Jemně odstupňované řízení přístupu na výpočetních prostředcích jednoho uživatele
Tento článek představuje funkci filtrování dat, která umožňuje jemně odstupňované řízení přístupu u dotazů, které běží na výpočetních prostředcích jednoho uživatele (pro všechny účely nebo úlohy nakonfigurované s režimem přístupu jednoho uživatele ). Viz režimy Accessu.
Toto filtrování dat se provádí na pozadí pomocí bezserverového výpočetního prostředí.
Proč některé dotazy na výpočetní prostředky jednoho uživatele vyžadují filtrování dat?
Katalog Unity umožňuje řídit přístup k tabulkovým datům na úrovni sloupců a řádků (označované také jako jemně odstupňované řízení přístupu) pomocí následujících funkcí:
Když se uživatelé dotazují na zobrazení, která vylučují data z odkazovaných tabulek nebo tabulek dotazů, které používají filtry a masky, můžou bez omezení použít některý z následujících výpočetních prostředků:
- SQL Warehouses
- Sdílené výpočetní prostředky
Pokud ale ke spouštění těchto dotazů používáte výpočetní prostředky jednoho uživatele, výpočetní prostředky a pracovní prostor musí splňovat konkrétní požadavky:
Výpočetní prostředek jednoho uživatele musí být ve službě Databricks Runtime 15.4 LTS nebo vyšší.
Pracovní prostor musí být povolený pro bezserverové výpočetní prostředky pro úlohy, poznámkové bloky a tabulky Delta Live.
Informace o tom, že vaše oblast pracovního prostoru podporuje bezserverové výpočetní prostředky, najdete v tématu Funkce s omezenou regionální dostupností.
Pokud váš výpočetní prostředek a pracovní prostor jednoho uživatele splňuje tyto požadavky, spustí se filtrování dat automaticky při každém dotazování na zobrazení nebo tabulku, která používá jemně odstupňované řízení přístupu.
Podpora materializovaných zobrazení, streamovaných tabulek a standardních zobrazení
Kromě dynamických zobrazení, filtrů řádků a masek sloupců umožňuje filtrování dat také dotazy na následující zobrazení a tabulky, které nejsou podporovány na výpočetních prostředcích jednoho uživatele, na kterých běží Databricks Runtime 15.3 a níže:
-
Na výpočetních prostředcích jednoho uživatele, na kterých běží Databricks Runtime 15.3 a níže, musí
SELECTmít uživatel, který spouští dotaz v zobrazení, v tabulkách a zobrazeních odkazovaných v zobrazení, což znamená, že zobrazení nemůžete použít k zajištění podrobného řízení přístupu. V Databricks Runtime 15.4 s filtrováním dat nepotřebuje uživatel, který se dotazuje zobrazení, přístup k odkazovaným tabulkám a zobrazením.
Jak funguje filtrování dat na výpočetních prostředcích jednoho uživatele?
Pokaždé, když dotaz přistupuje k následujícím databázovým objektům, jeden výpočetní prostředek uživatele předá dotaz společně s bezserverovým výpočetním prostředím za účelem filtrování dat:
- Zobrazení sestavená přes tabulky, u kterých uživatel nemá
SELECToprávnění - Dynamická zobrazení
- Tabulky s definovanými filtry řádků nebo maskami sloupců
- Materializovaná zobrazení a streamované tabulky
V následujícím diagramu má SELECT uživatel zapnutý table_1view_2, a table_w_rls, který má použité filtry řádků. Uživatel nemá SELECT zapnutý table_2, na který odkazuje view_2.

Dotaz se table_1 zpracovává výhradně výpočetním prostředkem jednoho uživatele, protože není vyžadováno žádné filtrování. Dotazy na view_2 data a table_w_rls vyžadují filtrování dat, aby vrátila data, ke kterým má uživatel přístup. Tyto dotazy zpracovává funkce filtrování dat na bezserverových výpočetních prostředcích.
Jaké náklady vzniknou?
Zákazníci se účtují za výpočetní prostředky bez serveru, které se používají k provádění operací filtrování dat. Informace o cenách najdete v tématu Úrovně platformy a doplňky.
Dotazem na tabulku využití fakturace systému můžete zjistit, kolik se vám účtovalo. Například následující dotaz rozdělí náklady na výpočetní prostředky podle uživatele:
SELECT usage_date,
sku_name,
identity_metadata.run_as,
SUM(usage_quantity) AS `DBUs consumed by FGAC`
FROM system.billing.usage
WHERE usage_date BETWEEN '2024-08-01' AND '2024-09-01'
AND billing_origin_product = 'FINE_GRAINED_ACCESS_CONTROL'
GROUP BY 1, 2, 3 ORDER BY 1;
Zobrazení výkonu dotazů při zapojení filtrování dat
Uživatelské rozhraní Sparku pro výpočetní prostředky s jedním uživatelem zobrazuje metriky, které můžete použít k pochopení výkonu dotazů. Pro každý dotaz, který spustíte na výpočetním prostředku, zobrazí karta SQL/Dataframe reprezentaci grafu dotazu. Pokud byl dotaz zapojen do filtrování dat, uživatelské rozhraní zobrazí uzel operátoru RemoteSparkConnectScan v dolní části grafu. Tento uzel zobrazuje metriky, které můžete použít k prozkoumání výkonu dotazů. Viz Zobrazení informací o výpočetních prostředcích v uživatelském rozhraní Apache Sparku.
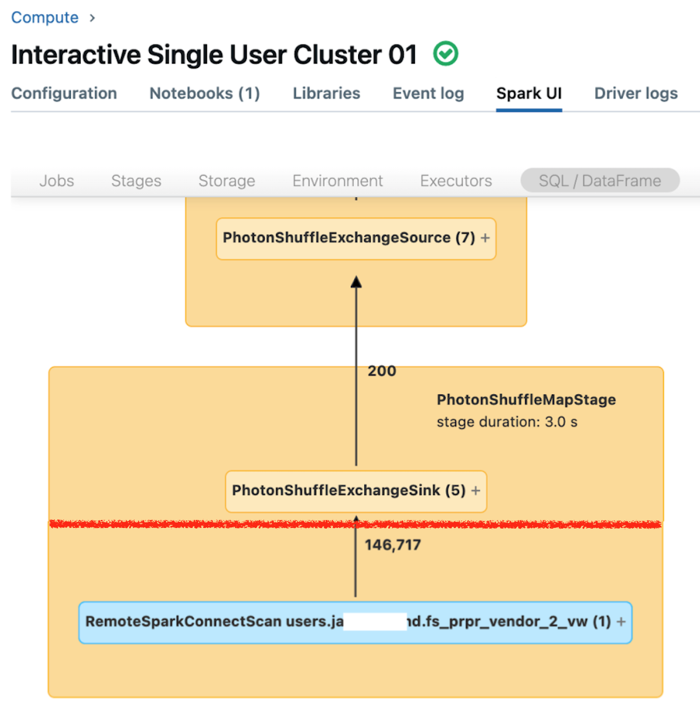
Rozbalte uzel operátoru RemoteSparkConnectScan a zobrazte metriky, které řeší například následující otázky:
- Kolik času trvalo filtrování dat? Zobrazit "celkový čas vzdáleného spuštění".
- Kolik řádků zůstalo po filtrování dat? Zobrazit "výstup řádků".
- Kolik dat (v bajtech) bylo vráceno po filtrování dat? Zobrazit "velikost výstupu řádků".
- Kolik datovýchsouborůch Zobrazit "Soubory vyřazené" a "Velikost souborů vyříznutých".
- Kolik datových souborů nebylo možné vyříznout a muselo být načteno z úložiště? Zobrazení "Čtení souborů" a "Velikost přečtených souborů".
- Z souborů, které se musely číst, kolik už bylo v mezipaměti? Zobrazení "Velikost přístupů do mezipaměti" a "Velikost zmeškaných mezipamětí".
Omezení
U tabulek s použitými filtry řádků nebo maskami sloupců není podporována operace zápisu nebo aktualizace tabulek.
Konkrétně se nepodporují operace DML, například
INSERT,DELETE,UPDATEREFRESH TABLE, aMERGE, . Z těchto tabulek můžete jen číst (SELECT).Při zavolání filtrování dat se ve výchozím nastavení zablokují spojení sama, ale můžete je povolit nastavením
spark.databricks.remoteFiltering.blockSelfJoinsna false na výpočetních prostředcích, na kterých tyto příkazy spouštíte.Než povolíte samoobslužná spojení u jednoho výpočetního prostředku uživatele, mějte na paměti, že dotaz samoobslužného spojení zpracovávaný funkcí filtrování dat by mohl vracet různé snímky stejné vzdálené tabulky.