Uživatelem definované agregace
Agregace v Power BI můžou zlepšit výkon dotazů u velkých sémantických modelů DirectQuery. Pomocí agregací ukládáte data do mezipaměti na agregované úrovni v paměti. Agregace v Power BI je možné ručně nakonfigurovat v datovém modelu, jak je popsáno v tomto článku. U předplatných Premium automaticky povolte funkci Automatické agregace v modelu Nastavení.
Vytváření agregačních tabulek
V závislosti na typu zdroje dat lze tabulku agregací vytvořit ve zdroji dat jako tabulku nebo zobrazení nativní dotaz. Pro nejvyšší výkon vytvořte tabulku agregací jako tabulku importu vytvořenou v Power Query. Potom použijete dialogové okno Spravovat agregace v Power BI Desktopu k definování agregací pro sloupce agregace se souhrnem, tabulkou podrobností a vlastnostmi sloupce podrobností.
Dimenzionální zdroje dat, jako jsou datové sklady a datová tržiště, můžou používat agregace založené na relacích. Zdroje velkých objemů dat založené na Hadoopu často zakládají agregace na sloupcích GroupBy. Tento článek popisuje typické rozdíly modelování dat Power BI pro každý typ zdroje dat.
Správa agregací
V podokně Data libovolného zobrazení Power BI Desktopu klikněte pravým tlačítkem myši na tabulku agregací a pak vyberte Spravovat agregace.
Dialogové okno Spravovat agregace zobrazuje řádek pro každý sloupec v tabulce, kde můžete zadat chování agregace. V následujícím příkladu jsou dotazy na tabulku podrobností o prodeji interně přesměrovány na tabulku agregace Agregace Sales Agg .
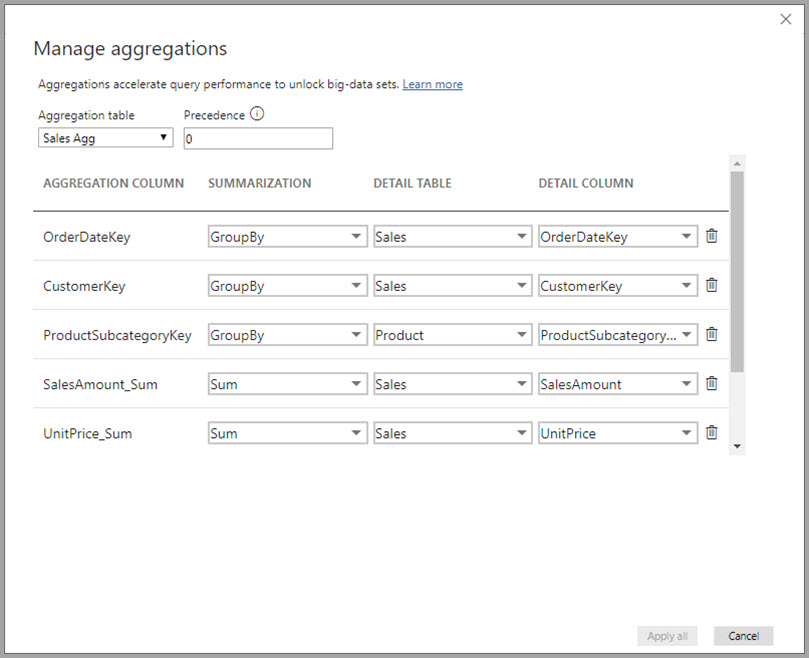
V tomto příkladu agregace založené na relacích jsou položky GroupBy volitelné. S výjimkou funkce DISTINCTCOUNT nemají vliv na chování agregace a primárně se jedná o čitelnost. Bez položek GroupBy by se agregace stále dostaly na základě relací. Toto se liší od příkladu velkých objemů dat dále v tomto článku, kde jsou požadovány položky GroupBy.
Ověření
Dialogové okno Spravovat agregace vynucuje ověření:
- Sloupec podrobností musí mít stejný datový typ jako sloupec agregace s výjimkou funkcí Souhrn řádků tabulky Počet a Počet. Řádky tabulky Count a Count jsou k dispozici pouze pro celočíselné sloupce agregace a nevyžadují odpovídající datový typ.
- Zřetězených agregací zahrnujících tři nebo více tabulek není povoleno. Například agregace v tabulce A nemůžou odkazovat na tabulku B , která obsahuje agregace odkazující na tabulku C.
- Duplicitní agregace, kde dvě položky používají stejnou funkci Souhrn a odkazují na stejnou tabulku podrobností a sloupec podrobností, nejsou povoleny.
- Tabulka podrobností musí používat režim úložiště DirectQuery, nikoli import.
- Seskupení podle sloupce cizího klíče používaného neaktivní relací a spoléhání se na funkci USERELATIONSHIP pro agregační přístupy se nepodporuje.
- Agregace založené na sloupcích GroupBy můžou používat relace mezi tabulkami agregace, ale vytváření relací mezi tabulkami agregace není v Power BI Desktopu podporované. V případě potřeby můžete vytvořit relace mezi tabulkami agregace pomocí nástroje třetí strany nebo skriptovacího řešení prostřednictvím koncových bodů XML for Analysis (XMLA).
Většina ověření se vynucuje zakázáním hodnot rozevíracího seznamu a zobrazením vysvětlujícího textu v popisu.
Tabulky agregace jsou skryté.
Uživatelé s přístupem jen pro čtení k modelu nemůžou dotazovat tabulky agregace. Přístup jen pro čtení zabraňuje obavám zabezpečení při použití se zabezpečením na úrovni řádků (RLS). Uživatelé a dotazy odkazují na tabulku podrobností, ne na tabulku agregace a nemusí o tabulce agregace vědět.
Z tohoto důvodu jsou tabulky agregace v zobrazení sestavy skryté. Pokud tabulka ještě není skrytá, dialogové okno Spravovat agregace ji nastaví na skryté, když vyberete Použít vše.
