Defragmentace metrik a zatížení v Service Fabric
Výchozí strategií Správce prostředků clusteru Service Fabric pro správu metrik zatížení v clusteru je distribuce zatížení. Zajištění rovnoměrného využití uzlů zabraňuje horkým a studeným místům, která vedou k kolizím i plýtvání zdroji. Distribuce úloh v clusteru je také nejbezpečnější z hlediska přeživších selhání, protože zajišťuje, že selhání nevybere velké procento dané úlohy.
Resource Manager clusteru Service Fabric podporuje jinou strategii správy zatížení, což je defragmentace. Defragmentace znamená, že místo pokusu o distribuci využití metriky v clusteru se konsoliduje. Konsolidace je jen inverze výchozí strategie vyrovnávání – místo minimalizace průměrné směrodatné odchylky zatížení metriky se Cluster Resource Manager pokusí tuto strategii zvýšit.
Kdy použít defragmentaci
Distribuce zatížení v clusteru spotřebovává některé prostředky na každém uzlu. Některé úlohy vytvářejí služby, které jsou mimořádně velké a využívají většinu nebo všechny uzly. V těchto případech je možné, že když se vytvoří velké úlohy, které na žádném uzlu nemá dostatek místa, aby je bylo možné spustit. Velké úlohy nejsou v Service Fabric problém; v těchto případech Správce prostředků clusteru zjistí, že musí změnit uspořádání clusteru, aby se uvolnil prostor pro tuto velkou úlohu. Mezitím ale musí úloha čekat na naplánování v clusteru.
Pokud se bude pohybovat mnoho služeb a stavu, může trvat dlouhou dobu, než se velká úloha umístí do clusteru. To je pravděpodobnější, pokud jsou i jiné úlohy v clusteru velké, takže změna uspořádání trvá déle. Tým Service Fabric měří časy vytváření v simulacích tohoto scénáře. Zjistili jsme, že vytváření velkých služeb trvalo mnohem déle, jakmile se využití clusteru překročilo mezi 30 % a 50 %. Abychom tento scénář zvládli, zavedli jsme defragmentaci jako strategii vyrovnávání. Zjistili jsme, že u velkých úloh, zejména těch, kde byla doba vytváření důležitá, defragmentace opravdu pomohla těmto novým úlohám naplánovat v clusteru.
Metriky defragmentace můžete nakonfigurovat tak, aby správce prostředků clusteru proaktivně zkusil kondenzovat zatížení služeb do méně uzlů. To pomáhá zajistit, že pro velké služby je téměř vždy prostor bez nutnosti přeuspořádání clusteru. Cluster nemusí přeuspořádat, což umožňuje rychle vytvářet velké úlohy.
Většina lidí nepotřebuje defragmentaci. Služby jsou obvykle malé, takže není těžké najít místo pro ně v clusteru. Pokud je možné přeuspořádání, jde to rychle, protože většina služeb je malá a dá se rychle a paralelně přesunout. Pokud ale máte velké služby a potřebujete je rychle vytvořit, je pro vás strategie defragmentace určená. Dále probereme kompromisy při použití defragmentace.
Kompromisy pro defragmentaci
Defragmentace může zvýšit dopad selhání, protože na uzlech, které selžou, běží více služeb. Defragmentace může také zvýšit náklady, protože prostředky v clusteru se musí uchovávat v rezervě a čekat na vytvoření velkých úloh.
Následující diagram znázorňuje vizuální znázornění dvou clusterů, jeden je defragmentovaný a druhý, který není.
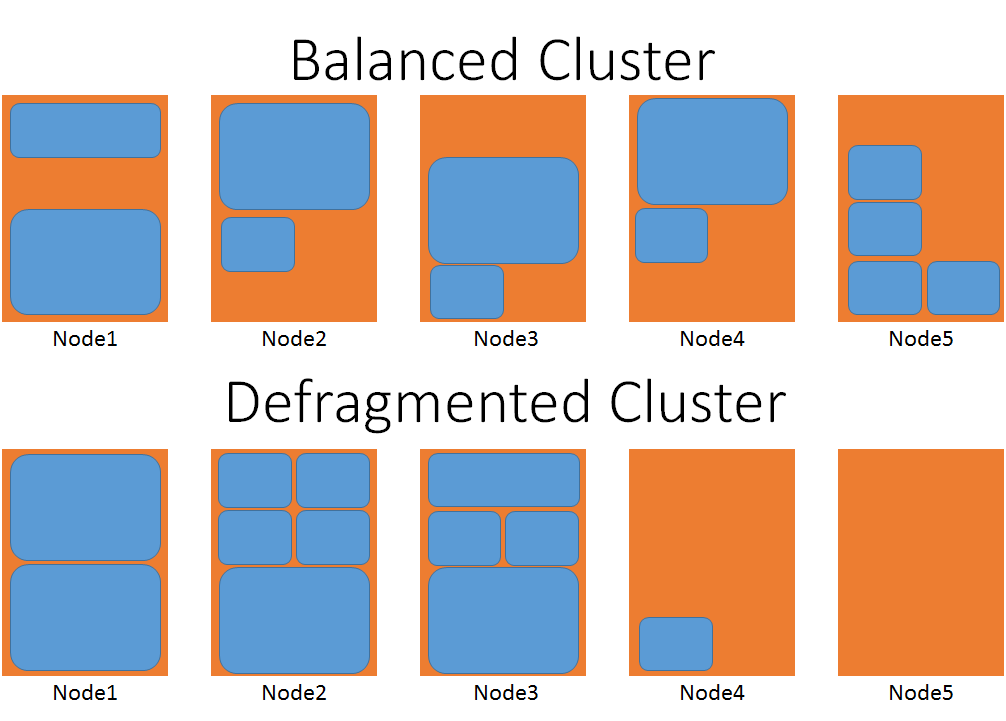
V vyváženém případě zvažte počet přesunů, které by bylo nutné umístit jeden z největších objektů služby. V defragmentovaném clusteru může být velká úloha umístěna na uzlech čtyři nebo pět, aniž by bylo nutné čekat na přesunutí jiných služeb.
Defragmentace pro a nevýhody
Jaké jsou další koncepční kompromisy? Tady je rychlá tabulka věcí, na které byste se mohli zamyslet:
| Defragmentace pro profesionály | Defragmentace nevýhody |
|---|---|
| Umožňuje rychlejší vytváření velkých služeb. | Soustřeďuje zatížení na méně uzlů a zvyšuje kolize. |
| Umožňuje nižší přesun dat během vytváření. | Selhání můžou mít vliv na více služeb a způsobit větší četnost změn. |
| Umožňuje bohatý popis požadavků a rekultivace prostoru. | Složitější celková konfigurace správy prostředků |
Defragmentované a normální metriky můžete kombinovat ve stejném clusteru. Správce prostředků clusteru se snaží co nejvíce konsolidovat metriky defragmentace a současně rozšířit ostatní. Výsledky kombinování defragmentace a strategie vyrovnávání závisí na několika faktorech, mezi které patří:
- počet metrik vyrovnávání vs. počet metrik defragmentace
- Zda jakákoli služba používá oba typy metrik
- váhy metrik
- aktuální zatížení metriky
K určení přesné potřebné konfigurace se vyžaduje experimentování. Před povolením metrik defragmentace v produkčním prostředí doporučujeme důkladné měření vašich úloh. To platí zejména při kombinování defragmentace a vyvážené metriky ve stejné službě.
Konfigurace metrik defragmentace
Konfigurace metrik defragmentace je globální rozhodnutí v clusteru a pro defragmentaci je možné vybrat jednotlivé metriky. Následující fragmenty konfigurace ukazují, jak nakonfigurovat metriky pro defragmentaci. V tomto případě je metrika Metric1 nakonfigurovaná jako defragmentační metrika, zatímco metrika 2 bude nadále vyvážená normálně.
ClusterManifest.xml:
<Section Name="DefragmentationMetrics">
<Parameter Name="Metric1" Value="true" />
<Parameter Name="Metric2" Value="false" />
</Section>
prostřednictvím ClusterConfig.json pro samostatná nasazení nebo Template.json pro clustery hostované v Azure:
"fabricSettings": [
{
"name": "DefragmentationMetrics",
"parameters": [
{
"name": "Metric1",
"value": "true"
},
{
"name": "Metric2",
"value": "false"
}
]
}
]
Další kroky
- Správce prostředků clusteru má mnoho možností pro popis clusteru. Další informace o nich najdete v tomto článku popisující cluster Service Fabric.
- Metriky jsou způsob, jakým správce prostředků clusteru Service Fabric spravuje spotřebu a kapacitu v clusteru. Další informace o metrikách a jejich konfiguraci najdete v tomto článku.