azure Synapse Analytics
Azure Data Factory Azure Synapse Analytics
Tip
Vyzkoušejte si službu Data Factory v Microsoft Fabric, řešení pro analýzy typu all-in-one pro podniky. Microsoft Fabric zahrnuje všechno od přesunu dat až po datové vědy, analýzy v reálném čase, business intelligence a vytváření sestav. Přečtěte si, jak začít používat novou zkušební verzi zdarma.
Tento článek popisuje, jak pomocí aktivity kopírování v kanálu Služby Azure Data Factory nebo Synapse Analytics kopírovat data do indexu služby Azure AI Search. Vychází z článku s přehledem aktivity kopírování, který představuje obecný přehled aktivity kopírování.
Podporované funkce
Tento konektor Azure AI Search je podporovaný pro následující funkce:
| Podporované funkce | IR | Spravovaný privátní koncový bod |
|---|---|---|
| aktivita Copy (-/jímka) | (1) (2) | ✓ |
(1) Prostředí Azure Integration Runtime (2) Místní prostředí Integration Runtime
Do indexu vyhledávání můžete kopírovat data z libovolného podporovaného zdrojového úložiště dat. Seznam úložišť dat podporovaných jako zdroje nebo jímky aktivitou kopírování najdete v tabulce Podporované úložiště dat.
Začínáme
K provedení aktivita Copy s kanálem můžete použít jeden z následujících nástrojů nebo sad SDK:
- Nástroj pro kopírování dat
- Azure Portal
- Sada .NET SDK
- Sada Python SDK
- Azure PowerShell
- Rozhraní REST API
- Šablona Azure Resource Manageru
Vytvoření propojené služby pro Azure Search pomocí uživatelského rozhraní
Pomocí následujících kroků vytvořte propojenou službu pro Azure Search v uživatelském rozhraní webu Azure Portal.
Přejděte na kartu Správa v pracovním prostoru Azure Data Factory nebo Synapse a vyberte Propojené služby a pak klikněte na Nový:
Vyhledejte hledání a vyberte konektor Služby Azure Search.
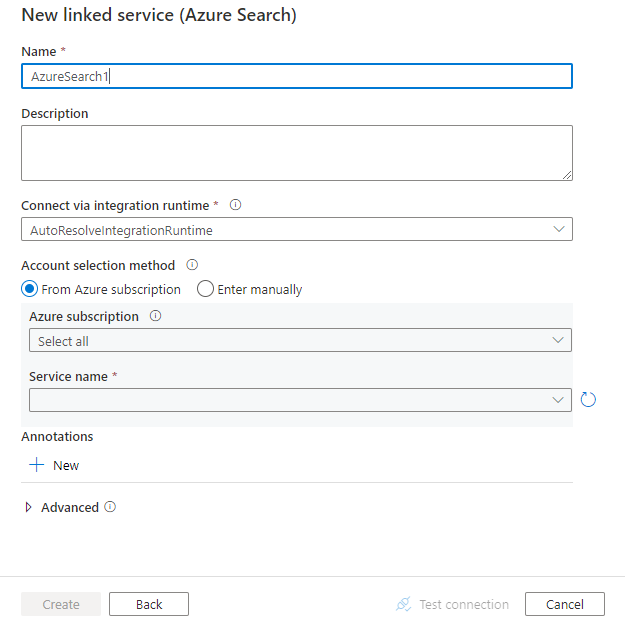
Nakonfigurujte podrobnosti o službě, otestujte připojení a vytvořte novou propojenou službu.
Podrobnosti konfigurace konektoru
Následující části obsahují podrobnosti o vlastnostech, které slouží k definování entit služby Data Factory specifických pro konektor Azure AI Search.
Vlastnosti propojené služby
Propojená služba Azure AI Search podporuje následující vlastnosti:
| Vlastnost | Popis | Povinní účastníci |
|---|---|---|
| type | Vlastnost typu musí být nastavená na: AzureSearch. | Ano |
| url | Adresa URL vyhledávací služby | Ano |
| key | Klíč správce vyhledávací služby. Označte toto pole jako securestring, abyste ho mohli bezpečně uložit, nebo odkazovat na tajný klíč uložený ve službě Azure Key Vault. | Ano |
| connectVia | Prostředí Integration Runtime , které se má použít pro připojení k úložišti dat. Můžete použít prostředí Azure Integration Runtime nebo místní prostředí Integration Runtime (pokud je vaše úložiště dat umístěné v privátní síti). Pokud není zadaný, použije výchozí prostředí Azure Integration Runtime. | No |
Důležité
Při kopírování dat z cloudového úložiště dat do indexu vyhledávání musíte v propojené službě Azure AI Search odkazovat na prostředí Azure Integration Runtime s explicitní oblastí v connactVia. Nastavte oblast jako oblast, ve které se nachází vaše vyhledávací služba. Další informace najdete v prostředí Azure Integration Runtime.
Příklad:
{
"name": "AzureSearchLinkedService",
"properties": {
"type": "AzureSearch",
"typeProperties": {
"url": "https://<service>.search.windows.net",
"key": {
"type": "SecureString",
"value": "<AdminKey>"
}
},
"connectVia": {
"referenceName": "<name of Integration Runtime>",
"type": "IntegrationRuntimeReference"
}
}
}
Vlastnosti datové sady
Úplný seznam oddílů a vlastností dostupných pro definování datových sad najdete v článku o datových sadách . Tato část obsahuje seznam vlastností podporovaných datovou sadou Azure AI Search.
Pokud chcete kopírovat data do služby Azure AI Search, podporují se následující vlastnosti:
| Vlastnost | Popis | Povinní účastníci |
|---|---|---|
| type | Vlastnost typu datové sady musí být nastavená na: AzureSearchIndex. | Ano |
| indexName | Název indexu vyhledávání Služba nevytvoří index. Index musí existovat ve službě Azure AI Search. | Ano |
Příklad:
{
"name": "AzureSearchIndexDataset",
"properties": {
"type": "AzureSearchIndex",
"typeProperties" : {
"indexName": "products"
},
"schema": [],
"linkedServiceName": {
"referenceName": "<Azure AI Search linked service name>",
"type": "LinkedServiceReference"
}
}
}
Vlastnosti aktivity kopírování
Úplný seznam oddílů a vlastností dostupných pro definování aktivit najdete v článku Pipelines . Tato část obsahuje seznam vlastností podporovaných zdrojem služby Azure AI Search.
Azure AI Search jako jímka
Pokud chcete kopírovat data do služby Azure AI Search, nastavte typ zdroje v aktivitě kopírování na AzureSearchIndexSink. V části jímky aktivity kopírování jsou podporovány následující vlastnosti:
| Vlastnost | Popis | Povinní účastníci |
|---|---|---|
| type | Vlastnost typu zdroje aktivity kopírování musí být nastavena na: AzureSearchIndexSink. | Ano |
| writeBehavior | Určuje, zda se má sloučit nebo nahradit, pokud dokument již v indexu existuje. Viz WriteBehavior vlastnost. Povolené hodnoty jsou: Sloučit (výchozí) a Nahrát. |
No |
| writeBatchSize | Nahraje data do indexu vyhledávání, když velikost vyrovnávací paměti dosáhne writeBatchSize. Podrobnosti najdete ve vlastnosti WriteBatchSize. Povolené hodnoty jsou: celé číslo 1 až 1 000; výchozí hodnota je 1000. |
No |
| maxConcurrentConnections | Horní limit souběžných připojení vytvořených k úložišti dat během spuštění aktivity. Zadejte hodnotu pouze v případech, kdy chcete omezit souběžná připojení. | No |
WriteBehavior – vlastnost
AzureSearchSink upsertuje při zápisu dat. Jinými slovy, pokud klíč dokumentu už v indexu vyhledávání existuje, Azure AI Search aktualizuje existující dokument místo vyvolání konfliktní výjimky.
AzureSearchSink poskytuje následující dvě chování upsertu (pomocí sady AzureSearch SDK):
- Sloučení: Zkombinujte všechny sloupce v novém dokumentu s existujícím. U sloupců s hodnotou null v novém dokumentu se hodnota v existujícím dokumentu zachová.
- Nahrání: Nový dokument nahradí existující dokument. U sloupců, které nejsou zadány v novém dokumentu, je hodnota nastavena na hodnotu null, zda je v existujícím dokumentu nenulová hodnota, nebo ne.
Výchozí chování je Sloučit.
WriteBatchSize – vlastnost
Azure AI Search podporuje psaní dokumentů jako dávky. Dávka může obsahovat 1 až 1 000 akcí. Akce zpracovává jeden dokument k provedení operace nahrání/sloučení.
Příklad:
"activities":[
{
"name": "CopyToAzureSearch",
"type": "Copy",
"inputs": [
{
"referenceName": "<input dataset name>",
"type": "DatasetReference"
}
],
"outputs": [
{
"referenceName": "<Azure AI Search output dataset name>",
"type": "DatasetReference"
}
],
"typeProperties": {
"source": {
"type": "<source type>"
},
"sink": {
"type": "AzureSearchIndexSink",
"writeBehavior": "Merge"
}
}
}
]
Podpora datových typů
Následující tabulka určuje, jestli je datový typ Azure AI Search podporovaný, nebo ne.
| Datový typ Azure AI Search | Podporováno v jímce azure AI Search |
|---|---|
| String | Y |
| Int32 | Y |
| Int64 | Y |
| Hodnota s dvojitou přesností | Y |
| Logická hodnota | Y |
| DataTimeOffset | Y |
| Pole řetězců | N |
| GeographyPoint | N |
V současné době se nepodporují jiné datové typy, například ComplexType. Úplný seznam podporovaných datových typů azure AI Search najdete v tématu Podporované datové typy (Azure AI Search).
Související obsah
Seznam úložišť dat podporovaných jako zdroje a jímky aktivitou kopírování najdete v podporovaných úložištích dat.