Nastavení automatizovaného strojového učení bez kódu pro tabulková data pomocí uživatelského rozhraní studia
V tomto článku jste nastavili automatizované trénovací úlohy strojového učení pomocí automatizovaného strojového učení Azure Machine Learning v studio Azure Machine Learning. Tento přístup umožňuje nastavit úlohu bez psaní jednoho řádku kódu. Automatizované strojové učení je proces, kdy Azure Machine Learning pro vaše konkrétní data vybere nejlepší algoritmus strojového učení. Tento proces umožňuje rychle generovat modely strojového učení. Další informace najdete v přehledu procesu automatizovaného strojového učení.
Tento kurz poskytuje základní přehled pro práci s automatizovaným strojovém učení v sadě Studio. Následující články obsahují podrobné pokyny pro práci s konkrétními modely strojového učení:
- Klasifikace: Kurz: Trénování klasifikačního modelu pomocí automatizovaného strojového učení v sadě Studio
- Prognózování časových řad: Kurz: Prognóza poptávky pomocí automatizovaného strojového učení v sadě Studio
- Zpracování přirozeného jazyka (NLP):: Nastavení automatizovaného strojového učení pro trénování modelu NLP (Azure CLI nebo Python SDK)
- Počítačové zpracování obrazu: Nastavení AutoML pro trénování modelů počítačového zpracování obrazu (Azure CLI nebo Python SDK)
- Regrese: Trénování regresního modelu pomocí automatizovaného strojového učení (Python SDK)
Požadavky
Předplatné Azure. Pro Azure Machine Learning můžete vytvořit bezplatný nebo placený účet .
Pracovní prostor nebo výpočetní instance služby Azure Machine Learning Informace o přípravě těchto prostředků najdete v tématu Rychlý start: Začínáme se službou Azure Machine Learning.
Datový prostředek, který se má použít pro trénovací úlohu automatizovaného strojového učení. Tento kurz popisuje, jak vybrat existující datový prostředek nebo vytvořit datový prostředek ze zdroje dat, jako je místní soubor, webová adresa URL nebo úložiště dat. Další informace najdete v tématu Vytváření a správa datových prostředků.
Důležité
Pro trénovací data existují dva požadavky:
- Data musí být v tabulkové podobě.
- Hodnota, která se má předpovědět ( cílový sloupec), musí být v datech.
Vytvoření experimentu
Následujícím postupem vytvořte a spusťte experiment:
Přihlaste se k studio Azure Machine Learning a vyberte své předplatné a pracovní prostor.
V nabídce vlevo vyberte automatizované strojové učení v části Vytváření obsahu:
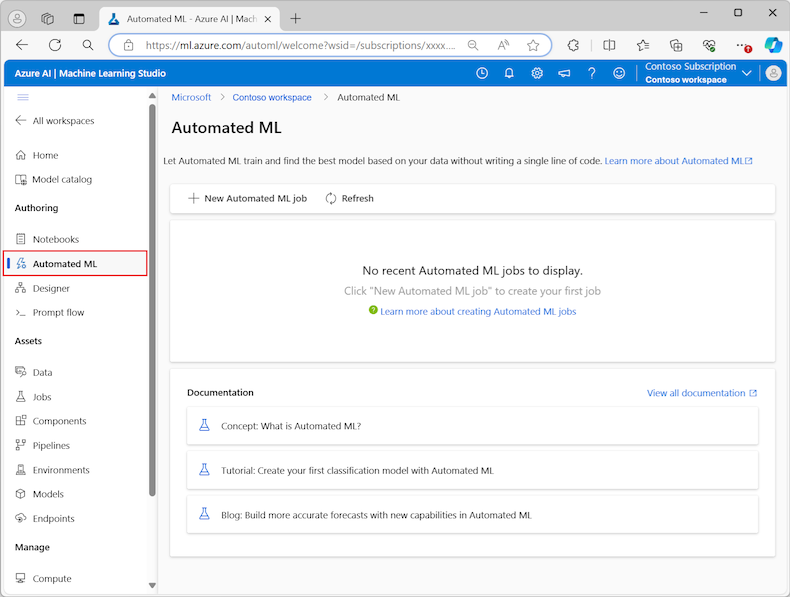
Při první práci s experimenty v sadě Studio se zobrazí prázdný seznam a odkazy na dokumentaci. V opačném případě se zobrazí seznam posledních experimentů automatizovaného strojového učení, včetně položek vytvořených pomocí sady Azure Machine Learning SDK.
Výběrem možnosti Nová automatizovaná úloha ML spustíte proces odeslání automatizovaného strojového učení.
Ve výchozím nastavení proces vybere možnost Trénovat automaticky na kartě Metoda trénování a pokračuje v nastavení konfigurace.
Na kartě Základní nastavení zadejte hodnoty požadovaných nastavení, včetně názvu úlohy a názvu experimentu. Podle potřeby můžete také zadat hodnoty pro volitelná nastavení.
Pokračujte výběrem tlačítka Další.

Identifikace datového assetu
Na kartě Typ úkolu a data zadáte datový asset pro experiment a model strojového učení, který se má použít k trénování dat.
V tomto kurzu můžete použít existující datový asset nebo vytvořit nový datový asset ze souboru na místním počítači. Stránky uživatelského rozhraní studia se mění na základě vašeho výběru pro zdroj dat a typ trénovacího modelu.
Pokud se rozhodnete použít existující datový asset, můžete pokračovat v části Konfigurace trénovacího modelu .
Pokud chcete vytvořit nový datový asset, postupujte takto:
Pokud chcete vytvořit nový datový asset ze souboru v místním počítači, vyberte Vytvořit.
Na stránce Datový typ:
- Zadejte název datového prostředku .
- Jako typ vyberte v rozevíracím seznamu tabulkové pole.
- Vyberte Další.
Na stránce Zdroj dat vyberte Z místních souborů.
Machine Learning Studio přidá do levé nabídky další možnosti pro konfiguraci zdroje dat.
Výběrem možnosti Další přejdete na stránku Typ cílového úložiště, kde zadáte umístění služby Azure Storage pro nahrání datového prostředku.
Můžete zadat výchozí kontejner úložiště, který se automaticky vytvoří s vaším pracovním prostorem, nebo zvolit kontejner úložiště, který se má použít pro experiment.
- Jako typ Úložiště dat vyberte Azure Blob Storage.
- V seznamu úložišť dat vyberte workspaceblobstore.
- Vyberte Další.
Na stránce Pro výběr souborů a složek použijte rozevírací nabídku Nahrát soubory nebo složku a vyberte možnost Nahrát soubory nebo Nahrát složku.
- Přejděte do umístění dat, která chcete nahrát, a vyberte Otevřít.
- Po nahrání souborů vyberte Další.
Machine Learning Studio ověří a nahraje data.
Poznámka:
Pokud jsou vaše data za virtuální sítí, musíte povolit funkci Přeskočit ověření , abyste měli jistotu, že pracovní prostor bude mít přístup k vašim datům. Další informace najdete v tématu Použití studio Azure Machine Learning ve virtuální síti Azure.
Zkontrolujte přesnost nahraných dat na stránce Nastavení . Pole na stránce jsou předem vyplněná na základě typu souboru vašich dat:
Pole Popis Formát souboru Definuje rozložení a typ dat uložených v souboru. Oddělovač Identifikuje jeden nebo více znaků pro určení hranice mezi samostatnými nezávislými oblastmi ve formátu prostého textu nebo jinými datovými proudy. Kódování Určuje, jaký bit tabulky schématu znaků se má použít ke čtení datové sady. Záhlaví sloupců Určuje, jak se zachází s hlavičkami datové sady( pokud existuje). Přeskočit řádky Určuje, kolik řádků se v datové sadě přeskočí( pokud existuje). Chcete-li pokračovat na stránku Schéma, vyberte Další. Tato stránka je také předem vyplněná na základě vašich výběrů nastavení . Pro každý sloupec můžete nakonfigurovat datový typ, zkontrolovat názvy sloupců a spravovat sloupce:
- Pokud chcete změnit datový typ sloupce, vyberte požadovanou možnost pomocí rozevírací nabídky Typ .
- Chcete-li vyloučit sloupec z datového prostředku, přepněte možnost Zahrnout pro sloupec.
Chcete-li pokračovat na stránku Revize, vyberte Další. Zkontrolujte souhrn nastavení konfigurace pro úlohu a pak vyberte Vytvořit.
Konfigurace trénovacího modelu
Jakmile je datový prostředek připravený, machine Learning Studio se vrátí na kartu Typ úlohy a data pro proces odeslání automatizovaného strojového učení. Nový datový asset je uvedený na stránce.
Provedením těchto kroků dokončete konfiguraci úlohy:
Rozbalte rozevírací nabídku Vybrat typ úkolu a zvolte trénovací model, který se má použít pro experiment. Mezi možnosti patří klasifikace, regrese, prognózování časových řad, zpracování přirozeného jazyka (NLP) nebo počítačové zpracování obrazu. Další informace o těchto možnostech najdete v popisu podporovaných typů úloh.
Po zadání trénovacího modelu vyberte datovou sadu v seznamu.
Chcete-li pokračovat na kartě Nastavení úlohy, vyberte Další.
V rozevíracím seznamu Cílový sloupec vyberte sloupec, který se má použít pro předpovědi modelu.
V závislosti na vašem trénovacím modelu nakonfigurujte následující požadovaná nastavení:
Klasifikace: Zvolte, jestli chcete povolit hluboké učení.
Prognózování časových řad: Zvolte, jestli chcete povolit hluboké učení, a potvrďte předvolby požadovaných nastavení:
Pomocí sloupce Čas zadejte časová data, která se mají v modelu použít.
Zvolte, jestli chcete povolit jednu nebo více možností automatického rozpoznávání . Když zrušíte výběr možnosti Automatické rozpoznávání, například horizont prognózy automatického rozpoznávání, můžete zadat konkrétní hodnotu. Hodnota horizontu prognózy určuje, kolik časových jednotek (minuty, hodiny, dny/ týdny/roky) může model předpovědět pro budoucnost. Čím dál do budoucna je model nutný k predikci, tím méně přesný model se stane.
Další informace o tom, jak tato nastavení nakonfigurovat, najdete v tématu Použití automatizovaného strojového učení k trénování modelu prognózování časových řad.
Zpracování přirozeného jazyka: Potvrďte předvolby požadovaných nastavení:
Pomocí možnosti Vybrat podtyp nakonfigurujte typ podtřídy pro model NLP. Můžete si vybrat z klasifikace více tříd, klasifikace více popisků a rozpoznávání pojmenovaných entit (NER).
V části Nastavení úklidu zadejte hodnoty pro algoritmus Slacku a vzorkování.
V části Prohledat prostor nakonfigurujte sadu možností algoritmu modelu.
Další informace o tom, jak tato nastavení nakonfigurovat, najdete v tématu Nastavení automatizovaného strojového učení pro trénování modelu NLP (Azure CLI nebo Python SDK).
Počítačové zpracování obrazu: Zvolte, jestli chcete povolit ruční úklid, a potvrďte předvolby požadovaných nastavení:
- Pomocí možnosti Vybrat podtyp nakonfigurujte typ podtřídy pro model počítačového zpracování obrazu. Můžete si vybrat z klasifikace obrázků (více tříd) nebo (multi-label), rozpoznávání objektů a mnohoúhelníku (segmentace instancí).
Další informace o tom, jak tato nastavení nakonfigurovat, najdete v tématu Nastavení AutoML pro trénování modelů počítačového zpracování obrazu (Azure CLI nebo Python SDK).
Zadání volitelných nastavení
Machine Learning Studio poskytuje volitelná nastavení, která můžete nakonfigurovat na základě výběru modelu strojového učení. Následující části popisují další nastavení.
Konfigurace dalších nastavení
Výběrem možnosti Zobrazit další nastavení konfigurace můžete zobrazit akce, které se mají s daty provádět při přípravě na trénování.
Na stránce Další konfigurace se zobrazují výchozí hodnoty založené na výběru experimentu a datech. Můžete použít výchozí hodnoty nebo nakonfigurovat následující nastavení:
| Nastavení | Popis |
|---|---|
| Primární metrika | Identifikujte hlavní metriku pro bodování modelu. Další informace najdete v tématu metriky modelu. |
| Povolení stackingu souborů | Povolte souborové učení a vylepšete výsledky strojového učení a prediktivní výkon kombinováním více modelů na rozdíl od použití jednotlivých modelů. Další informace naleznete v souboru modely. |
| Použití všech podporovaných modelů | Pomocí této možnosti můžete dát automatizovanému strojovému učení pokyn, jestli se mají v experimentu používat všechny podporované modely. Další informace najdete v podporovaných algoritmech pro každý typ úlohy. – Tuto možnost vyberte, pokud chcete nakonfigurovat nastavení Blokované modely . – Zrušte výběr této možnosti a nakonfigurujte nastavení Povolené modely . |
| Blokované modely | (K dispozici, když Vyberte všechny podporované modely ) Použijte rozevírací seznam a vyberte modely, které chcete z trénovací úlohy vyloučit. |
| Povolené modely | (K dispozici, když Možnost Použít všechny podporované modely není vybraná) Použijte rozevírací seznam a vyberte modely, které chcete použít pro trénovací úlohu. Důležité: K dispozici pouze pro experimenty sady SDK. |
| Vysvětlit nejlepší model | Tuto možnost vyberte, pokud chcete automaticky zobrazit vysvětlitelnost nejlepšího modelu vytvořeného automatizovaným strojovém učení. |
| Popisek kladné třídy | Zadejte popisek automatizovaného strojového učení, který se má použít pro výpočet binárních metrik. |
Konfigurace nastavení featurizace
Výběrem možnosti Zobrazit nastavení featurizace můžete zobrazit akce, které se mají s daty provádět při přípravě na trénování.
Na stránce Featurizace se zobrazují výchozí techniky featurizace pro datové sloupce. Můžete povolit nebo zakázat automatickou featurizaci a přizpůsobit nastavení automatického featurizace pro experiment.

Vyberte možnost Povolit featurizaci a povolte konfiguraci.
Důležité
Pokud data obsahují nečíselné sloupce, je featurizace vždy povolená.
Podle potřeby nakonfigurujte každý dostupný sloupec. Následující tabulka shrnuje vlastní nastavení, která jsou aktuálně dostupná prostřednictvím studia.
Column Vlastní nastavení Typ funkce Umožňuje změnit typ hodnoty pro vybraný sloupec. Imputovat pomocí Vyberte, jakou hodnotu mají být v datech imputované chybějící hodnoty. 

Nastavení featurizace nemá vliv na vstupní data potřebná k odvozování. Pokud z trénování vyloučíte sloupce, budou vyloučené sloupce nadále vyžadovány jako vstup pro odvozování modelu.
Konfigurace omezení pro úlohu
Oddíl Limity poskytuje možnosti konfigurace pro následující nastavení:
| Nastavení | Popis | Hodnota |
|---|---|---|
| Maximální počet zkušebních verzí | Zadejte maximální počet pokusů, které se mají vyzkoušet během úlohy automatizovaného strojového učení, kde má každá zkušební verze jinou kombinaci algoritmů a hyperparametrů. | Celé číslo mezi 1 a 1 000 |
| Maximální počet souběžných zkušebních verzí | Zadejte maximální počet zkušebních úloh, které lze spustit paralelně. | Celé číslo mezi 1 a 1 000 |
| Maximální počet uzlů | Zadejte maximální počet uzlů, které může tato úloha použít z vybraného cílového výpočetního objektu. | 1 nebo více v závislosti na konfiguraci výpočetních prostředků |
| Prahová hodnota skóre metriky | Zadejte prahovou hodnotu metriky iterace. Když iterace dosáhne prahové hodnoty, úloha trénování se ukončí. Mějte na paměti, že smysluplné modely mají korelaci větší než nula. V opačném případě je výsledek stejný jako uhodnutí. | Průměrná prahová hodnota metriky mezi hranicemi [0, 10] |
| Časový limit experimentu (minuty) | Zadejte maximální dobu, po které může celý experiment běžet. Jakmile experiment dosáhne limitu, zruší systém úlohu automatizovaného strojového učení včetně všech zkušebních verzí (podřízených úloh). | Počet minut |
| Časový limit iterace (minuty) | Zadejte maximální dobu, po kterou může každá zkušební úloha běžet. Jakmile úloha zkušební verze dosáhne tohoto limitu, systém zkušební verzi zruší. | Počet minut |
| Povolení předčasného ukončení | Tuto možnost použijte k ukončení úlohy, pokud se skóre v krátkodobém horizontu nezlepšuje. | Vyberte možnost povolení předčasného ukončení úlohy. |
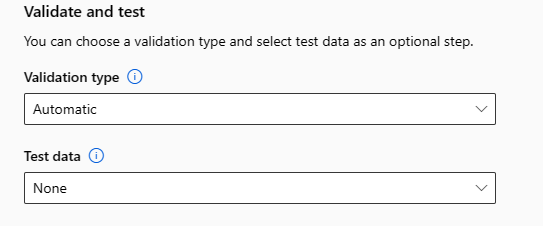
Ověření a test
Část Ověření a testování poskytuje následující možnosti konfigurace:
Zadejte typ ověření, který se má použít pro trénovací úlohu. Pokud explicitně nezadáte ani
validation_datan_cross_validationsparametr, automatizované strojové učení použije výchozí techniky v závislosti na počtu řádků zadaných v jedné datové sadětraining_data.Velikost trénovacích dat Technika ověřování Větší než 20 000 řádků Použije se rozdělení dat trénování/ověření. Výchozí hodnota je 10 % počáteční trénovací sady dat jako ověřovací sady. Tato ověřovací sada se pak používá pro výpočet metrik. Menší než 20 000& řádků Použije se přístup křížového ověřování. Výchozí počet záhybů závisí na počtu řádků.
- Datová sada s méně než 1 000 řádky: Použije se 10 složených záhybů.
- Datová sada s 1 000 až 20 000 řádky: Používají se tři záhybyZadejte testovací data (Preview) k vyhodnocení doporučeného modelu, který automatizované strojové učení vygeneruje na konci experimentu. Když zadáte testovací datovou sadu, na konci experimentu se automaticky aktivuje testovací úloha. Tato testovací úloha je jedinou úlohou na nejlepším modelu doporučeném automatizovaným strojovém učení. Další informace najdete v tématu Zobrazení výsledků úlohy vzdáleného testu (Preview).<
/a0> Důležité
Poskytnutí testovací datové sady pro vyhodnocení vygenerovaných modelů je funkce Preview. Tato funkce je experimentální funkce ve verzi Preview a může se kdykoli změnit.
Testovací data se považují za samostatná od trénování a ověřování a neměly by předcházet výsledkům testovací úlohy doporučeného modelu. Další informace najdete v tématu trénování, ověřování a testování dat.
Můžete buď zadat vlastní testovací datovou sadu, nebo se rozhodnout použít procento trénovací datové sady. Testovací data musí být ve formě datové sady tabulky Azure Machine Learning.
Schéma testovací datové sady by se mělo shodovat s trénovací datovou sadou. Cílový sloupec je nepovinný, ale pokud není uveden žádný cílový sloupec, nevypočítá se žádné testovací metriky.
Testovací datová sada by neměla být stejná jako trénovací datová sada nebo ověřovací datová sada.
Úlohy prognózování nepodporují rozdělení trénování a testování.
Konfigurace výpočetních prostředků
Postupujte podle těchto kroků a nakonfigurujte výpočetní prostředky:
Výběrem možnosti Další pokračujte na kartu Výpočty .
Pomocí rozevíracího seznamu Vybrat typ výpočetních prostředků zvolte možnost pro profilaci dat a trénovací úlohu. Mezi možnosti patří výpočetní cluster, výpočetní instance nebo bezserverová instance.
Po výběru typu výpočetních prostředků se druhé uživatelské rozhraní na stránce změní na základě vašeho výběru:
Bez serveru: Nastavení konfigurace se zobrazí na aktuální stránce. Pokračujte k dalšímu kroku, kde najdete popis nastavení, které chcete nakonfigurovat.
Výpočetní cluster nebo výpočetní instance: Vyberte si z následujících možností:
Pomocí rozevíracího seznamu Výběr automatizovaného výpočetního prostředí ML vyberte existující výpočetní prostředky pro váš pracovní prostor a pak vyberte Další. Pokračujte v části Spustit experiment a zobrazte výsledky .
Výběrem možnosti Nový vytvořte novou výpočetní instanci nebo cluster. Tato možnost otevře stránku Vytvořit výpočetní prostředky . Pokračujte k dalšímu kroku, kde najdete popis nastavení, které chcete nakonfigurovat.
U bezserverového výpočetního prostředí nebo nového výpočetního prostředí nakonfigurujte všechna požadovaná (*) nastavení:
Nastavení konfigurace se liší v závislosti na typu výpočetních prostředků. Následující tabulka shrnuje různá nastavení, která možná budete muset nakonfigurovat:
Pole Popis Název výpočetních prostředků Zadejte jedinečný název, který identifikuje váš výpočetní kontext. Místo Zadejte oblast počítače. Priorita virtuálního počítače Virtuální počítače s nízkou prioritou jsou levnější, ale nezaručují výpočetní uzly. Typ virtuálního počítače Jako typ virtuálního počítače vyberte procesor nebo GPU. Úroveň virtuálního počítače Vyberte prioritu experimentu. Velikost virtuálního počítače Vyberte velikost virtuálního počítače pro výpočetní prostředky. Minimální a maximální počet uzlů Pokud chcete profilovat data, musíte zadat jeden nebo více uzlů. Zadejte maximální počet uzlů výpočetních prostředků. Výchozí hodnota je šest uzlů pro výpočetní prostředí Azure Machine Learning. Nečinné sekundy před vertikálním snížením kapacity Zadejte dobu nečinnosti, než se cluster automaticky škáluje na minimální počet uzlů. Rozšířené nastavení Tato nastavení umožňují nakonfigurovat uživatelský účet a existující virtuální síť pro experiment. Po nakonfigurování požadovaných nastavení podle potřeby vyberte Další nebo Vytvořit.
Vytvoření nového výpočetního objektu může trvat několik minut. Po dokončení vytváření vyberte Další.
Spuštění experimentu a zobrazení výsledků
Vyberte Dokončit a spusťte experiment. Proces přípravy experimentu může trvat až 10 minut. U každého kanálu může další 2 až 3 minuty trvat, než se dokončí úlohy trénování. Pokud jste pro nejlepší doporučený model zadali generování řídicího panelu RAI, může to trvat až 40 minut.
Poznámka:
Algoritmy automatizovaného strojového učení mají vlastní náhodnost, která může způsobit mírné variace konečného skóre metrik doporučeného modelu, jako je přesnost. Automatizované strojové učení také provádí operace s daty, jako jsou rozdělení trénovacích testů, rozdělení ověření trénování nebo křížové ověření, podle potřeby. Pokud spustíte experiment se stejným nastavením konfigurace a primární metrikou vícekrát, pravděpodobně se v důsledku těchto faktorů zobrazí variace konečného skóre metrik každého experimentu.
Zobrazení podrobností o experimentu
Otevře se obrazovka Podrobnosti úlohy na kartě Podrobnosti . Tato obrazovka zobrazuje souhrn úlohy experimentu včetně stavového řádku v horní části vedle čísla úlohy.
Na kartě Modely je seznam vytvořených modelů seřazený podle skóre metriky. Ve výchozím nastavení se na prvním místě seznamu zobrazí model, který na základě zvolené metriky získá nejvyšší skóre. Při pokusu o více modelů se cvičené modely přidají do seznamu. Pomocí tohoto přístupu získáte rychlé porovnání metrik pro modely vytvořené doposud.
Zobrazení podrobností o trénovací úloze
Procházení podrobností o všech dokončených modelech pro podrobnosti úlohy trénování Grafy metrik výkonu pro konkrétní modely můžete zobrazit na kartě Metriky . Další informace najdete v tématu Vyhodnocení výsledků experimentu automatizovaného strojového učení. Na této stránce najdete také podrobnosti o všech vlastnostech modelu spolu s přidruženým kódem, podřízenými úlohami a obrázky.
Zobrazení výsledků vzdálené úlohy testu (Preview)
Pokud jste zadali testovací datovou sadu nebo jste se rozhodli pro rozdělení trénování a testování během nastavení experimentu ve formuláři Ověření a testování , automatizované strojové učení ve výchozím nastavení automaticky testuje doporučený model. Automatizované strojové učení proto vypočítá testovací metriky a určí kvalitu doporučeného modelu a jeho predikce.
Důležité
Testování modelů pomocí testovací datové sady pro vyhodnocení vygenerovaných modelů je funkce preview. Tato funkce je experimentální funkce ve verzi Preview a může se kdykoli změnit.
Tato funkce není dostupná pro následující scénáře automatizovaného strojového učení:
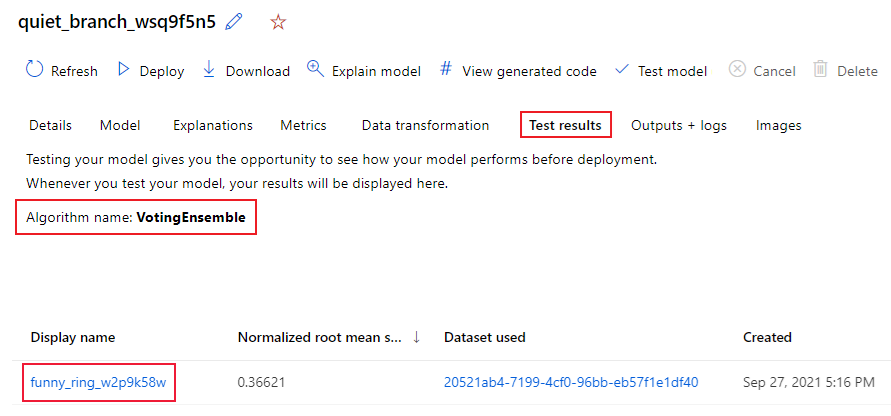
Pokud chcete zobrazit metriky testovací úlohy doporučeného modelu, postupujte takto:
V studiu přejděte na stránku Modely a vyberte nejlepší model.
Vyberte kartu Výsledky testu (Preview).
Vyberte požadovanou úlohu a zobrazte kartu Metriky :
Pomocí následujících kroků zobrazte predikce testů použité k výpočtu metrik testu:
V dolní části stránky vyberte odkaz v části Výstupní datová sada a otevřete datovou sadu.
Na stránce Datové sady vyberte kartu Prozkoumat a zobrazte předpovědi z testovací úlohy.
Soubor predikce lze také zobrazit a stáhnout z karty Výstupy a protokoly . Rozbalte složku Predikce a vyhledejte soubor prediction.csv .
Úloha testování modelu vygeneruje soubor predictions.csv uložený ve výchozím úložišti dat vytvořeném s pracovním prostorem. Toto úložiště dat je viditelné všem uživatelům se stejným předplatným. Testovací úlohy se nedoporučují pro scénáře, pokud některé z informací používaných pro testovací úlohu nebo vytvořené testovací úlohou musí zůstat soukromé.
Testování existujícího modelu automatizovaného strojového učení (Preview)
Po dokončení experimentu můžete modely automatizovaného strojového učení otestovat za vás.
Důležité
Testování modelů pomocí testovací datové sady pro vyhodnocení vygenerovaných modelů je funkce preview. Tato funkce je experimentální funkce ve verzi Preview a může se kdykoli změnit.
Tato funkce není dostupná pro následující scénáře automatizovaného strojového učení:
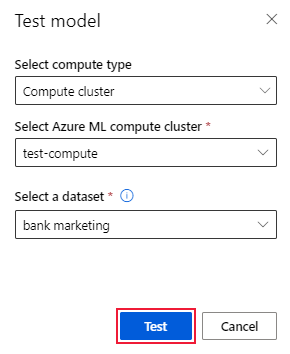
Pokud chcete otestovat jiný model vygenerovaný automatizovaným strojovém učení, a ne doporučený model, postupujte takto:
Vyberte existující úlohu experimentu automatizovaného strojového učení.
Přejděte na kartu Modely úlohy a vyberte dokončený model, který chcete otestovat.
Na stránce Podrobnosti modelu vyberte možnost Testovací model (Preview) a otevřete podokno Testovací model.
V podokně Testovací model vyberte výpočetní cluster a testovací datovou sadu, kterou chcete použít pro testovací úlohu.
Vyberte možnost Test. Schéma testovací datové sady by se mělo shodovat s trénovací datovou sadou, ale sloupec Target (Cíl) je nepovinný.
Po úspěšném vytvoření testovací úlohy modelu se na stránce Podrobnosti zobrazí zpráva o úspěchu. Výběrem karty Výsledky testu zobrazíte průběh úlohy.
Pokud chcete zobrazit výsledky testovací úlohy, otevřete stránku Podrobnosti a postupujte podle kroků v části Zobrazit výsledky vzdálené úlohy testu (Preview).
Řídicí panel zodpovědné umělé inteligence (Preview)
Pokud chcete lépe porozumět modelu, můžete zobrazit různé přehledy o modelu pomocí řídicího panelu Zodpovědné AI. Toto uživatelské rozhraní umožňuje vyhodnotit a ladit nejlepší model automatizovaného strojového učení. Řídicí panel zodpovědné umělé inteligence vyhodnocuje chyby modelu a problémy s nestranností, diagnostikuje, proč k chybám dochází vyhodnocením trénování nebo testovacích dat a pozorováním vysvětlení modelu. Tyto přehledy vám společně můžou pomoct vytvořit důvěru s vaším modelem a předat procesy auditu. Zodpovědné řídicí panely AI nejde vygenerovat pro existující model automatizovaného strojového učení. Řídicí panel se vytvoří pouze pro nejlepší doporučený model při vytvoření nové úlohy automatizovaného strojového učení. Uživatelé by měli dál používat vysvětlení modelů (Preview), dokud nebude podpora k dispozici pro stávající modely.
Pomocí následujících kroků vygenerujte řídicí panel zodpovědné umělé inteligence pro konkrétní model:
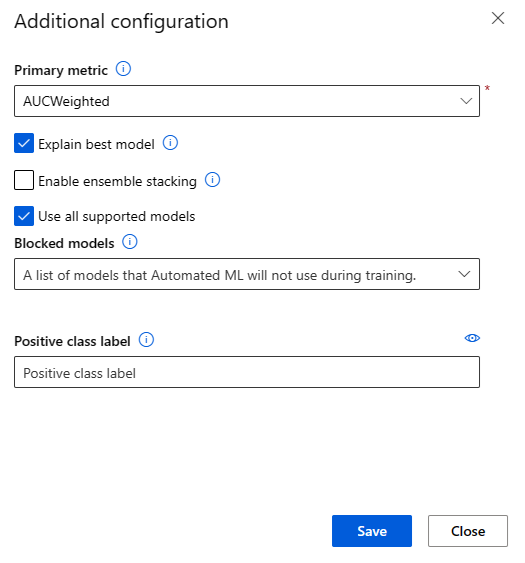
Při odesílání úlohy automatizovaného strojového učení přejděte do části Nastavení úlohy v nabídce vlevo a vyberte možnost Zobrazit další nastavení konfigurace.
Na stránce Další konfigurace vyberte možnost Vysvětlit nejlepší model:
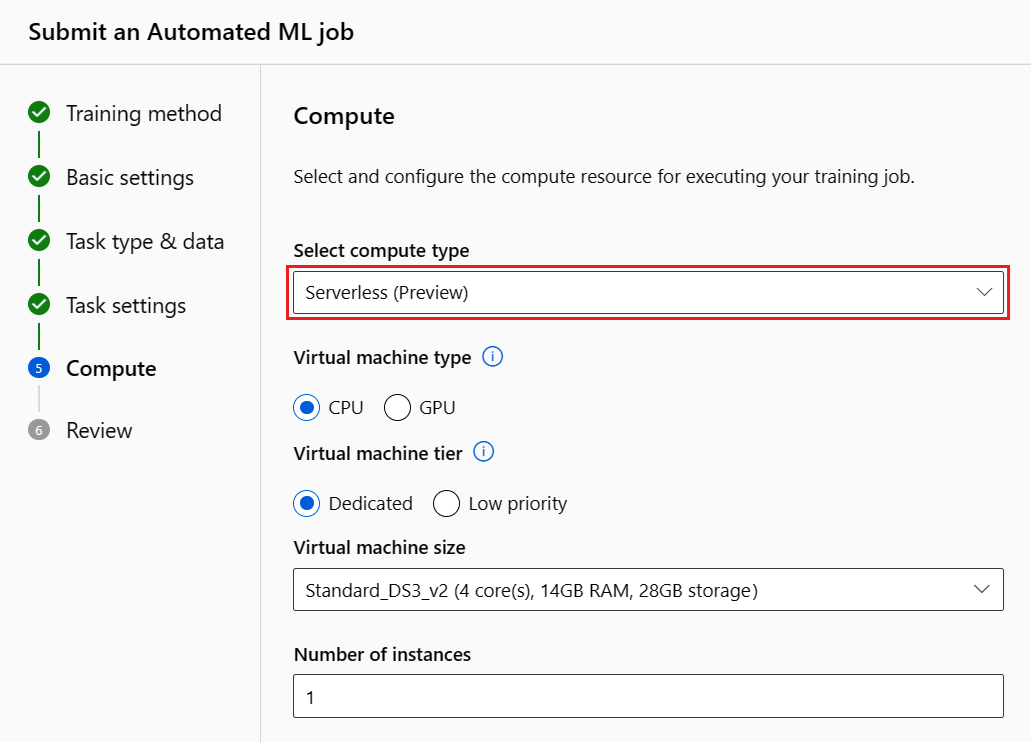
Přepněte na kartu Compute a vyberte možnost Bezserverová výpočetní funkce:
Po dokončení operace přejděte na stránku Modely vaší úlohy automatizovaného strojového učení, která obsahuje seznam trénovaných modelů. Vyberte odkaz Zobrazit zodpovědný řídicí panel AI:

Pro vybraný model se zobrazí řídicí panel Zodpovědné AI:

Na řídicím panelu se zobrazí čtyři komponenty aktivované pro nejlepší model automatizovaného strojového učení:
Komponenta Co komponenta zobrazuje? Jak si přečíst graf? Analýza chyb Analýzu chyb použijte v případě, že potřebujete:
– Získejte hluboké znalosti o tom, jak se selhání modelu distribuují napříč datovou sadou a napříč několika dimenzemi vstupu a funkcí.
– Rozdělte agregované metriky výkonu tak, aby automaticky zjistily chybné kohorty, abyste mohli informovat cílené kroky pro zmírnění rizik.Grafy analýzy chyb Přehled modelů a nestrannost Tato komponenta slouží k:
– Získejte hluboké znalosti o výkonu modelu v různých kohortách dat.
– Seznamte se s problémy s nestranností modelu tím, že se podíváte na metriky nestrannosti. Tyto metriky můžou vyhodnotit a porovnat chování modelu napříč podskupinami identifikovanými z hlediska citlivých (nebo nesmyslných) funkcí.Přehled modelů a grafy nestrannosti Vysvětlení modelů Pomocí komponenty vysvětlení modelu můžete vygenerovat popisy předpovědí modelu strojového učení, které jsou srozumitelné pro člověka:
- Globální vysvětlení: Jaké funkce mají vliv například na celkové chování modelu přidělování úvěrů?
- Místní vysvětlení: Proč byla například žádost o půjčku zákazníka schválena nebo odmítnuta?Model Explainability Charts Analýza dat Analýzu dat použijte v případě, že potřebujete:
– Prozkoumejte statistiku datové sady výběrem různých filtrů, abyste mohli data rozdělit do různých dimenzí (označovaných také jako kohorty).
– Porozumíte distribuci datové sady mezi různé kohorty a skupiny funkcí.
– Určete, jestli vaše zjištění týkající se spravedlnosti, analýzy chyb a kauzality (odvozené z jiných komponent řídicího panelu) jsou výsledkem distribuce datové sady.
– Rozhodněte se, ve kterých oblastech se mají shromažďovat další data pro zmírnění chyb, které pocházejí z problémů s reprezentací, šumu popisků, šumu v funkcích, předsudků popisků a podobných faktorů.Grafy Data Exploreru Můžete dále vytvářet kohorty (podskupiny datových bodů, které sdílejí zadané charakteristiky), abyste se zaměřili na analýzu jednotlivých komponent na různé kohorty. V levém horním rohu řídicího panelu se vždy zobrazí název kohorty použité na řídicím panelu. Výchozí zobrazení na řídicím panelu je celá datová sada s názvem Všechna data ve výchozím nastavení. Další informace najdete v tématu Globální ovládací prvky pro řídicí panel.


Úpravy a odesílání úloh (Preview)
Ve scénářích, ve kterých chcete vytvořit nový experiment na základě nastavení existujícího experimentu, poskytuje automatizované strojové učení možnost Upravit a odeslat v uživatelském rozhraní studia. Tato funkce je omezená na experimenty zahájené z uživatelského rozhraní studia a vyžaduje, aby schéma dat nového experimentu odpovídalo schématu původního experimentu.
Důležité
Možnost kopírovat, upravovat a odesílat nový experiment na základě existujícího experimentu je funkce preview. Tato funkce je experimentální funkce ve verzi Preview a může se kdykoli změnit.
Možnost Upravit a odeslat otevře průvodce vytvořením nové úlohy automatizovaného strojového učení s předem vyplněnými nastaveními dat, výpočtů a experimentů. Možnosti na jednotlivých kartách v průvodci můžete nakonfigurovat a podle potřeby upravit výběry pro nový experiment.
Nasazení modelu
Jakmile budete mít nejlepší model, můžete model nasadit jako webovou službu, abyste mohli předpovědět nová data.
Poznámka:
Pokud chcete nasadit model vygenerovaný prostřednictvím automl balíčku pomocí sady Python SDK, musíte ho zaregistrovat do pracovního prostoru.
Jakmile model zaregistrujete, můžete model vyhledat v sadě Studio tak , že v nabídce vlevo vyberete Modely . Na stránce přehledu modelu můžete vybrat možnost Nasadit a pokračovat krokem 2 v této části.
Automatizované strojové učení vám pomůže nasadit model bez psaní kódu.
Spuštění nasazení pomocí jedné z následujících metod:
Nasaďte nejlepší model s definovanými kritérii metrik:
Po dokončení experimentu vyberte 1 . Úlohu a přejděte na stránku nadřazené úlohy.
Vyberte model uvedený v části Nejlepší souhrn modelu a pak vyberte Nasadit.
Nasazení konkrétní iterace modelu z tohoto experimentu:
- Na kartě Modely vyberte požadovaný model a pak vyberte Nasadit.
Vyplňte podokno Nasadit model:
Pole Hodnota Název Zadejte jedinečný název nasazení. Popis Zadejte popis, který vám umožní lépe identifikovat účel nasazení. Typ výpočetních prostředků Vyberte typ koncového bodu, který chcete nasadit: Azure Kubernetes Service (AKS) nebo Azure Container Instance (ACI). Název výpočetních prostředků (platí jenom pro AKS) Vyberte název clusteru AKS, do kterého chcete nasadit. Povolení ověřování Vyberte, pokud chcete povolit ověřování založené na tokenech nebo klíčích. Použití vlastních prostředků nasazení Pokud chcete nahrát vlastní hodnoticí skript a soubor prostředí, povolte vlastní prostředky. V opačném případě automatizované strojové učení poskytuje tyto prostředky ve výchozím nastavení. Další informace najdete v tématu Nasazení a určení skóre modelu strojového učení pomocí online koncového bodu. Důležité
Názvy souborů musí mít délku 1 až 32 znaků. Název musí začínat a končit alfanumerickými znaky a může obsahovat pomlčky, podtržítka, tečky a alfanumerické znaky. Mezery nejsou povolené.
Nabídka Upřesnit nabízí výchozí funkce nasazení, jako je shromažďování dat a nastavení využití prostředků. Tyto výchozí hodnoty můžete přepsat pomocí možností v této nabídce. Další informace najdete v tématu Monitorování online koncových bodů.
Vyberte Nasadit. Dokončení nasazení může trvat přibližně 20 minut.
Po spuštění nasazení se otevře karta Souhrn modelu. Průběh nasazení můžete monitorovat v části Stav nasazení.
Teď máte funkční webovou službu pro generování předpovědí. Predikce můžete otestovat dotazováním služby z kompletních ukázek AI v Microsoft Fabric.