Přehled provozní kontinuity služby Azure Database for PostgreSQL – flexibilní server
PLATÍ PRO:  Flexibilní server Azure Database for PostgreSQL
Flexibilní server Azure Database for PostgreSQL
Kontinuita podnikových procesů na flexibilním serveru Azure Database for PostgreSQL odkazuje na mechanismy, zásady a postupy, které vaší firmě umožňují pokračovat v provozu v případě přerušení, zejména výpočetní infrastruktury. Ve většině případů flexibilní server Azure Database for PostgreSQL zpracovává rušivé události, ke kterým může dojít v cloudovém prostředí, a udržuje vaše aplikace a obchodní procesy spuštěné. Některé události se ale nedají zpracovat automaticky, například:
- Uživatel omylem odstraní nebo aktualizuje řádek v tabulce.
- Zemětřesení způsobí výpadek napájení a dočasně zakáže zónu dostupnosti nebo oblast.
- Oprava databáze potřebná k opravě chyby nebo problému se zabezpečením
Flexibilní server Azure Database for PostgreSQL poskytuje funkce, které chrání data a snižují výpadky pro důležité databáze během plánovaných a neplánovaných výpadků. Založený na infrastruktuře Azure, která nabízí robustní odolnost a dostupnost, má flexibilní server Azure Database for PostgreSQL funkce provozní kontinuity, které poskytují další ochranu proti chybám, řeší požadavky na dobu obnovení a snižují riziko ztráty dat. Při navrhování aplikací byste měli zvážit odolnost proti výpadkům – plánovanou dobu obnovení (RTO) a expozici ztráty dat – cíl bodu obnovení (RPO). Například vaše databáze pro důležité obchodní informace vyžaduje přísnější dobu provozu než testovací databáze.
Následující tabulka ukazuje funkce, které flexibilní server Azure Database for PostgreSQL nabízí.
| Funkce | Popis | Důležité informace |
|---|---|---|
| Automatické zálohování | Flexibilní server Azure Database for PostgreSQL automaticky provádí denní zálohy databázových souborů a průběžně zálohuje transakční protokoly. Zálohy je možné uchovávat po dobu 7 až 35 dnů. Databázový server můžete obnovit k libovolnému bodu v čase během doby uchovávání záloh. RtO závisí na velikosti dat, která se mají obnovit a čas provést obnovení protokolu. Může to být několik minut až 12 hodin. Další podrobnosti najdete v tématu Koncepty – zálohování a obnovení. | Zálohovaná data zůstávají v rámci oblasti. |
| Zónově redundantní vysoká dostupnost | Flexibilní server Azure Database for PostgreSQL je možné nasadit s konfigurací zónově redundantní vysoké dostupnosti (HA), kde jsou primární a pohotovostní servery nasazené ve dvou různých zónách dostupnosti v rámci oblasti. Tato konfigurace vysoké dostupnosti chrání vaše databáze před selháními na úrovni zóny a také pomáhá snížit výpadky aplikace během plánovaných a neplánovaných výpadků. Data z primárního serveru se replikují do pohotovostní repliky v synchronním režimu. V případě jakéhokoli přerušení primárního serveru dojde k automatickému převzetí služeb při selhání na pohotovostní repliku. Ve většině případů se očekává, že rto bude menší než 120. Očekávaný cíl bodu obnovení (RPO) je nula (bez ztráty dat). Další informace najdete v tématu [Koncepty – Vysoká dostupnost]/azure/spolehlivost/reliability-postgresql-flexible-server. | Podporuje se v úrovních výpočetních prostředků optimalizovaných pro obecné účely a paměti. K dispozici pouze v oblastech, kde je k dispozici více zón. |
| Stejná vysoká dostupnost zóny | Flexibilní server Azure Database for PostgreSQL je možné nasadit se stejnou konfigurací vysoké dostupnosti (HA), kde jsou primární a pohotovostní servery nasazené ve stejné zóně dostupnosti v oblasti. Tato konfigurace vysoké dostupnosti chrání vaše databáze před selháními na úrovni uzlů a pomáhá také snížit výpadky aplikací během plánovaných a neplánovaných výpadků. Data z primárního serveru se replikují do pohotovostní repliky v synchronním režimu. V případě jakéhokoli přerušení primárního serveru dojde k automatickému převzetí služeb při selhání na pohotovostní repliku. Ve většině případů se očekává, že rto bude menší než 120. Očekávaný cíl bodu obnovení (RPO) je nula (bez ztráty dat). Další informace najdete v tématu [Koncepty – Vysoká dostupnost]/azure/spolehlivost/reliability-postgresql-flexible-server. | Podporuje se v úrovních výpočetních prostředků optimalizovaných pro obecné účely a paměti. |
| Spravované disky úrovně Premium | Soubory databáze se ukládají ve vysoce odolném a spolehlivém spravovaném úložišti Premium. Toto úložiště zajišťuje redundanci dat díky třem kopiím repliky uloženým v rámci zóny dostupnosti s možnostmi automatického obnovení dat. Další informace najdete v dokumentaci ke spravovaným diskům. | Data uložená v zóně dostupnosti |
| Zónově redundantní zálohování | Flexibilní zálohy serverů Azure Database for PostgreSQL se automaticky a bezpečně ukládají v zónově redundantním úložišti v rámci oblasti, pokud tato oblast podporuje zóny dostupnosti. Během selhání na úrovni zóny, kdy je váš server zřízený a pokud váš server není nakonfigurovaný s redundancí zón, můžete databázi obnovit pomocí nejnovějšího bodu obnovení v jiné zóně. Další informace najdete v tématu Koncepty – zálohování a obnovení. | Platí pouze v oblastech, kde je k dispozici více zón. |
| Geograficky redundantní zálohování | Zálohy flexibilního serveru Azure Database for PostgreSQL se zkopírují do vzdálené oblasti. pomáhá situaci zotavení po havárii v případě výpadku primární oblasti serveru. | Tato funkce je aktuálně povolená ve vybraných oblastech. V závislosti na velikosti dat trvá delší plánovanou dobu obnovení a vyšší cíl bodu obnovení. |
| Replika pro čtení | Repliky pro čtení mezi oblastmi je možné nasadit za účelem ochrany databází před selháními na úrovni oblasti. Repliky pro čtení se aktualizují asynchronně pomocí technologie fyzické replikace PostgreSQL a mohou zpožďovat primární replikaci. Další informace najdete v tématu Koncepty – repliky pro čtení. | Podporuje se v úrovních výpočetních prostředků optimalizovaných pro obecné účely a paměti. |
Následující tabulka porovnává plánovanou dobu obnovení a cíl bodu obnovení (RPO) v typickém scénáři úloh :
| Schopnost | Nárazové rozšíření | Obecné použití | Optimalizované pro paměť |
|---|---|---|---|
| Obnovení k určitému bodu v čase ze zálohy | Jakýkoli bod obnovení v rámci doby uchovávání RTO – liší se RPO < 5 min |
Jakýkoli bod obnovení v rámci doby uchovávání RTO – liší se RPO < 5 min |
Jakýkoli bod obnovení v rámci doby uchovávání RTO – liší se RPO < 5 min |
| Geografické obnovení z geograficky replikovaných záloh | RTO – liší se RPO < 1 h |
RTO – liší se RPO < 1 h |
RTO – liší se RPO < 1 h |
| Čtení replik | RTO – minuty* RPO < 5 min* |
RTO – minuty* RPO < 5 min* |
RTO – minuty* RPO < 5 min* |
* RtO a RPO mohou být v některých případech mnohem vyšší v závislosti na různých faktorech, mezi které patří latence mezi lokalitami, objem přenášených dat a důležité úlohy zápisu do primární databáze.
Události plánovaného výpadku
Níže jsou uvedené některé scénáře plánované údržby. K těmto událostem obvykle dochází až několik minut výpadku a bez ztráty dat.
| Scénář | Proces |
|---|---|
| Škálování výpočetních prostředků (iniciované uživatelem) | Během operace škálování výpočetních prostředků se aktivní kontrolní body můžou dokončit, vyprázdní se připojení klientů, zruší se všechny nepotvrzené transakce, úložiště se odpojí a vypne se. Nová instance flexibilního serveru Azure Database for PostgreSQL se stejným názvem databázového serveru se zřídí s konfigurací škálovaných výpočetních prostředků. Úložiště se pak připojí k novému serveru a databáze se spustí, což v případě potřeby provede obnovení před přijetím připojení klientů. |
| Vertikální navýšení kapacity úložiště (iniciované uživatelem) | Když se zahájí operace vertikálního navýšení kapacity úložiště, aktivní kontrolní body se můžou dokončit, klientská připojení se vyprázdní a všechny nepotvrzené transakce se zruší. Po vypnutí serveru. Úložiště se škáluje na požadovanou velikost a pak se připojí k novému serveru. Obnovení se provede v případě potřeby před přijetím připojení klientů. Mějte na paměti, že vertikální snížení kapacity velikosti úložiště se nepodporuje. |
| Nové nasazení softwaru (iniciované Azure) | Nové funkce zavedení nebo opravy chyb se automaticky stávají součástí plánované údržby služby a můžete naplánovat, kdy k těmto aktivitám dojde. Další informace najdete na portálu. |
| Upgrady podverze (iniciované Azure) | Azure Database for PostgreSQL automaticky opravuje databázové servery na podverzi určenou Azure. Stává se to jako součást plánované údržby služby. Databázový server se automaticky restartuje s novou podverzi. Další informace najdete v dokumentaci. Můžete také zkontrolovat svůj portál. |
Když je instance flexibilního serveru Azure Database for PostgreSQL nakonfigurovaná s vysokou dostupností, služba nejprve provádí operace škálování a údržby na pohotovostním serveru. Další informace najdete v tématu [Koncepty – Vysoká dostupnost]/azure/spolehlivost/reliability-postgresql-flexible-server.
Zmírnění dopadu neplánovaných výpadků
Neplánované výpadky můžou nastat v důsledku nepředvídatelných přerušení, jako jsou selhání hardwaru, problémy se sítí a chyby softwaru. Pokud databázový server nakonfigurovaný s vysokou dostupností neočekávaně klesne, aktivuje se pohotovostní replika a klienti můžou pokračovat v provozu. Pokud není nakonfigurovaná vysoká dostupnost(HA), pak pokud pokus o restartování selže, automaticky se zřídí nový databázový server. I když se neplánovaný výpadek nedá vyhnout, flexibilní server Azure Database for PostgreSQL pomáhá zmírnit výpadky tím, že automaticky provádí operace obnovení bez nutnosti zásahu člověka.
I když neustále usilujeme o zajištění vysoké dostupnosti, dochází k občasným výpadkům flexibilního serveru Azure Database for PostgreSQL, což způsobuje nedostupnost databází, což má vliv na vaši aplikaci. Když naše monitorování služeb zjistí problémy, které způsobují rozsáhlé chyby připojení, chyby nebo problémy s výkonem, služba automaticky deklaruje výpadek, který vás bude informovat.
Výpadek služby
V případě výpadku flexibilního serveru Azure Database for PostgreSQL najdete další podrobnosti týkající se výpadku na následujících místech:
- Banner webu Azure Portal: Pokud je vaše předplatné označeno jako ovlivněné, na webu Azure Portal se zobrazí upozornění na výpadek problému se službou.
- Nápověda + podpora nebo podpora + řešení potíží: Když vytvoříte lístek podpory z nápovědy a podpory nebo podpory a řešení potíží, zobrazí se informace o jakýchkoli problémech, které mají vliv na vaše prostředky. Pokud chcete zobrazit další informace a souhrn dopadu, vyberte Zobrazit podrobnosti o výpadku. Na stránce Nová žádost o podporu bude také upozornění.
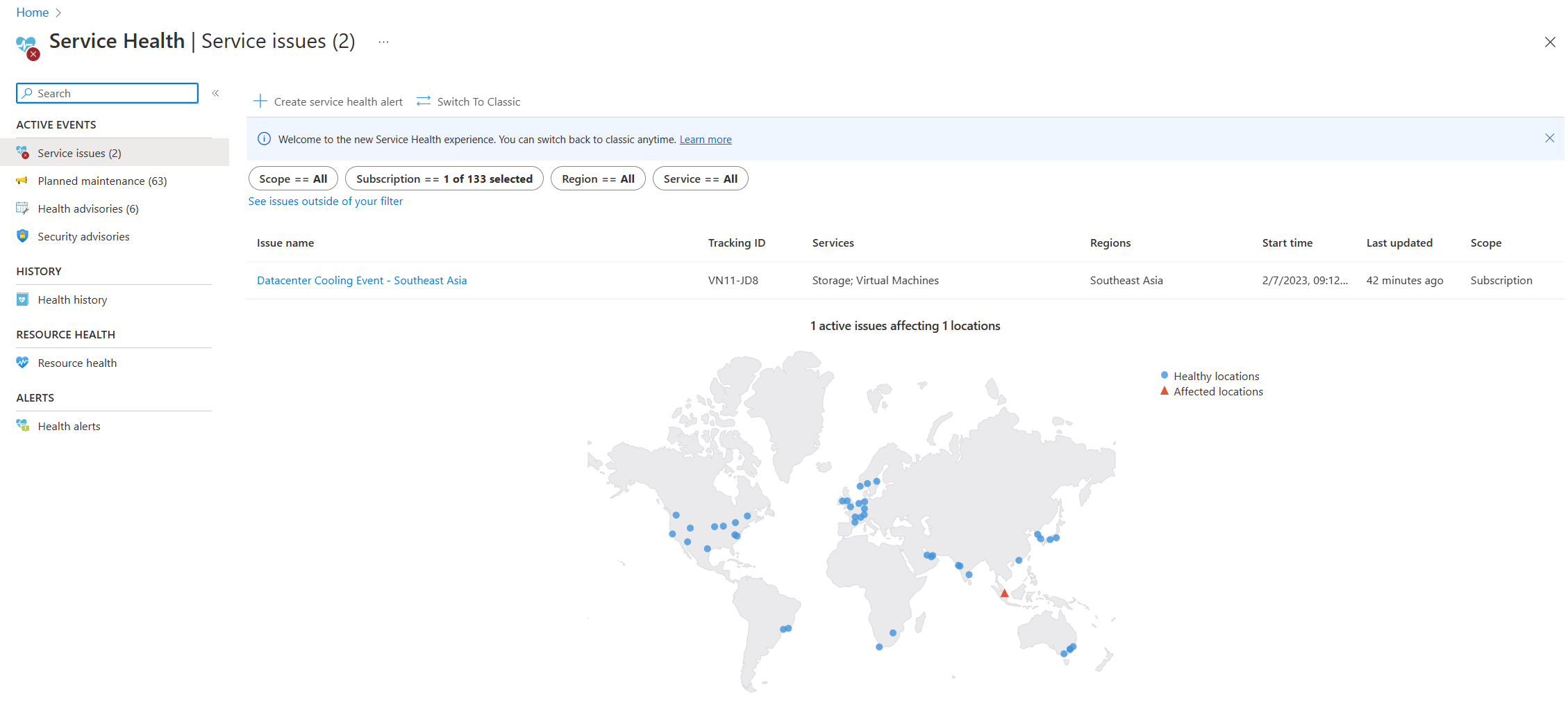
- Nápověda ke službě: Stránka Service Health na webu Azure Portal obsahuje informace o stavu datového centra Azure globálně. Na panelu hledání na webu Azure Portal vyhledejte "stav služby" a pak zobrazte problémy se službou v kategorii Aktivní události. Stav jednotlivých prostředků můžete zobrazit také na stránce Stav prostředku libovolného prostředku v nabídce Nápověda. Následuje ukázkový snímek obrazovky se stránkou Service Health s informacemi o aktivním problému se službou v jihovýchodní Asii.
- E-mailové oznámení: Pokud jste nastavili upozornění, přijde e-mailové oznámení, když výpadek služby ovlivní vaše předplatné a prostředek. E-maily přicházejí z "azure-noreply@microsoft.com". Text e-mailu začíná upozorněním protokolu aktivit ... aktivoval problém se službou pro předplatné Azure.... Další informace o upozorněních na stav služby najdete v tématu Příjem upozornění protokolu aktivit na oznámeních služby Azure pomocí webu Azure Portal.
Důležité
Jak název napovídá, dočasné tabulkové prostory v PostgreSQL se používají pro dočasné objekty a také pro další interní databázové operace, jako je řazení. Proto nedoporučujeme vytvářet objekty schématu uživatele v dočasném tabulkovém prostoru, protože nezaručujeme stálost takových objektů po restartování serveru, převzetí služeb při selhání vysoké dostupnosti atd.
Neplánovaný výpadek: scénáře selhání a obnovení služby
Níže jsou uvedeny některé neplánované scénáře selhání a proces obnovení.
| Scénář | Proces obnovení [Servery nakonfigurované bez zónově redundantní vysoké dostupnosti] |
Proces obnovení [Servery nakonfigurované se zónově redundantní vysokou dostupností] |
|---|---|---|
| Selhání databázového serveru | Pokud databázový server nefunguje, Azure se pokusí restartovat databázový server. Pokud to selže, databázový server se restartuje na jiném fyzickém uzlu. Doba obnovení (RTO) závisí na různých faktorech, včetně aktivity v době selhání, například velké transakce, a objemu obnovení, které se má provést během procesu spuštění databázového serveru. Aplikace využívající databáze PostgreSQL musí být sestaveny způsobem, který zjišťuje a opakuje ukončená připojení a neúspěšné transakce. |
Pokud se zjistí selhání databázového serveru, server převezme služby při selhání na pohotovostní server, čímž se sníží výpadek. Další informace najdete na [stránce konceptů vysoké dostupnosti]/azure/reliability/reliability-postgresql-flexible-server. Očekává se, že RTO bude 60–120 s nulovou ztrátou dat. |
| Selhání úložiště | Aplikace nevidí žádný dopad na problémy související s úložištěm, jako je selhání disku nebo poškození fyzického bloku. Vzhledem k tomu, že jsou data uložená ve třech kopiích, bude kopie dat obsluhována úložištěm pro přežití. Poškozený blok dat se automaticky opraví a automaticky se vytvoří nová kopie dat. | U jakýchkoli vzácných a neobnovitelných chyb, jako je například celé úložiště, je instance flexibilního serveru Azure Database for PostgreSQL předaná do pohotovostní repliky, aby se snížil výpadek. Další informace najdete na [stránce konceptů vysoké dostupnosti]/azure/reliability/reliability-postgresql-flexible-server. |
| Logické nebo uživatelské chyby | Pokud se chcete zotavit z chyb uživatelů, jako jsou omylem vynechané tabulky nebo nesprávně aktualizovaná data, musíte provést obnovení k určitému bodu v čase (PITR). Při provádění operace obnovení zadáte vlastní bod obnovení, což je čas těsně před chybou. Pokud chcete obnovit pouze podmnožinu databází nebo konkrétních tabulek místo všech databází na databázovém serveru, můžete obnovit databázový server v nové instanci, exportovat tabulky prostřednictvím pg_dump a pak tyto tabulky obnovit do databáze pomocí pg_restore . |
Tyto chyby uživatelů nejsou chráněny s vysokou dostupností, protože všechny změny se replikují do pohotovostní repliky synchronně. Abyste tyto chyby mohli obnovit, musíte provést obnovení k určitému bodu v čase. |
| Selhání zóny dostupnosti | Pokud se chcete zotavit z selhání na úrovni zóny, můžete provést obnovení k určitému bodu v čase pomocí zálohy a zvolit vlastní bod obnovení s nejnovějším časem k obnovení nejnovějších dat. Nová instance flexibilního serveru Azure Database for PostgreSQL se nasadí v jiné nepůsobené zóně. Doba potřebná k obnovení závisí na předchozím zálohování a objemu transakčních protokolů, které se mají obnovit. | Flexibilní server Azure Database for PostgreSQL se automaticky převezme při selhání pohotovostnímu serveru během 60 až 120 s nulovou ztrátou dat. Další informace najdete na [stránce konceptů vysoké dostupnosti]/azure/reliability/reliability-postgresql-flexible-server. |
| Selhání oblasti | Pokud je váš server nakonfigurovaný s geograficky redundantním zálohováním, můžete provést geografické obnovení ve spárované oblasti. Nový server se zřídí a obnoví na poslední dostupná data zkopírovaná do této oblasti. Můžete také použít repliky pro čtení mezi oblastmi. V případě selhání oblasti můžete provést operaci zotavení po havárii zvýšením úrovně repliky pro čtení na samostatný server pro čtení i zápis. Očekává se, že cíl bodu obnovení bude až 5 minut (ztráta dat možná), s výjimkou případu závažného regionálního selhání, kdy se cíl bodu obnovení může v době selhání blížit prodlevě replikace. |
Stejný proces. |
Konfigurace databáze po obnovení z regionálního selhání
- Pokud k zotavení z výpadku používáte geografické obnovení nebo geografickou repliku, musíte zajistit, aby bylo správně nakonfigurované připojení k novému serveru, aby bylo možné obnovit normální funkci aplikace. Můžete postupovat podle úkolů po obnovení.
- Pokud jste dříve nastavili nastavení diagnostiky na původním serveru, nezapomeňte na cílovém serveru provést totéž, jak je vysvětleno v tématu Konfigurace a přístupové protokoly na flexibilním serveru Azure Database for PostgreSQL.
- Nastavte upozornění telemetrie, musíte zajistit, aby se vaše stávající nastavení pravidla upozornění aktualizovalo tak, aby se mapuje na nový server. Další informace o pravidlech upozornění najdete v tématu Použití webu Azure Portal k nastavení upozornění na metriky pro flexibilní server Azure Database for PostgreSQL.
Důležité
Odstraněné servery je možné obnovit. Pokud server odstraníte, můžete postupovat podle našich pokynů k obnovení vyřazené databáze Azure – Azure Database for PostgreSQL – Flexibilního serveru . Pokud chcete zabránit náhodnému odstranění serveru, použijte zámek prostředků Azure.
Související obsah
- Vysoká dostupnost na flexibilním serveru Azure Database for PostgreSQL
- Obnovení instance flexibilního serveru Azure Database for PostgreSQL k určitému bodu v čase