Zpracování dat spuštěním skriptů U-SQL ve službě Azure Data Lake Analytics pomocí služby Azure Data Factory a Synapse Analytics
PLATÍ PRO:  Azure Data Factory Azure Synapse Analytics
Azure Data Factory Azure Synapse Analytics
Tip
Vyzkoušejte si službu Data Factory v Microsoft Fabric, řešení pro analýzy typu all-in-one pro podniky. Microsoft Fabric zahrnuje všechno od přesunu dat až po datové vědy, analýzy v reálném čase, business intelligence a vytváření sestav. Přečtěte si, jak začít používat novou zkušební verzi zdarma.
Kanál v pracovním prostoru Azure Data Factory nebo Synapse Analytics zpracovává data v propojených službách úložiště pomocí propojených výpočetních služeb. Obsahuje posloupnost aktivit, ve kterých každá aktivita provádí konkrétní operaci zpracování. Tento článek popisuje aktivitu U-SQL služby Data Lake Analytics, která spouští skript U-SQL ve výpočetní propojené službě Azure Data Lake Analytics.
Před vytvořením kanálu s aktivitou U-SQL pro Data Lake Analytics vytvořte účet Azure Data Lake Analytics Analytics. Další informace o Azure Data Lake Analytics najdete v tématu Začínáme s Azure Data Lake Analytics.
Přidání aktivity U-SQL pro Azure Data Lake Analytics do kanálu pomocí uživatelského rozhraní
Pokud chcete v kanálu použít aktivitu U-SQL pro Azure Data Lake Analytics, proveďte následující kroky:
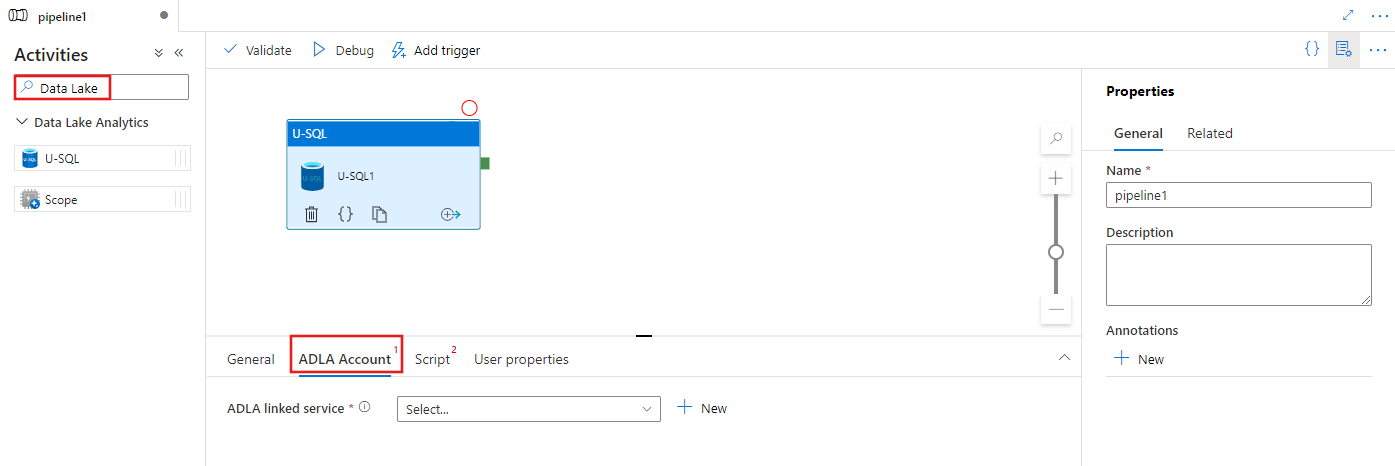
Vyhledejte Data Lake v podokně Aktivity kanálu a přetáhněte aktivitu U-SQL na plátno kanálu.
Pokud ještě není vybraná, vyberte na plátně novou aktivitu U-SQL.
Výběrem karty Účet ADLA vyberte nebo vytvořte novou propojenou službu Azure Data Lake Analytics, která se použije ke spuštění aktivity U-SQL.
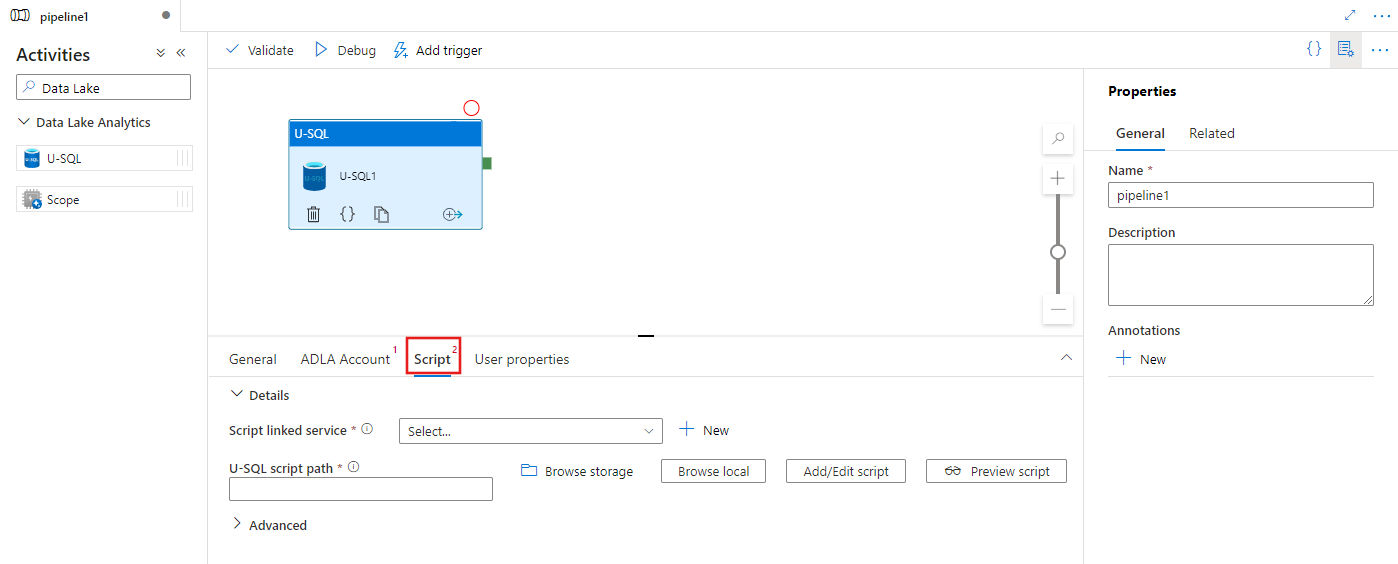
Výběrem karty Skript vyberte nebo vytvořte novou propojenou službu úložiště a cestu v umístění úložiště, která bude hostovat skript.
Propojená služba Azure Data Lake Analytics
Vytvoříte propojenou službu Azure Data Lake Analytics , která propojí výpočetní službu Azure Data Lake Analytics s pracovním prostorem Azure Data Factory nebo Synapse Analytics. Aktivita U-SQL služby Data Lake Analytics v kanálu odkazuje na tuto propojenou službu.
Následující tabulka obsahuje popis obecných vlastností použitých v definici JSON.
| Vlastnost | Popis | Povinní účastníci |
|---|---|---|
| type | Vlastnost typu by měla být nastavena na: AzureDataLakeAnalytics. | Ano |
| accountName | Název účtu Azure Data Lake Analytics | Ano |
| dataLakeAnalyticsUri | Identifikátor URI služby Azure Data Lake Analytics | No |
| subscriptionId | ID předplatného Azure | No |
| resourceGroupName | Název skupiny prostředků Azure | No |
Ověřování instančního objektu
Propojená služba Azure Data Lake Analytics vyžaduje ověření instančního objektu pro připojení ke službě Azure Data Lake Analytics. Pokud chcete použít ověřování instančního objektu, zaregistrujte entitu aplikace v Microsoft Entra ID a udělte jí přístup k Data Lake Analytics i Data Lake Store, které používá. Podrobný postup najdete v tématu Ověřování mezi službami. Poznamenejte si následující hodnoty, které slouží k definování propojené služby:
- ID aplikace
- Klíč aplikace
- ID tenanta
Pomocí Průvodce přidáním uživatele udělte instančnímu objektu oprávnění ke službě Azure Data Lake Analytics.
Ověřování instančního objektu použijte zadáním následujících vlastností:
| Vlastnost | Popis | Povinní účastníci |
|---|---|---|
| servicePrincipalId | Zadejte ID klienta aplikace. | Ano |
| servicePrincipalKey | Zadejte klíč aplikace. | Ano |
| nájemce | Zadejte informace o tenantovi (název domény nebo ID tenanta), pod kterým se vaše aplikace nachází. Můžete ho načíst tak, že narazíte myší v pravém horním rohu webu Azure Portal. | Ano |
Příklad: Ověřování instančního objektu
{
"name": "AzureDataLakeAnalyticsLinkedService",
"properties": {
"type": "AzureDataLakeAnalytics",
"typeProperties": {
"accountName": "<account name>",
"dataLakeAnalyticsUri": "<azure data lake analytics URI>",
"servicePrincipalId": "<service principal id>",
"servicePrincipalKey": {
"value": "<service principal key>",
"type": "SecureString"
},
"tenant": "<tenant info, e.g. microsoft.onmicrosoft.com>",
"subscriptionId": "<optional, subscription id of ADLA>",
"resourceGroupName": "<optional, resource group name of ADLA>"
},
"connectVia": {
"referenceName": "<name of Integration Runtime>",
"type": "IntegrationRuntimeReference"
}
}
}
Další informace o propojené službě najdete v tématu Propojené služby Compute.
