Vytvoření vektorového dotazu ve službě Azure AI Search
Pokud máte ve službě Azure AI Search vektorový index, tento článek vysvětluje, jak:
Tento článek používá rest pro ilustraci. Ukázky kódu v jiných jazycích najdete v úložišti GitHubu azure-search-vector-samples pro ucelená řešení, která zahrnují vektorové dotazy.
Průzkumníka služby Search můžete také použít na webu Azure Portal.
Požadavky
Azure AI Search, v libovolné oblasti a na libovolné úrovni.
Vektorový index ve službě Azure AI Search
vectorSearchZkontrolujte oddíl v indexu a potvrďte vektorový index.Volitelně můžete do indexu přidat vektorizátor pro předdefinovaný převod textu na vektor nebo převod obrázků na vektor během dotazů.
Visual Studio Code s klientem REST a ukázkovými daty, pokud chcete tyto příklady spustit sami. Pokud chcete začít s klientem REST, přečtěte si rychlý start: Azure AI Search s využitím REST.
Převod vstupu řetězce dotazu na vektor
Pokud chcete dotazovat vektorové pole, musí být samotný dotaz vektorem.
Jedním z přístupů k převodu textového řetězce dotazu uživatele na jeho vektorové vyjádření je volání vložené knihovny nebo rozhraní API do kódu aplikace. Osvědčeným postupem je vždy použít stejné modely vkládání, které se používají k vygenerování vkládání ve zdrojových dokumentech. Ukázky kódu ukazující , jak vygenerovat vkládání v úložišti azure-search-vector-samples .
Druhým přístupem je použití integrované vektorizace, která je nyní obecně dostupná, aby služba Azure AI Search zpracovávala vstupy a výstupy vektorizace dotazů.
Tady je příklad rozhraní REST API řetězce dotazu odeslaného do nasazení modelu vkládání Azure OpenAI:
POST https://{{openai-service-name}}.openai.azure.com/openai/deployments/{{openai-deployment-name}}/embeddings?api-version={{openai-api-version}}
Content-Type: application/json
api-key: {{admin-api-key}}
{
"input": "what azure services support generative AI'"
}
Očekávaná odpověď je 202 pro úspěšné volání nasazeného modelu.
Pole "embedding" v těle odpovědi je vektorové znázornění řetězce dotazu "input". Pro účely testování byste v požadavku dotazu zkopírovali hodnotu pole embedding do vectorQueries.vector pomocí syntaxe uvedené v následujících několika částech.
Skutečná odpověď pro toto volání POST nasazeného modelu zahrnuje 1536 vkládání, oříznuto zde pouze na několik prvních vektorů pro čitelnost.
{
"object": "list",
"data": [
{
"object": "embedding",
"index": 0,
"embedding": [
-0.009171937,
0.018715322,
...
-0.0016804502
]
}
],
"model": "ada",
"usage": {
"prompt_tokens": 7,
"total_tokens": 7
}
}
V tomto přístupu zodpovídá kód aplikace za připojení k modelu, generování vložených objektů a zpracování odpovědi.
Žádost o vektorový dotaz
Tato část ukazuje základní strukturu vektorového dotazu. K formulování vektorového dotazu můžete použít Azure Portal, rozhraní REST API nebo sady Azure SDK. Pokud migrujete z verze 2023-07-01-Preview, dojde k zásadním změnám. Podrobnosti najdete v tématu Upgrade na nejnovější rozhraní REST API .
2024-07-01 je stabilní verze rozhraní REST API pro Search POST. Tato verze podporuje:
vectorQueriesje konstruktor pro vektorové vyhledávání.vectorQueries.kindnastavte provectorvektorovou matici nebo nastavtetext, zda je vstup řetězec a máte vektorizátor.vectorQueries.vectorje dotaz (vektorové znázornění textu nebo obrázku).vectorQueries.weight(volitelné) určuje relativní váhu každého vektorového dotazu zahrnutého do vyhledávacích operací (viz Váha vektoru).exhaustive(volitelné) vyvolá vyčerpávající síť KNN v době dotazu, i když je pole indexováno pro HNSW.
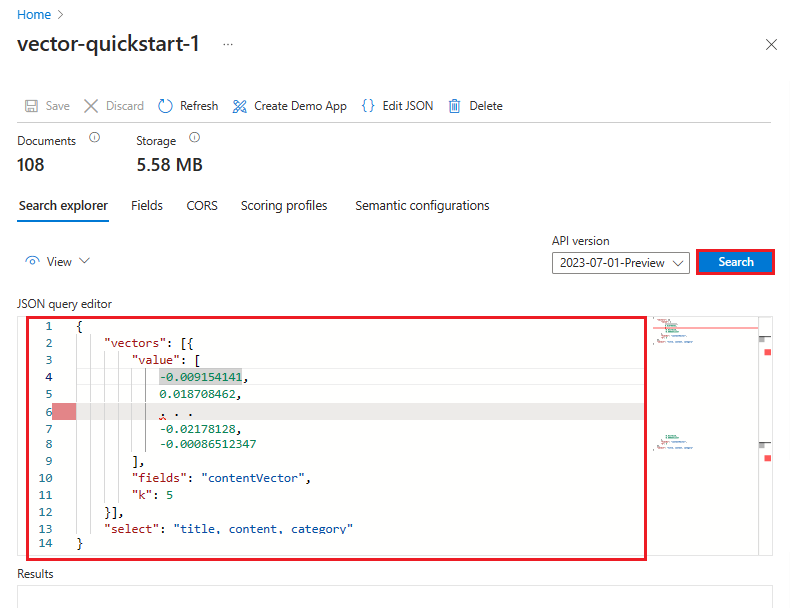
V následujícím příkladu je vektor reprezentací tohoto řetězce: "jaké služby Azure podporují fulltextové vyhledávání". Dotaz cílí na contentVector pole. Dotaz vrátí k výsledky. Skutečný vektor má 1536 vkládání, takže je v tomto příkladu oříznutý kvůli čitelnosti.
POST https://{{search-service-name}}.search.windows.net/indexes/{{index-name}}/docs/search?api-version=2024-07-01
Content-Type: application/json
api-key: {{admin-api-key}}
{
"count": true,
"select": "title, content, category",
"vectorQueries": [
{
"kind": "vector",
"vector": [
-0.009154141,
0.018708462,
. . .
-0.02178128,
-0.00086512347
],
"exhaustive": true,
"fields": "contentVector",
"weight": 0.5,
"k": 5
}
]
}
Odpověď vektorových dotazů
Ve službě Azure AI Search se odpovědi na dotazy ve výchozím nastavení skládají ze všech retrievable polí. Je ale běžné omezit výsledky hledání na podmnožinu retrievable polí jejich výpisem select v příkazu.
V vektorovém dotazu pečlivě zvažte, jestli v odpovědi potřebujete vektorová pole. Vektorová pole nejsou čitelná pro člověka, takže pokud odesíláte odpověď na webovou stránku, měli byste zvolit nevectorová pole, která představují výsledek. Pokud se například dotaz provede contentVectorproti, můžete místo toho vrátit content .
Pokud chcete ve výsledku vektorová pole, tady je příklad struktury odpovědi. contentVector je pole řetězců vkládání, které je zde oříznuto pro stručnost. Skóre hledání označuje relevanci. Další nevectorová pole jsou zahrnuta pro kontext.
{
"@odata.count": 3,
"value": [
{
"@search.score": 0.80025613,
"title": "Azure Search",
"category": "AI + Machine Learning",
"contentVector": [
-0.0018343845,
0.017952163,
0.0025753193,
...
]
},
{
"@search.score": 0.78856903,
"title": "Azure Application Insights",
"category": "Management + Governance",
"contentVector": [
-0.016821077,
0.0037742127,
0.016136652,
...
]
},
{
"@search.score": 0.78650564,
"title": "Azure Media Services",
"category": "Media",
"contentVector": [
-0.025449317,
0.0038463024,
-0.02488436,
...
]
}
]
}
Klíčové body:
kurčuje, kolik výsledků nejbližšího souseda se vrátí, v tomto případě tři. Vektorové dotazy vždy vracíkvýsledky za předpokladu, že existují alespoňkdokumenty, i když existují dokumenty se špatnou podobností, protože algoritmus najde nejbližšíksousedy vektoru dotazu.Určuje algoritmus
@search.scorevektorového vyhledávání.Pole ve výsledcích hledání jsou všechna
retrievablepole nebo pole v klauzuliselect. Během provádění vektorového dotazu se shoda provádí pouze u vektorových dat. Odpověď však může obsahovat libovolnéretrievablepole v indexu. Vzhledem k tomu, že neexistuje žádné zařízení pro dekódování výsledku vektorového pole, je zahrnutí nevectorových textových polí užitečné pro jejich lidské čitelné hodnoty.
Více vektorových polí
Vlastnost vectorQueries.fields můžete nastavit na více vektorových polí. Vektorový dotaz se provede pro každé vektorové pole, které zadáte v fields seznamu. Při dotazování na více vektorových polí se ujistěte, že každý z nich obsahuje vkládání ze stejného modelu vkládání a že se dotaz generuje také ze stejného modelu vkládání.
POST https://{{search-service-name}}.search.windows.net/indexes/{{index-name}}/docs/search?api-version=2024-07-01
Content-Type: application/json
api-key: {{admin-api-key}}
{
"count": true,
"select": "title, content, category",
"vectorQueries": [
{
"kind": "vector",
"vector": [
-0.009154141,
0.018708462,
. . .
-0.02178128,
-0.00086512347
],
"exhaustive": true,
"fields": "contentVector, titleVector",
"k": 5
}
]
}
Více vektorových dotazů
Víceotázové vektorové vyhledávání odesílá více dotazů napříč více vektorovými poli ve vyhledávacím indexu. Běžným příkladem tohoto požadavku dotazu je použití modelů, jako je CLIP pro vícemodální vektorové vyhledávání, kde stejný model může vektorizovat obrazový a textový obsah.
Následující příklad dotazu hledá podobnost v obou myImageVector a myTextVector, ale odesílá ve dvou různých vložených dotazů v uvedeném pořadí, přičemž každý provádí paralelně. Tento dotaz vytvoří výsledek, který se vyhodnotí pomocí reciproční Rank Fusion (RRF).
vectorQueriesposkytuje pole vektorových dotazů.vectorobsahuje vektory obrázků a textové vektory v indexu vyhledávání. Každá instance je samostatný dotaz.fieldsurčuje, které vektorové pole se má cílit.kje počet nejbližších sousedů, které se mají zahrnout do výsledků.
{
"count": true,
"select": "title, content, category",
"vectorQueries": [
{
"kind": "vector",
"vector": [
-0.009154141,
0.018708462,
. . .
-0.02178128,
-0.00086512347
],
"fields": "myimagevector",
"k": 5
},
{
"kind": "vector"
"vector": [
-0.002222222,
0.018708462,
-0.013770515,
. . .
],
"fields": "mytextvector",
"k": 5
}
]
}
Výsledky hledání by zahrnovaly kombinaci textu a obrázků za předpokladu, že index vyhledávání obsahuje pole pro soubor obrázku (index vyhledávání neukládá obrázky).
Dotazování pomocí integrované vektorizace
Tato část ukazuje vektorový dotaz, který vyvolá integrovanou vektorizaci , která převede textový nebo obrazový dotaz na vektor. Pro tuto funkci doporučujeme stabilní 2024-07-01 rozhraní REST API, Průzkumník služby Search nebo novější balíčky sady Azure SDK.
Předpokladem je index vyhledávání s nakonfigurovaným vektorizátorem a přiřazeným k vektorovým polím. Vektorizátor poskytuje informace o připojení k modelu vkládání použitému v době dotazu.
Průzkumník služby Search podporuje integrovanou vektorizaci v době dotazu. Pokud index obsahuje vektorová pole a vektorizátor, můžete použít předdefinovaný převod textu na vektor.
Přihlaste se k webu Azure Portal pomocí svého účtu Azure a přejděte na Search Azure AI.
V nabídce vlevo rozbalte indexy správy>vyhledávání a vyberte index. Průzkumník služby Search je první karta na stránce indexu.
Zkontrolujte profily vektorů a ověřte, že máte vektorizátor.
V Průzkumníku služby Search můžete zadat textový řetězec do výchozího vyhledávacího panelu v zobrazení dotazu. Integrovaný vektorizátor převede řetězec na vektor, provede hledání a vrátí výsledky.
Případně můžete vybrat zobrazení ZOBRAZIT>JSON a zobrazit nebo upravit dotaz. Pokud jsou vektory přítomné, Průzkumník služby Search automaticky nastaví vektorový dotaz. Pomocí zobrazení JSON můžete vybrat pole použitá při hledání a v odpovědi, přidat filtry nebo vytvořit pokročilejší dotazy, jako je hybridní. Příklad JSON je k dispozici na kartě REST API v této části.
Počet seřazených výsledků v odpovědi vektorového dotazu
Vektorový dotaz určuje k parametr, který určuje, kolik shod se vrátí ve výsledcích. Vyhledávací web vždy vrátí k počet shod. Pokud k je větší než počet dokumentů v indexu, určuje počet dokumentů horní mez toho, co lze vrátit.
Pokud znáte fulltextové vyhledávání, víte, že očekáváte nulové výsledky, pokud index neobsahuje termín nebo frázi. Při vektorovém vyhledávání ale operace hledání identifikuje nejbližší sousedy a vždy vrátí k výsledky, i když nejbližší sousedé nejsou tak podobné. Proto je možné získat výsledky pro nesmyslné nebo off-topic dotazy, zejména pokud nepoužíváte výzvy k nastavení hranic. Méně relevantní výsledky mají horší skóre podobnosti, ale stále jsou "nejbližšími" vektory, pokud není nic bližšího. Odpověď bez smysluplných výsledků tak může stále vracet k výsledky, ale skóre podobnosti každého výsledku by bylo nízké.
Tento problém může zmírnit hybridní přístup , který zahrnuje fulltextové vyhledávání. Dalším zmírněním je nastavení minimální prahové hodnoty pro skóre hledání, ale pouze v případě, že je dotaz čistě jedním vektorovým dotazem. Hybridní dotazy nejsou příznivé pro minimální prahové hodnoty, protože rozsahy RRF jsou tak menší a nestálé.
Mezi parametry dotazu ovlivňující počet výsledků patří:
"k": nvýsledky pro dotazy pouze s vektory"top": nvýsledky pro hybridní dotazy, které obsahují parametr "search".
"k" i "top" jsou volitelné. Není zadáno, výchozí počet výsledků v odpovědi je 50. Můžete nastavit "horní" a "přeskočit" na stránku prostřednictvím dalších výsledků nebo změnit výchozí.
Algoritmy řazení používané ve vektorovém dotazu
Hodnocení výsledků se vypočítá buď takto:
- Metrika podobnosti
- Reciproční fúzní pořadí (RRF), pokud existuje více sad výsledků hledání.
Metrika podobnosti
Metrika podobnosti zadaná v části indexu vectorSearch dotazu jen pro vektor. Platné hodnoty jsou cosine, euclidean a dotProduct.
Modely vkládání Azure OpenAI používají kosinusovou podobnost, takže pokud používáte modely vkládání Azure OpenAI, cosine je doporučená metrika. Mezi další podporované metriky řazení patří euclidean a dotProduct.
Použití RRF
Více sad se vytvoří, pokud dotaz cílí na více vektorových polí, spustí paralelně více vektorových dotazů nebo pokud je dotaz hybridní vektorové a fulltextové vyhledávání s sémantickým řazením nebo bez.
Během provádění dotazu může vektorový dotaz cílit pouze na jeden interní vektorový index. Pro více vektorových polí a více vektorových dotazů proto vyhledávací web generuje více dotazů, které cílí na odpovídající vektorové indexy každého pole. Výstup je sada seřazených výsledků pro každý dotaz, které jsou sloučeny pomocí RRF. Další informace naleznete v tématu Bodování relevance pomocí reciproční Rank Fusion (RRF).
Vektorové váhy
weight Přidejte parametr dotazu, který určuje relativní váhu každého vektorového dotazu zahrnutého do vyhledávacích operací. Tato hodnota se používá při kombinování výsledků více seznamů řazení vytvořených dvěma nebo více vektorovými dotazy ve stejném požadavku nebo z vektorové části hybridního dotazu.
Výchozí hodnota je 1,0 a hodnota musí být kladné číslo větší než nula.
Váhy se používají při výpočtu skóre sloučeného pořadí jednotlivých dokumentů. Výpočet je násobitelem weight hodnoty oproti skóre pořadí dokumentu v příslušné sadě výsledků.
Následující příklad je hybridní dotaz se dvěma řetězci vektorového dotazu a jedním textovým řetězcem. Váhy se přiřazují vektorům dotazů. První dotaz je 0,5 nebo polovina váhy, což snižuje jeho důležitost v požadavku. Druhý vektorový dotaz je dvakrát důležitý.
POST https://[service-name].search.windows.net/indexes/[index-name]/docs/search?api-version=2024-07-01
{
"vectorQueries": [
{
"kind": "vector",
"vector": [1.0, 2.0, 3.0],
"fields": "my_first_vector_field",
"k": 10,
"weight": 0.5
},
{
"kind": "vector",
"vector": [4.0, 5.0, 6.0],
"fields": "my_second_vector_field",
"k": 10,
"weight": 2.0
}
],
"search": "hello world"
}
Hmotnost vektorů se vztahuje pouze na vektory. Textový dotaz v tomto příkladu ("hello world") má implicitní váhu 1,0 nebo neutrální hmotnost. V hybridním dotazu ale můžete zvýšit nebo snížit důležitost textových polí nastavením maxTextRecallSize.
Nastavení prahových hodnot pro vyloučení výsledků s nízkým skóre (Preview)
Vzhledem k tomu, že hledání nejbližšího souseda vždy vrací požadované k sousedy, je možné v rámci splnění k požadavku na číslo u výsledků hledání získat více shod s nízkým skóre. Pokud chcete vyloučit výsledky hledání s nízkým skóre, můžete přidat threshold parametr dotazu, který vyfiltruje výsledky na základě minimálního skóre. Filtrování probíhá před rozdělením výsledků z různých sad úplností.
Tento parametr je stále ve verzi Preview. Doporučujeme rozhraní REST API verze Preview 2024-05-01-preview.
V tomto příkladu jsou všechny shody, které skóre nižší než 0,8 jsou vyloučeny z výsledků hledání vektorů, i když počet výsledků klesne pod k.
POST https://[service-name].search.windows.net/indexes/[index-name]/docs/search?api-version=2024-05-01-preview
Content-Type: application/json
api-key: [admin key]
{
"vectorQueries": [
{
"kind": "vector",
"vector": [1.0, 2.0, 3.0],
"fields": "my-cosine-field",
"threshold": {
"kind": "vectorSimilarity",
"value": 0.8
}
}
]
}
MaxTextSizeRecall pro hybridní vyhledávání (Preview)
Vektorové dotazy se často používají v hybridních konstruktorech, které obsahují nevectorová pole. Pokud zjistíte, že výsledky seřazené podle BM25 jsou ve výsledcích hybridních dotazů vyšší nebo nižší, můžete nastavit maxTextRecallSize zvýšení nebo snížení výsledků seřazených podle BM25 pro hybridní řazení.
Tuto vlastnost můžete nastavit pouze v hybridních požadavcích, které obsahují komponenty "search" i "vectorQueries".
Tento parametr je stále ve verzi Preview. Doporučujeme rozhraní REST API verze Preview 2024-05-01-preview.
Další informace naleznete v tématu Set maxTextRecallSize – Vytvoření hybridního dotazu.
Další kroky
V dalším kroku si projděte příklady kódu vektorového dotazu v Pythonu, C# nebo JavaScriptu.