Výpočetní prostředky poznámkového bloku
Tento článek popisuje možnosti výpočetních prostředků poznámkového bloku. Poznámkový blok můžete spustit v clusteru Databricks, bezserverovém výpočetním prostředí nebo pro příkazy SQL použít SQL Warehouse, typ výpočetních prostředků optimalizovaný pro analýzu SQL.
Výpočetní prostředí bez serveru pro poznámkové bloky
Bezserverové výpočetní prostředky umožňují rychle připojit poznámkový blok k výpočetním prostředkům na vyžádání.
Pokud se chcete připojit k bezserverovému výpočetnímu prostředí, klikněte v poznámkovém bloku na rozevírací nabídku Připojit a vyberte Bezserverový.
Další informace najdete v tématu Bezserverové výpočetní prostředky pro poznámkové bloky .
Připojení poznámkového bloku ke clusteru
Pokud chcete připojit poznámkový blok ke clusteru, potřebujete oprávnění PŘIPOJIT K úrovni clusteru.
Důležité
Pokud je poznámkový blok připojený ke clusteru, má každý uživatel s oprávněním CAN RUN v poznámkovém bloku implicitní oprávnění pro přístup ke clusteru.
Pokud chcete připojit poznámkový blok ke clusteru, klikněte na výběr výpočetních prostředků na panelu nástrojů poznámkového bloku a v rozevírací nabídce vyberte cluster.
V nabídce se zobrazí výběr clusterů, které jste nedávno použili nebo které právě běží.
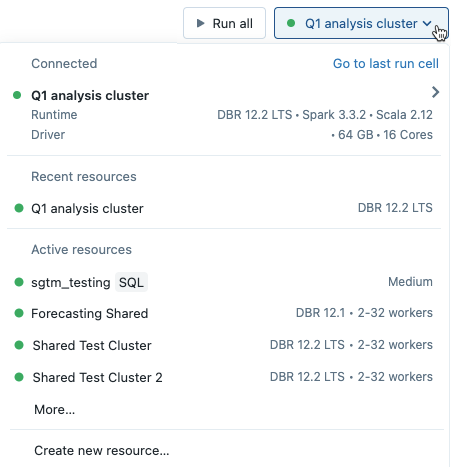
Pokud chcete vybrat ze všech dostupných clusterů, klikněte na Další.... Kliknutím na název clusteru zobrazte rozevírací nabídku a vyberte existující cluster.
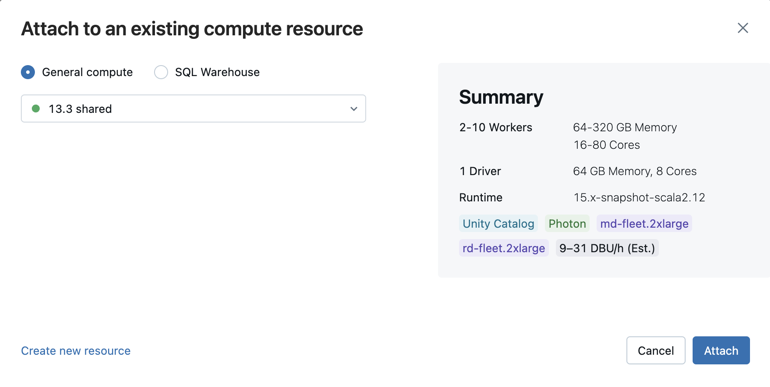
Nový cluster můžete vytvořit také výběrem možnosti Vytvořit nový prostředek... z rozevírací nabídky.
Důležité
Připojený poznámkový blok má definované následující proměnné Apache Sparku.
| Třída | Název proměnné |
|---|---|
SparkContext |
sc |
SQLContext/HiveContext |
sqlContext |
SparkSession (Spark 2.x) |
spark |
Nevytvádřujte , SparkSessionSparkContextnebo SQLContext. To povede k nekonzistentnímu chování.
Použití poznámkového bloku se službou SQL Warehouse
Když je poznámkový blok připojený ke službě SQL Warehouse, můžete spouštět buňky SQL a Markdown. Spuštění buňky v jakémkoli jiném jazyce (například Python nebo R) vyvolá chybu. Buňky SQL spuštěné ve službě SQL Warehouse se zobrazují v historii dotazů SQL Warehouse. Uživatel, který spustil dotaz, může zobrazit profil dotazu z poznámkového bloku kliknutím na uplynulý čas v dolní části výstupu.
Spuštění poznámkového bloku vyžaduje profesionální nebo bezserverový SQL Warehouse. Musíte mít přístup k pracovnímu prostoru a SQL Warehouse.
Pokud chcete k SQL Warehouse připojit poznámkový blok, postupujte takto:
Na panelu nástrojů poznámkového bloku klikněte na selektor výpočetních prostředků. V rozevírací nabídce se zobrazují výpočetní prostředky, které jsou aktuálně spuštěné nebo které jste nedávno použili. Sklady SQL jsou označené značkou
 .
.V nabídce vyberte SQL Warehouse.
Pokud chcete zobrazit všechny dostupné sklady SQL, v rozevírací nabídce vyberte Další... Zobrazí se dialogové okno s výpočetními prostředky dostupnými pro poznámkový blok. Vyberte SQL Warehouse, zvolte sklad, který chcete použít, a klikněte na Připojit.
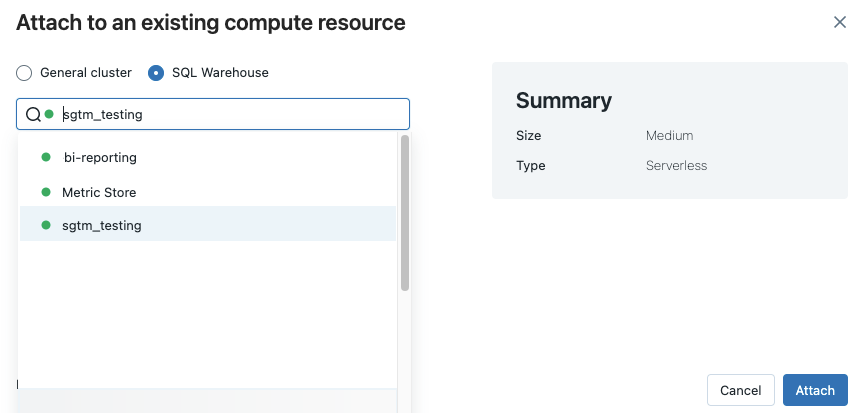
Při vytváření pracovního postupu nebo naplánované úlohy můžete také jako výpočetní prostředek pro poznámkový blok SQL vybrat SQL Warehouse.
Omezení SQL Warehouse
Další informace najdete v poznámkových blocích Databricks se známými omezeními .
Odpojení poznámkového bloku
Pokud chcete odpojit poznámkový blok od výpočetního prostředku, klikněte na výběr výpočetních prostředků na panelu nástrojů poznámkového bloku a najeďte myší na připojený cluster nebo SQL Warehouse v seznamu, aby se zobrazila boční nabídka. V boční nabídce vyberte Odpojit.
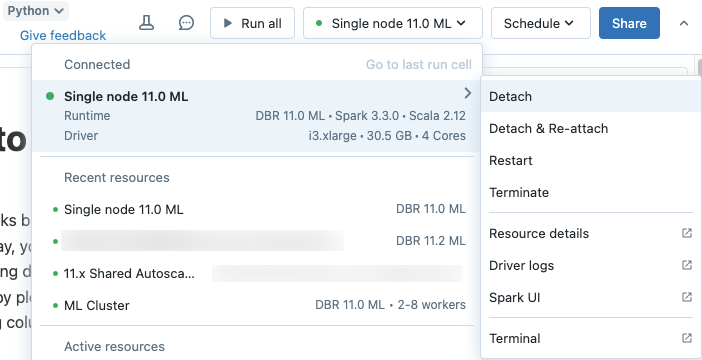
Poznámkové bloky můžete také odpojit od clusteru pomocí karty Poznámkové bloky na stránce podrobností clusteru.
Tip
Azure Databricks doporučuje odpojit nepoužívané poznámkové bloky z clusterů. Tím se uvolní místo v paměti ovladače.