Aktivita U-SQL služby Data Lake Analytics
Následující fragment kódu JSON definuje kanál s aktivitou U-SQL Data Lake Analytics. Definice aktivity obsahuje odkaz na propojenou službu Azure Data Lake Analytics, kterou jste vytvořili dříve. Pokud chcete spustit skript U-SQL Data Lake Analytics, služba odešle skript, který jste zadali do Data Lake Analytics, a požadované vstupy a výstupy jsou definovány ve skriptu pro Data Lake Analytics k načtení a výstupu.
{
"name": "ADLA U-SQL Activity",
"description": "description",
"type": "DataLakeAnalyticsU-SQL",
"linkedServiceName": {
"referenceName": "<linked service name of Azure Data Lake Analytics>",
"type": "LinkedServiceReference"
},
"typeProperties": {
"scriptLinkedService": {
"referenceName": "<linked service name of Azure Data Lake Store or Azure Storage which contains the U-SQL script>",
"type": "LinkedServiceReference"
},
"scriptPath": "scripts\\kona\\SearchLogProcessing.txt",
"degreeOfParallelism": 3,
"priority": 100,
"parameters": {
"in": "/datalake/input/SearchLog.tsv",
"out": "/datalake/output/Result.tsv"
}
}
}
Následující tabulka popisuje názvy a popisy vlastností, které jsou specifické pro tuto aktivitu.
| Vlastnost | Popis | Povinní účastníci |
|---|---|---|
| name | Název aktivity v kanálu | Ano |
| description | Text popisující, co aktivita dělá. | No |
| type | U aktivity U-SQL služby Data Lake Analytics je typ aktivity DataLakeAnalyticsU-SQL. | Ano |
| linkedServiceName | Propojená služba s Azure Data Lake Analytics Další informace o této propojené službě najdete v článku o propojených službách Compute. | Ano |
| scriptPath | Cesta ke složce, která obsahuje skript U-SQL V názvu souboru se rozlišují malá a velká písmena. | Ano |
| scriptLinkedService | Propojená služba, která propojila Službu Azure Data Lake Store nebo Azure Storage , která obsahuje skript | Ano |
| degreeOfParallelism | Maximální počet uzlů, které se současně používají ke spuštění úlohy. | No |
| priorita | Určuje, které úlohy ze všech zařazených do fronty mají být vybrány, aby se spustily jako první. Čím nižší je číslo, tím vyšší je priorita. | No |
| parametry | Parametry, které se mají předat do skriptu U-SQL | No |
| runtimeVersion | Verze modulu runtime modulu U-SQL, který se má použít. | No |
| compilationMode | Režim kompilace U-SQL Musí to být jedna z těchto hodnot: Sémantika: Proveďte pouze sémantické kontroly a nezbytné kontroly sanity, Úplné: Proveďte úplnou kompilaci, včetně kontroly syntaxe, optimalizace, generování kódu atd., SingleBox: Proveďte úplnou kompilaci s nastavením TargetType na SingleBox. Pokud pro tuto vlastnost nezadáte hodnotu, server určí optimální režim kompilace. |
No |
Viz SearchLogProcessing.txt definice skriptu.
Ukázkový skript U-SQL
@searchlog =
EXTRACT UserId int,
Start DateTime,
Region string,
Query string,
Duration int,
Urls string,
ClickedUrls string
FROM @in
USING Extractors.Tsv(nullEscape:"#NULL#");
@rs1 =
SELECT Start, Region, Duration
FROM @searchlog
WHERE Region == "en-gb";
@rs1 =
SELECT Start, Region, Duration
FROM @rs1
WHERE Start <= DateTime.Parse("2012/02/19");
OUTPUT @rs1
TO @out
USING Outputters.Tsv(quoting:false, dateTimeFormat:null);
Ve výše uvedeném příkladu skriptu je vstup a výstup skriptu definován v @in a @out parametry. Hodnoty parametrů @in a @out ve skriptu U-SQL se službou předávají dynamicky pomocí oddílu "parameters".
V definici kanálu můžete zadat další vlastnosti, například degreeOfParallelism a prioritu, pro úlohy, které běží ve službě Azure Data Lake Analytics.
Dynamické parametry
V definici ukázkového kanálu jsou parametry in a out přiřazeny pevně zakódovanými hodnotami.
"parameters": {
"in": "/datalake/input/SearchLog.tsv",
"out": "/datalake/output/Result.tsv"
}
Místo toho je možné použít dynamické parametry. Příklad:
"parameters": {
"in": "/datalake/input/@{formatDateTime(pipeline().parameters.WindowStart,'yyyy/MM/dd')}/data.tsv",
"out": "/datalake/output/@{formatDateTime(pipeline().parameters.WindowStart,'yyyy/MM/dd')}/result.tsv"
}
V tomto případě se vstupní soubory stále vybírají ze složky /datalake/input a výstupní soubory se generují ve složce /datalake/output. Názvy souborů jsou dynamické na základě času spuštění okna předávaného při aktivaci kanálu.
Související obsah
Podívejte se na následující články, které vysvětlují, jak transformovat data jinými způsoby: