Zvýšení výkonu úloh Apache Sparku pomocí azure HDInsight IO Cache
Poznámka:
- Mezipaměť IO byla podporována až do Sparku 2.3 a nebude podporována ve Sparku 2.4 (HDInsight 4.0) a Spark 3.1.2 (HDInsight 5.0).
Io Cache je služba ukládání dat do mezipaměti pro Azure HDInsight, která zlepšuje výkon úloh Apache Sparku. Io Cache také funguje s úlohami Apache TEZ a Apache Hive , které je možné spouštět v clusterech Apache Spark . Io Cache používá opensourcovou komponentu ukládání do mezipaměti s názvem RubiX. RubiX je místní mezipaměť disku pro použití s analytickými moduly pro velké objemy dat, které přistupuje k datům ze systémů cloudového úložiště. RubiX je jedinečný mezi systémy ukládání do mezipaměti, protože používá disky SSD (Solid-State Drive) místo rezervované operační paměti pro účely ukládání do mezipaměti. Služba Io Cache spouští a spravuje servery metadat RubiX na každém pracovním uzlu clusteru. Nakonfiguruje také všechny služby clusteru pro transparentní použití mezipaměti RubiX.
Většina disků SSD poskytuje více než 1 GByte za sekundu šířky pásma. Tato šířka pásma doplněná mezipamětí souborů v paměti operačního systému poskytuje dostatečnou šířku pásma pro načtení výpočetních modulů pro zpracování velkých objemů dat, jako je Apache Spark. Pro Apache Spark je k dispozici operační paměť, aby zpracovávala úlohy závislé na paměti, jako jsou například náhodné prohazování. Použití výhradní paměti umožňuje Apache Sparku dosáhnout optimálního využití prostředků.
Poznámka:
Io Cache v současné době používá RubiX jako součást ukládání do mezipaměti, ale v budoucích verzích služby se to může změnit. Použijte rozhraní io Cache a nevezměte žádné závislosti přímo v implementaci RubiX. Služba Azure BLOB Storage se v tuto chvíli podporuje jenom ve službě Io Cache.
Výhody azure HDInsight IO Cache
Použití io Cache poskytuje zvýšení výkonu pro úlohy, které čtou data ze služby Azure Blob Storage.
Při použití vstupně-výstupní mezipaměti nemusíte provádět žádné změny úloh Sparku, abyste viděli zvýšení výkonu. Pokud je mezipaměť IO Cache zakázaná, tento kód Sparku bude číst data vzdáleně ze služby Azure Blob Storage: spark.read.load('wasbs:///myfolder/data.parquet').count() Při aktivaci vstupně-výstupní mezipaměti způsobí stejný řádek kódu čtení v mezipaměti vstupně-výstupní mezipaměť. Při následujících čteních se data čtou místně z disku SSD. Pracovní uzly v clusteru HDInsight jsou vybaveny místně připojenými vyhrazenými jednotkami SSD. Služba HDInsight IO Cache používá tyto místní disky SSD pro ukládání do mezipaměti, což poskytuje nejnižší úroveň latence a maximalizuje šířku pásma.
Začínáme
Azure HDInsight IO Cache se ve výchozím nastavení deaktivuje ve verzi Preview. Io Cache je k dispozici v clusterech Azure HDInsight 3.6+ Spark, na kterých běží Apache Spark 2.3. Pokud chcete aktivovat vstupně-výstupní mezipaměť ve službě HDInsight 4.0, proveďte následující kroky:
Ve webovém prohlížeči přejděte do
https://CLUSTERNAME.azurehdinsight.netumístění , kdeCLUSTERNAMEje název vašeho clusteru.Na levé straně vyberte službu Io Cache.
Vyberte Akce (akce služby v HDI 3.6) a aktivujte.
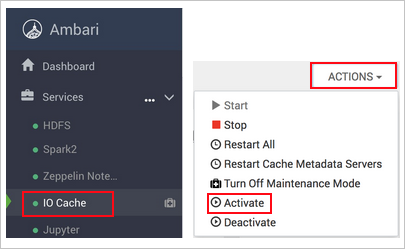
Potvrďte restartování všech ovlivněných služeb v clusteru.
Poznámka:
I když se indikátor průběhu zobrazuje jako aktivovaný, vstupně-výstupní mezipaměť není ve skutečnosti povolená, dokud nerestartujete ostatní ovlivněné služby.
Řešení problému
Po povolení vstupně-výstupní mezipaměti může dojít k chybám při spouštění úloh Sparku na disku. K těmto chybám dochází, protože Spark také používá místní diskové úložiště k ukládání dat během operací náhodného prohazování. Spark může po povolení vstupně-výstupní mezipaměti dojít k výpadku místa SSD a sníží se prostor úložiště Spark. Velikost místa využitého vstupně-výstupní mezipamětí ve výchozím nastavení představuje polovinu celkového prostoru SSD. Využití místa na disku pro vstupně-výstupní mezipaměť je možné konfigurovat v Ambari. Pokud dojde k chybám místa na disku, snižte množství místa na disku využitého pro vstupně-výstupní mezipaměť a restartujte službu. Pokud chcete změnit sadu místa pro vstupně-výstupní mezipaměť, postupujte takto:
V Apache Ambari vyberte na levé straně službu HDFS .
Vyberte karty Konfigurace a Upřesnit.

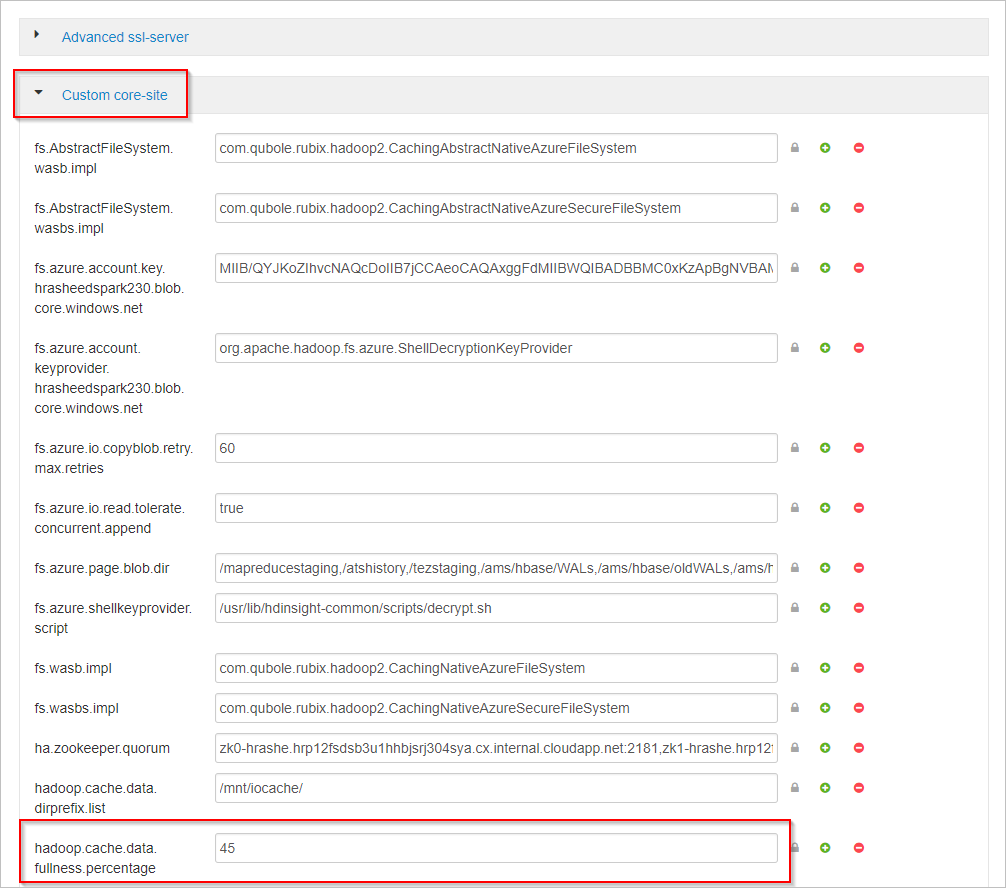
Posuňte se dolů a rozbalte oblast Vlastní jádro webu .
Vyhledejte vlastnost hadoop.cache.data.fullness.percentage.
Změňte hodnotu v poli.
Vyberte Uložit v pravém horním rohu.
Vyberte Restartovat>všechny ovlivněné restartování.

Vyberte Potvrdit restartování vše.
Pokud to nepomůže, zakažte vstupně-výstupní mezipaměť.
Další kroky
Přečtěte si další informace o vstupně-výstupní mezipaměti, včetně srovnávacích testů výkonu v tomto blogovém příspěvku: Úlohy Apache Spark získávají až 9x rychlejší využití služby HDInsight IO Cache.