Co je Azure HDInsight?
Azure HDInsight je spravovaná opensourcová analytická služba v cloudu, která je určená pro podniky. S HDInsight můžete ve svém prostředí Azure používat opensourcové architektury, jako jsou Apache Spark, Apache Hive, LLAP, Apache Kafka, Hadoop a další.
Co je HDInsight a technologie Hadoop?
Azure HDInsight je platforma spravovaného clusteru, která usnadňuje spouštění architektur pro velké objemy dat, jako jsou Apache Spark, Apache Hive, LLAP, Apache Kafka, Apache Hadoop a další ve vašem prostředí Azure. Je navržený tak, aby zpracovával velké objemy dat s vysokou rychlostí a efektivitou.
Proč mám používat Azure HDInsight?
| Schopnost | Popis |
|---|---|
| Nativní pro cloud | Azure HDInsight umožňuje vytvářet optimalizované clustery pro Spark, Interactive query (LLAP), Kafka, HBase a Hadoop v Azure. HDInsight poskytuje také komplexní smlouvu SLA pro všechny vaše produkční úlohy. |
| Škálovatelnost a nízké náklady | HDInsight umožňuje vertikálně navyšovat nebo snížit kapacitu úloh. Náklady můžete snížit tak, že vytvoříte clustery na vyžádání a platíte jenom za to, co používáte. Můžete také sestavovat datové kanály pro zprovoznění úloh. Oddělený výpočetní výkon a úložiště poskytují lepší výkon a flexibilitu. |
| Bezpečnost a dodržování předpisů | HDInsight umožňuje chránit podnikové datové prostředky pomocí služby Azure Virtual Network, šifrování a integrace s Microsoft Entra ID. HDInsight také splňuje nejoblíbenější oborové a vládní standardy dodržování předpisů. |
| Sledování | Azure HDInsight se integruje s protokoly Azure Monitoru a poskytuje jedno rozhraní, pomocí kterého můžete monitorovat všechny clustery. |
| Globální dostupnost | HDInsight je k dispozici ve více oblastech než jakákoli jiná nabídka analýzy velkých objemů dat . Služba Azure HDInsight je dostupná také pro Azure Government, Čínu a Německo a umožňuje tak splnit požadavky vašeho podniku v klíčových suverénních oblastech. |
| Produktivita | Azure HDInsight umožňuje používat bohaté nástroje zvyšující produktivitu pro Hadoop a Spark s oblíbeným vývojovým prostředím. Mezi tato vývojová prostředí patří Visual Studio, VS Code, Eclipse a IntelliJ pro podporu jazyka Scala, Python, Java a .NET. |
| Rozšiřitelnost | Clustery HDInsight můžete rozšířit o nainstalované komponenty (Hue, Presto atd.) pomocí akcí skriptu, přidáním hraničních uzlů nebo integrací s jinými certifikovanými aplikacemi pro velké objemy dat . HDInsight umožňuje bezproblémovou integraci s nejoblíbenějšími řešeními pro velké objemy dat prostřednictvím nasazení jedním kliknutím. |
What is big data?
Velké objemy dat se shromažďují v narůstajícím množství, s vyšší rychlostí a stále větší pestrostí formátů. Může jít o historické (tzn. uložené) objemy dat nebo o objemy dat v reálném čase (streamované ze zdroje). Informace o nejběžnějších případech použití velkých objemů dat najdete v části Scénáře použití služby HDInsight.
Typy clusterů ve službě HDInsight
HDInsight zahrnuje specifické typy clusterů a možnosti přizpůsobení clusterů, jako je například možnost přidávání komponent, nástrojů a jazyků. HDInsight nabízí následující typy clusteru:
| Typ clusteru | Popis | Začínáme |
|---|---|---|
| Apache Hadoop | Architektura, která používá HDFS, správu prostředků YARN a jednoduchý programovací model MapReduce pro paralelní zpracování a analýzu dávkových dat. | Vytvoření clusteru Apache Hadoop |
| Apache Spark | Opensourcová architektura paralelního zpracování, která podporuje zpracování v paměti za účelem zvýšení výkonu aplikací pro analýzu velkých objemů dat. Přečtěte si téma Co je Apache Spark v prostředí HDInsight? | Vytvoření clusteru Apache Spark |
| Apache HBase | Databáze NoSQL založená na Hadoopu, která poskytuje náhodný přístup a silnou konzistenci pro velké objemy nestrukturovaných a částečně strukturovaných dat – potenciálně miliardy řádků krát miliony sloupců. Přečtěte si téma Co je HBase v HDInsight? | Vytvoření clusteru Apache HBase |
| Apache Interactive Query | Ukládání do mezipaměti v paměti pro interaktivní a rychlejší dotazy Hive Viz Použití Interactive Query ve službě HDInsight. | Vytvoření clusteru Interactive Query |
| Apache Kafka | Opensourcová platforma se používá k vytváření streamovaných datových kanálů a aplikací. Kafka také poskytuje funkce propojující fronty zpráv, pomocí kterých můžete publikovat datové streamy a přihlašovat se k jejich odběru. Viz Úvod k Apache Kafka ve službě HDInsight. | Vytvoření clusteru Apache Kafka |
Scénáře použití služby HDInsight
Azure HDInsight je možné použít pro různé scénáře zpracování velkých objemů dat . Může se jednat o historická data (data, která jsou už shromážděná a uložená) nebo data v reálném čase (data, která se přímo streamují ze zdroje). Scénáře zpracování těchto dat můžeme shrnout do následujících kategorií:
Dávkové zpracování (ETL)
Extrakce, transformace a načítání (ETL) je proces, při kterém se nestrukturovaná nebo strukturovaná data extrahují z heterogenních zdrojů dat. Potom se transformují do strukturovaného formátu a načítají do úložiště dat. Transformovaná data je možné použít pro datové vědy nebo datové sklady.
Datové sklady
Pomocí služby HDInsight můžete provádět interaktivní dotazy v petabajtovém měřítku nad strukturovanými i nestrukturovanými daty v jakémkoli měřítku. Můžete také sestavovat modely, které je propojí s nástroji BI.
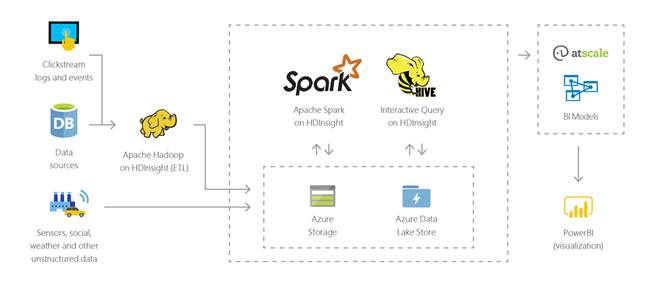
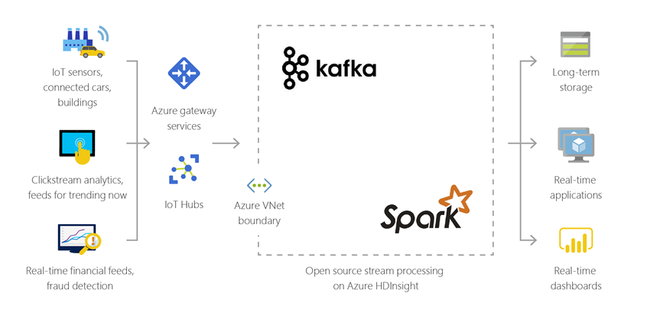
Internet věcí (IoT)
HdInsight můžete použít ke zpracování streamovaných dat přijatých v reálném čase z různých druhů zařízení. Pokud chcete získat další informace, přečtěte si tento blogový příspěvek z Azure, který oznamuje verzi Public Preview pro Apache Kafka v HDInsightu se Spravovanými disky Azure.
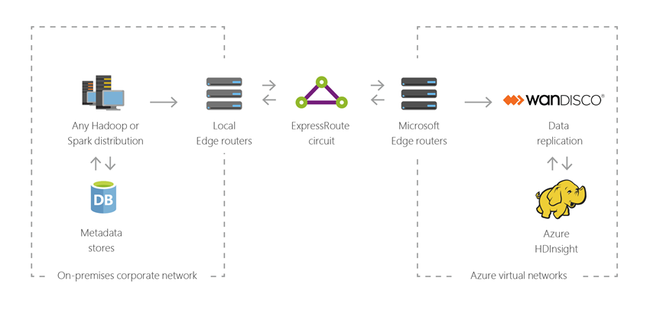
Hybridní
Pomocí služby HDInsight můžete rozšířit stávající místní infrastrukturu velkých objemů dat do Azure, abyste mohli využít pokročilé analytické možnosti cloudu.
Opensourcové komponenty ve službě HDInsight
Azure HDInsight umožňuje vytvářet clustery s opensourcovými architekturami, jako jsou Spark, Hive, LLAP, Kafka, Hadoop a HBase. Tyto clustery ve výchozím nastavení zahrnují různé opensourcové komponenty, jako jsou Apache Ambari, Avro, Apache Hive 3, HCatalog, Apache Hadoop MapReduce, Apache Hadoop YARN, Apache Phoenix, Apache Pig, Apache Sqoop, Apache Tez, Apache Oozie a Apache ZooKeeper.
Programovací jazyky v prostředí HDInsight
Clustery HDInsight, včetně clusterů Spark, HBase, Kafka, Hadoop a dalších, podporují celou řadu programovacích jazyků. Některé z nich ale nejsou ve výchozím nastavení nainstalované. Pro knihovny, moduly nebo balíčky, které nejsou ve výchozím nastavení nainstalovány, použijte akci skriptu k instalaci komponenty.
| Programovací jazyk | Informační |
|---|---|
| Výchozí podpora programovacích jazyků | Ve výchozím nastavení podporují clustery prostředí HDInsight tyto jazyky:
|
| Jazyky Java virtual machine (JVM) | V prostředí Java Virtual Machine (JVM) je možné spouštět celou řadu jiných jazyků, než je Java. Pokud ale spustíte některé z těchto jazyků, možná budete muset do clusteru nainstalovat další komponenty. Clustery HDInsight podporují následující jazyky založené na prostředí JVM:
|
| Jazyky pro Hadoop | Clustery HDInsight podporují následující jazyky, které jsou specifické pro technologii Hadoop:
|
Vývojářské nástroje pro HDInsight
Vývojářské nástroje pro HDInsight, včetně nástrojů IntelliJ, Eclipse, Visual Studio Code a Visual Studio, můžete díky bezproblémové integraci s Azure použít k vytváření a odesílání úloh a dotazů na data HDInsight.
- Azure Toolkit for IntelliJ 10
- Sada Azure Toolkit pro Eclipse 6
- Nástroje Azure HDInsight pro VS Code 13
- Nástroje Azure Data Lake pro Visual Studio 9
Business intelligence ve službě HDInsight
Známé nástroje business intelligence (BI) načítají, analyzují a vykazují data integrovaná v prostředí HDInsight buď pomocí doplňku Power Query, nebo ovladače Microsoft Hive ODBC Driver:
Apache Spark BI s využitím nástrojů pro vizualizaci dat ve službě Azure HDInsight
Vizualizace dat Apache Hivu pomocí Microsoft Power BI ve službě Azure HDInsight
Vizualizace dat Interactive Query Hive pomocí Power BI ve službě Azure HDInsight
Připojení Excelu do Apache Hadoopu s Power Query (vyžaduje Windows)
Připojení Excel do Apache Hadoopu pomocí ovladače ODBC Microsoft Hive (vyžaduje Windows)
Rezidenci dat v oblasti
Spark, Hadoop a LLAP neukládají zákaznická data, takže tyto služby automaticky splňují požadavky na rezidenci dat v dané oblasti zadané v Centru zabezpečení.
Kafka a HBase ukládají zákaznická data. Tato data jsou automaticky uložená systémem Kafka a HBase v jedné oblasti, takže tato služba splňuje požadavky na rezidenci dat v jednotlivých oblastech zadaných v Centru zabezpečení.
Známé nástroje business intelligence (BI) načítají, analyzují a hlásí data integrovaná se službou HDInsight pomocí doplňku Power Query nebo ovladače ODBC Microsoft Hive.