Generování zodpovědných přehledů AI v uživatelském rozhraní studia
V tomto článku vytvoříte řídicí panel Zodpovědné AI a přehled výkonnostních metrik (Preview) bez kódu v uživatelském rozhraní studio Azure Machine Learning.
Důležité
Tato funkce je v současné době ve verzi Public Preview. Tato verze Preview je poskytována bez smlouvy o úrovni služeb a nedoporučujeme ji pro produkční úlohy. Některé funkce se nemusí podporovat nebo mohou mít omezené možnosti.
Další informace najdete v dodatečných podmínkách použití pro verze Preview v Microsoft Azure.
Pokud chcete získat přístup k průvodci generováním řídicího panelu a vygenerovat řídicí panel zodpovědné umělé inteligence, postupujte takto:
Zaregistrujte svůj model ve službě Azure Machine Learning, abyste měli přístup k prostředí bez kódu.
V levém podokně studio Azure Machine Learning vyberte kartu Modely.
Vyberte zaregistrovaný model, pro který chcete vytvořit přehledy zodpovědné umělé inteligence, a pak vyberte kartu Podrobnosti .
Vyberte Vytvořit řídicí panel zodpovědné umělé inteligence (Preview).


Další podporované typy modelů a omezení najdete na řídicím panelu Zodpovědné AI v podporovaných scénářích a omezeních.
Průvodce poskytuje rozhraní pro zadání všech potřebných parametrů pro vytvoření řídicího panelu Zodpovědné umělé inteligence bez nutnosti dotykového ovládání kódu. Prostředí se provádí zcela v uživatelském rozhraní studio Azure Machine Learning. Studio představuje tok s asistencí a instruktážní text, který vám pomůže s kontextem různých možností, kterými komponentami zodpovědné umělé inteligence chcete řídicí panel naplnit.
Průvodce je rozdělený do pěti částí:
- Trénovací datové sady
- Testovací datová sada
- Úloha modelování
- Komponenty řídicího panelu
- Parametry komponent
- Konfigurace experimentu
Výběr datových sad
V prvních dvou částech vyberete trénovací a testovací datové sady, které jste použili při trénování modelu k vygenerování přehledů o ladění modelu. U komponent, jako je kauzální analýza, která nevyžaduje model, použijete datovou sadu trénování k trénování kauzálního modelu k vygenerování kauzálních přehledů.
Poznámka:
Podporují se pouze formáty tabulkových datových sad v tabulce ML.
Vyberte datovou sadu pro trénování: V seznamu registrovaných datových sad v pracovním prostoru Azure Machine Learning vyberte datovou sadu, kterou chcete použít ke generování přehledů zodpovědné umělé inteligence pro komponenty, jako jsou vysvětlení modelu a analýza chyb.

Vyberte datovou sadu pro testování: V seznamu registrovaných datových sad vyberte datovou sadu, kterou chcete použít k naplnění vizualizací řídicího panelu Zodpovědné umělé inteligence.

Pokud není uvedená trénování nebo testovací datová sada, kterou chcete použít, vyberte Vytvořit a nahrajte ji.


Výběr úlohy modelování
Po výběru datových sad vyberte typ úlohy modelování, jak je znázorněno na následujícím obrázku:

Výběr komponent řídicího panelu
Řídicí panel Zodpovědné AI nabízí dva profily pro doporučené sady nástrojů, které můžete vygenerovat:
Ladění modelů: Pochopení a ladění chybných kohort dat v modelu strojového učení pomocí analýzy chyb, kontrafaktuální příklady citlivostní analýzy a vysvětlení modelů.
Zásahy v reálném životě: Pochopení a ladění chybných kohort dat v modelu strojového učení pomocí kauzální analýzy.
Poznámka:
Klasifikace více tříd nepodporuje profil analýzy zásahů v reálném životě.

- Vyberte profil, který chcete použít.
- Vyberte Další.
Konfigurace parametrů pro komponenty řídicího panelu
Po výběru profilu se zobrazí parametry komponenty pro podokno konfigurace ladění modelu pro odpovídající komponenty.

Parametry komponenty pro ladění modelu:
Cílová funkce (povinné):: Určete funkci, kterou byl model natrénován k predikci.
Kategorické funkce: Označuje, které funkce jsou kategorické, aby se správně vykreslovaly jako hodnoty kategorií v uživatelském rozhraní řídicího panelu. Toto pole je předem načteno na základě metadat datové sady.
Generování stromu chyb a heat mapy: Zapněte a vypněte komponentu analýzy chyb pro řídicí panel Zodpovědné umělé inteligence.
Funkce pro chybovou heat mapu: Vyberte až dvě funkce, pro které chcete předem vygenerovat chybovou heat mapu.
Pokročilá konfigurace: Zadejte další parametry, například Maximální hloubka stromu chyb, Počet listů ve stromu chyb a Minimální počet vzorků v každém uzlu typu list.
Vygenerujte kontrafaktuální příklady citlivostní citlivosti: Zapněte a vypněte, aby se pro řídicí panel Zodpovědné umělé inteligence vygenerovala komponenta citlivostní citlivostní analýza.
Počet kontrafaktual (povinné):: Zadejte počet kontrafaktuálních příkladů, které chcete vygenerovat na datový bod. Aby bylo možné dosáhnout požadované předpovědi, je potřeba vygenerovat minimálně 10, aby bylo možné zobrazit pruhový graf funkcí, které byly v průměru nejvýraznější.
Rozsah predikcí hodnot (povinné):: Určete pro regresní scénáře rozsah, ve kterém chcete použít kontrafaktuální příklady, ve kterých mají být hodnoty predikce. U scénářů binární klasifikace se rozsah automaticky nastaví tak, aby vygeneroval kontrafaktuals pro opačnou třídu každého datového bodu. V případě scénářů s více klasifikacemi můžete pomocí rozevíracího seznamu určit, jakou třídu má každý datový bod předpovědět.
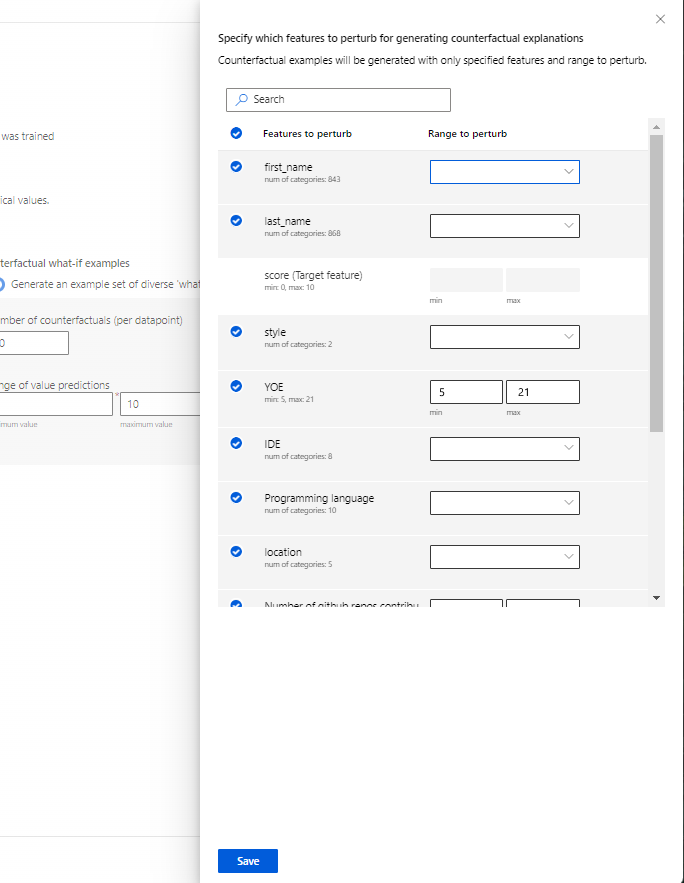
Určete, které funkce se mají perturbovat: Ve výchozím nastavení budou všechny funkce perturbedné. Pokud ale chcete, aby byly perturbedné pouze konkrétní funkce, vyberte Určit, které funkce se mají perturb použít pro generování kontrafaktuálních vysvětlení , aby se zobrazilo podokno se seznamem funkcí, které chcete vybrat.
Když vyberete Možnost Určit, které funkce se mají perturb použít, můžete určit rozsah, ve kterém chcete povolit perturbace. Příklad: Pro funkci YOE (Roky zkušeností) určete, že kontrafaktuální hodnoty by měly mít hodnoty funkcí v rozsahu od 10 do 21 místo výchozích hodnot 5 až 21.
Vygenerování vysvětlení: Zapněte a vypněte komponentu vysvětlení modelu pro řídicí panel Zodpovědné umělé inteligence. Není nutná žádná konfigurace, protože k vygenerování důležitosti funkcí se použije výchozí popisovač neprůpažných rámečků.

Případně pokud vyberete profil zásahů v reálném životě, zobrazí se následující obrazovka, která vygeneruje kauzální analýzu. Pomůže vám to pochopit kauzální účinky funkcí, které chcete "léčit" na určitý výsledek, který chcete optimalizovat.

Parametry komponent pro zásahy v reálném životě využívají kauzální analýzu. Postupujte následovně:
- Cílová funkce (povinné):: Zvolte výsledek, pro který chcete vypočítat kauzální účinky.
- Funkce léčby (povinné): Zvolte jednu nebo více funkcí, které vás zajímají o změnu ("zpracování") pro optimalizaci cílového výsledku.
- Kategorické funkce: Označuje, které funkce jsou kategorické, aby se správně vykreslovaly jako hodnoty kategorií v uživatelském rozhraní řídicího panelu. Toto pole je předem načteno na základě metadat datové sady.
- Upřesňující nastavení: Zadejte další parametry pro kauzální analýzu, jako jsou heterogenní funkce (to znamená další funkce, které vám pomohou pochopit kauzální segmentaci v analýze, kromě funkcí vaší léčby) a jaký kauzální model chcete použít.
Konfigurace experimentu
Nakonec nakonfigurujte experiment tak, aby zahájil úlohu a vygeneroval řídicí panel Zodpovědné umělé inteligence.

V podokně konfigurace trénovací úlohy nebo experimentu postupujte takto:
- Název: Dejte řídicímu panelu jedinečný název, abyste ho mohli odlišit při prohlížení seznamu řídicích panelů pro daný model.
- Název experimentu: Vyberte existující experiment, ve které chcete úlohu spustit, nebo vytvořte nový experiment.
- Existující experiment: V rozevíracím seznamu vyberte existující experiment.
- Vyberte typ výpočetních prostředků: Zadejte typ výpočetních prostředků, který chcete použít ke spuštění úlohy.
- Vyberte výpočetní prostředky: V rozevíracím seznamu vyberte výpočetní prostředky, které chcete použít. Pokud neexistují žádné výpočetní prostředky, vyberte znaménko plus (+), vytvořte nový výpočetní prostředek a pak seznam aktualizujte.
- Popis: Přidejte delší popis řídicího panelu zodpovědné umělé inteligence.
- Značky: Přidejte do tohoto řídicího panelu zodpovědné umělé inteligence všechny značky.
Po dokončení konfigurace experimentu vyberte Vytvořit a začněte generovat řídicí panel Zodpovědné umělé inteligence. Budete přesměrováni na stránku experimentu, abyste mohli sledovat průběh vaší úlohy pomocí odkazu na výsledný řídicí panel Zodpovědné AI ze stránky úlohy po dokončení.
Pokud chcete zjistit, jak zobrazit a používat řídicí panel Zodpovědné AI, použijte řídicí panel Zodpovědné AI v studio Azure Machine Learning.
Generování přehledu výkonnostních metrik zodpovědné umělé inteligence (Preview)
Po vytvoření řídicího panelu můžete pomocí uživatelského rozhraní bez kódu v studio Azure Machine Learning přizpůsobit a vygenerovat přehled výkonnostních metrik Zodpovědné umělé inteligence. To vám umožní sdílet klíčové přehledy o zodpovědném nasazení modelu, jako je nestrannost a důležitost funkcí, s netechnickými a technickými účastníky. Podobně jako při vytváření řídicího panelu můžete pomocí následujícího postupu získat přístup k průvodci generováním přehledu výkonnostních metrik:
- V studio Azure Machine Learning přejděte na kartu Modely z levého navigačního panelu.
- Vyberte registrovaný model, pro který chcete vytvořit přehled výkonnostních metrik, a vyberte kartu Zodpovědná AI .
- Na horním panelu vyberte Vytvořit přehledy zodpovědné umělé inteligence (Preview) a pak vygenerovat nový přehled výkonnostních metrik PDF.
Průvodce vám umožní přizpůsobit přehled výkonnostních metrik PDF bez nutnosti dotykového kódu. Prostředí se provádí zcela v studio Azure Machine Learning, které vám pomůžou kontextovat různé volby uživatelského rozhraní pomocí toku s asistencí a instrukčním textem, které vám pomůžou vybrat komponenty, kterým chcete přehled výkonnostních metrik naplnit. Průvodce je rozdělený do sedmi kroků, přičemž osmý krok (posouzení nestrannosti), který se zobrazí pouze pro modely s kategorickými funkcemi:
- Souhrn přehledu výkonnostních metrik PDF
- Výkon modelu
- Výběr nástroje
- Analýza dat (dříve označovaná jako Průzkumník dat)
- Kauzální analýza
- Interpretovatelnost
- Konfigurace experimentu
- Posouzení nestrannosti (pouze pokud existují kategorické funkce)
Konfigurace přehledu výkonnostních metrik
Nejprve zadejte popisný název přehledu výkonnostních metrik. Můžete také zadat volitelný popis funkce modelu, data, která byla natrénována a vyhodnocena, typ architektury a další.
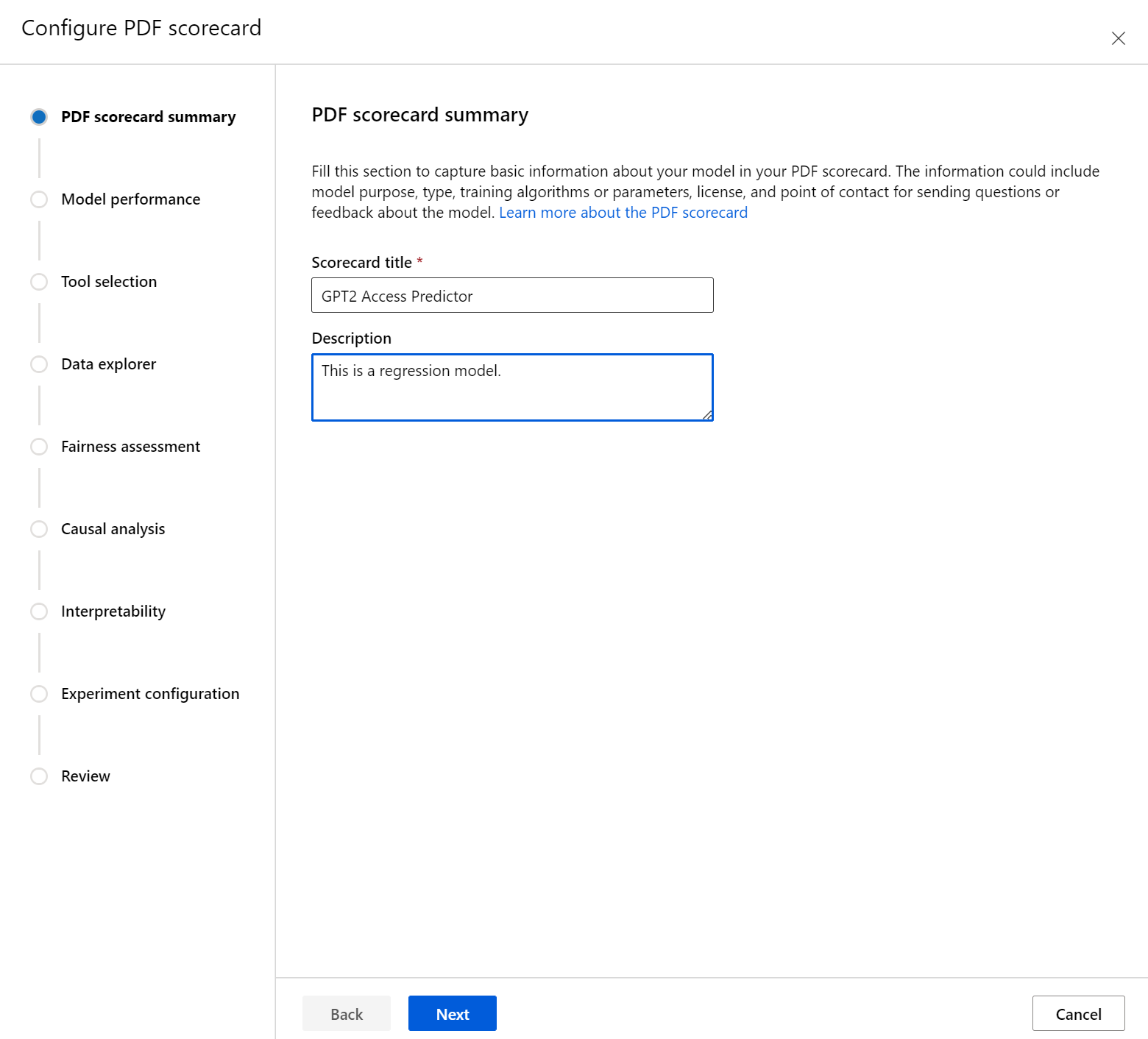
Část Výkon modelu umožňuje začlenit do standardních metrik vyhodnocení modelu přehledu výkonnostních metrik a zároveň nastavit požadované cílové hodnoty pro vybrané metriky. Vyberte požadované metriky výkonu (až tři) a cílové hodnoty pomocí rozevíracích seznamu.

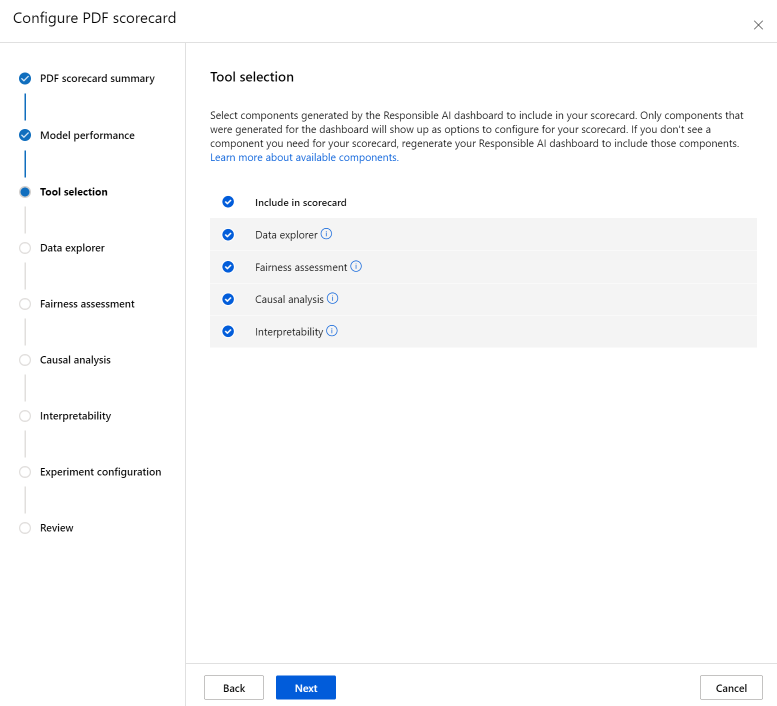
Krok výběru nástroje umožňuje zvolit, které další součásti chcete zahrnout do přehledu výkonnostních metrik. Zaškrtnutím políčka Zahrnout do přehledu výkonnostních metrik zahrňte všechny součásti nebo jednotlivé komponenty zaškrtněte nebo zrušte zaškrtnutí jednotlivých součástí. Výběrem ikony informací ("i" v kruhu) vedle komponent získáte další informace.
Část Analýza dat (dříve označovaná jako Průzkumník dat) umožňuje analýzu kohorty. Tady můžete identifikovat problémy s nadměrnou reprezentací a zjistit, jak jsou data v datové sadě v clusteru, a zjistit, jak predikce modelu ovlivňují konkrétní kohorty dat. Pomocí zaškrtávacích políček v rozevíracím seznamu vyberte funkce, které vás zajímají níže, abyste identifikovali výkon modelu u jejich podkladových kohort.

Část Posouzení nestrannosti může pomoct s posouzením toho, které skupiny lidí můžou negativně ovlivnit predikce modelu strojového učení. V této části jsou dvě pole.
Citlivé funkce: identifikujte vybrané citlivé atributy (například věk, pohlaví) tak, že upřednostníte až 20 podskupin, které chcete prozkoumat a porovnat.
Metrika nestrannosti: Vyberte metriku nestrannosti, která je vhodná pro vaše nastavení (například rozdíl v přesnosti, poměr chybovosti) a určete požadované cílové hodnoty u vybraných metrik nestrannosti. Vybraná metrika spravedlnosti (spárovaná s výběrem rozdílu nebo poměru pomocí přepínače) zachytí rozdíl nebo poměr mezi extrémními hodnotami v podskupinách. (max – min nebo max/min).

Poznámka:
Posouzení nestrannosti je v současné době k dispozici pouze pro kategorické citlivé atributy, jako je pohlaví.
Část Kauzální analýza odpovídá na reálné otázky "co kdyby" o tom, jak by změny léčby ovlivnily skutečný výsledek. Pokud je kauzální komponenta aktivována na řídicím panelu Zodpovědné AI, pro který generujete přehled výkonnostních metrik, není potřeba žádná další konfigurace.

Část Interpretovatelnost generuje popisy pro předpovědi vytvořené modelem strojového učení, které jsou srozumitelné pro člověka. Pomocí vysvětlení modelu můžete porozumět odůvodnění rozhodnutí, která váš model učinil. Výběrem čísla (K) níže zobrazíte nejdůležitější klíčové funkce ovlivňující celkové předpovědi modelu. Výchozí hodnota pro K je 10.

Nakonec nakonfigurujte experiment tak, aby zahájil úlohu pro vygenerování přehledu výkonnostních metrik. Tyto konfigurace jsou stejné jako u řídicího panelu zodpovědné umělé inteligence.

Nakonec zkontrolujte konfigurace a vyberte Vytvořit a spusťte úlohu.
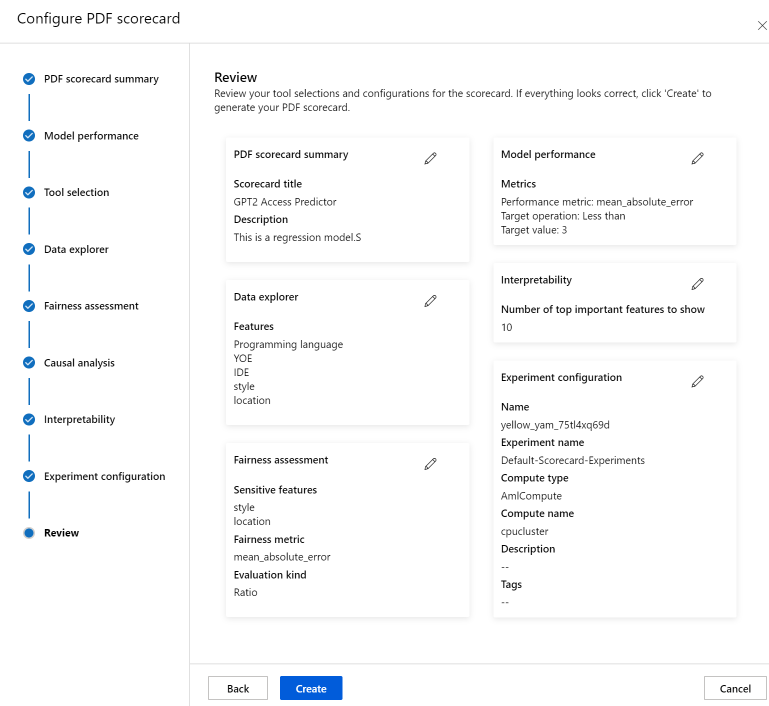
Jakmile ho spustíte, budete přesměrováni na stránku experimentu, abyste mohli sledovat průběh úlohy. Informace o tom, jak zobrazit a používat přehled výkonnostních metrik Zodpovědné AI, najdete v tématu Použití přehledu výkonnostních metrik Zodpovědné AI (Preview).









Další kroky
- Po vygenerování řídicího panelu Zodpovědné umělé inteligence si přečtěte, jak k němu přistupovat a používat ho v studio Azure Machine Learning.
- Přečtěte si další informace o konceptech a technikách řídicího panelu Zodpovědné umělé inteligence.
- Přečtěte si další informace o zodpovědném shromažďování dat.
- Přečtěte si další informace o tom, jak pomocí řídicího panelu Zodpovědné umělé inteligence a přehledu výkonnostních metrik ladit data a modely a informovat o lepším rozhodování v tomto blogovém příspěvku technické komunity.
- Přečtěte si, jak řídicí panel Zodpovědné AI a přehled výkonnostních metrik používala služba NHS (Uk National Health Service) v příběhu o skutečném životě zákazníka.
- Prozkoumejte funkce řídicího panelu Zodpovědné AI prostřednictvím této interaktivní webové ukázky AI Labu.