Kurz 2. část: Prozkoumání a vizualizace dat pomocí poznámkových bloků Microsoft Fabric
V tomto kurzu se dozvíte, jak provádět průzkumnou analýzu dat (EDA), abyste zkoumali a analyzovali data a současně sumarizovali jejich klíčové charakteristiky pomocí technik vizualizace dat.
Použijete seaborn, knihovnu vizualizace dat Pythonu, která poskytuje rozhraní vysoké úrovně pro vytváření vizuálů na datových rámcích a polích. Další informace o seabornnaleznete v tématu Seaborn: Statistické vizualizace dat.
Použijete také Data Wrangler , nástroj založený na poznámkových blocích, který poskytuje imerzivní prostředí pro provádění průzkumných analýz a čištění dat.
Hlavními kroky v tomto kurzu jsou:
- Přečtěte si data uložená z tabulky Delta v jezeře.
- Převeďte datový rámec Sparku na datový rámec Pandas, který knihovny vizualizací Pythonu podporují.
- Pomocí nástroje Data Wrangler proveďte počáteční čištění a transformaci dat.
- Provádět průzkumnou analýzu dat pomocí
seaborn.
Požadavky
Získejte předplatné Microsoft Fabric. Nebo si zaregistrujte bezplatnou zkušební verzi Microsoft Fabric.
Přihlaste se k Microsoft Fabric.
Použijte přepínač zkušeností v levém dolním rohu domovské stránky a přepněte na Fabric.
Toto je část 2 z 5 v sérii kurzů. K dokončení tohoto kurzu nejprve dokončete:
Sledujte v poznámkovém bloku
2-explore-cleanse-data.ipynb je poznámkový blok, který doprovází tento kurz.
Pokud chcete otevřít doprovodný poznámkový blok pro tento kurz, postupujte podle pokynů v části Příprava systému na kurzy datových věd, abyste importovali poznámkový blok do svého pracovního prostoru.
Pokud chcete raději zkopírovat a vložit kód z této stránky, můžete vytvořit nový poznámkový blok.
Nezapomeňte připojit lakehouse k notebooku, než začnete spouštět kód.
Důležitý
Připojte stejný jezerní dům, který jste použili v části 1.
Čtení nezpracovaných dat ze systému lakehouse
Číst nezpracovaná data z oddílu Files v lakehouse. Tato data jste nahráli v předchozím poznámkovém bloku. Před spuštěním tohoto kódu se ujistěte, že jste k tomuto poznámkovému bloku připojili stejný jezerní dům, který jste použili v části 1.
df = (
spark.read.option("header", True)
.option("inferSchema", True)
.csv("Files/churn/raw/churn.csv")
.cache()
)
Vytvoření datového rámce pandas z datové sady
Převeďte datový rámec Sparku na datový rámec pandas pro snadnější zpracování a vizualizaci.
df = df.toPandas()
Zobrazení nezpracovaných dat
Prozkoumejte nezpracovaná data pomocí display, proveďte některé základní statistiky a zobrazte zobrazení grafu. Nezapomeňte, že nejprve musíte importovat požadované knihovny, jako jsou Numpy, Pnadas, Seaborna Matplotlib pro analýzu a vizualizaci dat.
import seaborn as sns
sns.set_theme(style="whitegrid", palette="tab10", rc = {'figure.figsize':(9,6)})
import matplotlib.pyplot as plt
import matplotlib.ticker as mticker
from matplotlib import rc, rcParams
import numpy as np
import pandas as pd
import itertools
display(df, summary=True)
Použijte Data Wrangler pro počáteční čištění dat.
Pokud chcete prozkoumat a transformovat datové rámce pandas v poznámkovém bloku, spusťte přímo z poznámkového bloku službu Data Wrangler.
Poznámka
Data Wrangler nelze otevřít, když je jádro zápisníku zaneprázdněné. Provedení buňky musí být dokončeno před spuštěním Data Wrangler.
- Na pásu karet poznámkového bloku kartě Data vyberte Spustit Data Wrangler. Zobrazí se seznam aktivovaných datových rámců pandas, které jsou k dispozici pro úpravy.
- Vyberte datový rámec, který chcete otevřít v objektu Data Wrangler. Vzhledem k tomu, že tento sešit obsahuje pouze jeden datový rámec
df, vybertedf.
Data Wrangler se spustí a vygeneruje popisný přehled vašich dat. Tabulka uprostřed zobrazuje každý sloupec dat. Panel Souhrn vedle tabulky zobrazuje informace o datovém rámci. Když vyberete sloupec v tabulce, souhrn se aktualizuje informacemi o vybraném sloupci. V některých případech budou zobrazená a souhrnná data zkráceným pohledem na váš datový rámec. V takovém případě se v podokně souhrnu zobrazí obrázek upozornění. Najeďte myší na toto upozornění a zobrazte text vysvětlující situaci.

Každou operaci, kterou uděláte, můžete použít na kliknutí, aktualizovat zobrazení dat v reálném čase a vygenerovat kód, který můžete uložit zpět do poznámkového bloku jako opakovaně použitelnou funkci.
Zbývající část této části vás provede postupem čištění dat pomocí služby Data Wrangler.
Odstranit duplicitní řádky
Na levém panelu je seznam operací, které můžete s datovou sadou provádět (například Najít a nahradit, Formát, Vzorce, Číselné).
Rozbalte Najít a nahradit a vyberte Zahodit duplicitní řádky.
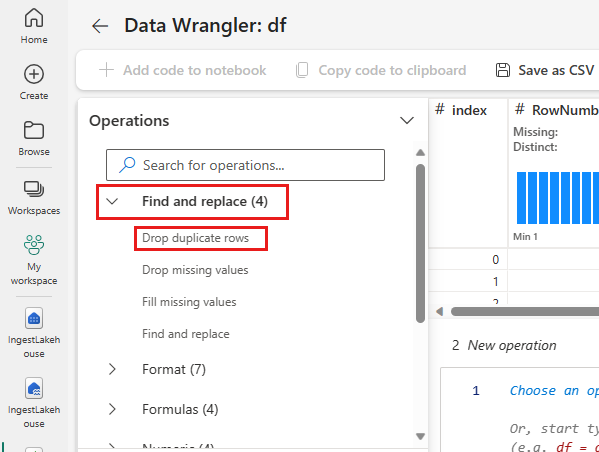
Zobrazí se panel pro výběr seznamu sloupců, které chcete porovnat, aby se definoval duplicitní řádek. Vyberte RowNumber a CustomerId.
Na prostředním panelu je náhled výsledků této operace. Ve verzi Preview je kód k provedení operace. V tomto případě se data jeví jako nezměněná. Ale vzhledem k tomu, že se díváte na zkrácené zobrazení, je vhodné operaci přesto použít.
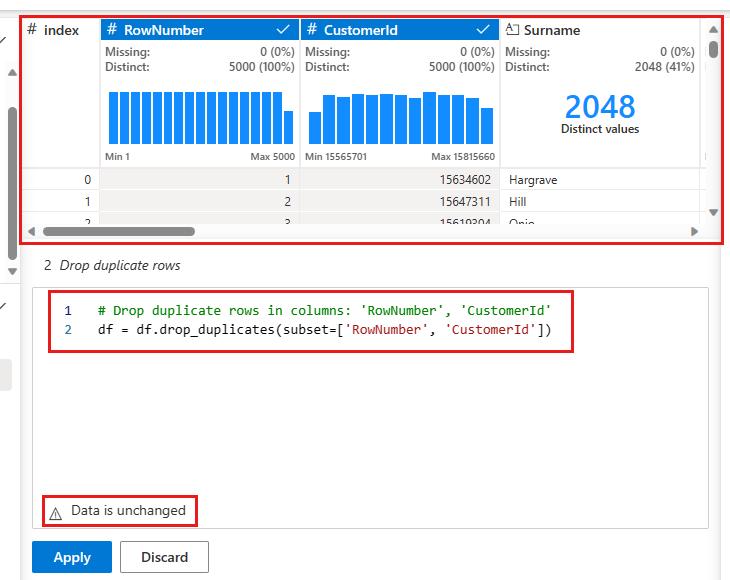
Vyberte Použít (na straně nebo ve spodní části) pro přechod k dalšímu kroku.

Odstranění řádků s chybějícími daty
Pomocí služby Data Wrangler můžete vypustit řádky s chybějícími daty napříč všemi sloupci.
Vyberte Vypustit chybějící hodnoty z Najít a nahradit.
Vyberte Vybrat všechny z cílových sloupců.
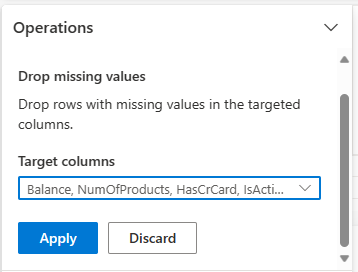
Vyberte Použít a přejděte k dalšímu kroku.

Odstranit sloupce
Pomocí služby Data Wrangler zahoďte sloupce, které nepotřebujete.
