Interaktivní vývoj jazyka R
PLATÍ PRO: Rozšíření Azure CLI ml v2 (aktuální)Python SDK azure-ai-ml v2 (aktuální)
Rozšíření Azure CLI ml v2 (aktuální)Python SDK azure-ai-ml v2 (aktuální)
Tento článek ukazuje, jak používat R v studio Azure Machine Learning ve výpočetní instanci, která spouští jádro R v poznámkovém bloku Jupyter.
Oblíbené integrované vývojové prostředí RStudio funguje také. RStudio nebo Posit Workbench můžete nainstalovat do vlastního kontejneru ve výpočetní instanci. To ale má omezení při čtení a zápisu do pracovního prostoru Azure Machine Learning.
Důležité
Kód uvedený v tomto článku funguje ve výpočetní instanci služby Azure Machine Learning. Výpočetní instance má prostředí a konfigurační soubor nezbytný pro úspěšné spuštění kódu.
Požadavky
- Pokud ještě nemáte předplatné Azure, vytvořte si napřed bezplatný účet. Vyzkoušejte si bezplatnou nebo placenou verzi služby Azure Machine Learning ještě dnes
- Pracovní prostor Azure Machine Learning a výpočetní instance
- Základní pochopení používání poznámkových bloků Jupyter v studio Azure Machine Learning Další informace najdete v části Vývoj modelů na cloudové pracovní stanici .
Spuštění jazyka R v poznámkovém bloku v sadě Studio
Poznámkový blok použijete ve svém pracovním prostoru Azure Machine Learning ve výpočetní instanci.
Přihlášení k studio Azure Machine Learning
Otevřete pracovní prostor, pokud ještě není otevřený.
V levém navigačním panelu vyberte Poznámkové bloky.
Vytvoření nového poznámkového bloku s názvem RunR.ipynb
Tip
Pokud si nejste jistí, jak vytvářet a pracovat s poznámkovými bloky v sadě Studio, přečtěte si téma Spouštění poznámkových bloků Jupyter ve vašem pracovním prostoru.
Vyberte poznámkový blok.
Na panelu nástrojů poznámkového bloku se ujistěte, že je spuštěná výpočetní instance. Pokud ne, spusťte ho teď.
Na panelu nástrojů poznámkového bloku přepněte jádro na R.


Poznámkový blok je teď připravený ke spuštění příkazů jazyka R.
Přístup k datům
Soubory můžete nahrát do prostředku úložiště souborů pracovního prostoru a pak k těmto souborům přistupovat v jazyce R. U souborů uložených v datových prostředcích Azure nebo v datech z úložišť dat však musíte nainstalovat některé balíčky.
Tato část popisuje, jak pomocí Pythonu reticulate a balíčku načíst datové prostředky a úložiště dat do jazyka R z interaktivní relace. Ke čtení tabulkových dat jako datových rámců Pandas použijete azureml-fsspec balíček Pythonu a reticulate balíček R. Tato část obsahuje také příklad čtení datových prostředků a úložišť dat do R data.frame.
Instalace těchto balíčků:
Ve výpočetní instanci vytvořte nový soubor s názvem setup.sh.
Zkopírujte tento kód do souboru:
#!/bin/bash set -e # Installs azureml-fsspec in default conda environment # Does not need to run as sudo eval "$(conda shell.bash hook)" conda activate azureml_py310_sdkv2 pip install azureml-fsspec conda deactivate # Checks that version 1.26 of reticulate is installed (needs to be done as sudo) sudo -u azureuser -i <<'EOF' R -e "if (packageVersion('reticulate') >= 1.26) message('Version OK') else install.packages('reticulate')" EOFVýběrem možnosti Uložit a spustit skript v terminálu spusťte skript.
Instalační skript zpracovává tyto kroky:
pipnainstalujeazureml-fsspecve výchozím prostředí Conda pro výpočetní instanci.- V případě potřeby nainstaluje balíček R
reticulate(verze musí být 1.26 nebo vyšší).
Čtení tabulkových dat z registrovaných datových prostředků nebo úložišť dat
Pro data uložená v datovém prostředku vytvořeném ve službě Azure Machine Learning použijte tento postup ke čtení tohoto tabulkového souboru do datového rámce Pandas nebo R data.frame:
Poznámka:
Čtení souboru s reticulate tabulkovými daty funguje jenom s tabulkovými daty.
Ujistěte se, že máte správnou verzi souboru
reticulate. V případě verze menší než 1.26 zkuste použít novější výpočetní instanci.packageVersion("reticulate")Načtení
reticulatea nastavení prostředí conda, ve kterémazureml-fsspecbylo nainstalovánolibrary(reticulate) use_condaenv("azureml_py310_sdkv2") print("Environment is set")Vyhledejte cestu URI k datovému souboru.
Nejprve získejte popisovač pracovního prostoru.
py_code <- "from azure.identity import DefaultAzureCredential from azure.ai.ml import MLClient credential = DefaultAzureCredential() ml_client = MLClient.from_config(credential=credential)" py_run_string(py_code) print("ml_client is configured")Tento kód použijte k načtení prostředku. Nezapomeňte nahradit
<MY_NAME>a<MY_VERSION>nahradit názvem a číslem datového assetu.Tip
V sadě Studio vyberte v levém navigačním panelu data název a číslo verze datového prostředku.
