Protokolování a zobrazení metrik a souborů protokolů v1
PLATÍ PRO: Python SDK azureml v1
Python SDK azureml v1
Protokolujte informace v reálném čase pomocí výchozího balíčku pro protokolování Pythonu i funkcí specifických pro sadu Azure Machine Learning Python SDK. Můžete protokolovat místně a odesílat protokoly do svého pracovního prostoru na portálu.
Protokoly vám pomohou při diagnostice chyb a upozornění a také při sledování metriky výkonu, jako jsou parametry a výkon modelu. V tomto článku se dozvíte, jak povolit protokolování v následujících scénářích:
- Metriky spouštění protokolů
- Interaktivní trénovací relace
- Odesílání trénovacích úloh pomocí ScriptRunConfig
- Nastavení
loggingnativní pro Python - Protokolování z dalších zdrojů
Tip
V tomto článku se dozvíte, jak monitorovat proces trénování modelu. Pokud vás zajímá monitorování využití prostředků a událostí ze služby Azure Machine Learning, jako jsou kvóty, dokončená trénovací spuštění nebo dokončená nasazení modelu, přečtěte si téma Monitorování služby Azure Machine Learning.
Datové typy
Můžete protokolovat různé datové typy, včetně skalárních hodnot, seznamů, tabulek, obrázků, adresářů a dalších prvků. Další informace a ukázky kódu v Pythonu pro různé datové typy najdete na referenční stránce k třídě Run.
Protokolování metrik spuštění
Pomocí následujících metod v rozhraních API protokolování můžete ovlivnit vizualizace metrik. Všimněte si limitů služby pro tyto protokolované metriky.
| Zaprotokolovaná hodnota | Příklad kódu | Formátování na portálu |
|---|---|---|
| Protokolování pole číselných hodnot | run.log_list(name='Fibonacci', value=[0, 1, 1, 2, 3, 5, 8, 13, 21, 34, 55, 89]) |
Spojnicový graf s jednou proměnnou |
| Zaznamená jednu číselnou hodnotu se stejným názvem metriky, který se opakovaně používá (například ze smyčky for). | for i in tqdm(range(-10, 10)): run.log(name='Sigmoid', value=1 / (1 + np.exp(-i))) angle = i / 2.0 |
Spojnicový graf s jednou proměnnou |
| Opakované protokolování řádku se 2 číselnými sloupci | run.log_row(name='Cosine Wave', angle=angle, cos=np.cos(angle)) sines['angle'].append(angle) sines['sine'].append(np.sin(angle)) |
Dvoumíselný spojnicový graf |
| Tabulka protokolů se 2 číselnými sloupci | run.log_table(name='Sine Wave', value=sines) |
Dvoumíselný spojnicový graf |
| Obrázek protokolu | run.log_image(name='food', path='./breadpudding.jpg', plot=None, description='desert') |
Tato metoda slouží k protokolování souboru obrázku nebo diagramu matplotlib do spuštění. Tyto image budou viditelné a srovnatelné v záznamu spuštění. |
Protokolování pomocí MLflow
Doporučujeme protokolovat modely, metriky a artefakty pomocí MLflow, protože je opensourcový a podporuje místní režim přenositelnosti cloudu. Následující tabulka a příklady kódu ukazují, jak pomocí MLflow protokolovat metriky a artefakty z trénovacích běhů. Přečtěte si další informace o metodách protokolování a vzorech návrhu MLflow.
Nezapomeňte nainstalovat mlflow balíčky pip azureml-mlflow do pracovního prostoru.
pip install mlflow
pip install azureml-mlflow
Nastavte identifikátor URI sledování MLflow tak, aby odkazoval na back-end služby Azure Machine Learning, aby se zajistilo, že se vaše metriky a artefakty zaprotokolují do vašeho pracovního prostoru.
from azureml.core import Workspace
import mlflow
from mlflow.tracking import MlflowClient
ws = Workspace.from_config()
mlflow.set_tracking_uri(ws.get_mlflow_tracking_uri())
mlflow.create_experiment("mlflow-experiment")
mlflow.set_experiment("mlflow-experiment")
mlflow_run = mlflow.start_run()
| Zaprotokolovaná hodnota | Příklad kódu | Notes |
|---|---|---|
| Protokolování číselné hodnoty (int nebo float) | mlflow.log_metric('my_metric', 1) |
|
| Protokolování logické hodnoty | mlflow.log_metric('my_metric', 0) |
0 = Pravda, 1 = Nepravda |
| Protokolování řetězce | mlflow.log_text('foo', 'my_string') |
Zaprotokolováno jako artefakt |
| Protokolování metrik numpy nebo objektů obrázků PIL | mlflow.log_image(img, 'figure.png') |
|
| Log matlotlib plot or image file | mlflow.log_figure(fig, "figure.png") |
Zobrazení metrik spuštění prostřednictvím sady SDK
Metriky vytrénovaného modelu můžete zobrazit pomocí run.get_metrics().
from azureml.core import Run
run = Run.get_context()
run.log('metric-name', metric_value)
metrics = run.get_metrics()
# metrics is of type Dict[str, List[float]] mapping metric names
# to a list of the values for that metric in the given run.
metrics.get('metric-name')
# list of metrics in the order they were recorded
K informacím o spuštění můžete přistupovat také pomocí MLflow prostřednictvím vlastností dat a informací objektu spuštění. Další informace najdete v dokumentaci k objektům MLflow.entities.Run.
Po dokončení spuštění ho můžete načíst pomocí MlFlowClient().
from mlflow.tracking import MlflowClient
# Use MlFlow to retrieve the run that was just completed
client = MlflowClient()
finished_mlflow_run = MlflowClient().get_run(mlflow_run.info.run_id)
Metriky, parametry a značky spuštění můžete zobrazit v datovém poli objektu run.
metrics = finished_mlflow_run.data.metrics
tags = finished_mlflow_run.data.tags
params = finished_mlflow_run.data.params
Poznámka:
Slovník metrik pod položkou mlflow.entities.Run.data.metrics vrátí pouze naposledy zaprotokolovanou hodnotu pro daný název metriky. Pokud například protokolujete v pořadí 1, pak 2, pak 3, pak 4 na metriku s názvem sample_metric, pouze 4 se nachází ve slovníku metrik pro sample_metric.
Pokud chcete získat všechny metriky protokolované pro konkrétní název metriky, můžete použít MlFlowClient.get_metric_history().
Zobrazení metrik spuštění v uživatelském rozhraní studia
V studio Azure Machine Learning můžete procházet dokončené záznamy spuštění, včetně protokolovaných metrik.
Přejděte na kartu Experimenty . Pokud chcete zobrazit všechna spuštění v pracovním prostoru v rámci experimentů, vyberte kartu Všechna spuštění . Procházením podrobností o spuštěních pro konkrétní experimenty můžete použít filtr Experiment v horním řádku nabídek.
V individuálním zobrazení Experiment vyberte kartu Všechny experimenty . Na řídicím panelu spuštění experimentu můžete zobrazit sledované metriky a protokoly pro každé spuštění.
Můžete také upravit tabulku seznamu spuštění a vybrat několik spuštění a zobrazit buď poslední, minimální nebo maximální zaprotokolovanou hodnotu pro vaše spuštění. Přizpůsobte si grafy a porovnejte hodnoty protokolovaných metrik a agregace napříč několika spuštěními. Na ose y grafu můžete vykreslit více metrik a přizpůsobit osu x tak, aby vykreslovala protokolované metriky.
Zobrazení a stažení souborů protokolu spuštění
Soubory protokolů jsou základním prostředkem pro ladění úloh Azure Machine Learning. Po odeslání trénovací úlohy přejděte k podrobnostem konkrétního spuštění a zobrazte jeho protokoly a výstupy:
- Přejděte na kartu Experimenty .
- Vyberte ID spuštění pro konkrétní spuštění.
- V horní části stránky vyberte Výstupy a protokoly .
- Výběrem možnosti Stáhnout vše stáhnete všechny protokoly do složky ZIP.
- Jednotlivé soubory protokolu můžete stáhnout také tak, že zvolíte soubor protokolu a vyberete Stáhnout.
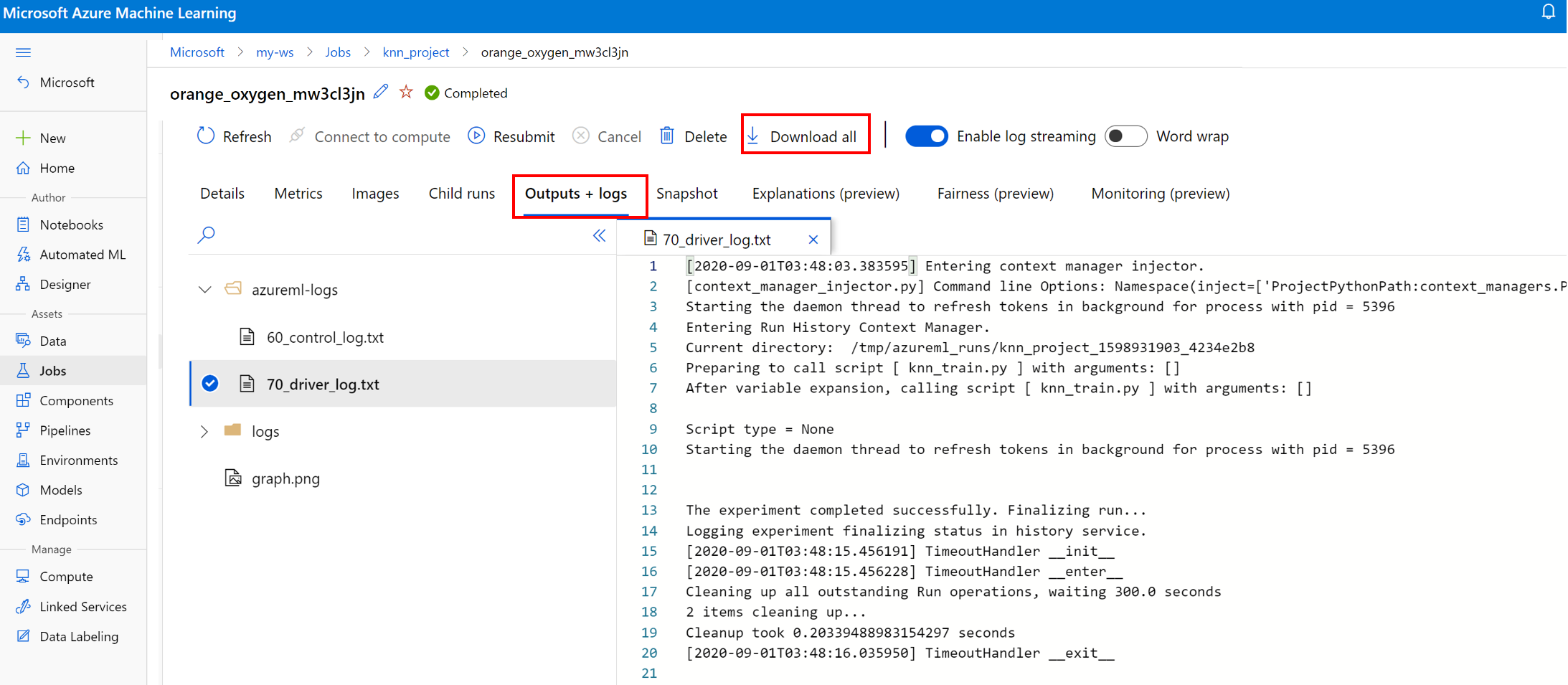
user_logs složka
Tato složka obsahuje informace o protokolech generovaných uživatelem. Tato složka je ve výchozím nastavení otevřená a je vybraná std_log.txt protokol. Std_log.txt se zobrazují protokoly kódu (například příkazy print). Tento soubor obsahuje stdout protokoly a stderr protokoly z řídicího skriptu a trénovacího skriptu, jeden pro jednotlivé procesy. Ve většině případů tady budete monitorovat protokoly.
složka system_logs
Tato složka obsahuje protokoly vygenerované službou Azure Machine Learning a ve výchozím nastavení se zavře. Protokoly vygenerované systémem jsou seskupené do různých složek na základě fáze úlohy v modulu runtime.
Další složky
Pro úlohy trénování ve více výpočetních clusterech se protokoly nacházejí pro každou IP adresu uzlu. Struktura pro každý uzel je stejná jako úlohy s jedním uzlem. Existuje ještě jedna složka protokolů pro celkové spouštění, stderr a protokoly stdout.
Azure Machine Learning během trénování protokoluje informace z různých zdrojů, jako je AutoML nebo kontejner Dockeru, který spouští trénovací úlohu. Mnohé z těchto protokolů nejsou zdokumentované. Pokud narazíte na problémy a obraťte se na podporu Microsoftu, může být během řešení potíží možné tyto protokoly použít.
Interaktivní relace protokolování
Interaktivní relace protokolování se obvykle používají v prostředích poznámkových bloků. Interaktivní relace protokolování se pouštějí pomocí metody Experiment.start_logging(). Všechny metriky zaznamenávané během relace se přidají do záznamu spuštění v experimentu. Metoda run.complete() ukončí relace a označí běh jako dokončený.
Protokoly ScriptRun
V této části se dozvíte, jak přidat kód protokolování do běhů vytvořených při využití konfigurace pomocí třídy ScriptRunConfig. K zapouzdření skriptů a prostředí pro opakovatelná spouštění můžete využít třídu ScriptRunConfig. Tuto možnost můžete také využít pro zobrazení vizuálního widgetu pro Jupyter Notebook pro monitorování.
V tomto příkladu se provede uklizení parametrů přes hodnoty alfa a k zaznamenání výsledků se použije metoda run. log ().
Vytvořte trénovací skript, který obsahuje logiku protokolování:
train.py.# Copyright (c) Microsoft. All rights reserved. # Licensed under the MIT license. from sklearn.datasets import load_diabetes from sklearn.linear_model import Ridge from sklearn.metrics import mean_squared_error from sklearn.model_selection import train_test_split from azureml.core.run import Run import os import numpy as np import mylib # sklearn.externals.joblib is removed in 0.23 try: from sklearn.externals import joblib except ImportError: import joblib os.makedirs('./outputs', exist_ok=True) X, y = load_diabetes(return_X_y=True) run = Run.get_context() X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.2, random_state=0) data = {"train": {"X": X_train, "y": y_train}, "test": {"X": X_test, "y": y_test}} # list of numbers from 0.0 to 1.0 with a 0.05 interval alphas = mylib.get_alphas() for alpha in alphas: # Use Ridge algorithm to create a regression model reg = Ridge(alpha=alpha) reg.fit(data["train"]["X"], data["train"]["y"]) preds = reg.predict(data["test"]["X"]) mse = mean_squared_error(preds, data["test"]["y"]) run.log('alpha', alpha) run.log('mse', mse) model_file_name = 'ridge_{0:.2f}.pkl'.format(alpha) # save model in the outputs folder so it automatically get uploaded with open(model_file_name, "wb") as file: joblib.dump(value=reg, filename=os.path.join('./outputs/', model_file_name)) print('alpha is {0:.2f}, and mse is {1:0.2f}'.format(alpha, mse))Odešlete skript
train.pypro spuštění v prostředí spravovaném uživatelem. K trénování se odešle celá složka skriptu.from azureml.core import ScriptRunConfig src = ScriptRunConfig(source_directory='./scripts', script='train.py', environment=user_managed_env)run = exp.submit(src)Parametr
show_outputzapne podrobné protokolování, které vám umožní zobrazit podrobnosti z procesu trénování a také informace o všech vzdálených prostředcích nebo cílových výpočetních objektech. Pomocí následujícího kódu zapněte podrobné protokolování při odeslání experimentu.run = exp.submit(src, show_output=True)Ve výsledném běhu můžete použít také stejný parametr ve funkci
wait_for_completion.run.wait_for_completion(show_output=True)
Nativní protokolování v Pythonu
Některé protokoly v sadě SDK mohou obsahovat chybu, která dává pokyn k nastavení úrovně protokolování na ladění. Pokud chcete nastavit úroveň protokolování, přidejte do skriptu následující kód.
import logging
logging.basicConfig(level=logging.DEBUG)
Další zdroje protokolování
Azure Machine Learning může během trénování protokolovat také informace z jiných zdrojů, jako jsou například spuštění automatizovaného strojové učení nebo kontejnery Docker, které spouští úlohy. Tyto protokoly nejsou zdokumentované, ale pokud narazíte na problémy a kontaktujete podporu Microsoftu, dají se tyto protokoly využít při řešení potíží.
Informace o protokolování metrik v designeru služby Azure Machine Learning najdete v tématu věnovaném postupu při protokolování metrik v designeru.
Příklady poznámkových bloků
Následující poznámkové bloky ukazují koncepty popsané v tomto článku:
- how-to-use-azureml/training/train-on-local
- how-to-use-azureml/track-and-monitor-experiments/logging-api
Postupujte podle pokynů v článku věnovaném využití poznámkových bloků Jupyter k prozkoumání této služby a zjistěte, jak provozovat poznámkové bloky.
Další kroky
Další informace o tom, jak používat Azure Machine Learning, najdete v těchto článcích:
- Příklad postupu při registraci nejvhodnějšího modelu a jeho nasazení najdete v kurzu Trénování modelu klasifikace obrázků s Azure Machine Learning.