Příklad: Sestavení a nasazení vlastní dovednosti pomocí služby Azure Machine Learning (archivováno)
Tento příklad je archivovaný a není podporován. Vysvětlili jsme, jak pomocí Azure Machine Learning vytvořit vlastní dovednost, která z recenzí extrahuje mínění založené na aspektech. To umožnilo, aby přiřazení pozitivního a negativního mínění v rámci stejné kontroly bylo správně přiřazeno identifikovaným entitům, jako jsou zaměstnanci, místnost, předsálí nebo fond.
K trénování modelu mínění založeného na aspektech ve službě Azure Machine Learning budete používat úložiště receptů nlp. Model se pak nasadí jako koncový bod v clusteru Azure Kubernetes. Po nasazení se koncový bod přidá do kanálu pro rozšiřování jako dovednost AML, kterou může používat kognitivní Search.
K dispozici jsou dvě datové sady. Pokud chcete model vytrénovat sami, vyžaduje se soubor hotel_reviews_1000.csv. Chcete raději vynechat trénovací krok? Stáhněte si hotel_reviews_100.csv.
- Vytvoření instance Azure Cognitive Search
- Vytvoření pracovního prostoru Azure Machine Learning (vyhledávací služba a pracovní prostor by měly být ve stejném předplatném)
- Trénování a nasazení modelu do clusteru Azure Kubernetes
- Propojení kanálu rozšiřování AI s nasazeným modelem
- Ingestování výstupu z nasazeného modelu jako vlastní dovednosti
Důležité
Tato dovednost je ve verzi Public Preview v rámci doplňkových podmínek použití. Tuto dovednost podporuje rozhraní REST API ve verzi Preview .
Požadavky
- Předplatné Azure – získejte bezplatné předplatné.
- Kognitivní Search
- Prostředek služeb Cognitive Services
- Účet Azure Storage)
- Pracovní prostor služby Azure Machine Learning
Nastavení
- Naklonujte nebo stáhněte obsah ukázkového úložiště.
- Extrahujte obsah, pokud je stažený soubor ZIP. Ujistěte se, že soubory jsou pro čtení i zápis.
- Při nastavování účtů a služeb Azure zkopírujte názvy a klíče do snadno přístupného textového souboru. Názvy a klíče se přidají do první buňky v poznámkovém bloku, kde jsou definované proměnné pro přístup ke službám Azure.
- Pokud službu Azure Machine Learning a její požadavky neznáte, měli byste si před zahájením práce projít tyto dokumenty:
- Konfigurace vývojového prostředí pro Azure Machine Learning
- Vytváření a správa pracovních prostorů Azure Machine Learning v Azure Portal
- Při konfiguraci vývojového prostředí pro Azure Machine Learning zvažte použití cloudové výpočetní instance , která vám usnadní a urychlí začátek.
- Nahrajte soubor datové sady do kontejneru v účtu úložiště. Větší soubor je nutný, pokud chcete v poznámkovém bloku provést trénovací krok. Pokud chcete trénovací krok přeskočit, doporučujeme menší soubor.
Otevření poznámkového bloku a připojení ke službám Azure
- Vložte všechny požadované informace o proměnných, které umožní přístup ke službám Azure, do první buňky a buňku spusťte.
- Spuštěním druhé buňky potvrdíte, že jste se připojili k vyhledávací službě pro vaše předplatné.
- Oddíly 1.1 až 1.5 vytvoří úložiště dat vyhledávací služby, sadu dovedností, index a indexer.
V tomto okamžiku můžete přeskočit postup vytvoření trénovací sady dat a experimentu ve službě Azure Machine Learning a přeskočit přímo k registraci dvou modelů, které jsou k dispozici ve složce models v úložišti GitHub. Pokud tyto kroky přeskočíte, přeskočíte v poznámkovém bloku k oddílu 3.5, Psaní hodnoticího skriptu. To ušetří čas; dokončení kroků stahování a nahrání dat může trvat až 30 minut.
Vytváření a trénování modelů
Oddíl 2 obsahuje šest buněk, které stáhnou soubor vkládání rukavic z úložiště receptů nlp. Po stažení se soubor nahraje do úložiště dat služby Azure Machine Learning. Soubor .zip je přibližně 2G a provedení těchto úloh bude nějakou dobu trvat. Po nahrání se trénovací data extrahují a teď jste připraveni přejít k oddílu 3.
Trénování modelu mínění založeného na aspektech a nasazení koncového bodu
Oddíl 3 poznámkového bloku vytrénuje modely vytvořené v části 2, zaregistruje je a nasadí jako koncový bod v clusteru Azure Kubernetes. Pokud azure Kubernetes neznáte, důrazně doporučujeme, abyste si před vytvořením clusteru pro odvozování prostudovali následující články:
- Přehled služby Azure Kubernetes Service
- Základní koncepty Kubernetes pro Azure Kubernetes Service (AKS)
- Kvóty, omezení velikosti virtuálních počítačů a dostupnost oblastí v Azure Kubernetes Service (AKS)
Vytvoření a nasazení clusteru pro odvozování může trvat až 30 minut. Doporučujeme webovou službu otestovat před přechodem k posledním krokům, aktualizací sady dovedností a spuštěním indexeru.
Aktualizace sady dovedností
Oddíl 4 v poznámkovém bloku obsahuje čtyři buňky, které aktualizují sadu dovedností a indexer. Alternativně můžete použít portál k výběru a použití nové dovednosti v sadě dovedností a pak spuštěním indexeru aktualizovat vyhledávací službu.
Na portálu přejděte do části Sada dovedností a vyberte odkaz Definice sady dovedností (JSON). Na portálu se zobrazí json vaší sady dovedností, který byl vytvořen v prvních buňkách poznámkového bloku. Napravo od displeje je rozevírací nabídka, kde můžete vybrat šablonu definice dovednosti. Vyberte šablonu Azure Machine Learning (AML). zadejte název pracovního prostoru Azure ML a koncový bod pro model nasazený do clusteru pro odvozování. Šablona se aktualizuje identifikátorem URI a klíčem koncového bodu.
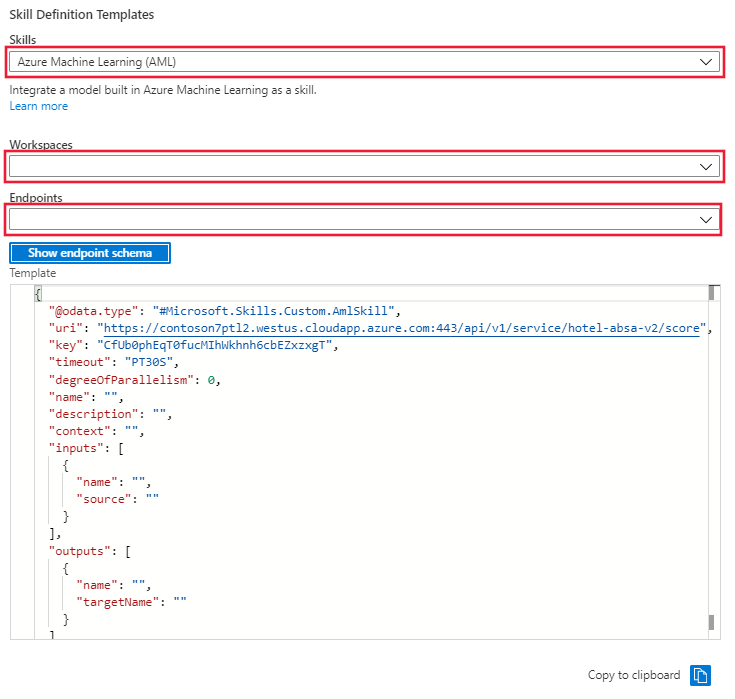
Zkopírujte šablonu sady dovedností z okna a vložte ji do definice sady dovedností na levé straně. Upravte šablonu tak, aby poskytovala chybějící hodnoty pro:
- Název
- Description
- Kontext
- Název a zdroj vstupů
- Outputs name a targetName
Uložte sadu dovedností.
Po uložení sady dovedností přejděte do indexeru a vyberte odkaz Definice indexeru (JSON). Portál zobrazí json indexeru, který byl vytvořen v prvních buňkách poznámkového bloku. Mapování výstupních polí bude potřeba aktualizovat pomocí dalších mapování polí, aby bylo zajištěno, že je indexer dokáže správně zpracovat a předat. Uložte změny a pak vyberte Spustit.
Vyčištění prostředků
Pokud pracujete s vlastním předplatným, je vhodné vždy na konci projektu zkontrolovat, jestli budete vytvořené prostředky ještě potřebovat. Prostředky, které necháte běžet, vás stojí peníze. Můžete odstraňovat prostředky jednotlivě nebo odstraněním skupiny prostředků odstranit celou sadu prostředků najednou.
Prostředky můžete najít a spravovat na portálu pomocí odkazu Všechny prostředky nebo Skupiny prostředků v levém navigačním podokně.
Pokud používáte bezplatnou službu, nezapomeňte, že jste omezeni na tři indexy, indexery a zdroje dat. Jednotlivé položky na portálu můžete odstranit, abyste zůstali pod limitem.