# Replace <MY_NAME> and <MY_VERSION> with your values py_code <- "my_name = '<MY_NAME>' my_version = '<MY_VERSION>' data_asset = ml_client.data.get(name=my_name, version=my_version) data_uri = data_asset.path"Pokud chcete načíst identifikátor URI, spusťte kód.
py_run_string(py_code) print(paste("URI path is", py$data_uri))
Pomocí funkcí pro čtení pandas můžete číst soubor nebo soubory do prostředí R.
pd <- import("pandas") cc <- pd$read_csv(py$data_uri) head(cc)
Můžete také použít identifikátor URI úložiště dat pro přístup k různým souborům v registrovaném úložišti dat a číst tyto prostředky do R data.frame.
V tomto formátu vytvořte identifikátor URI úložiště dat pomocí vlastních hodnot:
subscription <- '<subscription_id>' resource_group <- '<resource_group>' workspace <- '<workspace>' datastore_name <- '<datastore>' path_on_datastore <- '<path>' uri <- paste0("azureml://subscriptions/", subscription, "/resourcegroups/", resource_group, "/workspaces/", workspace, "/datastores/", datastore_name, "/paths/", path_on_datastore)Tip
Místo zapamatování formátu identifikátoru URI úložiště dat můžete z uživatelského rozhraní studia zkopírovat a vložit identifikátor URI úložiště dat, pokud znáte úložiště dat, ve kterém se soubor nachází:
- Přejděte do souboru nebo složky, kterou chcete přečíst do jazyka R.
- Vyberte tři tečky (...) vedle něj.
- Vyberte z nabídky Kopírovat identifikátor URI.
- Vyberte identifikátor URI úložiště dat, který chcete zkopírovat do poznámkového bloku nebo skriptu.
Všimněte si, že v kódu musíte vytvořit proměnnou
<path>.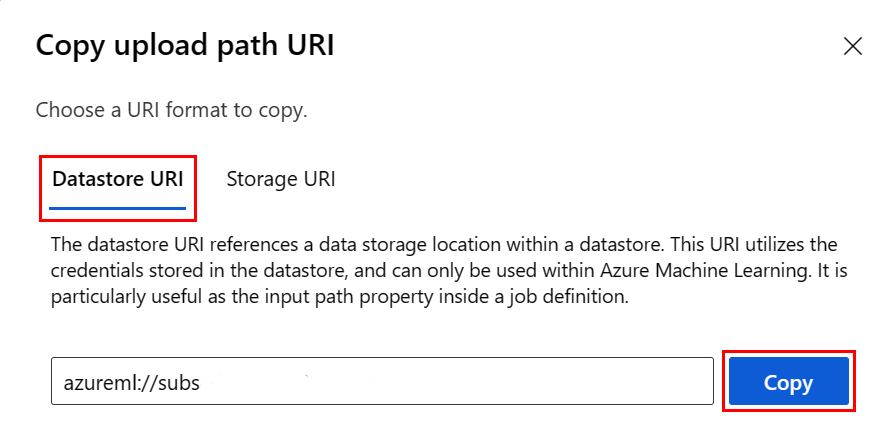
Vytvořte objekt úložiště souborů pomocí dříve uvedeného identifikátoru URI:
fs <- azureml.fsspec$AzureMachineLearningFileSystem(uri, sep = "")
- Čtení do R
data.frame:
df <- with(fs$open("<path>)", "r") %as% f, {
x <- as.character(f$read(), encoding = "utf-8")
read.csv(textConnection(x), header = TRUE, sep = ",", stringsAsFactors = FALSE)
})
print(df)
Instalace balíčků R
Výpočetní instance má mnoho předinstalovaných balíčků R.
Pokud chcete nainstalovat další balíčky, musíte explicitně uvést umístění a závislosti.
Tip
Když vytváříte nebo používáte jinou výpočetní instanci, musíte znovu nainstalovat všechny balíčky, které jste nainstalovali.
Například pro instalaci tsibble balíčku:
install.packages("tsibble",
dependencies = TRUE,
lib = "/home/azureuser")
Poznámka:
Pokud instalujete balíčky v rámci relace R, která běží v poznámkovém bloku Jupyter, dependencies = TRUE je nutné. Jinak závislé balíčky nebudou automaticky nainstalovány. Umístění lib je také nutné k instalaci ve správném umístění výpočetní instance.
Načtení knihoven R
Přidejte /home/azureuser do cesty knihovny jazyka R.
.libPaths("/home/azureuser")
Tip
Aby bylo možné získat přístup k uživatelským nainstalovaným knihovnám, musíte aktualizovat v každém interaktivním .libPaths skriptu jazyka R. Přidejte tento kód na začátek každého interaktivního skriptu jazyka R nebo poznámkového bloku.
Po aktualizaci knihovny libPath načtěte knihovny obvyklým způsobem.
library('tsibble')
Použití R v poznámkovém bloku
Kromě výše popsaných problémů použijte R stejně jako v jakémkoli jiném prostředí, včetně místní pracovní stanice. V poznámkovém bloku nebo skriptu můžete číst a zapisovat do cesty, kam je poznámkový blok nebo skript uložený.
Poznámka:
- Z interaktivní relace jazyka R můžete zapisovat pouze do systému souborů pracovního prostoru.
- Z interaktivní relace jazyka R nemůžete pracovat s MLflow (například s modelem protokolu nebo registrem dotazů).