Kurz: Použití strukturovaného streamování Apache Sparku se systémem Apache Kafka ve službě HDInsight
Tento kurz ukazuje, jak pomocí strukturovaného streamování Apache Sparku číst a zapisovat data pomocí Apache Kafka ve službě Azure HDInsight.
Strukturované streamování Sparku je modul pro zpracování datových proudů založený na Spark SQL. Umožňuje zrychlit streamované i dávkové výpočty se statickými daty.
V tomto kurzu se naučíte:
- Vytvoření clusterů pomocí šablony Azure Resource Manageru
- Použití strukturovaného streamování Sparku se systémem Kafka
Až budete s kroky v tomto dokumentu hotovi, nezapomeňte clustery odstranit, abyste se vyhnuli nadbytečným poplatkům.
Požadavky
jq, procesor JSON příkazového řádku. Viz třída https://stedolan.github.io/jq/.
Znalost používání poznámkových bloků Jupyter se Sparkem ve službě HDInsight Další informace najdete v tématu Načítání dat a spouštění dotazů pomocí Apache Sparku v dokumentu HDInsight .
Znalost programovacího jazyku Scala. Kód použitý v tomto kurzu je napsaný v jazyce Scala.
Znalost vytváření témat Kafka. Další informace najdete v dokumentu Rychlého startu Apache Kafka ve službě HDInsight.
Důležité
Kroky v tomto dokumentu vyžadují skupinu prostředků Azure obsahující cluster Spark ve službě HDInsight i cluster Kafka ve službě HDInsight. Oba tyto clustery se nacházejí ve virtuální síti Azure, což umožňuje přímou komunikaci clusteru Spark s clusterem Kafka.
Pro usnadnění práce tento dokument odkazuje na šablonu, která může vytvořit všechny požadované prostředky Azure.
Další informace o používání služby HDInsight ve virtuální síti najdete v dokumentu Plánování virtuální sítě pro HDInsight .
Strukturované streamování s využitím Apache Kafka
Strukturované streamování Sparku je modul pro zpracování datových proudů založený na modulu Spark SQL. Při použití strukturovaného streamování můžete dotazy streamování psát stejným způsobem jako dávkové dotazy.
Následující fragmenty kódu ukazují čtení ze systému Kafka a uložení do souboru. První z nich je dávková operace, zatímco druhá je operace streamování:
// Read a batch from Kafka
val kafkaDF = spark.read.format("kafka")
.option("kafka.bootstrap.servers", kafkaBrokers)
.option("subscribe", kafkaTopic)
.option("startingOffsets", "earliest")
.load()
// Select data and write to file
kafkaDF.select(from_json(col("value").cast("string"), schema) as "trip")
.write
.format("parquet")
.option("path","/example/batchtripdata")
.option("checkpointLocation", "/batchcheckpoint")
.save()
// Stream from Kafka
val kafkaStreamDF = spark.readStream.format("kafka")
.option("kafka.bootstrap.servers", kafkaBrokers)
.option("subscribe", kafkaTopic)
.option("startingOffsets", "earliest")
.load()
// Select data from the stream and write to file
kafkaStreamDF.select(from_json(col("value").cast("string"), schema) as "trip")
.writeStream
.format("parquet")
.option("path","/example/streamingtripdata")
.option("checkpointLocation", "/streamcheckpoint")
.start.awaitTermination(30000)
V obou fragmentech kódu se data čtou ze systému Kafka a zapisují do souboru. Rozdíly mezi příklady jsou následující:
| Batch | Streamování |
|---|---|
read |
readStream |
write |
writeStream |
save |
start |
Operace streamování také používá awaitTermination(30000), který zastaví stream po 30 000 ms.
Pokud chcete použít strukturované streamování s využitím systému Kafka, váš projekt musí obsahovat závislost na balíčku org.apache.spark : spark-sql-kafka-0-10_2.11. Verze tohoto balíčku musí odpovídat verzi Sparku ve službě HDInsight. Informace o závislostech pro Spark 2.4 (dostupné ve službě HDInsight 4.0) najdete na adrese https://search.maven.org/#artifactdetails%7Corg.apache.spark%7Cspark-sql-kafka-0-10_2.11%7C2.2.0%7Cjar.
Pro Poznámkový blok Jupyter použitý v tomto kurzu načte následující buňka závislost balíčku:
%%configure -f
{
"conf": {
"spark.jars.packages": "org.apache.spark:spark-sql-kafka-0-10_2.11:2.2.0",
"spark.jars.excludes": "org.scala-lang:scala-reflect,org.apache.spark:spark-tags_2.11"
}
}
Vytvoření clusterů
Apache Kafka ve službě HDInsight neposkytuje přístup ke zprostředkovatelům Kafka přes veřejný internet. Cokoli, co využívá systém Kafka, musí být ve stejné virtuální síti Azure. V tomto kurzu se clustery Kafka i Spark nacházejí ve stejné virtuální síti Azure.
Následující diagram znázorňuje tok komunikace mezi Sparkem a systémem Kafka:
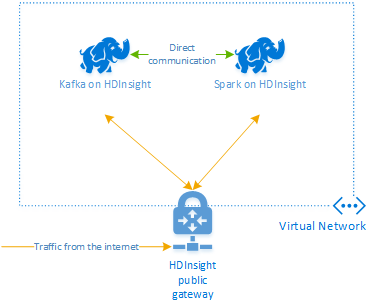
Poznámka:
Komunikace služby Kafka je omezená na virtuální síť. Další služby v clusteru, jako jsou SSH a Ambari, jsou přístupné přes internet. Další informace o veřejných portech dostupných ve službě HDInsight najdete v tématu Porty a identifikátory URI používané službou HDInsight.
K vytvoření virtuální sítě Azure a následnému vytvoření clusterů Kafka a Spark v rámci této sítě použijte následující postup:
Pomocí následujícího tlačítka se přihlaste do Azure a otevřete šablonu na webu Azure Portal.

Šablona Azure Resource Manageru se nachází na adrese https://raw.githubusercontent.com/Azure-Samples/hdinsight-spark-kafka-structured-streaming/master/azuredeploy.json.
Tato šablona vytvoří následující prostředky:
Kafka v clusteru HDInsight 4.0 nebo 5.0
Spark 2.4 nebo 3.1 v clusteru HDInsight 4.0 nebo 5.0.
Virtuální síť Azure obsahující clustery HDInsight.
Důležité
Poznámkový blok strukturovaného streamování použitý v tomto kurzu vyžaduje Spark 2.4 nebo 3.1 ve službě HDInsight 4.0 nebo 5.0. Pokud používáte starší verzi Sparku ve službě HDInsight, při použití poznámkového bloku se zobrazí chyby.
Pomocí následujících informací vyplňte položky v části Přizpůsobená šablona:
Nastavení Hodnota Předplatné Vaše předplatné Azure. Skupina prostředků Skupina prostředků obsahující prostředky. Umístění Oblast Azure, ve které se prostředky vytvoří. Název clusteru Spark Název clusteru Spark. Prvních šest znaků se musí lišit od názvu clusteru Kafka. Název clusteru Kafka Název clusteru Kafka. Prvních šest znaků se musí lišit od názvu clusteru Spark. Uživatelské jméno přihlášení clusteru Uživatelské jméno správce clusterů. Heslo přihlášení clusteru Heslo správce clusterů. Uživatelské jméno SSH Uživatel SSH, který se má pro clustery vytvořit. Heslo SSH Heslo uživatele SSH. 
Přečtěte si podmínky a ujednání a pak vyberte Souhlasím s podmínkami a ujednáními uvedenými výše.
Vyberte Koupit.
Poznámka:
Vytvoření clusterů může trvat až 20 minut.
Použití strukturovaného streamování Sparku
Tento příklad ukazuje, jak používat strukturované streamování Sparku se systémem Kafka ve službě HDInsight. Používá data o jízdách taxíkem, která poskytuje New York City. Datová sada používaná v tomto poznámkovém bloku pochází z roku 2016 Zeleně taxislužby.
Shromážděte informace o hostiteli. Pomocí níže uvedených příkazů curl a jq získejte informace o hostitelích Kafka ZooKeeper a zprostředkovatele. Příkazy jsou navržené pro příkazový řádek windows, pro jiná prostředí budou potřeba mírné variace. Nahraďte
KafkaClusternázvem clusteru Kafka aKafkaPasswordheslem pro přihlášení ke clusteru. NahraďteC:\HDI\jq-win64.exetaké skutečnou cestu k instalaci jq. Zadejte příkazy do příkazového řádku Windows a uložte výstup pro pozdější kroky.REM Enter cluster name in lowercase set CLUSTERNAME=KafkaCluster set PASSWORD=KafkaPassword curl -u admin:%PASSWORD% -G "https://%CLUSTERNAME%.azurehdinsight.net/api/v1/clusters/%CLUSTERNAME%/services/ZOOKEEPER/components/ZOOKEEPER_SERVER" | C:\HDI\jq-win64.exe -r "["""\(.host_components[].HostRoles.host_name):2181"""] | join(""",""")" curl -u admin:%PASSWORD% -G "https://%CLUSTERNAME%.azurehdinsight.net/api/v1/clusters/%CLUSTERNAME%/services/KAFKA/components/KAFKA_BROKER" | C:\HDI\jq-win64.exe -r "["""\(.host_components[].HostRoles.host_name):9092"""] | join(""",""")"Ve webovém prohlížeči přejděte do
https://CLUSTERNAME.azurehdinsight.net/jupyterumístění , kdeCLUSTERNAMEje název vašeho clusteru. Po zobrazení výzvy zadejte přihlašovací jméno (správce) a heslo clusteru, které jste použili při vytváření clusteru.Vyberte Nový > Spark a vytvořte poznámkový blok.
Streamování Sparku má mikrobatching, což znamená, že data přicházejí jako dávky a exekutory běží v dávkách dat. Pokud má exekutor časový limit nečinnosti menší než doba potřebnou ke zpracování dávky, budou exekutory neustále přidány a odebrány. Pokud je časový limit nečinnosti exekutorů větší než doba trvání dávky, exekutor se nikdy neodebere. Proto doporučujeme zakázat dynamické přidělování nastavením spark.dynamicAllocation.enabled na false při spouštění streamovaných aplikací.
Načtěte balíčky používané poznámkovým blokem zadáním následujících informací do buňky poznámkového bloku. Spusťte příkaz pomocí kombinace kláves CTRL+ENTER.
%%configure -f { "conf": { "spark.jars.packages": "org.apache.spark:spark-sql-kafka-0-10_2.11:2.2.0", "spark.jars.excludes": "org.scala-lang:scala-reflect,org.apache.spark:spark-tags_2.11", "spark.dynamicAllocation.enabled": false } }Vytvořte téma Kafka. Upravte následující příkaz nahrazením
YOUR_ZOOKEEPER_HOSTSinformací o hostiteli Zookeeper extrahovanými v prvním kroku. Zadáním upraveného příkazu do poznámkového bloku Jupyter vytvořtetripdatatéma.%%bash export KafkaZookeepers="YOUR_ZOOKEEPER_HOSTS" /usr/hdp/current/kafka-broker/bin/kafka-topics.sh --create --replication-factor 3 --partitions 8 --topic tripdata --zookeeper $KafkaZookeepersNačtěte data o jízdách taxíkem. Zadáním příkazu do další buňky načtěte data o jízdách taxíkem v New Yorku. Data se načtou do datového rámce a pak se datový rámec zobrazí jako výstup buňky.
import spark.implicits._ // Load the data from the New York City Taxi data REST API for 2016 Green Taxi Trip Data val url="https://data.cityofnewyork.us/resource/pqfs-mqru.json" val result = scala.io.Source.fromURL(url).mkString // Create a dataframe from the JSON data val taxiDF = spark.read.json(Seq(result).toDS) // Display the dataframe containing trip data taxiDF.show()Nastavte informace o hostitelích zprostředkovatele Kafka. Nahraďte
YOUR_KAFKA_BROKER_HOSTSinformacemi o hostitelích zprostředkovatele, které jste extrahovali v kroku 1. Do další buňky Poznámkového bloku Jupyter zadejte upravený příkaz.// The Kafka broker hosts and topic used to write to Kafka val kafkaBrokers="YOUR_KAFKA_BROKER_HOSTS" val kafkaTopic="tripdata" println("Finished setting Kafka broker and topic configuration.")Odešlete data do Systému Kafka. V následujícím příkazu
vendoridse pole použije jako hodnota klíče pro zprávu Kafka. Klíč používá Kafka při dělení dat. Všechna pole jsou uložená ve zprávě Kafka jako řetězcová hodnota JSON. Zadáním následujícího příkazu v Jupyteru uložte data do Kafka pomocí dávkového dotazu.// Select the vendorid as the key and save the JSON string as the value. val query = taxiDF.selectExpr("CAST(vendorid AS STRING) as key", "to_JSON(struct(*)) AS value").write.format("kafka").option("kafka.bootstrap.servers", kafkaBrokers).option("topic", kafkaTopic).save() println("Data sent to Kafka")Deklarujte schéma. Následující příkaz ukazuje, jak použít schéma při čtení dat JSON z kafka. Do další buňky Jupyter zadejte příkaz.
// Import bits useed for declaring schemas and working with JSON data import org.apache.spark.sql._ import org.apache.spark.sql.types._ import org.apache.spark.sql.functions._ // Define a schema for the data val schema = (new StructType).add("dropoff_latitude", StringType).add("dropoff_longitude", StringType).add("extra", StringType).add("fare_amount", StringType).add("improvement_surcharge", StringType).add("lpep_dropoff_datetime", StringType).add("lpep_pickup_datetime", StringType).add("mta_tax", StringType).add("passenger_count", StringType).add("payment_type", StringType).add("pickup_latitude", StringType).add("pickup_longitude", StringType).add("ratecodeid", StringType).add("store_and_fwd_flag", StringType).add("tip_amount", StringType).add("tolls_amount", StringType).add("total_amount", StringType).add("trip_distance", StringType).add("trip_type", StringType).add("vendorid", StringType) // Reproduced here for readability //val schema = (new StructType) // .add("dropoff_latitude", StringType) // .add("dropoff_longitude", StringType) // .add("extra", StringType) // .add("fare_amount", StringType) // .add("improvement_surcharge", StringType) // .add("lpep_dropoff_datetime", StringType) // .add("lpep_pickup_datetime", StringType) // .add("mta_tax", StringType) // .add("passenger_count", StringType) // .add("payment_type", StringType) // .add("pickup_latitude", StringType) // .add("pickup_longitude", StringType) // .add("ratecodeid", StringType) // .add("store_and_fwd_flag", StringType) // .add("tip_amount", StringType) // .add("tolls_amount", StringType) // .add("total_amount", StringType) // .add("trip_distance", StringType) // .add("trip_type", StringType) // .add("vendorid", StringType) println("Schema declared")Vyberte data a spusťte stream. Následující příkaz ukazuje, jak načíst data ze systému Kafka pomocí dávkového dotazu. Výsledky pak zapište do HDFS v clusteru Spark. V tomto příkladu načte
selectzprávu (pole hodnoty) ze systému Kafka a použije na něj schéma. Data se pak zapíšou do HDFS (WASB nebo ADL) ve formátu parquet. Do další buňky Jupyter zadejte příkaz.// Read a batch from Kafka val kafkaDF = spark.read.format("kafka").option("kafka.bootstrap.servers", kafkaBrokers).option("subscribe", kafkaTopic).option("startingOffsets", "earliest").load() // Select data and write to file val query = kafkaDF.select(from_json(col("value").cast("string"), schema) as "trip").write.format("parquet").option("path","/example/batchtripdata").option("checkpointLocation", "/batchcheckpoint").save() println("Wrote data to file")Soubory můžete ověřit zadáním příkazu do další buňky Jupyter. Zobrazí seznam souborů v adresáři
/example/batchtripdata.%%bash hdfs dfs -ls /example/batchtripdataZatímco předchozí příklad použil dávkový dotaz, následující příkaz ukazuje, jak provést totéž pomocí streamovacího dotazu. Do další buňky Jupyter zadejte příkaz.
// Stream from Kafka val kafkaStreamDF = spark.readStream.format("kafka").option("kafka.bootstrap.servers", kafkaBrokers).option("subscribe", kafkaTopic).option("startingOffsets", "earliest").load() // Select data from the stream and write to file kafkaStreamDF.select(from_json(col("value").cast("string"), schema) as "trip").writeStream.format("parquet").option("path","/example/streamingtripdata").option("checkpointLocation", "/streamcheckpoint").start.awaitTermination(30000) println("Wrote data to file")Spuštěním následující buňky ověřte, že se soubory zapisovaly dotazem streamování.
%%bash hdfs dfs -ls /example/streamingtripdata
Vyčištění prostředků
Pokud chcete vyčistit prostředky vytvořené v tomto kurzu, můžete odstranit skupinu prostředků. Odstraněním skupiny prostředků se odstraní také přidružený cluster HDInsight. A všechny další prostředky přidružené ke skupině prostředků.
Odebrání skupiny prostředků pomocí webu Azure Portal:
- Na webu Azure Portal rozbalte nabídku na levé straně, otevřete nabídku služeb a pak zvolte Skupiny prostředků, abyste zobrazili seznam skupin prostředků.
- Vyhledejte skupinu prostředků, kterou chcete odstranit, a klikněte pravým tlačítkem na tlačítko Další (...) na pravé straně seznamu.
- Vyberte Odstranit skupinu prostředků a potvrďte tuto akci.
Upozorňující
Účtování clusteru HDInsight začne vytvořením clusteru a skončí jeho odstraněním. Účtuje se poměrnou částí po minutách, takže byste cluster měli odstranit vždy, když už se nepoužívá.
Odstraněním clusteru Kafka ve službě HDInsight odstraníte také všechna data uložená v systému Kafka.