Rozbalte schéma a vyberte odebrání sloupců.
Vyberte RowNumber , CustomerId, Příjmení. Tyto sloupce se v náhledu zobrazují červeně, aby se ukázalo, že byly změněny kódem (v tomto případě, odstraněny.)
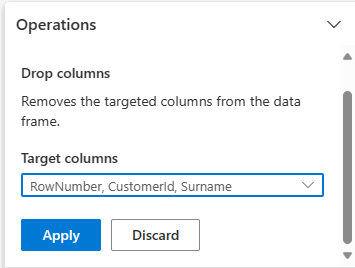
Vyberte Použít pro pokračování na další krok.

Přidání kódu do poznámkového bloku
Pokaždé, když vyberete Použít, se vlevo dole v panelu Kroky čištění vytvoří nový krok. V dolní části panelu vyberte Kód náhledu pro všechny kroky, abyste zobrazili kombinaci všech samostatných kroků.
Vyberte Přidat kód do poznámkového bloku vlevo nahoře, abyste zavřeli aplikaci Data Wrangler a kód automaticky přidali. Přidat kód do poznámkového bloku kód zabalí do funkce a pak funkci zavolá.
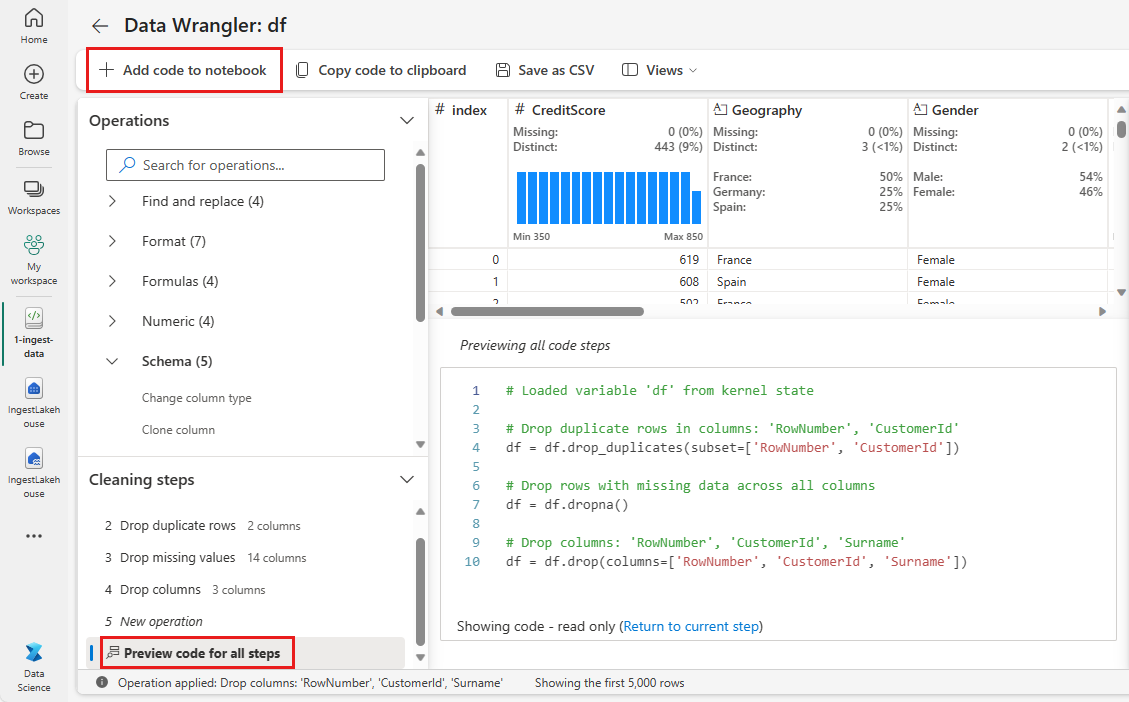
Spropitné
Kód vygenerovaný službou Data Wrangler se nepoužije, dokud ručně nespustíte novou buňku.
Pokud jste nepoužíli službu Data Wrangler, můžete místo toho použít tuto další buňku kódu.
Tento kód se podobá kódu vytvořenému rozhraním Data Wrangler, ale přidá do argumentu inplace=True ke každému vygenerovanému postupu. Když nastavíte inplace=True, pandas přepíše původní datový rámec místo vytvoření nového datového rámce jako výstupu.
# Modified version of code generated by Data Wrangler
# Modification is to add in-place=True to each step
# Define a new function that include all above Data Wrangler operations
def clean_data(df):
# Drop rows with missing data across all columns
df.dropna(inplace=True)
# Drop duplicate rows in columns: 'RowNumber', 'CustomerId'
df.drop_duplicates(subset=['RowNumber', 'CustomerId'], inplace=True)
# Drop columns: 'RowNumber', 'CustomerId', 'Surname'
df.drop(columns=['RowNumber', 'CustomerId', 'Surname'], inplace=True)
return df
df_clean = clean_data(df.copy())
df_clean.head()
Prozkoumání dat
Zobrazí některé souhrny a vizualizace vyčištěných dat.
Určení kategorických, číselných a cílových atributů
Tento kód slouží k určení kategorických, číselných a cílových atributů.
# Determine the dependent (target) attribute
dependent_variable_name = "Exited"
print(dependent_variable_name)
# Determine the categorical attributes
categorical_variables = [col for col in df_clean.columns if col in "O"
or df_clean[col].nunique() <=5
and col not in "Exited"]
print(categorical_variables)
# Determine the numerical attributes
numeric_variables = [col for col in df_clean.columns if df_clean[col].dtype != "object"
and df_clean[col].nunique() >5]
print(numeric_variables)
Statistický souhrn pěti čísel
Zobrazte souhrn s pěti čísly (minimální skóre, první kvartil, medián, třetí kvartil, maximální skóre) pro číselné atributy pomocí krabicových grafů.
df_num_cols = df_clean[numeric_variables]
sns.set(font_scale = 0.7)
fig, axes = plt.subplots(nrows = 2, ncols = 3, gridspec_kw = dict(hspace=0.3), figsize = (17,8))
fig.tight_layout()
for ax,col in zip(axes.flatten(), df_num_cols.columns):
sns.boxplot(x = df_num_cols[col], color='green', ax = ax)
fig.delaxes(axes[1,2])
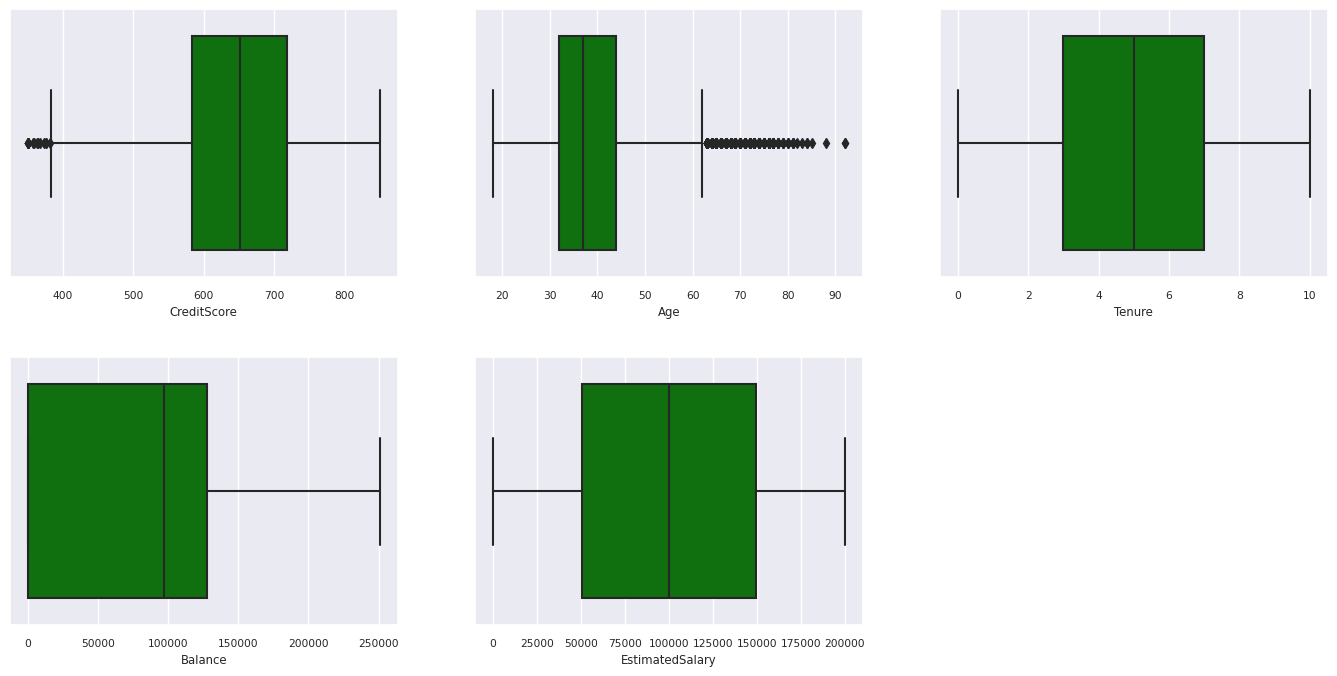
Distribuce ukončených a neexitovaných zákazníků
Umožňuje zobrazit distribuci ukončených a neexitovaných zákazníků napříč atributy kategorií.
attr_list = ['Geography', 'Gender', 'HasCrCard', 'IsActiveMember', 'NumOfProducts', 'Tenure']
fig, axarr = plt.subplots(2, 3, figsize=(15, 4))
for ind, item in enumerate (attr_list):
sns.countplot(x = item, hue = 'Exited', data = df_clean, ax = axarr[ind%2][ind//2])
fig.subplots_adjust(hspace=0.7)

Rozdělení číselných atributů
Pomocí histogramu můžete zobrazit rozdělení četnosti číselných atributů.
columns = df_num_cols.columns[: len(df_num_cols.columns)]
fig = plt.figure()
fig.set_size_inches(18, 8)
length = len(columns)
for i,j in itertools.zip_longest(columns, range(length)):
plt.subplot((length // 2), 3, j+1)
plt.subplots_adjust(wspace = 0.2, hspace = 0.5)
df_num_cols[i].hist(bins = 20, edgecolor = 'black')
plt.title(i)
plt.show()

Provádění přípravy funkcí
Vytváření funkcí za účelem generování nových atributů na základě aktuálních atributů:
df_clean["NewTenure"] = df_clean["Tenure"]/df_clean["Age"]
df_clean["NewCreditsScore"] = pd.qcut(df_clean['CreditScore'], 6, labels = [1, 2, 3, 4, 5, 6])
df_clean["NewAgeScore"] = pd.qcut(df_clean['Age'], 8, labels = [1, 2, 3, 4, 5, 6, 7, 8])
df_clean["NewBalanceScore"] = pd.qcut(df_clean['Balance'].rank(method="first"), 5, labels = [1, 2, 3, 4, 5])
df_clean["NewEstSalaryScore"] = pd.qcut(df_clean['EstimatedSalary'], 10, labels = [1, 2, 3, 4, 5, 6, 7, 8, 9, 10])
Použijte Data Wrangler k provedení jednorozměrného kódování.
Data Wrangler lze také použít k provedení jednohotového kódování. Uděláte to tak, že znovu otevřete Data Wrangler. Tentokrát vyberte údaje df_clean.
- Rozbalte Vzorce a vyberte jednohotové kódování.
- Zobrazí se panel, ve kterém si můžete vybrat sloupce, které chcete zakódovat metodou one-hot. Vyberte Zeměpis a pohlaví.
Vygenerovaný kód můžete zkopírovat, zavřít data Wrangler a vrátit se do poznámkového bloku a pak vložit do nové buňky. Nebo vyberte Přidat kód do poznámkového bloku v levém horním rohu a zavřete aplikaci Data Wrangler a přidejte kód automaticky.
Pokud jste službu Data Wrangler nepoužíli, můžete místo toho použít tuto další buňku kódu:
# This is the same code that Data Wrangler will generate
import pandas as pd
def clean_data(df_clean):
# One-hot encode columns: 'Geography', 'Gender'
df_clean = pd.get_dummies(df_clean, columns=['Geography', 'Gender'])
return df_clean
df_clean_1 = clean_data(df_clean.copy())
df_clean_1.head()
Shrnutí pozorování z průzkumné analýzy dat
- Většina zákazníků je z Francie porovnání se Španělskem a Německem, zatímco Španělsko má nejnižší četnost změn oproti Francii a Německu.
- Většina zákazníků má platební karty.
- Existují zákazníci, jejichž skóre věku a kreditu je vyšší než 60 a nižší než 400, ale nedají se považovat za odlehlé hodnoty.
- Velmi málo zákazníků má více než dva produkty banky.
- Zákazníci, kteří nejsou aktivní, mají vyšší míru odchodů.
- Gender a délka zaměstnání se zdají nemít vliv na rozhodnutí zákazníka uzavřít bankovní účet.
Vytvoření tabulky delta pro vyčištěná data
Tato data použijete v dalším poznámkovém bloku této řady.
table_name = "df_clean"
# Create Spark DataFrame from pandas
sparkDF=spark.createDataFrame(df_clean_1)
sparkDF.write.mode("overwrite").format("delta").save(f"Tables/{table_name}")
print(f"Spark dataframe saved to delta table: {table_name}")
Další krok
Trénování a registrace modelů strojového učení s využitím těchto dat: