Jak používat OPENROWSET s využitím bezserverového fondu SQL ve službě Azure Synapse Analytics
Funkce OPENROWSET(BULK...) umožňuje přístup k souborům ve službě Azure Storage. OPENROWSET funkce čte obsah vzdáleného zdroje dat (například souboru) a vrací obsah jako sadu řádků. V rámci prostředku bezserverového fondu SQL se k poskytovateli hromadné sady řádků OPENROWSET přistupuje voláním funkce OPENROWSET a zadáním možnosti BULK.
Na OPENROWSET funkci lze odkazovat v FROM klauzuli dotazu, jako by se jednalo o název OPENROWSETtabulky . Podporuje hromadné operace prostřednictvím integrovaného zprostředkovatele BULK, který umožňuje čtení a vracení dat ze souboru jako sadu řádků.
Poznámka:
Funkce OPENROWSET není ve vyhrazeném fondu SQL podporovaná.
Zdroj dat
Funkce OPENROWSET v Synapse SQL čte obsah souborů ze zdroje dat. Zdroj dat je účet úložiště Azure, na který se dá explicitně odkazovat ve OPENROWSET funkci, nebo se může dynamicky odvozovat z adresy URL souborů, které chcete číst.
Funkce OPENROWSET může volitelně obsahovat DATA_SOURCE parametr pro určení zdroje dat, který obsahuje soubory.
OPENROWSETbezDATA_SOURCEpoužití k přímému čtení obsahu souborů z umístění adresy URL určeného jakoBULKmožnost:SELECT * FROM OPENROWSET(BULK 'http://<storage account>.dfs.core.windows.net/container/folder/*.parquet', FORMAT = 'PARQUET') AS [file]
Jedná se o rychlý a snadný způsob, jak číst obsah souborů bez předkonfigurace. Tato možnost umožňuje použít možnost základního ověřování pro přístup k úložišti (předávání Microsoft Entra pro přihlášení Microsoft Entra a token SAS pro přihlášení SQL).
OPENROWSETproDATA_SOURCEpřístup k souborům v zadaném účtu úložiště:SELECT * FROM OPENROWSET(BULK '/folder/*.parquet', DATA_SOURCE='storage', --> Root URL is in LOCATION of DATA SOURCE FORMAT = 'PARQUET') AS [file]Tato možnost umožňuje nakonfigurovat umístění účtu úložiště ve zdroji dat a zadat metodu ověřování, která se má použít pro přístup k úložišti.
Důležité
OPENROWSETposkytujeDATA_SOURCErychlý a snadný způsob přístupu k souborům úložiště, ale nabízí omezené možnosti ověřování. Například instanční objekty Microsoft Entra mají přístup k souborům pouze pomocí jejich identity Microsoft Entra nebo veřejně dostupných souborů. Pokud potřebujete výkonnější možnosti ověřování, použijteDATA_SOURCEmožnost a definujte přihlašovací údaje, které chcete použít pro přístup k úložišti.
Zabezpečení
Uživatel databáze musí mít ADMINISTER BULK OPERATIONS oprávnění k používání OPENROWSET funkce.
Správce úložiště musí také uživateli povolit přístup k souborům zadáním platného tokenu SAS nebo povolením instančního objektu Microsoft Entra pro přístup k souborům úložiště. Další informace o řízení přístupu k úložišti najdete v tomto článku.
OPENROWSET Pomocí následujících pravidel určete, jak se ověřit v úložišti:
DATA_SOURCEBezOPENROWSETověřovacího mechanismu závisí na typu volajícího.- Každý uživatel může používat
OPENROWSETbezDATA_SOURCEčtení veřejně dostupných souborů v úložišti Azure. - Přihlášení Microsoft Entra mají přístup k chráněným souborům pomocí vlastní identity Microsoft Entra, pokud azure storage umožňuje uživateli Microsoft Entra přístup k podkladovým souborům (například pokud má volající
Storage Readeroprávnění k úložišti Azure). - Přihlášení SQL můžou také používat
OPENROWSETbezDATA_SOURCEpřístupu k veřejně dostupným souborům, souborům chráněným pomocí tokenu SAS nebo spravované identitě pracovního prostoru Synapse. Abyste umožnili přístup k souborům úložiště, musíte vytvořit přihlašovací údaje s vymezeným serverem.
- Každý uživatel může používat
DATA_SOURCEMechanismusOPENROWSETověřování je definován v přihlašovacích údajích s oborem databáze přiřazených k odkazovanému zdroji dat. Tato možnost umožňuje přistupovat k veřejně dostupnému úložišti nebo přistupovat k úložišti pomocí tokenu SAS, spravované identity pracovního prostoru nebo identity volajícího Microsoft Entra (pokud je volajícím instanční objekt Microsoft Entra). PokudDATA_SOURCEodkazujete na úložiště Azure, které není veřejné, budete muset vytvořit přihlašovací údaje s oborem databáze a odkazovat na nějDATA SOURCE, abyste umožnili přístup k souborům úložiště.
Volající musí mít REFERENCES oprávnění k přihlašovacím údajům, aby ho mohl použít k ověření v úložišti.
Syntaxe
--OPENROWSET syntax for reading Parquet or Delta Lake files
OPENROWSET
( { BULK 'unstructured_data_path' , [DATA_SOURCE = <data source name>, ]
FORMAT= ['PARQUET' | 'DELTA'] }
)
[WITH ( {'column_name' 'column_type' }) ]
[AS] table_alias(column_alias,...n)
--OPENROWSET syntax for reading delimited text files
OPENROWSET
( { BULK 'unstructured_data_path' , [DATA_SOURCE = <data source name>, ]
FORMAT = 'CSV'
[ <bulk_options> ]
[ , <reject_options> ] }
)
WITH ( {'column_name' 'column_type' [ 'column_ordinal' | 'json_path'] })
[AS] table_alias(column_alias,...n)
<bulk_options> ::=
[ , FIELDTERMINATOR = 'char' ]
[ , ROWTERMINATOR = 'char' ]
[ , ESCAPECHAR = 'char' ]
[ , FIRSTROW = 'first_row' ]
[ , FIELDQUOTE = 'quote_characters' ]
[ , DATA_COMPRESSION = 'data_compression_method' ]
[ , PARSER_VERSION = 'parser_version' ]
[ , HEADER_ROW = { TRUE | FALSE } ]
[ , DATAFILETYPE = { 'char' | 'widechar' } ]
[ , CODEPAGE = { 'ACP' | 'OEM' | 'RAW' | 'code_page' } ]
[ , ROWSET_OPTIONS = '{"READ_OPTIONS":["ALLOW_INCONSISTENT_READS"]}' ]
<reject_options> ::=
{
| MAXERRORS = reject_value,
| ERRORFILE_DATA_SOURCE = <data source name>,
| ERRORFILE_LOCATION = '/REJECT_Directory'
}
Argumenty
Pro vstupní soubory, které obsahují cílová data pro dotazování, máte tři možnosti. Platné hodnoty jsou:
CSV – obsahuje libovolný textový soubor s oddělovači řádků a sloupců s oddělovači řádků a sloupců. Libovolný znak lze použít jako oddělovač polí, například TSV: FIELDTERMINATOR = tab.
ParqueT – binární soubor ve formátu Parquet.
DELTA – sada souborů Parquet uspořádaných ve formátu Delta Lake (Preview).
Hodnoty s prázdnými mezerami nejsou platné. Například CSV není platná hodnota.
"unstructured_data_path"
Unstructured_data_path, která vytváří cestu k datům, může být absolutní nebo relativní cesta:
- Absolutní cesta ve formátu
\<prefix>://\<storage_account_path>/\<storage_path>umožňuje uživateli přímo číst soubory. - Relativní cesta ve formátu
<storage_path>, který musí být použit s parametremDATA_SOURCEa popisuje vzor souboru v rámci <storage_account_path> umístění definovaném vEXTERNAL DATA SOURCE.
Níže najdete příslušné <hodnoty cest> účtu úložiště, které budou propojit s vaším konkrétním externím zdrojem dat.
| Externí zdroj dat | Předpona | Cesta k účtu úložiště |
|---|---|---|
| Azure Blob Storage | http[s] | <>storage_account.blob.core.windows.net/path/file |
| Azure Blob Storage | wasb[s] | <container>@<storage_account.blob.core.windows.net/path/file> |
| Azure Data Lake Store Gen1 | http[s] | <>storage_account.azuredatalakestore.net/webhdfs/v1 |
| Azure Data Lake Store Gen2 | http[s] | <>storage_account.dfs.core.windows.net/path/file |
| Azure Data Lake Store Gen2 | abfs[s] | <>file_system@<account_name.dfs.core.windows.net/path/file> |
"<storage_path>"
Určuje cestu v úložišti, která odkazuje na složku nebo soubor, který chcete přečíst. Pokud cesta odkazuje na kontejner nebo složku, budou všechny soubory načteny z tohoto konkrétního kontejneru nebo složky. Soubory v podsložkách nebudou zahrnuty.
Pomocí zástupných znaků můžete cílit na více souborů nebo složek. Je povoleno použití více nekonekutivních zástupných znaků.
Níže je příklad, který čte všechny soubory CSV začínající populací ze všech složek počínaje /csv/population:
https://sqlondemandstorage.blob.core.windows.net/csv/population*/population*.csv
Pokud zadáte unstructured_data_path jako složku, dotaz bezserverového fondu SQL načte soubory z této složky.
Bezserverový fond SQL můžete dát pokyn k procházení složek zadáním /* na konci cesty, například: https://sqlondemandstorage.blob.core.windows.net/csv/population/**
Poznámka:
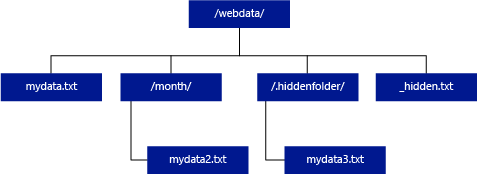
Na rozdíl od Hadoopu a PolyBase nevrací bezserverový fond SQL podsložky, pokud nezadáte na konci cesty /**. Stejně jako Hadoop a PolyBase nevrací soubory, pro které název souboru začíná podtržením (_) nebo tečkou (.).
Pokud v následujícím příkladu unstructured_data_path=https://mystorageaccount.dfs.core.windows.net/webdata/ dotaz bezserverového fondu SQL vrátí řádky z mydata.txt. Nevrátí mydata2.txt a mydata3.txt, protože jsou umístěné v podsložce.
[WITH ( {'column_name' 'column_type' [ 'column_ordinal'] }) ]
Klauzule WITH umožňuje zadat sloupce, které chcete číst ze souborů.
U datových souborů CSV můžete číst všechny sloupce a zadat názvy sloupců a jejich datové typy. Pokud chcete podmnožinu sloupců, pomocí řadových čísel vyberte sloupce z původního datového souboru podle řad. Sloupce budou vázány pořadovým označením. Pokud se použije HEADER_ROW = PRAVDA, vazba sloupce se provádí podle názvu sloupce místo řadové pozice.
Tip
U souborů CSV také můžete vynechat klauzuli WITH. Datové typy se automaticky odvozí z obsahu souboru. Argument HEADER_ROW můžete použít k určení existence řádku záhlaví, ve kterém budou názvy sloupců velkých a malých písmen čtena z řádku záhlaví. Podrobnosti najdete v tématu Automatické zjišťování schématu.
Pro soubory Parquet nebo Delta Lake zadejte názvy sloupců, které odpovídají názvům sloupců v původních datových souborech. Sloupce budou vázané podle názvu a rozlišují se malá a velká písmena. Pokud je klauzule WITH vynechána, vrátí se všechny sloupce ze souborů Parquet.
Důležité
U názvů sloupců v souborech Parquet a Delta Lake se rozlišují malá a velká písmena. Pokud v souborech zadáte název sloupce, který se liší od názvu sloupce,
NULLvrátí se pro tento sloupec hodnoty.
column_name = Název výstupního sloupce. Pokud je zadaný, tento název přepíše název sloupce ve zdrojovém souboru a názvu sloupce zadaném v cestě JSON, pokud existuje. Pokud není zadaný json_path, přidá se automaticky jako $.column_name. Zkontrolujte chování json_path argumentu.
column_type = Datový typ pro výstupní sloupec. Tady se provede implicitní převod datového typu.
column_ordinal = pořadové číslo sloupce ve zdrojových souborech. Tento argument se pro soubory Parquet ignoruje, protože vazba se provádí podle názvu. Následující příklad by vrátil druhý sloupec pouze ze souboru CSV:
WITH (
--[country_code] VARCHAR (5) COLLATE Latin1_General_BIN2,
[country_name] VARCHAR (100) COLLATE Latin1_General_BIN2 2
--[year] smallint,
--[population] bigint
)
json_path = výraz cesty JSON ke sloupci nebo vnořené vlastnosti. Výchozí režim cesty je laxní.
Poznámka:
Dotaz v přísném režimu selže s chybou, pokud zadanou cestu neexistuje. V lax režimu dotaz bude úspěšný a výraz cesty JSON se vyhodnotí jako NULL.
<bulk_options>
FIELDTERMINATOR ='field_terminator'
Určuje ukončovací znak pole, který se má použít. Výchozí ukončovací znak pole je čárka (",").
ROWTERMINATOR ='row_terminator''
Určuje ukončovací znak řádku, který se má použít. Pokud není zadaný ukončovací znak řádku, použije se jeden z výchozích ukončovačů. Výchozí ukončovací znaky pro PARSER_VERSION = 1.0 jsou \r\n, \n a \r. Výchozí ukončovací znaky pro PARSER_VERSION = 2.0 jsou \r\n a \n.
Poznámka:
Pokud použijete PARSER_VERSION='1.0' a jako ukončovací znak řádku zadáte \n (nový řádek), bude automaticky předpona znakem \r (návrat na začátek řádku), což má za následek ukončení řádku \r\n.
ESCAPE_CHAR = 'char'
Určuje znak v souboru, který se používá k řídicímu znaku a všechny hodnoty oddělovače v souboru. Pokud za řídicím znakem následuje jiná hodnota než samotná nebo jakákoli hodnota oddělovače, při čtení hodnoty se řídicí znak zahodí.
Parametr ESCAPECHAR se použije bez ohledu na to, jestli je pole FIELDQUOTE nebo není povolené. Nebude použit k uvozování znaku. Znak uvozování musí být uvozován jiným znakem uvozování. Znak uvozování se může objevit v hodnotě sloupce pouze v případě, že je hodnota zapouzdřena znaky uvozování.
FIRSTROW = 'first_row'
Určuje počet prvního řádku, který se má načíst. Výchozí hodnota je 1 a označuje první řádek v zadaném datovém souboru. Čísla řádků jsou určena počítáním ukončovačů řádků. FIRSTROW je založená na 1.
FIELDQUOTE = 'field_quote'
Určuje znak, který se použije jako znak uvozovek v souboru CSV. Pokud není zadaný, použije se znak uvozovky (").
DATA_COMPRESSION = 'data_compression_method'
Určuje metodu komprese. Podporováno pouze v PARSER_VERSION='1.0'. Podporuje se následující metoda komprese:
- GZIP
PARSER_VERSION = 'parser_version'
Určuje verzi analyzátoru, která se má použít při čtení souborů. Aktuálně podporované verze analyzátoru CSV jsou 1.0 a 2.0:
- PARSER_VERSION = '1.0'
- PARSER_VERSION = '2.0'
Analyzátor CSV verze 1.0 je výchozí a je bohatý na funkce. Verze 2.0 je vytvořená pro výkon a nepodporuje všechny možnosti a kódování.
Specifika analyzátoru CSV verze 1.0:
- Následující možnosti nejsou podporované: HEADER_ROW.
- Výchozí ukončovací znaky jsou \r\n, \n a \r.
- Pokud jako ukončovací znak řádku zadáte \n (nový řádek), bude automaticky předpona znakem \r (návrat na začátek řádku), který má za následek ukončení řádku \r\n.
Specifika analyzátoru CSV verze 2.0:
- Nepodporují se všechny datové typy.
- Maximální délka sloupce znaků je 8000.
- Maximální limit velikosti řádku je 8 MB.
- Následující možnosti nejsou podporované: DATA_COMPRESSION.
- Prázdný řetězec v quotedu ("") se interpretuje jako prázdný řetězec.
- Možnost DATEFORMAT SET není dodržena.
- Podporovaný formát pro datový typ DATE: RRRR-MM-DD
- Podporovaný formát pro datový typ TIME: HH:MM:SS[.zlomek sekund]
- Podporovaný formát pro datový typ DATETIME2: RRRR-MM-DD HH:MM:SS[.zlomkové sekundy]
- Výchozí ukončovací znaky jsou \r\n a \n.
HEADER_ROW = { TRUE | FALSE }
Určuje, jestli soubor CSV obsahuje řádek záhlaví. Výchozí hodnota je FALSE. podporována v PARSER_VERSION='2.0'. Pokud je hodnota TRUE, názvy sloupců se načtou z prvního řádku podle argumentu FIRSTROW. Pokud je zadána hodnota TRUE a schéma pomocí funkce WITH, vazba názvů sloupců bude provedena podle názvu sloupce, nikoli řadových pozic.
DATAFILETYPE = { 'char' | "widechar" }
Určuje kódování: char používá se pro UTF8, widechar slouží pro soubory UTF16.
CODEPAGE = { 'ACP' | 'OEM' | 'RAW' | 'code_page' }
Určuje znakovou stránku dat v datovém souboru. Výchozí hodnota je 65001 (kódování UTF-8). Další podrobnosti o této možnosti najdete tady.
ROWSET_OPTIONS = '{"READ_OPTIONS":["ALLOW_INCONSISTENT_READS"]}'
Tato možnost zakáže kontrolu úprav souborů během provádění dotazu a přečte soubory, které se aktualizují během spuštění dotazu. To je užitečná možnost, když potřebujete číst soubory jen pro připojení, které jsou připojeny při běhu dotazu. V doplňovatelných souborech se stávající obsah neaktualizuje a přidají se jenom nové řádky. Proto je pravděpodobnost nesprávných výsledků minimalizovaná ve srovnání s aktualizovatelnými soubory. Tato možnost vám může umožnit čtení často připojených souborů bez zpracování chyb. Další informace najdete v části dotazování přidávaných souborů CSV.
Možnosti odmítnutí
Poznámka:
Funkce odmítnutých řádků je ve verzi Public Preview. Upozorňujeme, že funkce odmítnutých řádků funguje pro textové soubory s oddělovači a PARSER_VERSION 1.0.
Můžete zadat parametry zamítnutí, které určují, jak bude služba zpracovávat nezašpiněné záznamy, které načítá z externího zdroje dat. Datový záznam se považuje za nezašpiněný, pokud skutečné datové typy neodpovídají definicím sloupců externí tabulky.
Pokud nezadáte nebo změníte možnosti zamítnutí, služba použije výchozí hodnoty. Služba použije možnosti zamítnutí k určení počtu řádků, které je možné odmítnout před selháním skutečného dotazu. Dotaz vrátí (částečné) výsledky, dokud nedojde k překročení prahové hodnoty zamítnutí. Poté selže s příslušnou chybovou zprávou.
MAXERRORS = reject_value
Určuje počet řádků, které lze odmítnout před selháním dotazu. MAXERRORS musí být celé číslo od 0 do 2 147 483 647.
ERRORFILE_DATA_SOURCE = zdroj dat
Určuje zdroj dat, kde se zamítají řádky a odpovídající chybový soubor by se měl zapsat.
ERRORFILE_LOCATION = umístění adresáře
Určuje adresář v rámci DATA_SOURCE nebo ERROR_FILE_DATASOURCE, pokud je zadán, že odmítnuté řádky a odpovídající chybový soubor by měly být zapsány. Pokud zadaná cesta neexistuje, služba ji vytvoří vaším jménem. Vytvoří se podřízený adresář s názvem "rejectedrows". Znak "" zajistí, že adresář bude uchycený pro jiné zpracování dat, pokud není explicitně pojmenovaný v parametru location. V tomto adresáři existuje složka vytvořená na základě času odeslání v YearMonthDay_HourMinuteSecond_StatementID formátu (např. 20180330-173205-559EE7D2-196D-400A-806D-3BF5D007F891). ID příkazu můžete použít ke korelaci složky s dotazem, který ho vygeneroval. V této složce jsou zapsány dva soubory: error.json soubor a datový soubor.
error.json soubor obsahuje pole JSON s zjištěnými chybami souvisejícími s odmítnutými řádky. Každý prvek představující chybu obsahuje následující atributy:
| Atribut | Popis |
|---|---|
| Chyba | Důvod zamítnutí řádku |
| Řádek | Odmítnuté pořadové číslo řádku v souboru |
| Column | Odmítnuté pořadové číslo sloupce |
| Hodnota | Odmítnutá hodnota sloupce Pokud je hodnota větší než 100 znaků, zobrazí se pouze prvních 100 znaků. |
| Soubor | Cesta k souboru, do kterého řádek patří. |
Analýza textu s rychlým oddělovačem
Můžete použít dvě verze analyzátoru textu s oddělovači. Analyzátor CSV verze 1.0 je výchozí a má bohatou funkci, zatímco analyzátor verze 2.0 je vytvořený pro zajištění výkonu. Zlepšení výkonu analyzátoru 2.0 pochází z pokročilých technik analýzy a více vláken. Při růstu velikosti souboru bude větší rychlost.
Automatické zjišťování schématu
Soubory CSV i Parquet můžete snadno dotazovat, aniž byste museli znát nebo zadávat schéma tak, že vynecháte klauzuli WITH. Názvy sloupců a datové typy se odvozí ze souborů.
Soubory Parquet obsahují metadata sloupců, která se budou číst, mapování typů lze najít v mapování typů pro Parquet. Zkontrolujte čtení souborů Parquet bez zadání schématu pro ukázky.
U souborů CSV je možné názvy sloupců číst z řádku záhlaví. Pomocí argumentu HEADER_ROW můžete určit, zda řádek záhlaví existuje. Pokud HEADER_ROW = NEPRAVDA, použijí se obecné názvy sloupců: C1, C2, ... Cn where n is number of columns in file. Datové typy budou odvozeny z prvních 100 datových řádků. Zkontrolujte čtení souborů CSV bez zadání schématu ukázek.
Mějte na paměti, že pokud čtete počet souborů najednou, schéma se odvodí z první souborové služby z úložiště. To může znamenat, že některé z očekávaných sloupců jsou vynechány, protože soubor používaný službou k definování schématu tyto sloupce neobsahuje. V takovém případě použijte klauzuli OPENROWSET WITH.
Důležité
Existují případy, kdy nelze příslušný datový typ odvodit z důvodu nedostatku informací a místo toho se použije větší datový typ. To přináší režii na výkon a je zvláště důležité pro sloupce znaků, které budou odvozeny jako varchar(8000). Pokud chcete dosáhnout optimálního výkonu, zkontrolujte odvozené datové typy a použijte vhodné datové typy.
Mapování typů pro Parquet
Soubory Parquet a Delta Lake obsahují popisy typů pro každý sloupec. Následující tabulka popisuje, jak se typy Parquet mapují na nativní typy SQL.
| Typ Parquet | Logický typ Parquet (poznámka) | Datový typ SQL |
|---|---|---|
| BOOLEOVSKÝ | bitové | |
| BINARY / BYTE_ARRAY | varbinary | |
| DVOJITÝ | float (číslo s plovoucí řádovou čárkou) | |
| FLOAT | real | |
| INT32 | int | |
| INT64 | bigint | |
| INT96 | datetime2 | |
| FIXED_LEN_BYTE_ARRAY | binární | |
| BINÁRNÍ | UTF8 | varchar *(kolace UTF8) |
| BINÁRNÍ | STRING | varchar *(kolace UTF8) |
| BINÁRNÍ | VÝČET | varchar *(kolace UTF8) |
| FIXED_LEN_BYTE_ARRAY | UUID | uniqueidentifier |
| BINÁRNÍ | DESETINNÝ | decimal |
| BINÁRNÍ | JSON | varchar(8000) *(kolace UTF8) |
| BINÁRNÍ | BSON | Nepodporováno |
| FIXED_LEN_BYTE_ARRAY | DESETINNÝ | decimal |
| BYTE_ARRAY | INTERVAL | Nepodporováno |
| INT32 | INT(8; true) | smallint |
| INT32 | INT(16; true) | smallint |
| INT32 | INT(32; true) | int |
| INT32 | INT(8, false) | tinyint |
| INT32 | INT(16; false) | int |
| INT32 | INT(32; false) | bigint |
| INT32 | DATE | datum |
| INT32 | DESETINNÝ | decimal |
| INT32 | ČAS (MILIS) | čas |
| INT64 | INT(64; true) | bigint |
| INT64 | INT(64; false) | decimal(20;0) |
| INT64 | DESETINNÝ | decimal |
| INT64 | TIME (MICROS) | čas |
| INT64 | TIME (NANOS) | Nepodporováno |
| INT64 | TIMESTAMP (normalizováno na utc) (MILLIS / MICROS) | datetime2 |
| INT64 | TIMESTAMP (není normalizováno na utc) (MILLIS / MICROS) | bigint – před převodem hodnoty na hodnotu datetime nezapomeňte explicitně upravit bigint hodnotu s posunem časového pásma. |
| INT64 | ČASOVÉ RAZÍTKO (NANOS) | Nepodporováno |
| Komplexní typ | SEZNAM | varchar(8000), serializovaný do formátu JSON |
| Komplexní typ | MAPA | varchar(8000), serializovaný do formátu JSON |
Příklady
Čtení souborů CSV bez zadání schématu
Následující příklad přečte soubor CSV, který obsahuje řádek záhlaví bez zadání názvů sloupců a datových typů:
SELECT
*
FROM OPENROWSET(
BULK 'https://pandemicdatalake.blob.core.windows.net/public/curated/covid-19/ecdc_cases/latest/ecdc_cases.csv',
FORMAT = 'CSV',
PARSER_VERSION = '2.0',
HEADER_ROW = TRUE) as [r]
Následující příklad přečte soubor CSV, který neobsahuje řádek záhlaví bez zadání názvů sloupců a datových typů:
SELECT
*
FROM OPENROWSET(
BULK 'https://pandemicdatalake.blob.core.windows.net/public/curated/covid-19/ecdc_cases/latest/ecdc_cases.csv',
FORMAT = 'CSV',
PARSER_VERSION = '2.0') as [r]
Čtení souborů Parquet bez zadání schématu
Následující příklad vrátí všechny sloupce prvního řádku ze sady dat sčítání lidu ve formátu Parquet a bez zadání názvů sloupců a datových typů:
SELECT
TOP 1 *
FROM
OPENROWSET(
BULK 'https://azureopendatastorage.blob.core.windows.net/censusdatacontainer/release/us_population_county/year=20*/*.parquet',
FORMAT='PARQUET'
) AS [r]
Čtení souborů Delta Lake bez zadání schématu
Následující příklad vrátí všechny sloupce prvního řádku ze sady dat sčítání lidu ve formátu Delta Lake a bez zadání názvů sloupců a datových typů:
SELECT
TOP 1 *
FROM
OPENROWSET(
BULK 'https://azureopendatastorage.blob.core.windows.net/censusdatacontainer/release/us_population_county/year=20*/*.parquet',
FORMAT='DELTA'
) AS [r]
Čtení konkrétních sloupců ze souboru CSV
Následující příklad vrátí pouze dva sloupce s pořadovými čísly 1 a 4 ze souborů základního souboru*.csv. Vzhledem k tomu, že v souborech není žádný řádek záhlaví, začne číst z prvního řádku:
SELECT
*
FROM OPENROWSET(
BULK 'https://sqlondemandstorage.blob.core.windows.net/csv/population/population*.csv',
FORMAT = 'CSV',
FIRSTROW = 1
)
WITH (
[country_code] VARCHAR (5) COLLATE Latin1_General_BIN2 1,
[population] bigint 4
) AS [r]
Čtení konkrétních sloupců ze souboru Parquet
Následující příklad vrátí pouze dva sloupce prvního řádku ze sady dat sčítání lidu ve formátu Parquet:
SELECT
TOP 1 *
FROM
OPENROWSET(
BULK 'https://azureopendatastorage.blob.core.windows.net/censusdatacontainer/release/us_population_county/year=20*/*.parquet',
FORMAT='PARQUET'
)
WITH (
[stateName] VARCHAR (50),
[population] bigint
) AS [r]
Určení sloupců pomocí cest JSON
Následující příklad ukazuje, jak můžete použít výrazy cesty JSON v klauzuli WITH a demonstrovat rozdíl mezi striktními a laxními režimy cesty:
SELECT
TOP 1 *
FROM
OPENROWSET(
BULK 'https://azureopendatastorage.blob.core.windows.net/censusdatacontainer/release/us_population_county/year=20*/*.parquet',
FORMAT='PARQUET'
)
WITH (
--lax path mode samples
[stateName] VARCHAR (50), -- this one works as column name casing is valid - it targets the same column as the next one
[stateName_explicit_path] VARCHAR (50) '$.stateName', -- this one works as column name casing is valid
[COUNTYNAME] VARCHAR (50), -- STATEname column will contain NULLs only because of wrong casing - it targets the same column as the next one
[countyName_explicit_path] VARCHAR (50) '$.COUNTYNAME', -- STATEname column will contain NULLS only because of wrong casing and default path mode being lax
--strict path mode samples
[population] bigint 'strict $.population' -- this one works as column name casing is valid
--,[population2] bigint 'strict $.POPULATION' -- this one fails because of wrong casing and strict path mode
)
AS [r]
Zadání více souborů nebo složek v cestě BULK
Následující příklad ukazuje, jak v parametru BULK použít více cest k souborům nebo složkám:
SELECT
TOP 10 *
FROM
OPENROWSET(
BULK (
'https://azureopendatastorage.blob.core.windows.net/censusdatacontainer/release/us_population_county/year=2000/*.parquet',
'https://azureopendatastorage.blob.core.windows.net/censusdatacontainer/release/us_population_county/year=2010/*.parquet'
),
FORMAT='PARQUET'
)
AS [r]
Další kroky
Další ukázky najdete v rychlém startu pro dotazování na úložiště dat, kde se dozvíte, jak číst OPENROWSET formáty souborů CSV, PARQUET, DELTA LAKE a JSON. Projděte si osvědčené postupy pro dosažení optimálního výkonu. Dozvíte se také, jak uložit výsledky dotazu do Služby Azure Storage pomocí CETAS.