Režimy úložiště
Funkce agregace komunikuje s režimy úložiště na úrovni tabulky. Tabulky Power BI můžou používat režimy úložiště DirectQuery, Import nebo Duální . DirectQuery dotazuje back-end přímo, zatímco Import ukládá data do mezipaměti v paměti a odesílá dotazy do dat uložených v mezipaměti. Všechny zdroje dat DirectQuery importu a nedimenzionálních dat Power BI můžou pracovat s agregacemi.
Pokud chcete nastavit režim úložiště agregované tabulky na Import, aby se urychlily dotazy, vyberte agregovanou tabulku v zobrazení modelu Power BI Desktopu. V podokně Vlastnosti rozbalte položku Upřesnit, rozbalte výběr v režimu úložiště a vyberte Importovat. Změna importu je nevratná.
Další informace o režimech úložiště tabulek najdete v tématu Správa režimu úložiště v Power BI Desktopu.
Zabezpečení na úrovni řádků pro agregace
Aby výrazy RLS fungovaly správně pro agregace, měly by filtrovat tabulku agregace a tabulku podrobností.
V následujícím příkladu funguje výraz RLS v tabulce Geography pro agregace, protože Geography je na straně filtrování relací s tabulkou Sales a Sales Agg table. Dotazy, které narazily na tabulku agregace a dotazy, které nemají zabezpečení na úrovni řádků ( RLS) se úspěšně použily.
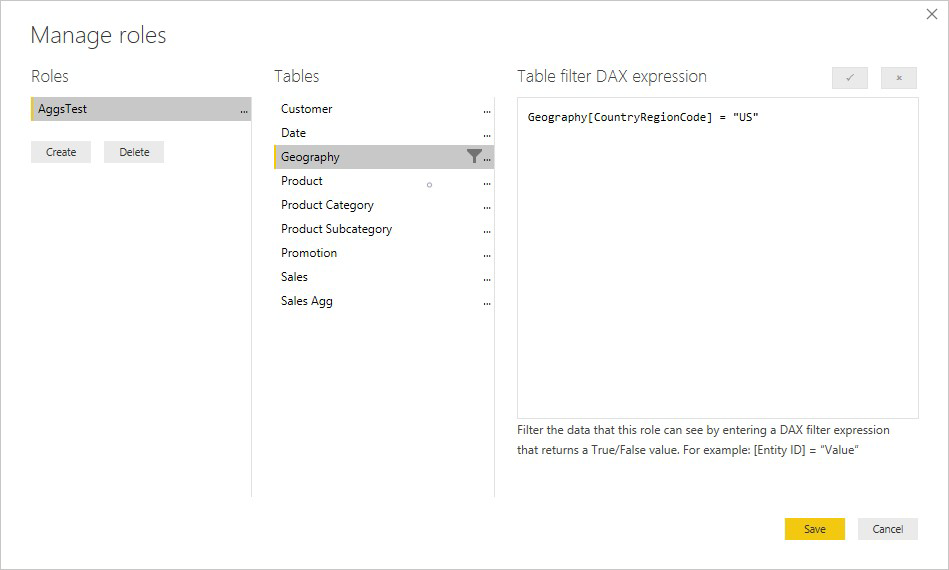
Výraz RLS v tabulce Product filtruje pouze tabulku podrobností Prodej, nikoli agregovanou tabulku Agregace prodeje. Vzhledem k tomu, že tabulka agregace je další reprezentací dat v tabulce podrobností, bylo by nezabezpečené odpovídat na dotazy z tabulky agregace, pokud se filtr RLS nedá použít. Filtrování pouze tabulky podrobností se nedoporučuje, protože dotazy uživatelů z této role nemají prospěch z agregačních přístupů.
Výraz RLS, který filtruje pouze tabulku agregace Agregace Sales(Agregace prodeje), nikoli tabulku podrobností o prodeji není povolená.
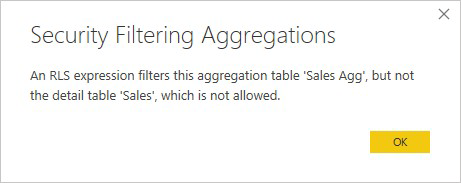
U agregací založených na sloupcích GroupBy je možné použít výraz RLS použitý u tabulky podrobností k filtrování tabulky agregace, protože všechny sloupce GroupBy v tabulce agregace jsou pokryty tabulkou podrobností. Na druhou stranu filtr RLS v tabulce agregace nejde použít u tabulky podrobností, takže je nepovolen.
Agregace založená na relacích
Dimenzionální modely obvykle používají agregace založené na relacích. Modely Power BI z datových skladů a datových mart se podobají schématům hvězdy a sněhové vločky s relacemi mezi tabulkami dimenzí a tabulkami faktů.
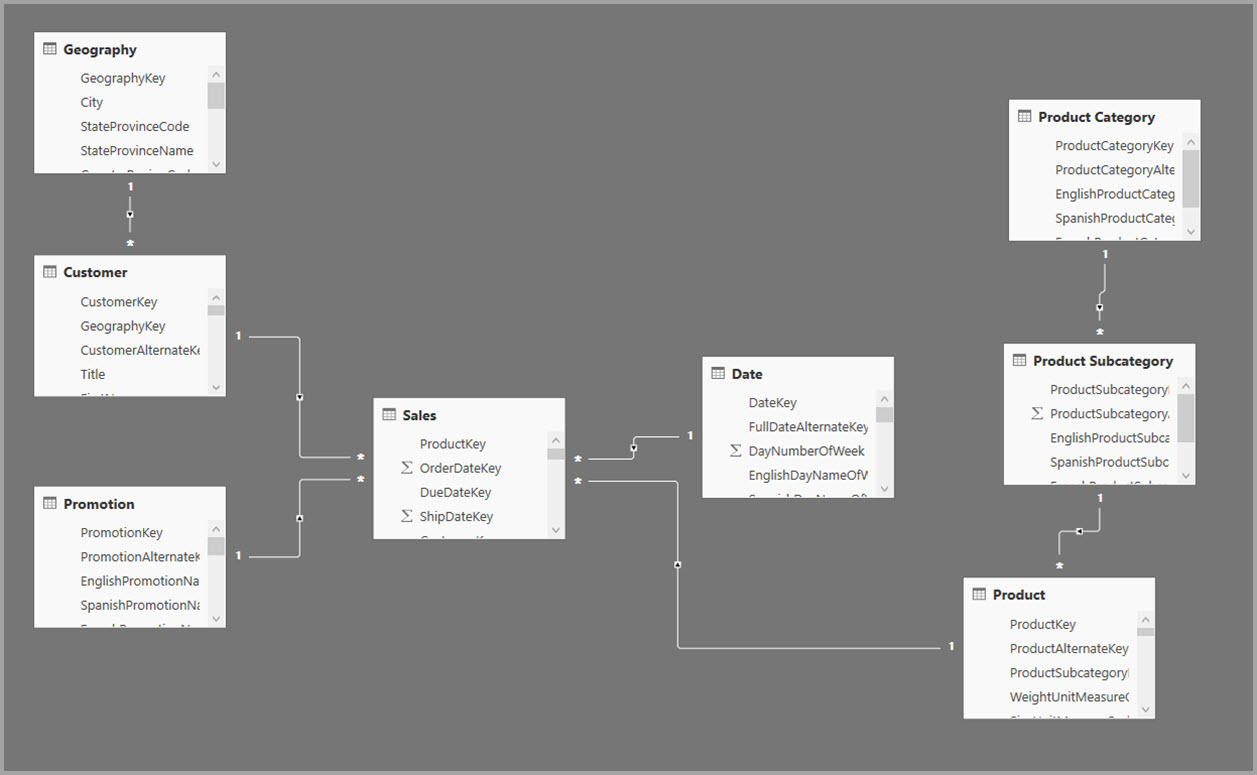
V následujícím příkladu model získává data z jednoho zdroje dat. Tabulky používají režim úložiště DirectQuery. Tabulka faktů Prodej obsahuje miliardy řádků. Nastavení režimu úložiště sales na import pro ukládání do mezipaměti by spotřebovalo značné režijní náklady na paměť a prostředky.
Místo toho vytvořte tabulku agregace Agregace Sales Agg . V tabulce Sales Agg se počet řádků rovná součtu salesAmount seskupených podle CustomerKey, DateKey a ProductSubcategoryKey. Tabulka Sales Agg (Agregace prodeje) má vyšší členitost než Sales(Prodej), takže místo miliard může obsahovat miliony řádků, které se dají snadněji spravovat.
Pokud se pro dotazy s vysokou obchodní hodnotou používají následující tabulky dimenzí, můžou filtrovat agregace prodeje pomocí relací 1:N nebo N:1 .
- Zeměpisná oblast
- Zákazník
- Datum
- Product Subcategory
- Kategorie produktu
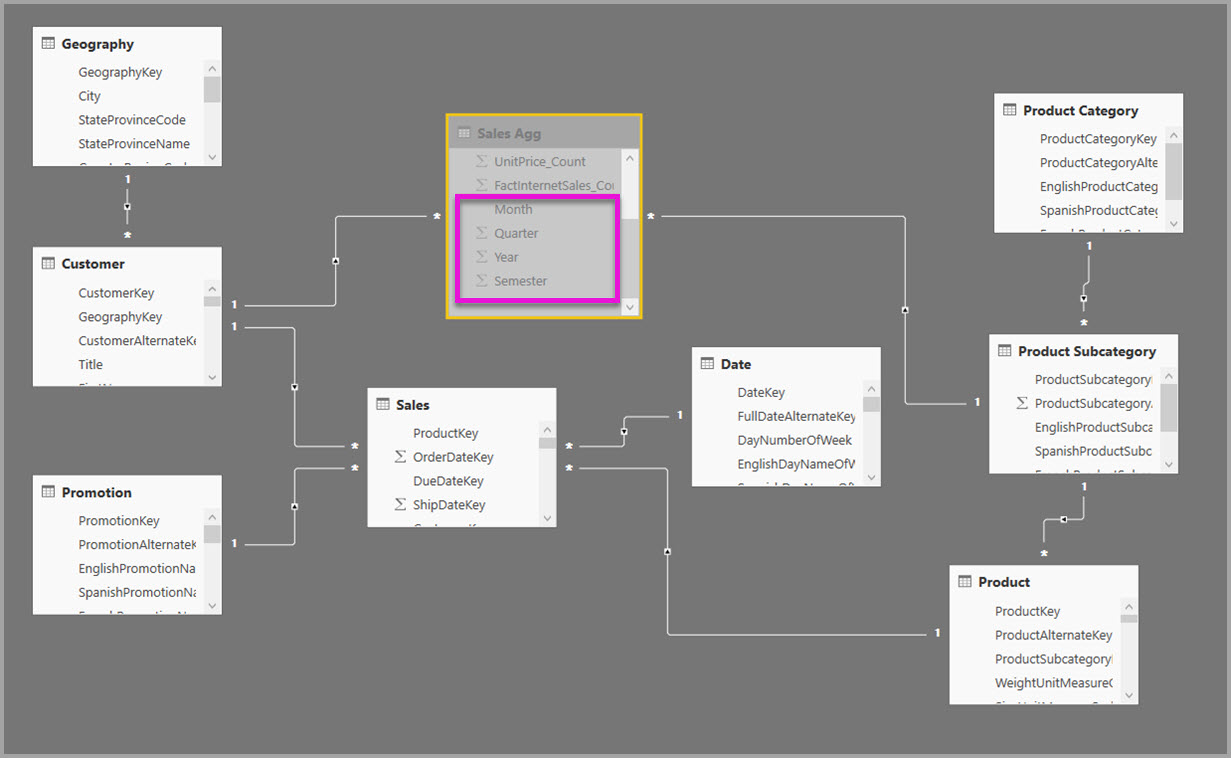
Následující obrázek znázorňuje tento model.
