Jádra pro Poznámkový blok Jupyter v clusterech Apache Spark ve službě Azure HDInsight
Clustery HDInsight Spark poskytují jádra, která můžete použít s poznámkovým blokem Jupyter v Apache Sparku k testování aplikací. Jádro je program, který spouští a interpretuje váš kód. Tři jádra jsou:
- PySpark – pro aplikace napsané v Python2. (Platí jenom pro clustery verze Spark 2.4)
- PySpark3 – pro aplikace napsané v Python3.
- Spark – pro aplikace napsané v jazyce Scala.
V tomto článku se naučíte používat tato jádra a výhody jejich používání.
Požadavky
Cluster Apache Spark ve službě HDInsight. Pokyny najdete v tématu Vytváření clusterů Apache Spark ve službě Azure HDInsight.
Vytvoření poznámkového bloku Jupyter ve Spark HDInsightu
Na webu Azure Portal vyberte cluster Spark. Pokyny najdete v části Seznam a zobrazení clusterů . Otevře se zobrazení Přehled .
V zobrazení Přehled vyberte v poli Řídicí panely clusteru poznámkový blok Jupyter. Po vyzvání zadejte přihlašovací údaje správce clusteru.
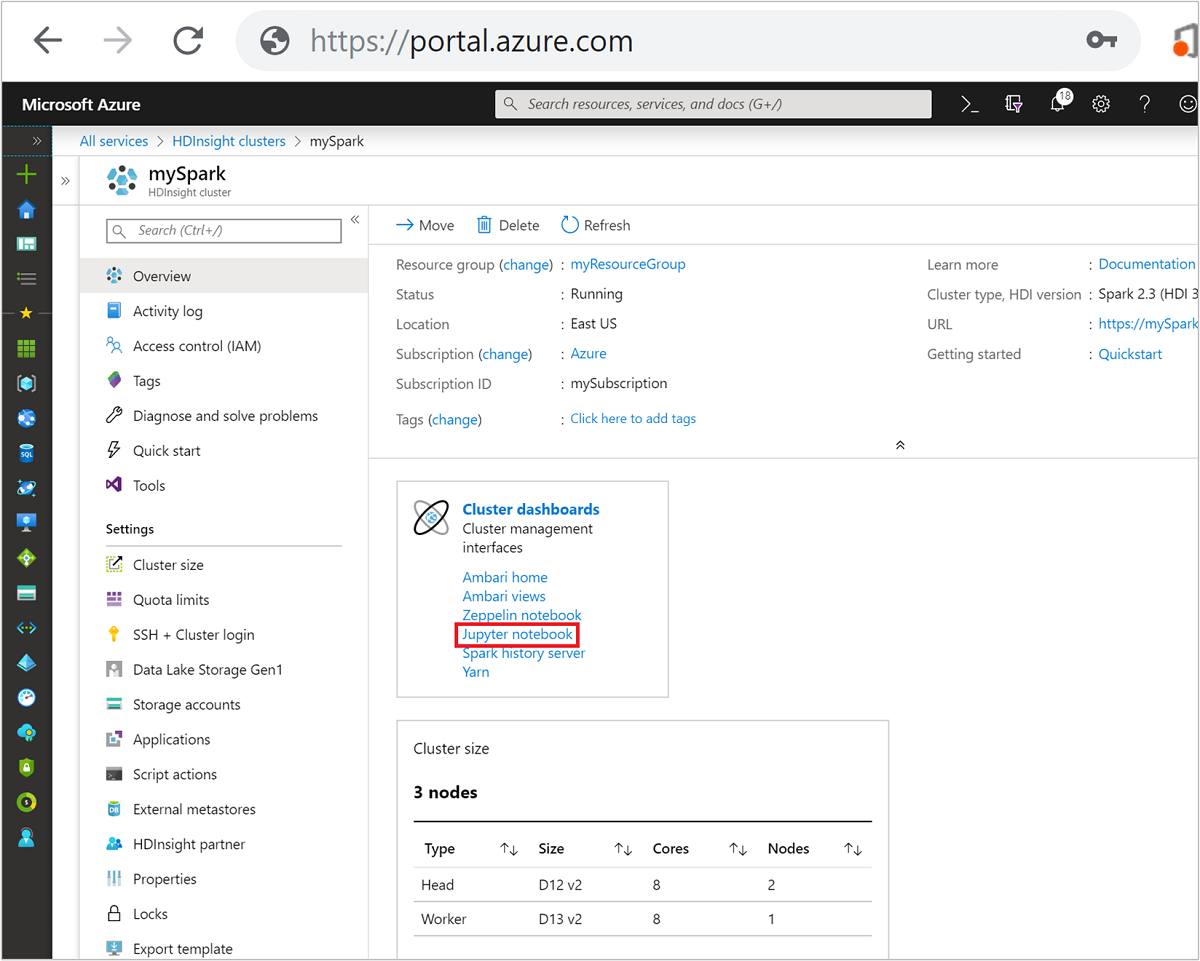
Poznámka:
K poznámkovému bloku Jupyter v clusteru Spark se také můžete dostat tak, že v prohlížeči otevřete následující adresu URL. Nahraďte CLUSTERNAME názvem clusteru:
https://CLUSTERNAME.azurehdinsight.net/jupyterVyberte Nový a pak vyberte Pyspark, PySpark3 nebo Spark a vytvořte poznámkový blok. Použijte jádro Sparku pro aplikace Scala, jádro PySpark pro aplikace Python2 a jádro PySpark3 pro aplikace Python3.
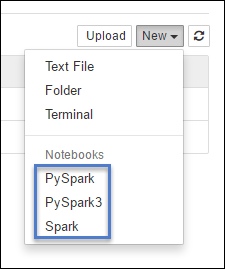
Poznámka:
Pro Spark 3.1 bude k dispozici pouze PySpark3 nebo Spark .
- Otevře se poznámkový blok s vybraným jádrem.
Výhody používání jader
Tady je několik výhod použití nových jader s Poznámkovým blokem Jupyter v clusterech Spark HDInsight.
Přednastavené kontexty S jádry PySpark, PySpark3 nebo Spark nemusíte explicitně nastavovat kontexty Spark nebo Hive, než začnete pracovat s aplikacemi. Tyto kontexty jsou ve výchozím nastavení k dispozici. Mezi tyto kontexty patří:
sc – pro kontext Sparku
sqlContext – pro kontext Hive
Proto nemusíte spouštět příkazy, jako je následující, abyste nastavili kontexty:
sc = SparkContext('yarn-client') sqlContext = HiveContext(sc)Místo toho můžete přímo použít přednastavené kontexty v aplikaci.
Buňkové magie. Jádro PySpark poskytuje některé předdefinované "magie", což jsou speciální příkazy, se kterými
%%můžete volat (například%%MAGIC<args>). Příkaz magic musí být prvním slovem v buňce kódu a umožňovat více řádků obsahu. Kouzelné slovo by mělo být první slovo v buňce. Přidání čehokoli před magií, dokonce i komentáře, způsobí chybu. Další informace o magiích najdete tady.V následující tabulce jsou uvedeny různé magie dostupné prostřednictvím jader.
Magie Příklad Popis help %%helpVygeneruje tabulku všech dostupných magických objektů s příkladem a popisem. informace %%infoVýstupy informací o relaci pro aktuální koncový bod Livy konfigurace %%configure -f{"executorMemory": "1000M","executorCores": 4}Konfiguruje parametry pro vytvoření relace. Příznak vynucení ( -f) je povinný, pokud už byla vytvořena relace, což zajišťuje, že relace se zahodí a znovu vytvoří. Seznam platnýchparametrůch Parametry musí být předány jako řetězec JSON a musí být na dalším řádku za magií, jak je znázorněno v ukázkovém sloupci.sql %%sql -o <variable name>
SHOW TABLESSpustí dotaz Hive na sqlContext. -oPokud je parametr předán, výsledek dotazu se zachová v kontextu %%local Pythonu jako datový rámec Pandas.local %%locala=1Veškerý kód v pozdějších řádcích se spustí místně. Kód musí být platný kód Python2 bez ohledu na to, jaké jádro používáte. Takže i když %%localjste při vytváření poznámkového bloku vybrali jádra PySpark3 nebo Spark, musí mít tato buňka jenom platný kód Python2.Protokoly %%logsVypíše protokoly pro aktuální relaci Livy. Odstranit… %%delete -f -s <session number>Odstraní konkrétní relaci aktuálního koncového bodu Livy. Relaci, která se spouští pro samotné jádro, nemůžete odstranit. Vyčištění %%cleanup -fOdstraní všechny relace pro aktuální koncový bod Livy, včetně relace tohoto poznámkového bloku. Příznak síly -f je povinný. Poznámka:
Kromě magie přidané jádrem PySpark můžete také použít integrované magie IPython, včetně
%%sh. Pomocí magie můžete%%shspouštět skripty a blok kódu v hlavním uzlu clusteru.Automatická vizualizace Jádro Pyspark automaticky vizualizuje výstup dotazů Hive a SQL. Můžete si vybrat mezi několika různými typy vizualizací, mezi které patří tabulka, výsečový, spojnicový, plošný, pruhový.
Podporované parametry pomocí magic %%sql
Magic %%sql podporuje různé parametry, které můžete použít k řízení typu výstupu, který obdržíte při spouštění dotazů. V následující tabulce je uveden výstup.
| Parametr | Příklad | Popis |
|---|---|---|
| -o | -o <VARIABLE NAME> |
Tento parametr použijte k zachování výsledku dotazu v kontextu %%local Pythonu jako datového rámce Pandas . Název proměnné datového rámce je zadaný název proměnné. |
| -q | -q |
Tento parametr použijte k vypnutí vizualizací buňky. Pokud nechcete automaticky zobrazit obsah buňky a jen ji chcete zachytit jako datový rámec, použijte -q -o <VARIABLE>. Pokud chcete vizualizace vypnout bez zachycení výsledků (například pro spuštění dotazu SQL, jako je CREATE TABLE příkaz), použijte -q bez zadání argumentu -o . |
| -m | -m <METHOD> |
Kde METODA buď vezme , nebo vzorek (výchozí hodnota se vezme). Pokud je takemetoda , jádro vybere prvky z horní části sady výsledků dat určené MAXROWS (popsané dále v této tabulce). Pokud je metoda vzorek, jádro náhodně vzorkuje prvky sady dat podle parametru -r popsaného dále v této tabulce. |
| -r | -r <FRACTION> |
Tady ZLOMEK je číslo s plovoucí desetinnou čárkou mezi 0,0 a 1,0. Pokud je sampleukázková metoda pro dotaz SQL , jádro náhodně vzorkuje zadaný zlomek prvků sady výsledků za vás. Pokud například spustíte dotaz SQL s argumenty -m sample -r 0.01, pak se náhodně vzorkuje 1 % řádků výsledku. |
| -n | -n <MAXROWS> |
MAXROWS je celočíselná hodnota. Jádro omezuje počet výstupních řádků na MAXROWS. Pokud je parametr MAXROWS záporným číslem, například -1, počet řádků v sadě výsledků není omezen. |
Příklad:
%%sql -q -m sample -r 0.1 -n 500 -o query2
SELECT * FROM hivesampletable
Výše uvedený příkaz provede následující akce:
- Vybere všechny záznamy z hivesampletable.
- Protože používáme -q, vypne se automatickávisualizace.
- Protože používáme
-m sample -r 0.1 -n 500, náhodně vzorkuje 10 % řádků v hivesampletable a omezuje velikost sady výsledků na 500 řádků. - A konečně, protože jsme ho také použili
-o query2, uloží výstup do datového rámce s názvem query2.
Důležité informace při používání nových jader
Bez ohledu na to, které jádro použijete, ponechají poznámkové bloky spuštěné, spotřebovávají prostředky clusteru. S těmito jádry, protože kontexty jsou přednastavené, jednoduše ukončíte poznámkové bloky, nezabije kontext. A proto se prostředky clusteru budou dál používat. Osvědčeným postupem je použít možnost Zavřít a zastavit v nabídce Soubor poznámkového bloku, až poznámkový blok dokončíte. Uzavření ukončí kontext a potom poznámkový blok ukončí.
Kde jsou poznámkové bloky uložené?
Pokud váš cluster používá Azure Storage jako výchozí účet úložiště, ukládají se poznámkové bloky Jupyter do účtu úložiště ve složce /HdiNotebooks . Poznámkové bloky, textové soubory a složky, které vytvoříte z Jupyteru, jsou přístupné z účtu úložiště. Pokud například použijete Jupyter k vytvoření složky myfolder a poznámkového bloku myfolder/mynotebook.ipynb, můžete k ho v /HdiNotebooks/myfolder/mynotebook.ipynb rámci účtu úložiště přistupovat. Opak je také pravdivý, to znamená, že pokud poznámkový blok nahrajete přímo do svého účtu úložiště, /HdiNotebooks/mynotebook1.ipynbpoznámkový blok se zobrazí i z Jupyteru. Poznámkové bloky zůstanou v účtu úložiště i po odstranění clusteru.
Poznámka:
Clustery HDInsight se službou Azure Data Lake Storage jako výchozí úložiště neukládají poznámkové bloky do přidruženého úložiště.
Způsob ukládání poznámkových bloků do účtu úložiště je kompatibilní s Apache Hadoop HDFS. Pokud do clusteru SSH přejdete, můžete použít příkazy pro správu souborů:
| Příkaz | Popis |
|---|---|
hdfs dfs -ls /HdiNotebooks |
# Vypsat vše v kořenovém adresáři – vše v tomto adresáři je viditelné pro Jupyter z domovské stránky |
hdfs dfs –copyToLocal /HdiNotebooks |
# Stáhněte si obsah složky HdiNotebooks. |
hdfs dfs –copyFromLocal example.ipynb /HdiNotebooks |
# Nahrajte poznámkový blok example.ipynb do kořenové složky, aby byl viditelný z Jupyteru. |
Bez ohledu na to, jestli cluster jako výchozí účet úložiště používá Azure Storage nebo Azure Data Lake Storage, ukládají se poznámkové bloky také na hlavním uzlu /var/lib/jupyterclusteru .
Podporovaný prohlížeč
Poznámkové bloky Jupyter v clusterech Spark HDInsight se podporují jenom v Prohlížeči Google Chrome.
Návrhy
Nová jádra se vyvíjejí ve fázi vývoje a budou v průběhu času vyspělá. Rozhraní API se tedy můžou měnit, jak se tato jádra zralá. Vážíme si jakékoli zpětné vazby, které máte při používání těchto nových jader. Zpětná vazba je užitečná při formování konečné verze těchto jader. Komentáře nebo názory můžete zanechat v části Váš názor v dolní části tohoto článku.