Řešení potíží s pomalou úlohou na clusteru HDInsight nebo jejím selháním
Pokud aplikace zpracovávající data v clusteru HDInsight běží pomalu nebo selhává s kódem chyby, máte několik možností řešení potíží. Pokud vaše úlohy poběží déle, než se čekalo, nebo obecně dochází k pomalým dobám odezvy, může docházet k selháním z vašeho clusteru, jako jsou služby, na kterých cluster běží. Nejčastější příčinou těchto zpomalení je ale nedostatečné škálování. Při vytváření nového clusteru HDInsight vyberte odpovídající velikosti virtuálních počítačů.
Pokud chcete diagnostikovat pomalý nebo neúspěšný cluster, shromážděte informace o všech aspektech prostředí, jako jsou přidružené služby Azure, konfigurace clusteru a informace o provádění úloh. Užitečnou diagnostikou je pokus o reprodukci stavu chyby v jiném clusteru.
- Krok 1: Shromáždění dat o problému
- Krok 2: Ověření prostředí clusteru HDInsight
- Krok 3: Zobrazení stavu clusteru
- Krok 4: Zkontrolujte zásobník a verze prostředí.
- Krok 5: Zkontrolujte soubory protokolu clusteru.
- Krok 6: Zkontrolujte nastavení konfigurace.
- Krok 7: Reprodukujte selhání v jiném clusteru.
Krok 1: Shromáždění dat o problému
HDInsight poskytuje mnoho nástrojů, které můžete použít k identifikaci a řešení potíží s clustery. Následující kroky vás provedou těmito nástroji a poskytují návrhy pro určení problému.
Identifikace problému
Při identifikaci problému zvažte následující otázky:
- Co jsem očekával(a)? Co se místo toho stalo?
- Jak dlouho trvalo spuštění procesu? Jak dlouho má běžet?
- Mají moje úlohy v tomto clusteru vždycky pomalé? Běžely rychleji v jiném clusteru?
- Kdy k tomuto problému poprvé došlo? Jak často se to stalo od té doby?
- Změnilo se v konfiguraci clusteru něco?
Podrobnosti o clusteru
Mezi důležité informace o clusteru patří:
- Název clusteru
- Oblast clusteru – zkontrolujte výpadky oblastí.
- Typ a verze clusteru HDInsight
- Typ a počet instancí HDInsight určených pro hlavní a pracovní uzly.
Azure Portal může poskytnout tyto informace:

Můžete také použít Azure CLI:
az hdinsight list --resource-group <ResourceGroup>
az hdinsight show --resource-group <ResourceGroup> --name <ClusterName>
Další možností je použití PowerShellu. Další informace najdete v tématu Správa clusterů Apache Hadoop v HDInsight pomocí Azure PowerShellu.
Krok 2: Ověření prostředí clusteru HDInsight
Každý cluster HDInsight spoléhá na různé služby Azure a na opensourcový software, jako je Apache HBase a Apache Spark. Clustery HDInsight můžou volat také jiné služby Azure, jako jsou virtuální sítě Azure. Selhání clusteru může být způsobeno některou ze spuštěných služeb v clusteru nebo externí službou. Změna konfigurace služby clusteru může také způsobit selhání clusteru.
Podrobnosti služby
- Zkontrolujte verze opensourcové knihovny.
- Zkontrolujte výpadky služeb Azure.
- Zkontrolujte limity využití služby Azure.
- Zkontrolujte konfiguraci podsítě virtuální sítě Azure.
Zobrazení nastavení konfigurace clusteru pomocí uživatelského rozhraní Ambari
Apache Ambari poskytuje správu a monitorování clusteru HDInsight pomocí webového uživatelského rozhraní a rozhraní REST API. Ambari je součástí clusterů HDInsight založených na Linuxu. Na stránce HDInsight webu Azure Portal vyberte podokno Řídicí panel clusteru. Výběrem podokna řídicího panelu clusteru HDInsight otevřete uživatelské rozhraní Ambari a zadejte přihlašovací údaje clusteru.
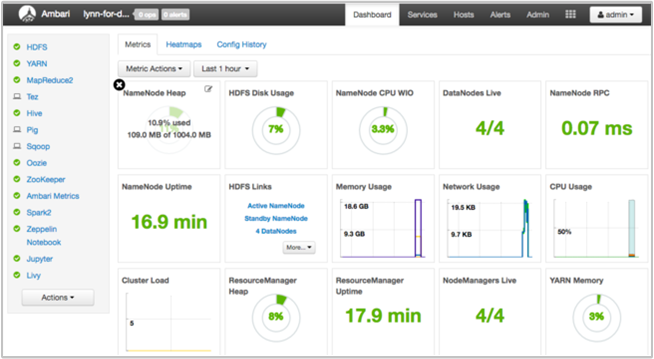
Pokud chcete otevřít seznam zobrazení služeb, vyberte zobrazení Ambari na stránce webu Azure Portal. Tento seznam závisí na tom, které knihovny jsou nainstalovány. Můžete například vidět Správce front YARN, zobrazení Hive a zobrazení Tez. Výběrem odkazu na službu zobrazíte informace o konfiguraci a službě.
Zkontrolujte výpadky služeb Azure
HDInsight spoléhá na několik služeb Azure. Spouští virtuální servery ve službě Azure HDInsight, ukládá data a skripty ve službě Azure Blob Storage nebo Azure Data Lake Storage a indexuje soubory protokolů ve službě Azure Table Storage. Přerušení těchto služeb, i když vzácné, může způsobit problémy ve službě HDInsight. Pokud máte v clusteru neočekávané zpomalení nebo selhání, zkontrolujte řídicí panel stavu Azure. Stav každé služby je uvedený v jednotlivých oblastech. Zkontrolujte oblast clusteru a také oblasti souvisejících služeb.
Kontrola limitů využití služeb Azure
Pokud spouštíte velký cluster nebo jste současně spustili mnoho clusterů, může cluster selhat, pokud jste překročili limit služby Azure. Limity služeb se liší v závislosti na vašem předplatném Azure. Další informace najdete v tématu Limity, kvóty a omezení předplatného a služeb Azure. Můžete požádat, aby Microsoft zvýšil počet dostupných prostředků HDInsight (například jader virtuálních počítačů a instancí virtuálních počítačů) pomocí žádosti o navýšení kvóty pro jádra Resource Manageru.
Kontrola verze
Porovnejte verzi clusteru s nejnovější verzí HDInsight. Každá verze HDInsight zahrnuje vylepšení, jako jsou nové aplikace, funkce, opravy a opravy chyb. Problém, který má vliv na váš cluster, je možná opravený v nejnovější verzi. Pokud je to možné, spusťte cluster znovu pomocí nejnovější verze SLUŽBY HDInsight a přidružených knihoven, jako jsou Apache HBase, Apache Spark a další.
Restartujte služby clusteru.
Pokud dochází ke zpomalení ve vašem clusteru, zvažte restartování služeb prostřednictvím uživatelského rozhraní Ambari nebo Azure Classic CLI. U clusteru můžou docházet k přechodným chybám a restartování je nejrychlejší způsob, jak stabilizovat vaše prostředí a případně zlepšit výkon.
Krok 3: Zobrazení stavu clusteru
Clustery HDInsight se skládají z různých typů uzlů spuštěných v instancích virtuálních počítačů. Každý uzel je možné monitorovat kvůli výpadku prostředků, problémům s připojením k síti a dalším problémům, které můžou cluster zpomalit. Každý cluster obsahuje dva hlavní uzly a většina typů clusterů obsahuje kombinaci pracovních a hraničních uzlů.
Popis různých uzlů, které jednotlivé typy clusteru používají, najdete v tématu Nastavení clusterů ve službě HDInsight pomocí Apache Hadoopu, Apache Sparku, Apache Kafka a dalších.
Následující části popisují, jak zkontrolovat stav jednotlivých uzlů a celkového clusteru.
Získání snímku stavu clusteru pomocí řídicího panelu uživatelského rozhraní Ambari
Řídicí panel uživatelského rozhraní Ambari (https://<clustername>.azurehdinsight.net) poskytuje přehled o stavu clusteru, jako je doba provozu, paměť, využití sítě a procesoru, využití disku HDFS atd. Pomocí oddílu Hostitelé Ambari můžete zobrazit prostředky na úrovni hostitele. Můžete také zastavit a restartovat služby.
Kontrola služby WebHCat
Jedním z běžných scénářů selhání úloh Apache Hive, Apache Pig nebo Apache Sqoop je selhání služby WebHCat (nebo Templeton). WebHCat je rozhraní REST pro vzdálené spouštění úloh, jako je Hive, Pig, Scoop a MapReduce. WebHCat přeloží žádosti o odeslání úlohy do aplikací Apache Hadoop YARN a vrátí stav odvozený ze stavu aplikace YARN. Následující části popisují běžné stavové kódy HTTP WebHCat.
BadGateway (stavový kód 502)
Tento kód je obecná zpráva z uzlů brány a jedná se o nejběžnější stavové kódy selhání. Jednou z možných příčin je, že služba WebHCat je na aktivním hlavním uzlu. Pokud chcete zkontrolovat tuto možnost, použijte následující příkaz CURL:
curl -u admin:{HTTP PASSWD} https://{CLUSTERNAME}.azurehdinsight.net/templeton/v1/status?user.name=admin
Ambari zobrazí upozornění zobrazující hostitele, na kterých je služba WebHCat spuštěná. Službu WebHCat můžete zkusit zálohovat restartováním služby na hostiteli.
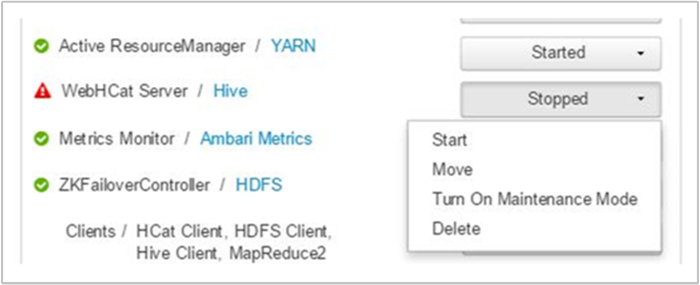
Pokud se server WebHCat stále nezobrazuje, zkontrolujte, jestli protokol operací neobsahuje chybové zprávy. Podrobnější informace najdete v stderr odkazovaných souborech a stdout souborech na uzlu.
Časový limit WebHCat vypršel.
Brána HDInsight vyprší časový limit odpovědí, které trvá déle než dvě minuty a vrací 502 BadGateway. WebHCat se dotazuje na služby YARN pro stavy úloh a pokud odpověď YARN trvá déle než dvě minuty, může tento požadavek vyprší časový limit.
V tomto případě zkontrolujte následující protokoly v /var/log/webhcat adresáři:
- webhcat.log je protokol Log4j, do kterého server zapisuje protokoly.
- webhcat-console.log je stdout serveru při spuštění.
- webhcat-console-error.log je stderr procesu serveru.
Poznámka:
Každý webhcat.log se každý den převrací a generuje soubory s názvem webhcat.log.YYYY-MM-DD. Vyberte příslušný soubor pro časový rozsah, který prošetřujete.
Následující části popisují některé možné příčiny vypršení časových limitů WebHCat.
Časový limit úrovně WebHCat
Pokud je WebHCat zatížený, s více než 10 otevřenými sokety, trvá déle, než se vytvoří nová připojení soketů, což může vést k vypršení časového limitu. Pokud chcete zobrazit seznam síťových připojení k WebHCat a z webu WebHCat, použijte netstat na aktuálním aktivním hlavním uzlu:
netstat | grep 30111
30111 je port WebHCat naslouchá na. Počet otevřených soketů by měl být menší než 10.
Pokud nejsou otevřené sokety, předchozí příkaz nevytvoří výsledek. Pokud chcete zkontrolovat, jestli je Templeton v provozu a naslouchá na portu 30111, použijte:
netstat -l | grep 30111
Časový limit úrovně YARN
Templeton volá YARN ke spouštění úloh a komunikace mezi Templetonem a YARN může způsobit vypršení časového limitu.
Na úrovni YARN existují dva typy časových limitů:
Odeslání úlohy YARN může trvat dostatečně dlouho, než dojde k vypršení časového limitu.
Pokud otevřete
/var/log/webhcat/webhcat.logsoubor protokolu a vyhledáte "úlohu zařazenou do fronty", může se zobrazit více položek, ve kterých je doba provádění příliš dlouhá (>2000 ms), přičemž položky zobrazují rostoucí dobu čekání.Čas pro úlohy zařazené do fronty se stále zvyšuje, protože rychlost, s jakou se nové úlohy odesílají, je vyšší než rychlost dokončení starých úloh. Jakmile se paměť YARN použije 100 %,
joblauncher queuenebude už možné si vypůjčit kapacitu z výchozí fronty. Proto není možné do fronty spouštěče úloh přijmout žádné nové úlohy. Toto chování může způsobit delší a delší dobu čekání, což způsobuje chybu časového limitu, která obvykle následuje mnoha dalšími.Následující obrázek ukazuje frontu spouštěče úloh na 714,4 % nadměrně. To je přijatelné, pokud je ve výchozí frontě stále bezplatná kapacita, ze které si můžete půjčit. Pokud je však cluster plně využitý a paměť YARN je v kapacitě 100 %, musí nové úlohy počkat, což nakonec způsobí vypršení časových limitů.

Tento problém můžete vyřešit dvěma způsoby: buď snížit rychlost odesílaných nových úloh, nebo zvýšit rychlost spotřeby starých úloh vertikálním navýšením kapacity clusteru.
Zpracování YARN může trvat dlouhou dobu, což může způsobit vypršení časových limitů.
Vypsat všechny úlohy: Jedná se o časově náročné volání. Toto volání vytvoří výčet aplikací z Resource Manageru YARN a pro každou dokončenou aplikaci získá stav z YARN JobHistoryServer. S vyšším počtem úloh může tento hovor vypršel časový limit.
Výpis úloh starších než sedm dnů: Server JOBHistoryServer HDInsight YARN je nakonfigurovaný tak, aby uchová informace o dokončené úloze po dobu sedmi dnů (
mapreduce.jobhistory.max-age-mshodnota). Při pokusu o vytvoření výčtu vyprázdněných úloh dochází k vypršení časového limitu.
Diagnostika těchto problémů:
- Určení časového rozsahu UTC pro řešení potíží
- Vyberte příslušné
webhcat.logsoubory. - Vyhledejte zprávy WARN a ERROR během této doby.
Další chyby WebHCat
Stavový kód HTTP 500
Ve většině případů, kdy WebHCat vrátí hodnotu 500, obsahuje chybová zpráva podrobnosti o selhání. V opačném případě vyhledejte
webhcat.logzprávy WARN a ERROR.Selhání úloh
V případech, kdy jsou interakce s WebHCat úspěšné, ale úlohy selhávají.
Templeton shromažďuje výstup konzoly úloh jako
stderrvstatusdir, což je často užitečné pro řešení potíží.stderrobsahuje identifikátor aplikace YARN skutečného dotazu.
Krok 4: Kontrola zásobníku a verzí prostředí
Stránka Zásobník uživatelského rozhraní Ambari a verze poskytuje informace o konfiguraci služeb clusteru a historii verzí služby. Nesprávné verze knihovny služby Hadoop můžou být příčinou selhání clusteru. V uživatelském rozhraní Ambari vyberte nabídku Správce a pak stacky a verze. Výběrem karty Verze na stránce zobrazíte informace o verzi služby:
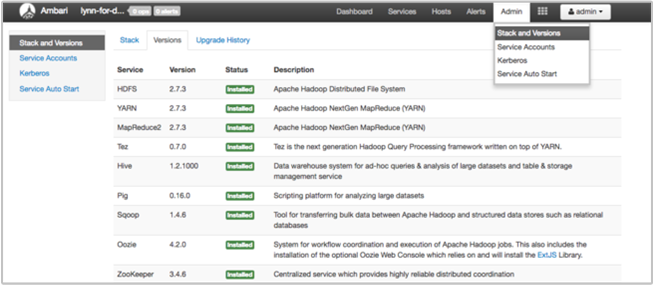
Krok 5: Prozkoumání souborů protokolu
Existuje mnoho typů protokolů, které se generují z mnoha služeb a komponent, které tvoří cluster HDInsight. Soubory protokolu WebHCat jsou popsány dříve. Existuje několik dalších užitečných souborů protokolu, které můžete prozkoumat, abyste zúžili problémy s clusterem, jak je popsáno v následujících částech.
Clustery HDInsight se skládají z několika uzlů, z nichž většina má za úkol spouštět odeslané úlohy. Úlohy běží souběžně, ale soubory protokolu můžou zobrazit výsledky pouze lineárně. HDInsight spouští nové úlohy a ukončuje ostatní, které se nedokončí jako první. Veškerá tato aktivita se protokoluje do
stderrsouborů asyslogsouborů.Soubory protokolu akcí skriptu zobrazují chyby nebo neočekávané změny konfigurace během procesu vytváření clusteru.
Protokoly kroku Hadoop identifikují úlohy Hadoop spuštěné jako součást kroku obsahujícího chyby.
Kontrola protokolů akcí skriptu
Akce skriptů HDInsight spouštějí skripty v clusteru ručně nebo po zadání. Akce skriptů lze například použít k instalaci dalšího softwaru v clusteru nebo ke změně nastavení konfigurace z výchozích hodnot. Kontrola protokolů akcí skriptu může poskytnout přehled o chybách, ke kterým došlo během instalace a konfigurace clusteru. Stav akce skriptu můžete zobrazit výběrem tlačítka ops v uživatelském rozhraní Ambari nebo přístupem k protokolům z výchozího účtu úložiště.
Protokoly akcí skriptu se nacházejí v adresáři \STORAGE_ACCOUNT_NAME\DEFAULT_CONTAINER_NAME\custom-scriptaction-logs\CLUSTER_NAME\DATE .
Zobrazení protokolů HDInsight pomocí rychlých odkazů Ambari
Uživatelské rozhraní HDInsight Ambari obsahuje řadu oddílů Rychlých odkazů . Pokud chcete získat přístup k odkazům na protokoly pro konkrétní službu v clusteru HDInsight, otevřete uživatelské rozhraní Ambari pro váš cluster a pak v seznamu vlevo vyberte odkaz na službu. Vyberte rozevírací seznam Rychlé odkazy, pak uzel HDInsight, který zajímá, a pak vyberte odkaz pro přidružený protokol.
Například pro protokoly HDFS:
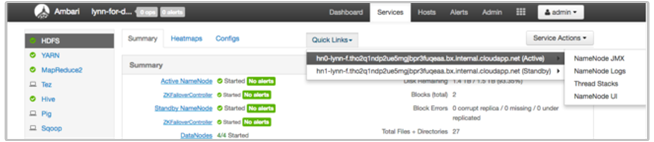
Zobrazení souborů protokolů generovaných systémem Hadoop
Cluster HDInsight generuje protokoly, které se zapisují do tabulek Azure a úložiště objektů blob v Azure. YARN vytvoří vlastní protokoly spouštění. Další informace najdete v tématu Správa protokolů pro cluster HDInsight.
Kontrola výpisů haldy
Výpisy paměti haldy obsahují snímek paměti aplikace, včetně hodnot proměnných v té době, které jsou užitečné pro diagnostiku problémů, ke kterým dochází za běhu. Další informace najdete v tématu Povolení výpisů paměti haldy pro služby Apache Hadoop v HDInsight se systémem Linux.
Krok 6: Kontrola nastavení konfigurace
Clustery HDInsight jsou předem nakonfigurované s výchozím nastavením pro související služby, jako jsou Hadoop, Hive, HBase atd. V závislosti na typu clusteru může být potřeba optimalizovat konfiguraci hardwaru, počet uzlů, typy spuštěných úloh a data, se kterými pracujete (a jak se tato data zpracovávají).
Podrobné pokyny k optimalizaci konfigurací výkonu pro většinu scénářů najdete v tématu Optimalizace konfigurací clusteru pomocí Apache Ambari. Při použití Sparku si přečtěte téma Optimalizace úloh Apache Sparku pro výkon.
Krok 7: Reprodukování selhání v jiném clusteru
Pokud chcete pomoct s diagnostikou zdroje chyby clusteru, spusťte nový cluster se stejnou konfigurací a potom znovu odešlete kroky neúspěšné úlohy 1 po druhém. Před zpracováním dalšího kroku zkontrolujte výsledky jednotlivých kroků. Tato metoda umožňuje opravit a znovu spustit jeden neúspěšný krok. Tato metoda má také výhodu načítání vstupních dat pouze jednou.
- Vytvořte nový testovací cluster se stejnou konfigurací jako cluster, který selhal.
- Odešlete první krok úlohy do testovacího clusteru.
- Po dokončení zpracování kroku zkontrolujte chyby v souborech protokolu kroků. Připojte se k hlavnímu uzlu testovacího clusteru a prohlédněte si soubory protokolů. Soubory protokolu kroků se zobrazí až po určitém spuštění kroku, dokončení nebo selhání.
- Pokud byl první krok úspěšný, spusťte další krok. Pokud došlo k chybám, prozkoumejte chybu v souborech protokolu. Pokud došlo k chybě v kódu, proveďte opravu a spusťte krok znovu.
- Pokračujte, dokud se všechny kroky nespustí bez chyby.
- Po dokončení ladění testovacího clusteru ho odstraňte.
Další kroky
- Správa clusterů HDInsight pomocí webového uživatelského rozhraní Apache Ambari
- Analýza protokolů HDInsight
- Přístup k aplikaci Apache Hadoop YARN přihlášení k linuxové službě HDInsight
- Povolení výpisů paměti haldy pro služby Apache Hadoop ve službě HDInsight se systémem Linux
- Známé problémy s clusterem Apache Spark ve službě HDInsight