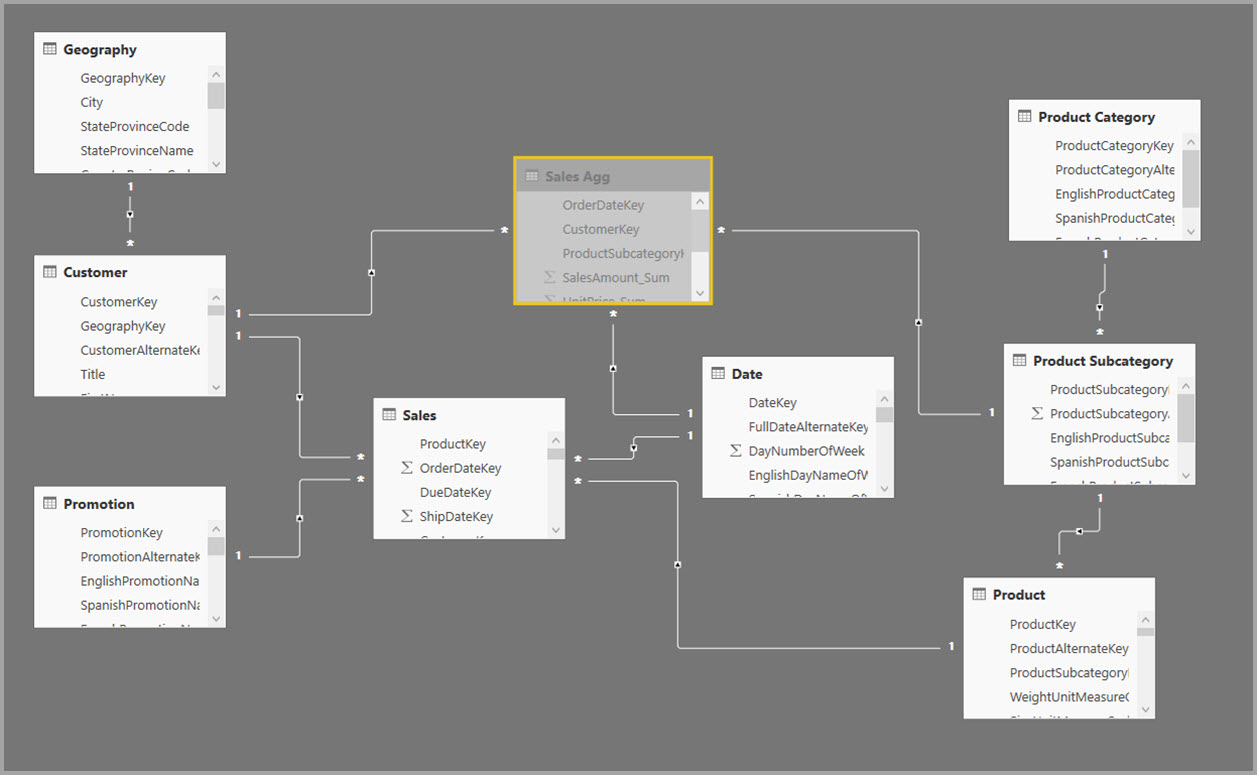
Následující tabulka ukazuje agregace pro tabulku Sales Agg (Agregace prodeje).
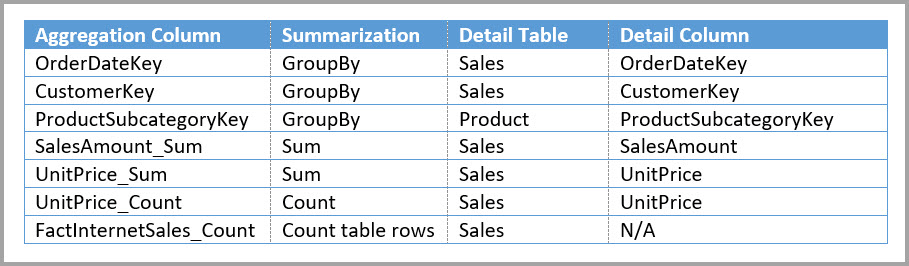
Poznámka:
Tabulka Sales Agg (podobně jako každá tabulka) má flexibilitu načítání různými způsoby. Agregaci lze provést ve zdrojové databázi pomocí procesů ETL/ELT nebo výrazem M pro tabulku. Agregovaná tabulka může pro sémantické modely použít režim úložiště Import nebo bez ní nebo bez ní, nebo může používat DirectQuery a optimalizovat pro rychlé dotazy pomocí indexů columnstore. Tato flexibilita umožňuje vyvážené architektury, které můžou rozložit zatížení dotazů, aby nedocházelo k kritickým bodům.
Změna režimu úložiště agregované tabulky Sales Agg (Agregace prodeje) na Import otevře dialogové okno s informací, že související tabulky dimenzí lze nastavit na režim úložiště Duální.
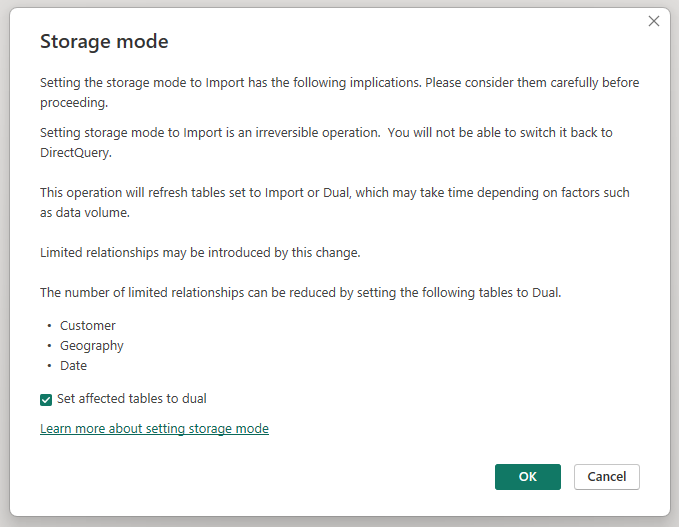
Nastavení souvisejících tabulek dimenzí na duální umožňuje v závislosti na poddotazu fungovat jako Import nebo DirectQuery. V tomto příkladu:
- Dotazy, které agregují metriky z tabulky Sales Agg (Agregace prodeje v režimu importu) a seskupují podle atributů ze souvisejících duálních tabulek, mohou být vráceny z mezipaměti v paměti.
- Dotazy, které agregují metriky z tabulky DirectQuery Sales a seskupují podle atributů ze souvisejících duálních tabulek, se dají vrátit v režimu DirectQuery. Logika dotazu, včetně operace GroupBy, se předává do zdrojové databáze.
Další informace o režimu duálního úložiště najdete v tématu Správa režimu úložiště v Power BI Desktopu.
Normální vs. omezené relace
Přístupy agregace založené na relacích vyžadují pravidelné relace.
Mezi běžné relace patří následující kombinace režimu úložiště, kde obě tabulky pocházejí z jednoho zdroje:
| Tabulka na mnoha stranách | Tabulka na straně 1 |
|---|---|
| Duální | Duální |
| Import | Import nebo duální |
| DirectQuery | DirectQuery nebo Duální |
Jediným případem , kdy je relace mezi zdroji považována za běžnou, je, pokud jsou obě tabulky nastaveny na Import. Relace M:N se vždy považují za omezené.
U přístupů k agregaci mezi zdroji , které nezávisí na relacích, najdete v tématu Agregace založené na sloupcích GroupBy.
Příklady agregačních dotazů založených na relacích
Následující dotaz agregaci dosáhne, protože sloupce v tabulce Date jsou v členitosti, které můžou agregaci dosáhnout. Sloupec SalesAmount používá agregaci Součet .

Následující dotaz nenarazí na agregaci. Přestože požadujete součet salesAmount, dotaz provádí operaci GroupBy ve sloupci v tabulce Product , která není v členitosti, která může agregaci dosáhnout. Pokud se podíváte na relace v modelu, může podkategorie produktu obsahovat více řádků produktu . Dotaz by nemohl určit, na který produkt se má agregovat. V tomto případě se dotaz vrátí k DirectQuery a odešle dotaz SQL do zdroje dat.

Agregace nejsou jen pro jednoduché výpočty, které provádějí jednoduchý součet. Komplexní výpočty můžou být také přínosné. Komplexní výpočet je koncepčně rozdělený do poddotazů pro každý součet, MINIMUM, MAX a COUNT. Každý poddotaz se vyhodnocuje, aby se zjistilo, jestli může agregaci použít. Tato logika nemá hodnotu true ve všech případech kvůli optimalizaci plánu dotazů, ale obecně by se měla použít. Následující příklad použije agregaci:

Funkce COUNTROWS může těžit z agregací. Následující dotaz agregaci dosáhne, protože pro tabulku Sales je definovaná agregace řádků tabulky Počet.

Funkce PRŮMĚR může těžit z agregací. Následující dotaz agregaci dosáhne, protože funkce PRŮMĚR se interně přeloží na sumu dělenou funkcí COUNT. Vzhledem k tomu, že sloupec UnitPrice má agregace definované pro sumu i POČET, agregace se dosáhne.

V některých případech může funkce DISTINCTCOUNT těžit z agregací. Následující dotaz agregaci dosáhne, protože pro Klíč zákazníka existuje položka GroupBy, která udržuje jedinečnost CustomerKey v tabulce agregace. Tato technika může přesto dosáhnout prahové hodnoty výkonu, kdy výkon dotazů může ovlivnit více než dva až pět milionů jedinečných hodnot. Může to ale být užitečné ve scénářích, ve kterých jsou v tabulce podrobností miliardy řádků, ale dva až pět milionů jedinečných hodnot ve sloupci. V tomto případě může funkce DISTINCTCOUNT provádět rychleji než prohledávání tabulky s miliardami řádků, i když byly uloženy do mezipaměti do paměti.

Funkce časového měřítka DAX (Data Analysis Expressions) jsou agregační. Následující dotaz agregaci dosáhne, protože funkce DATESYTD vygeneruje tabulku hodnot CalendarDay a tabulka agregace má členitost, která se vztahuje na sloupce seskupování podle v tabulce Date . Toto je příklad filtru s hodnotou tabulky na funkci CALCULATE, která může pracovat s agregacemi.

Agregace založená na sloupcích GroupBy
Modely velkých objemů dat založené na Hadoopu mají jiné charakteristiky než dimenzionální modely. Aby se zabránilo spojení mezi velkými tabulkami, modely velkých objemů dat často nepoužívají relace, ale denormalizují atributy dimenzí tabulkám faktů. Takové modely velkých objemů dat můžete pro interaktivní analýzu odemknout pomocí agregací založených na sloupcích GroupBy.
Následující tabulka obsahuje číselný sloupec Pohybu , který se má agregovat. Všechny ostatní sloupce jsou atributy, podle kterých se mají seskupit. Tabulka obsahuje data IoT a velký počet řádků. Režim úložiště je DirectQuery. Dotazy na zdroj dat, který se agreguje v celém modelu, je pomalý kvůli celkovému objemu.
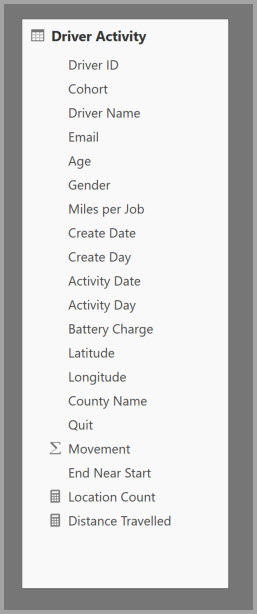
Pokud chcete u tohoto modelu povolit interaktivní analýzu, můžete přidat tabulku agregace, která seskupuje podle většiny atributů, ale vylučuje atributy s vysokou kardinalitou, jako je zeměpisná délka a zeměpisná šířka. To výrazně snižuje počet řádků a je dostatečně malý, aby se pohodlně vešly do mezipaměti v paměti.
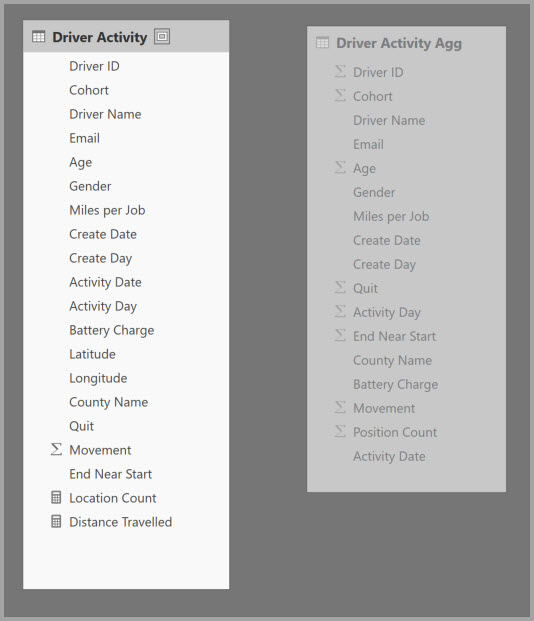
Mapování agregace pro tabulku Agregace aktivity řidiče definujete v dialogovém okně Spravovat agregace .
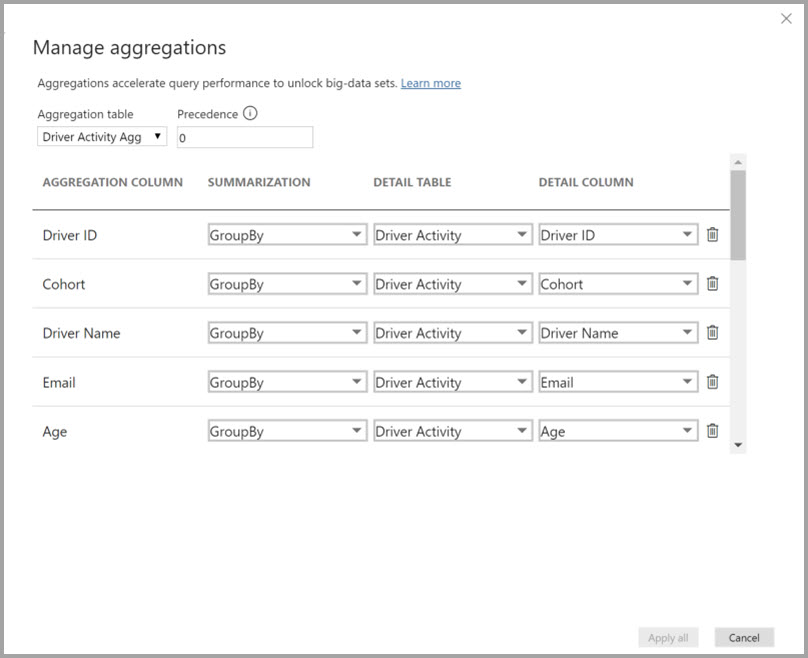
V agregacích založených na sloupcích GroupBy nejsou položky GroupBy volitelné. Bez nich se agregace nedostanou. To se liší od použití agregací založených na relacích, kde jsou položky GroupBy volitelné.
Následující tabulka ukazuje agregace pro tabulku Agregace aktivity řidiče.
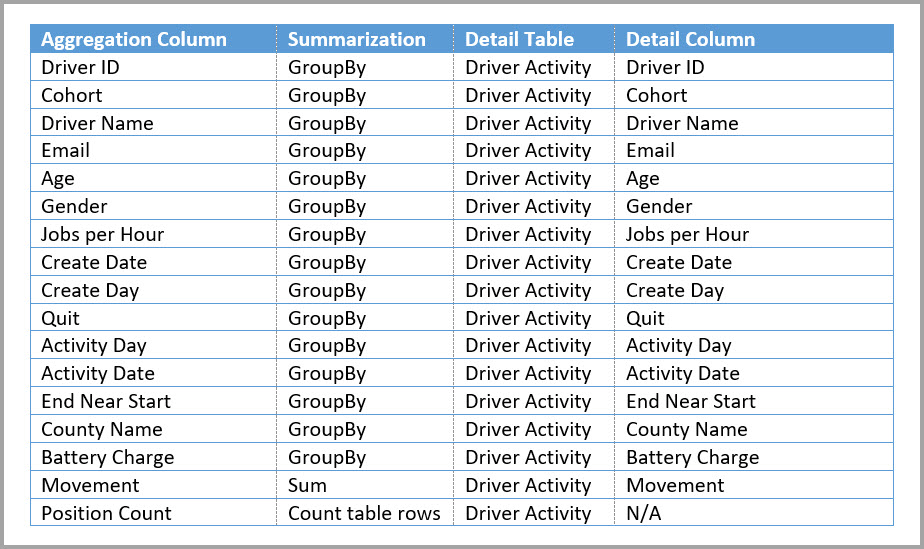
Režim úložiště agregované tabulky Driver Activity Agg (Agregovaná agregovaná agregace aktivity řidiče) můžete nastavit na Import.
Příklad agregačního dotazu GroupBy
Následující dotaz agregaci dosáhne, protože sloupec Datum aktivity je pokryt tabulkou agregace. Funkce COUNTROWS používá agregaci řádky počítané tabulky.

Zvláště u modelů, které obsahují atributy filtru v tabulkách faktů, je vhodné použít agregace spočítat řádky tabulky. Power BI může odesílat dotazy do modelu pomocí funkce COUNTROWS v případech, kdy uživatel explicitně nevyžaduje. Například dialogové okno filtru zobrazuje počet řádků pro každou hodnotu.
Kombinované techniky agregace
Můžete kombinovat techniky relací a sloupců GroupBy pro agregace. Agregace založené na relacích mohou vyžadovat rozdělení tabulek denormalizovaných dimenzí do více tabulek. Pokud je to nákladné nebo nepraktické pro určité tabulky dimenzí, můžete replikovat potřebné atributy v tabulce agregace pro tyto dimenze a používat relace pro ostatní.
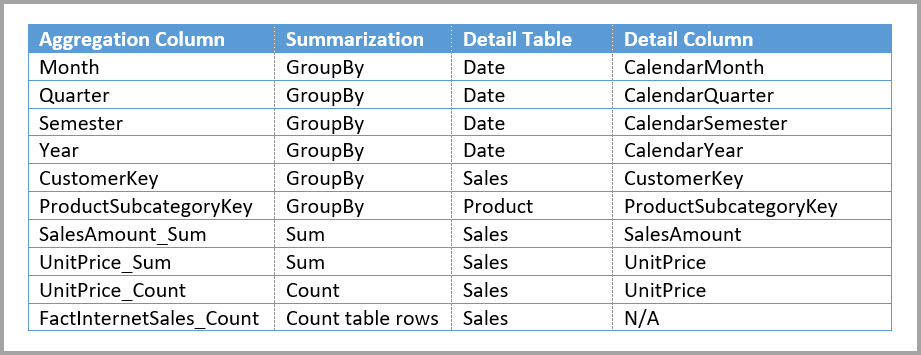
Následující model například replikuje měsíc, čtvrtletí, semestr a rok v tabulce Sales Agg (Agregace prodeje). Mezi agregacemi prodeje a tabulkou Date neexistuje žádná relace, ale existují relace s kategorií Customer (Zákazník) a Product Subcategory (Podkategorie produktu). Režim úložiště Agregace prodeje je Import.
Následující tabulka ukazuje položky nastavené v dialogovém okně Spravovat agregace pro tabulku Sales Agg . Položky GroupBy, kde Date je tabulka podrobností jsou povinné, aby byly nalezeny agregace pro dotazy, které seskupují podle atributů Date . Stejně jako v předchozím příkladu nemají položky GroupBy pro CustomerKey a ProductSubcategoryKey vliv na agregační přístupy s výjimkou DISTINCTCOUNT kvůli přítomnosti relací.
Příklady kombinovaných agregačních dotazů
Následující dotaz agregaci dosáhne, protože tabulka agregace pokrývá CalendarMonth a CategoryName je přístupná prostřednictvím relací 1:N. SalesAmount používá agregaci SUM .

Následující dotaz agregaci nenarazí, protože tabulka agregace nepokrývá calendarDay.

Následující dotaz časového měřítka nenarazí na agregaci, protože funkce DATESYTD vygeneruje tabulku hodnot CalendarDay a tabulka agregace nepokrývá CalendarDay.

Priorita agregace
Priorita agregace umožňuje, aby jednotlivé poddotazy považovaly více tabulek agregace.
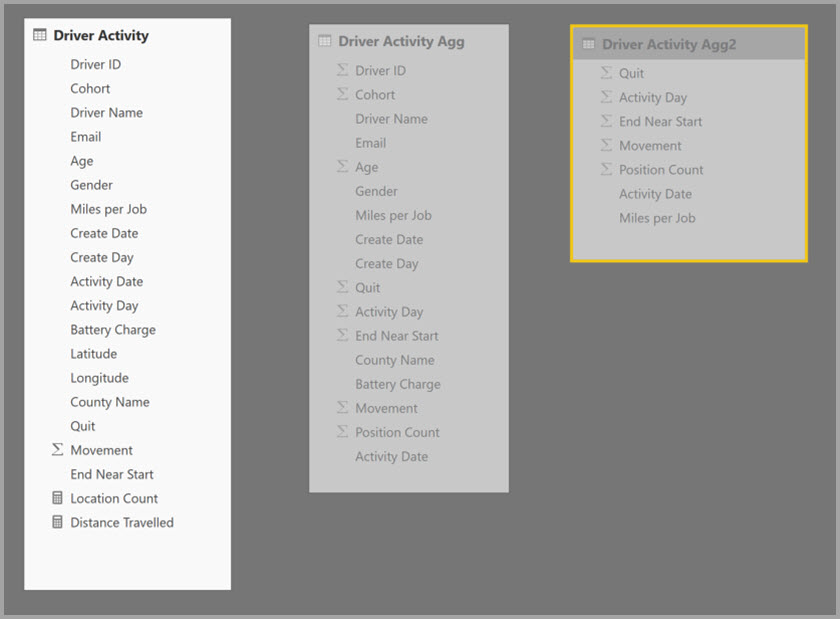
Následující příklad je složený model obsahující více zdrojů:
- Tabulka Driver Activity DirectQuery obsahuje více než bilión řádků dat IoT ze systému pro velké objemy dat. Poskytuje dotazy podrobné analýzy k zobrazení jednotlivých čtení IoT v kontrolovaných kontextech filtru.
- Tabulka Agregace aktivity řidiče je zprostředkující agregační tabulka v režimu DirectQuery. Obsahuje více než miliardu řádků ve službě Azure Synapse Analytics (dříve SQL Data Warehouse) a je optimalizovaná ve zdroji pomocí indexů columnstore.
- Tabulka Import aktivity řidiče Agg2 má vysokou členitost, protože atributy seskupování mají málo a nízkou kardinalitu. Počet řádků může být tak nízký jako tisíce, takže se snadno vejde do mezipaměti v paměti. Tyto atributy se používají řídicím panelem výkonného vedení s vysokým profilem, takže dotazy, které na ně odkazují, by měly být co nejrychleji.
Poznámka:
Agregační tabulky DirectQuery, které používají jiný zdroj dat než tabulka podrobností, se podporují jenom v případě, že je tabulka agregace ze zdroje SQL Serveru, Azure SQL nebo Azure Synapse Analytics (dříve SQL Data Warehouse).
Nároky na paměť tohoto modelu jsou relativně malé, ale odemykají obrovský model. Představuje vyváženou architekturu, protože rozšiřuje zatížení dotazů mezi komponenty architektury a využívá je na základě jejich silných stránek.
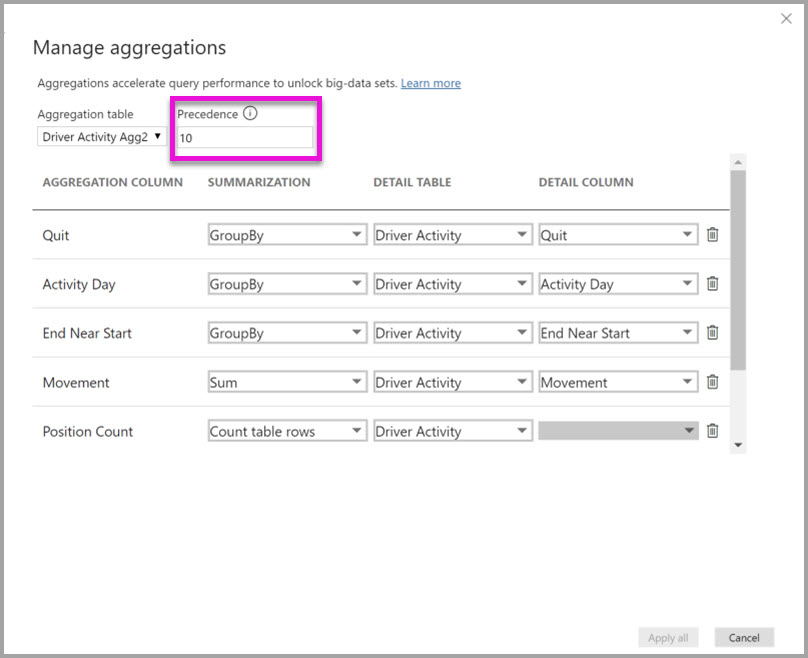
Dialogové okno Spravované agregace pro Agregaci aktivity řidiče nastaví pole Priority na 10, které je vyšší než u agregace aktivity řidiče. Nastavení vyšší priority znamená, že dotazy, které používají agregace, nejprve zvažují agregaci aktivity řidiče Agg2 . Poddotazy, které nejsou v členitosti, na které může odpovědět agregovaná aktivita řidiče Agg2 , můžou místo toho zvážit agregování aktivity řidiče. Podrobné dotazy, na které nemůže odpovědět ani tabulka agregace, můžou směrovat na aktivitu řidiče.
Tabulka zadaná ve sloupci Tabulka podrobností je Aktivita řidiče, nikoli Agregace aktivity řidiče, protože zřetězený agregace nejsou povolené.
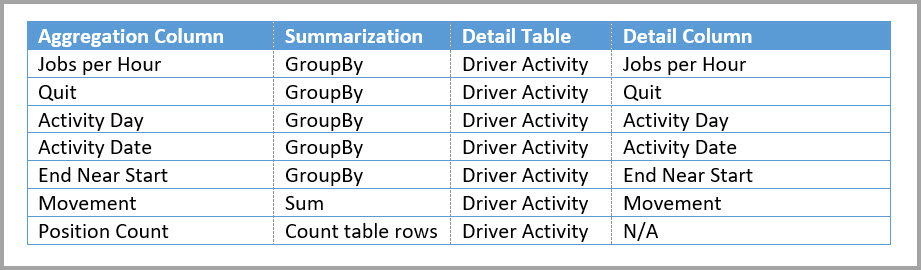
Následující tabulka ukazuje agregace pro tabulku Driver Activity Agg2 ( Agregace aktivity řidiče 2 ).
Zjištění, jestli dotazy narazily na agregace nebo neúspěšné agregace
SQL Profiler dokáže zjistit, jestli se dotazy vrací z modulu úložiště mezipaměti v paměti, nebo zda jsou vloženy do zdroje dat DirectQuery. Stejný proces můžete použít ke zjištění, jestli se agregace narazí. Další informace najdete v tématu Dotazy, které se do mezipaměti dostaly nebo zmeškaly.
SQL Profiler také poskytuje rozšířenou Query Processing\Aggregate Table Rewrite Query událost.
Následující fragment kódu JSON ukazuje příklad výstupu události při použití agregace.
- matchingResult ukazuje, že poddotaz použil agregaci.
- DataRequest zobrazuje sloupce GroupBy a agregované sloupce použité poddotaz.
- mapování zobrazuje sloupce v tabulce agregace, na které byly namapovány.

Zachování mezipamětí v synchronizaci
Agregace, které kombinují režimy úložiště DirectQuery, Import a/nebo Duální, můžou vracet různá data, pokud se mezipaměť v paměti nesynchronizuje se zdrojovými daty. Například spuštění dotazu se nepokoušá maskovat problémy s daty filtrováním výsledků DirectQuery tak, aby odpovídaly hodnotám uloženým v mezipaměti. V případě potřeby existují zavedené techniky pro řešení těchto problémů ve zdroji. Optimalizace výkonu by se měly používat jenom způsoby, které neohrožují vaši schopnost splnit obchodní požadavky. Je vaší zodpovědností znát toky dat a odpovídajícím způsobem navrhovat.
Úvahy a omezení
Agregace nepodporují dynamické parametry dotazu M.
Od srpna 2022 power BI kvůli změnám funkcí ignoruje tabulky agregace režimu importu s povolenými zdroji dat jednotného přihlašování kvůli potenciálním rizikům zabezpečení. Pokud chcete zajistit optimální výkon dotazů s agregacemi, doporučujeme pro tyto zdroje dat zakázat jednotné přihlašování.
Komunita
Power BI má živou komunitu, ve které MVP, profesionálové a kolegové sdílejí odborné znalosti v diskuzích, videích, blogech a dalších. Při získávání agregací se nezapomeňte podívat na tyto další zdroje informací: