Transformace dat v cloudu pomocí aktivity Sparku ve službě Azure Data Factory
PLATÍ PRO:  Azure Data Factory
Azure Data Factory  Azure Synapse Analytics
Azure Synapse Analytics
Tip
Vyzkoušejte si službu Data Factory v Microsoft Fabric, řešení pro analýzy typu all-in-one pro podniky. Microsoft Fabric zahrnuje všechno od přesunu dat až po datové vědy, analýzy v reálném čase, business intelligence a vytváření sestav. Přečtěte si, jak začít používat novou zkušební verzi zdarma.
V tomto kurzu vytvoříte pomocí webu Azure Portal kanál služby Azure Data Factory. Tento kanál transformuje data pomocí aktivity Sparku a propojené služby Azure HDInsight na vyžádáni.
V tomto kurzu provedete následující kroky:
- Vytvoření datové továrny
- Vytvoření kanálu využívajícího aktivitu Sparku
- Aktivace spuštění kanálu
- Monitorování spuštění kanálu
Pokud ještě nemáte předplatné Azure, vytvořte si napřed bezplatný účet.
Požadavky
Poznámka:
Při práci s Azure doporučujeme používat modul Azure Az PowerShellu. Pokud chcete začít, přečtěte si téma Instalace Azure PowerShellu. Informace o tom, jak migrovat na modul Az PowerShell, najdete v tématu Migrace Azure PowerShellu z AzureRM na Az.
- Účet služby Azure Storage. Vytvoříte skript Pythonu a vstupní soubor a nahrajete je do Azure Storage. V tomto účtu úložiště se ukládá výstup z programu Sparku. Cluster Spark na vyžádání používá stejný účet úložiště jako primární úložiště.
Poznámka:
HdInsight podporuje jenom účty úložiště pro obecné účely s úrovní Standard. Ujistěte se, že účet úložiště nemá úroveň Premium nebo není určený jenom pro objekty blob.
- Azure PowerShell: Postupujte podle pokynů v tématu Jak nainstalovat a nakonfigurovat Azure PowerShell.
Nahrání skriptu Pythonu do účtu služby Blob Storage
Vytvořte soubor Pythonu s názvem WordCount_Spark.py s následujícím obsahem:
import sys from operator import add from pyspark.sql import SparkSession def main(): spark = SparkSession\ .builder\ .appName("PythonWordCount")\ .getOrCreate() lines = spark.read.text("wasbs://adftutorial@<storageaccountname>.blob.core.windows.net/spark/inputfiles/minecraftstory.txt").rdd.map(lambda r: r[0]) counts = lines.flatMap(lambda x: x.split(' ')) \ .map(lambda x: (x, 1)) \ .reduceByKey(add) counts.saveAsTextFile("wasbs://adftutorial@<storageaccountname>.blob.core.windows.net/spark/outputfiles/wordcount") spark.stop() if __name__ == "__main__": main()Položku <storageAccountName> nahraďte názvem svého účtu služby Azure Storage. Pak soubor uložte.
Ve službě Azure Blob Storage vytvořte kontejner adftutorial, pokud ještě neexistuje.
Vytvořte složku s názvem spark.
Ve složce spark vytvořte dílčí složku s názvem script.
Do podsložky script uložte soubor WordCount_Spark.py.
Nahrání vstupního souboru
- Vytvořte soubor minecraftstory.txt a nějakým textem. Program Sparku spočítá slova v tomto textu.
- Ve složce spark vytvořte dílčí složku s názvem inputfiles.
- Nahrajte do dílčí složky inputfiles soubor minecraftstory.txt.
Vytvoření datové továrny
Postupujte podle kroků v rychlém startu v článku : Vytvoření datové továrny pomocí webu Azure Portal k vytvoření datové továrny, pokud ji ještě nemáte pro práci.
Vytvoření propojených služeb
V této části vytvoříte tyto dvě propojené služby:
- Propojená služba Azure Storage, která propojí účet služby Azure Storage s datovou továrnou. Toto úložiště používá cluster HDInsight na vyžádání. Obsahuje také skript Sparku, který se má spustit.
- Propojená služba HDInsight na vyžádání. Azure Data Factory automaticky vytvoří cluster HDInsight a spustí program Sparku. Až bude cluster HDInsight zadanou dobu nečinný, odstraní ho.
Vytvoření propojené služby Azure Storage
Na domovské stránce přepněte na kartu Spravovat na levém panelu.
Ve spodní části okna vyberte možnost Připojení a potom možnost + Nové.
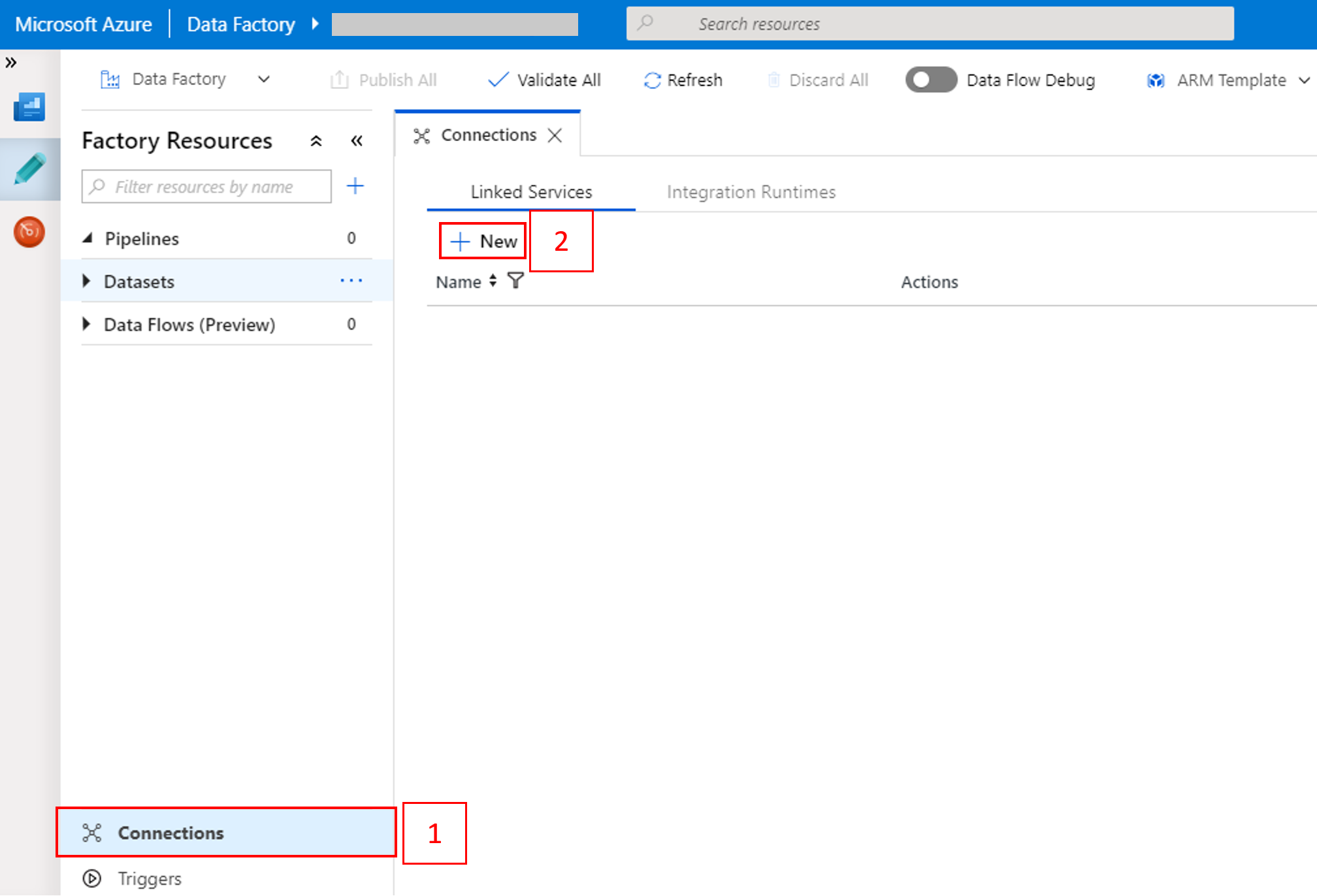
V okně Nová propojená služba vyberte Data Store>Azure Blob Storage a potom vyberte Pokračovat.

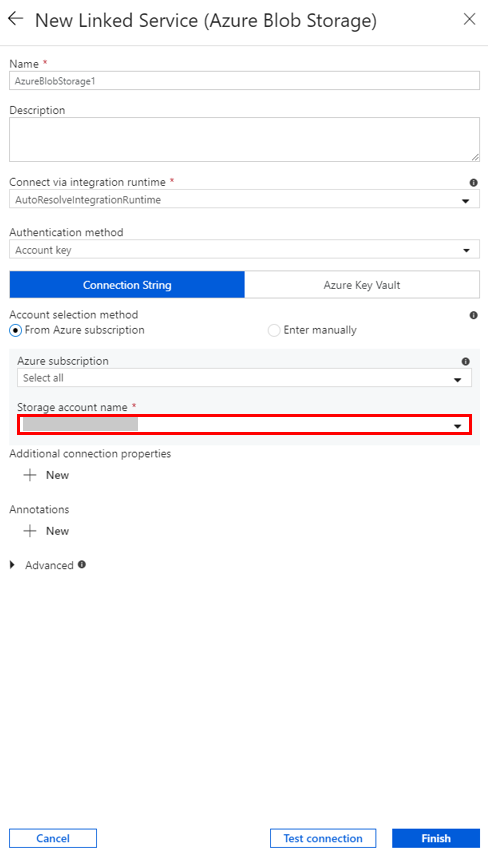
V seznamu v poli Název účtu úložiště vyberte název a potom vyberte Uložit.
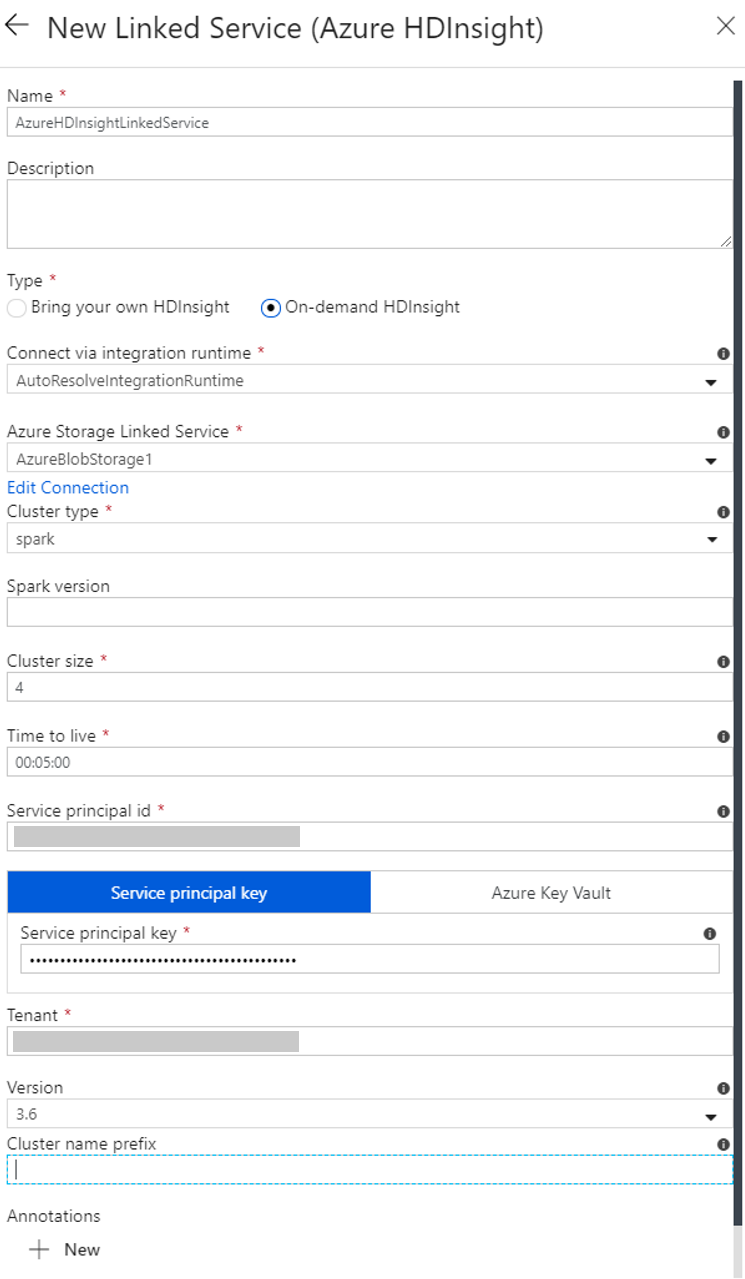
Vytvoření propojené služby HDInsight na vyžádání
Znovu vyberte tlačítko + Nová a vytvořte další propojenou službu.
V okně Nová propojená služba vyberte Compute>Azure HDInsight a potom vyberte Pokračovat.

V okně Nová propojená služba proveďte následující kroky:
a. Do pole Název zadejte AzureHDInsightLinkedService.
b. Ověřte, že je v poli Typ vybraná možnost HDInsight na vyžádání.
c. Pro propojenou službu Azure Storage vyberte AzureBlobStorage1. Tuto propojenou službu jste vytvořili dříve. Pokud jste použili jiný název, zadejte sem správný název.
d. V poli Typ clusteru vyberte spark.
e. V poli ID instančního objektu zadejte ID instančního objektu s oprávněním k vytvoření clusteru HDInsight.
Tento instanční objekt musí být členem role přispěvatele předplatného nebo skupiny prostředků, ve které se cluster vytvoří. Další informace naleznete v tématu Vytvoření aplikace Microsoft Entra a instančního objektu. ID instančního objektu je ekvivalentní ID aplikace a klíč instančního objektu je ekvivalentní hodnotě tajného klíče klienta.
f. Do pole Klíč instančního objektu zadejte klíč.
g. V poli Skupina prostředků vyberte stejnou skupinu prostředků, kterou jste použili při vytváření datové továrny. Cluster Spark se vytvoří v této skupině prostředků.
h. Rozbalte Typ operačního systému.
i. Zadejte Jméno uživatele clusteru.
j. Zadejte Heslo clusteru pro tohoto uživatele.
k. Vyberte Dokončit.
Poznámka:
Azure HDInsight omezuje celkový počet jader, která můžete v jednotlivých podporovaných oblastech Azure použít. V případě propojené služby HDInsight na vyžádání se cluster HDInsight vytvoří ve stejném umístění jako služba Azure Storage, kterou používá jako primární úložiště. Ujistěte se, že máte dostatečné kvóty pro jádra, aby bylo možné cluster úspěšně vytvořit. Další informace najdete v tématu Nastavení clusterů v HDInsight se systémem Hadoop, Spark, Kafka a dalšími.
Vytvořit kanál
Vyberte tlačítko + (plus) a potom v nabídce vyberte Kanál.
Na panelu nástrojů Aktivity rozbalte HDInsight. Přetáhněte aktivitu Spark z panelu nástrojů Aktivity na plochu návrháře kanálu.
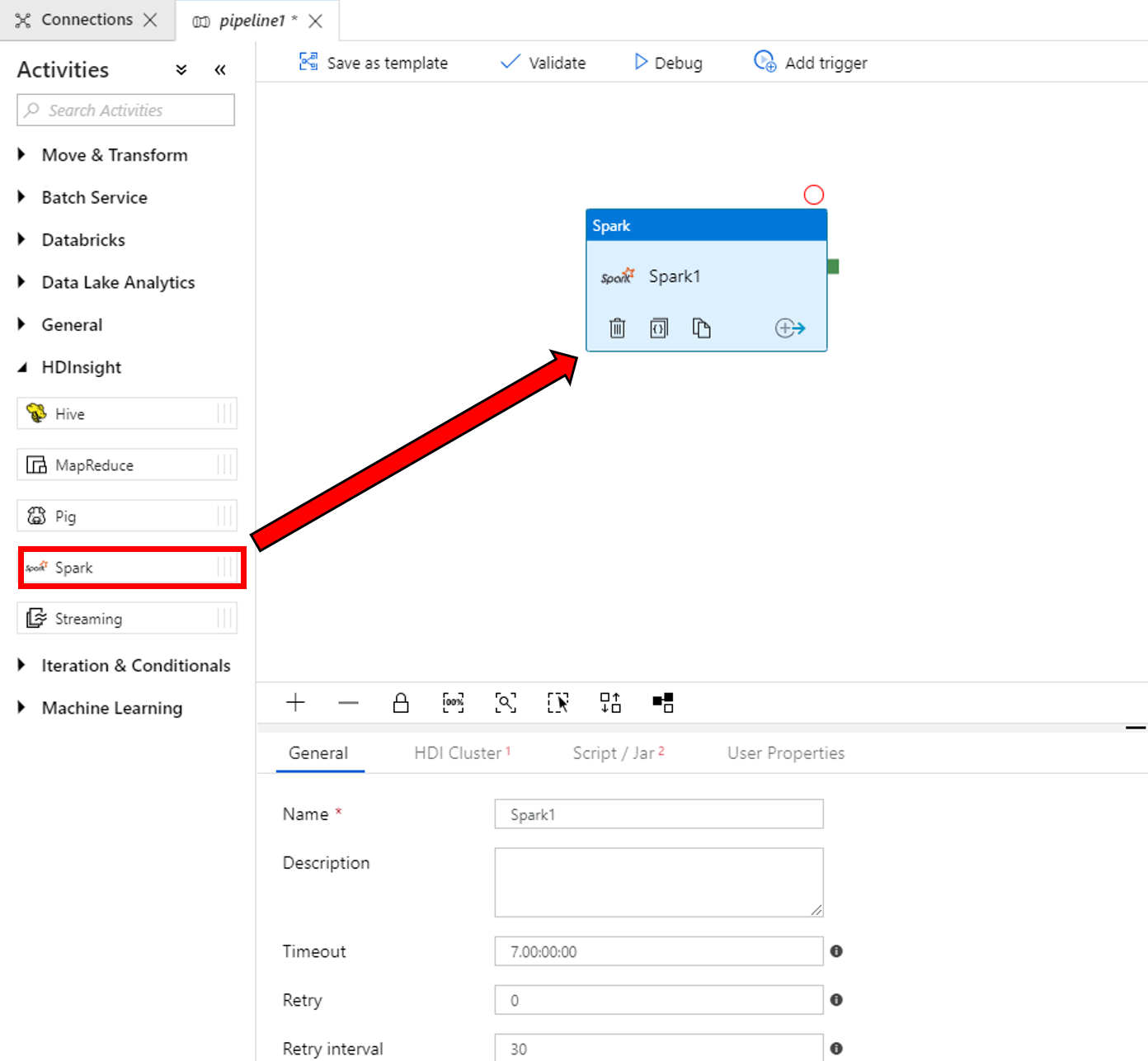
Ve vlastnostech v dolní části okna aktivity Spark proveďte následující kroky:
a. Přepněte na kartu Cluster HDInsight.
b. Vyberte službu AzureHDInsightLinkedService, kterou jste vytvořili v předchozím kroku.
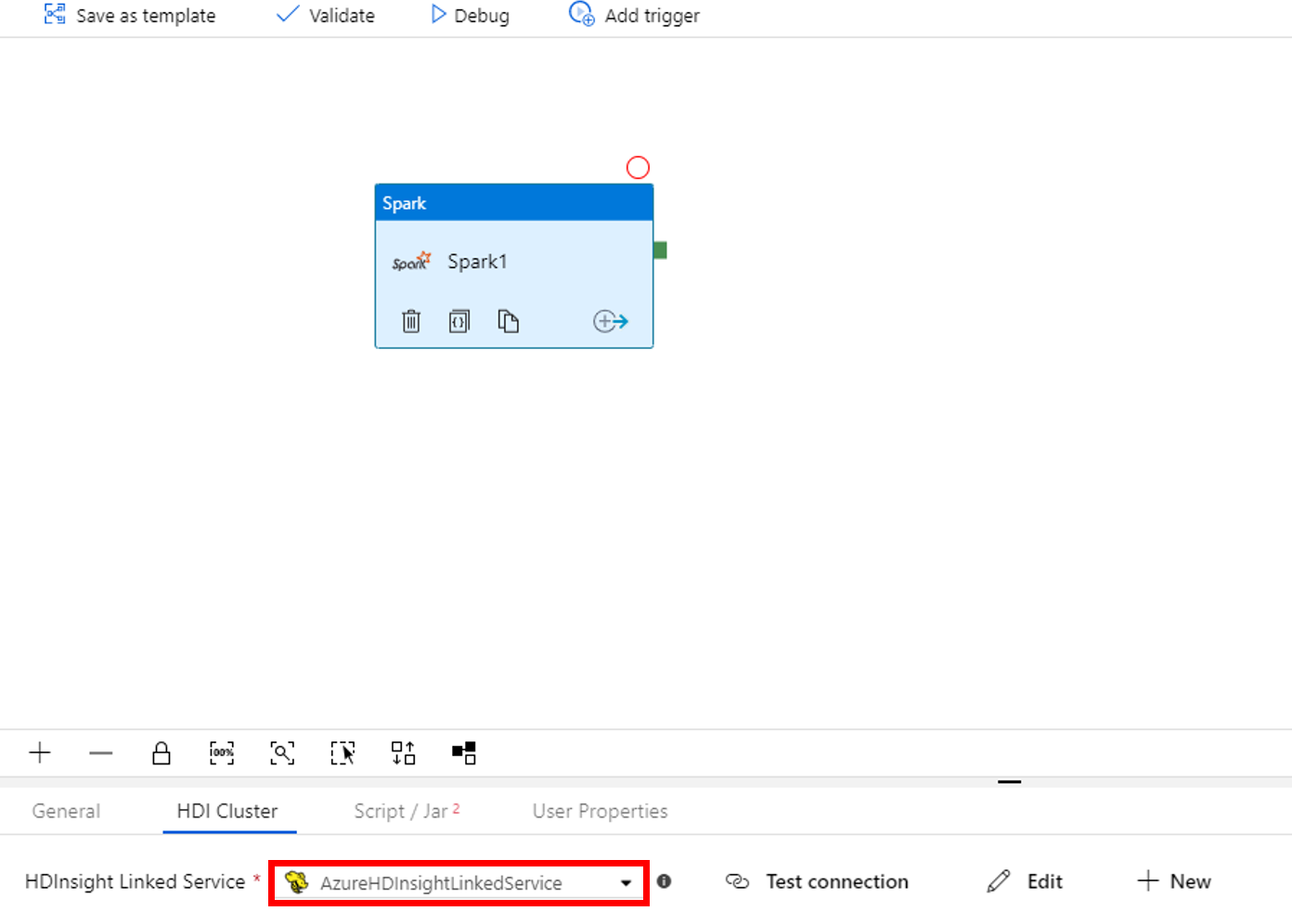
Přepněte na kartu Skripty/Jar a proveďte následující kroky:
a. Jako propojenou službu úlohy vyberte AzureBlobStorage1.
b. Klikněte na Procházet úložiště.

c. Přejděte do složky adftutorial/spark/script, vyberte soubor WordCount_Spark.py a potom vyberte Dokončit.
Pokud chcete kanál ověřit, vyberte tlačítko Ověřit na panelu nástrojů. Výběrem tlačítka >> (šipka doprava) zavřete okno ověřování.

Vyberte Publikovat vše. Uživatelské rozhraní služby Data Factory publikuje entity (propojené služby a kanál) do služby Azure Data Factory.

Aktivace spuštění kanálu
Na panelu nástrojů vyberte Přidat aktivační událost a pak vyberte Aktivovat.

Monitorování spuštění kanálu
Přepněte na kartu Monitorování . Potvrďte, že se zobrazuje spuštění kanálu. Vytvoření clusteru Spark trvá přibližně 20 minut.
Pravidelně klikejte na Aktualizovat a kontrolujte stav spuštění kanálu.
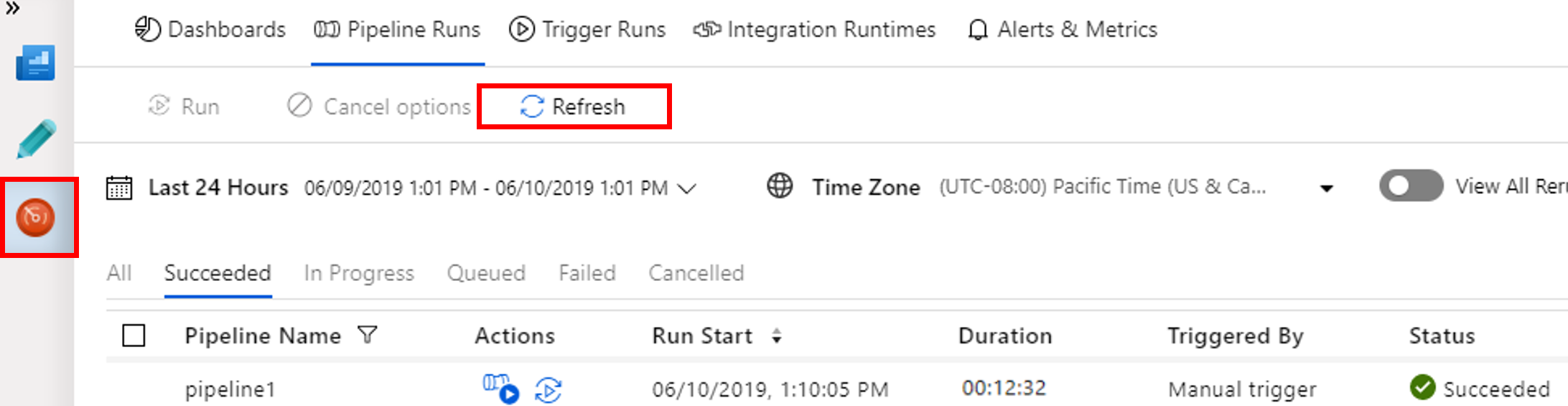
Pokud chcete zobrazit spuštění aktivit související se spuštěním kanálu, vyberte možnost Zobrazit spuštění aktivit ve sloupci Akce.
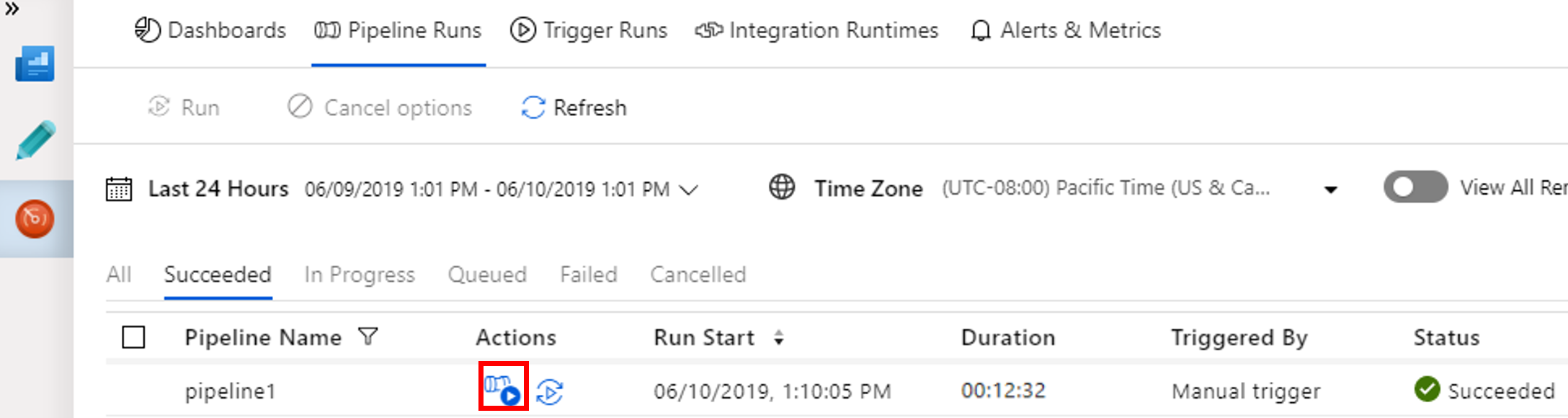
Výběrem odkazu Všechna spuštění kanálu v horní části můžete přepnout zpět do zobrazení spuštění kanálu.

Ověření výstupu
Ověřte, že se ve složce spark/otuputfiles/wordcount kontejneru adftutorial vytvořil výstupní soubor.
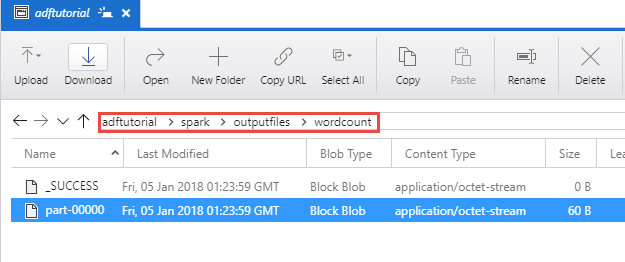
Tento soubor by měl obsahovat všechna slova ze vstupního textového souboru a počet výskytů těchto slov v souboru. Příklad:
(u'This', 1)
(u'a', 1)
(u'is', 1)
(u'test', 1)
(u'file', 1)
Související obsah
Kanál v této ukázce transformuje data pomocí aktivity Sparku a propojené služby HDInsight na vyžádáni. Naučili jste se:
- Vytvoření datové továrny
- Vytvoření kanálu využívajícího aktivitu Sparku
- Aktivace spuštění kanálu
- Monitorování spuštění kanálu
Pokud chcete zjistit, jak transformovat data spuštěním skriptu Hivu v clusteru Azure HDInsight ve virtuální síti, přejděte k následujícímu kurzu: