Modely v příkladu katalogu Unity
Tento příklad ukazuje, jak pomocí modelů v katalogu Unity sestavit aplikaci strojového učení, která předpovídá denní výkon větrné farmy. Příklad ukazuje, jak:
- Sledujte a protokolujte modely pomocí MLflow.
- Zaregistrujte modely do katalogu Unity.
- Popis modelů a jejich nasazení pro odvozování pomocí aliasů
- Integrace registrovaných modelů s produkčními aplikacemi
- Vyhledávání a zjišťování modelů v katalogu Unity
- Odstraňte modely.
Tento článek popisuje, jak provést tyto kroky pomocí sledování a modelů MLflow v uživatelských rozhraních a rozhraních API katalogu Unity.
Požadavky
Ujistěte se, že splňujete všechny požadavky v části Požadavky. Příklady kódu v tomto článku navíc předpokládají, že máte následující oprávnění:
USE CATALOGoprávnění vmainkatalogu.CREATE MODELaUSE SCHEMAoprávnění ke schématumain.default.
Poznámkový blok
Veškerý kód v tomto článku najdete v následujícím poznámkovém bloku.
Modely v ukázkovém poznámkovém bloku katalogu Unity
Instalace klienta Pythonu MLflow
Tento příklad vyžaduje klienta Pythonu MLflow verze 2.5.0 nebo vyšší a TensorFlow. Do horní části poznámkového bloku přidejte následující příkazy, které tyto závislosti nainstalují.
%pip install --upgrade "mlflow-skinny[databricks]>=2.5.0" tensorflow
dbutils.library.restartPython()
Načtení datové sady, trénování modelu a registrace do katalogu Unity
Tato část ukazuje, jak načíst datovou sadu farmy větru, vytrénovat model a zaregistrovat ho do katalogu Unity. Spuštění trénování modelu a metriky se sledují při spuštění experimentu.
Načtení datové sady
Následující kód načte datovou sadu obsahující informace o počasí a výstupu napájení pro větrnou farmu v USA. Datová sada obsahuje wind direction, wind speeda air temperature funkce vzorkované každých šest hodin (jednou na 00:00, najednou 08:00a jednou na 16:00), stejně jako denní agregační výkon (power) za několik let.
import pandas as pd
wind_farm_data = pd.read_csv("https://github.com/dbczumar/model-registry-demo-notebook/raw/master/dataset/windfarm_data.csv", index_col=0)
def get_training_data():
training_data = pd.DataFrame(wind_farm_data["2014-01-01":"2018-01-01"])
X = training_data.drop(columns="power")
y = training_data["power"]
return X, y
def get_validation_data():
validation_data = pd.DataFrame(wind_farm_data["2018-01-01":"2019-01-01"])
X = validation_data.drop(columns="power")
y = validation_data["power"]
return X, y
def get_weather_and_forecast():
format_date = lambda pd_date : pd_date.date().strftime("%Y-%m-%d")
today = pd.Timestamp('today').normalize()
week_ago = today - pd.Timedelta(days=5)
week_later = today + pd.Timedelta(days=5)
past_power_output = pd.DataFrame(wind_farm_data)[format_date(week_ago):format_date(today)]
weather_and_forecast = pd.DataFrame(wind_farm_data)[format_date(week_ago):format_date(week_later)]
if len(weather_and_forecast) < 10:
past_power_output = pd.DataFrame(wind_farm_data).iloc[-10:-5]
weather_and_forecast = pd.DataFrame(wind_farm_data).iloc[-10:]
return weather_and_forecast.drop(columns="power"), past_power_output["power"]
Konfigurace klienta MLflow pro přístup k modelům v katalogu Unity
Klient Pythonu MLflow ve výchozím nastavení vytváří modely v registru modelů pracovního prostoru v Azure Databricks. Pokud chcete upgradovat na modely v katalogu Unity, nakonfigurujte klienta pro přístup k modelům v katalogu Unity:
import mlflow
mlflow.set_registry_uri("databricks-uc")
Trénování a registrace modelu
Následující kód trénuje neurální síť pomocí TensorFlow Kerasu k predikci výstupu napájení na základě funkcí počasí v datové sadě a pomocí rozhraní API MLflow zaregistruje fitovaný model do katalogu Unity.
from tensorflow.keras.models import Sequential
from tensorflow.keras.layers import Dense
MODEL_NAME = "main.default.wind_forecasting"
def train_and_register_keras_model(X, y):
with mlflow.start_run():
model = Sequential()
model.add(Dense(100, input_shape=(X.shape[-1],), activation="relu", name="hidden_layer"))
model.add(Dense(1))
model.compile(loss="mse", optimizer="adam")
model.fit(X, y, epochs=100, batch_size=64, validation_split=.2)
example_input = X[:10].to_numpy()
mlflow.tensorflow.log_model(
model,
artifact_path="model",
input_example=example_input,
registered_model_name=MODEL_NAME
)
return model
X_train, y_train = get_training_data()
model = train_and_register_keras_model(X_train, y_train)
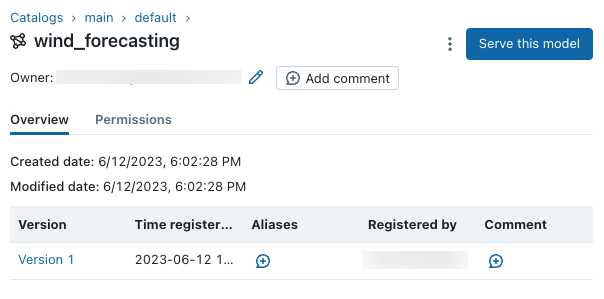
Zobrazení modelu v uživatelském rozhraní
Registrované modely a verze modelů můžete zobrazit a spravovat v katalogu Unity pomocí Průzkumníka katalogu. Vyhledejte model, který jste právě vytvořili v katalogu a default schématumain.
Nasazení verze modelu pro odvozování
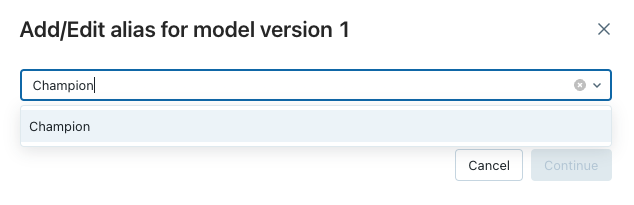
Modely v katalogu Unity podporují aliasy pro nasazení modelu. Aliasy poskytují proměnlivé pojmenované odkazy (například Šampion nebo Challenger) na konkrétní verzi registrovaného modelu. Na verze cílového modelu můžete odkazovat a používat tyto aliasy v pracovních postupech odvozování podřízených dat.
Jakmile přejdete do registrovaného modelu v Průzkumníku katalogu, kliknutím pod sloupec Aliases přiřaďte alias "Champion" k nejnovější verzi modelu a stisknutím klávesy Continue (Pokračovat) uložte změny.
Načtení verzí modelu pomocí rozhraní API
Komponenta MLflow Models definuje funkce pro načítání modelů z několika architektur strojového učení. Slouží například mlflow.tensorflow.load_model() k načtení modelů TensorFlow uložených ve formátu MLflow a mlflow.sklearn.load_model() slouží k načtení modelů scikit-learn uložených ve formátu MLflow.
Tyto funkce můžou načítat modely z modelů v katalogu Unity.
import mlflow.pyfunc
model_version_uri = "models:/{model_name}/1".format(model_name=MODEL_NAME)
print("Loading registered model version from URI: '{model_uri}'".format(model_uri=model_version_uri))
model_version_1 = mlflow.pyfunc.load_model(model_version_uri)
model_champion_uri = "models:/{model_name}@Champion".format(model_name=MODEL_NAME)
print("Loading registered model version from URI: '{model_uri}'".format(model_uri=model_champion_uri))
champion_model = mlflow.pyfunc.load_model(model_champion_uri)
Prognózování výkonu pomocí modelu šampionů
V této části se model šampionů používá k vyhodnocení dat předpovědi počasí pro větrnou farmu. Aplikace forecast_power() načte nejnovější verzi modelu prognózování ze zadané fáze a použije ji k prognózování výroby energie během následujících pěti dnů.
from mlflow.tracking import MlflowClient
def plot(model_name, model_alias, model_version, power_predictions, past_power_output):
import matplotlib.dates as mdates
from matplotlib import pyplot as plt
index = power_predictions.index
fig = plt.figure(figsize=(11, 7))
ax = fig.add_subplot(111)
ax.set_xlabel("Date", size=20, labelpad=20)
ax.set_ylabel("Power\noutput\n(MW)", size=20, labelpad=60, rotation=0)
ax.tick_params(axis='both', which='major', labelsize=17)
ax.xaxis.set_major_formatter(mdates.DateFormatter('%m/%d'))
ax.plot(index[:len(past_power_output)], past_power_output, label="True", color="red", alpha=0.5, linewidth=4)
ax.plot(index, power_predictions.squeeze(), "--", label="Predicted by '%s'\nwith alias '%s' (Version %d)" % (model_name, model_alias, model_version), color="blue", linewidth=3)
ax.set_ylim(ymin=0, ymax=max(3500, int(max(power_predictions.values) * 1.3)))
ax.legend(fontsize=14)
plt.title("Wind farm power output and projections", size=24, pad=20)
plt.tight_layout()
display(plt.show())
def forecast_power(model_name, model_alias):
import pandas as pd
client = MlflowClient()
model_version = client.get_model_version_by_alias(model_name, model_alias).version
model_uri = "models:/{model_name}@{model_alias}".format(model_name=MODEL_NAME, model_alias=model_alias)
model = mlflow.pyfunc.load_model(model_uri)
weather_data, past_power_output = get_weather_and_forecast()
power_predictions = pd.DataFrame(model.predict(weather_data))
power_predictions.index = pd.to_datetime(weather_data.index)
print(power_predictions)
plot(model_name, model_alias, int(model_version), power_predictions, past_power_output)
forecast_power(MODEL_NAME, "Champion")
Přidání popisů verzí modelu a modelu pomocí rozhraní API
Kód v této části ukazuje, jak můžete přidat popisy verzí modelu a modelu pomocí rozhraní API MLflow.
client = MlflowClient()
client.update_registered_model(
name=MODEL_NAME,
description="This model forecasts the power output of a wind farm based on weather data. The weather data consists of three features: wind speed, wind direction, and air temperature."
)
client.update_model_version(
name=MODEL_NAME,
version=1,
description="This model version was built using TensorFlow Keras. It is a feed-forward neural network with one hidden layer."
)
Vytvoření nové verze modelu
Klasické techniky strojového učení jsou také efektivní pro prognózování výkonu. Následující kód trénuje náhodný model doménové struktury pomocí knihovny scikit-learn a zaregistruje ho do katalogu Unity pomocí mlflow.sklearn.log_model() funkce.
import mlflow.sklearn
from sklearn.ensemble import RandomForestRegressor
from sklearn.metrics import mean_squared_error
with mlflow.start_run():
n_estimators = 300
mlflow.log_param("n_estimators", n_estimators)
rand_forest = RandomForestRegressor(n_estimators=n_estimators)
rand_forest.fit(X_train, y_train)
val_x, val_y = get_validation_data()
mse = mean_squared_error(rand_forest.predict(val_x), val_y)
print("Validation MSE: %d" % mse)
mlflow.log_metric("mse", mse)
example_input = val_x.iloc[[0]]
# Specify the `registered_model_name` parameter of the `mlflow.sklearn.log_model()`
# function to register the model to <UC>. This automatically
# creates a new model version
mlflow.sklearn.log_model(
sk_model=rand_forest,
artifact_path="sklearn-model",
input_example=example_input,
registered_model_name=MODEL_NAME
)
Načtení čísla nové verze modelu
Následující kód ukazuje, jak načíst nejnovější číslo verze modelu pro název modelu.
client = MlflowClient()
model_version_infos = client.search_model_versions("name = '%s'" % MODEL_NAME)
new_model_version = max([model_version_info.version for model_version_info in model_version_infos])
Přidání popisu do nové verze modelu
client.update_model_version(
name=MODEL_NAME,
version=new_model_version,
description="This model version is a random forest containing 100 decision trees that was trained in scikit-learn."
)
Označení nové verze modelu jako Challenger a otestování modelu
Před nasazením modelu pro obsluhu produkčního provozu je osvědčeným postupem ho otestovat na vzorku produkčních dat. Dříve jste použili alias Champion k označení verze modelu, která obsluhuje většinu produkčních úloh. Následující kód přiřadí alias Challenger nové verzi modelu a vyhodnotí jeho výkon.
client.set_registered_model_alias(
name=MODEL_NAME,
alias="Challenger",
version=new_model_version
)
forecast_power(MODEL_NAME, "Challenger")
Nasazení nové verze modelu jako verze modelu Champion
Po ověření, že nová verze modelu funguje dobře v testech, přiřadí následující kód alias "Champion" k nové verzi modelu a použije stejný kód aplikace z výstupu výkonu prognózy s částí modelu šampionů k vytvoření prognózy výkonu.
client.set_registered_model_alias(
name=MODEL_NAME,
alias="Champion",
version=new_model_version
)
forecast_power(MODEL_NAME, "Champion")
Nyní existují dvě verze modelu prognózování: verze modelu trénovaná v modelu Keras a verze trénovaná v scikit-learn. Všimněte si, že alias "Challenger" zůstává přiřazený nové verzi modelu scikit-learn, takže všechny podřízené úlohy, které cílí na verzi modelu "Challenger", budou nadále úspěšně spuštěny:
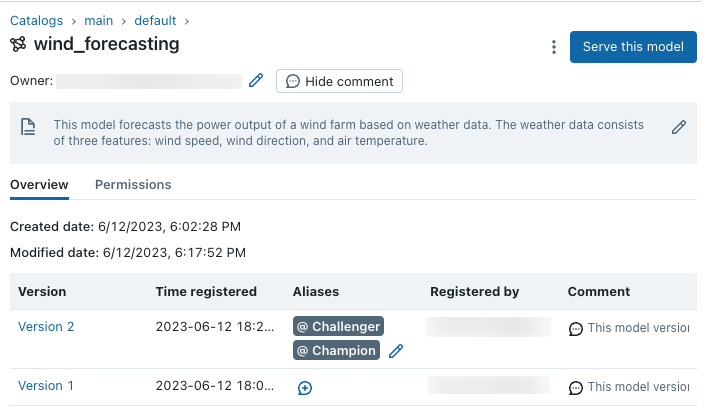
Odstranění modelů
Pokud už verzi modelu nepoužíváte, můžete ji odstranit. Můžete také odstranit celý registrovaný model; tím se odeberou všechny přidružené verze modelu. Odstranění verze modelu vymaže všechny aliasy přiřazené k verzi modelu.
Odstranění Version 1 pomocí rozhraní API MLflow
client.delete_model_version(
name=MODEL_NAME,
version=1,
)
Odstranění modelu pomocí rozhraní API MLflow
client = MlflowClient()
client.delete_registered_model(name=MODEL_NAME)