Vytváření cloudových služeb odolných proti chybám
Velká část správy datacenter a cloudových služeb zahrnuje návrh a údržbu spolehlivé služby na základě nespolehlivých částí. Následující obrázek znázorňuje část školení pro nové zaměstnance a měl by poskytnout představu o velkém počtu (a typech) selhání, ke kterým pravidelně dochází ve velkých datacentrech.

Obrázek 2: Problémy se spolehlivostí, jak je znázorněno v školicí prezentaci
K selhání v systému dochází v důsledku chybného stavu, který je způsobený chybou. V systémech obvykle nastávají chyby následujících typů:
- Přechodné chyby: Dočasné chyby v systému, které se opravují časem.
- Trvalé chyby: Chyby, které nelze obnovit, a obecně vyžadují nahrazení prostředků.
- Přerušované chyby: Chyby, ke kterým dochází pravidelně v systému.
Chyby můžou ovlivnit dostupnost systému tím, že způsobí nedostupnost služeb nebo sníží výkon funkcí systému. Systém odolný proti chybám je takový, který zvládá plnit svou funkci i v případě selhání systému. V cloudu je za systém odolný proti chybám často považován takový systém, který poskytuje služby konzistentním způsobem a s nižšími výpadky, než povoluje smlouva o úrovni služeb (SLA).
Proč je odolnost proti chybám důležitá?
Selhání v rozsáhlých, kritických systémech může způsobit významné finanční ztráty všem zúčastněným stranám. Samotnou podstatou systémů pro cloud computing je jejich vrstvená architektura. Proto chyba v jedné vrstvě cloudových prostředků může aktivovat selhání ve vyšších vrstvách nebo zabránit přístupu k nižším vrstvám.
Například chyba v jakékoli hardwarové komponentě systému může ovlivnit normální fungování aplikace SaaS (software jako služba) běžící na virtuálním počítači s vadných prostředkem. Chyby v libovolné vrstvě systému mají přímou vazbu na smlouvu SLA mezi poskytovateli na všech úrovních.
Proaktivní opatření
Poskytovatelé služeb používají určitá opatření, jak systém navrhnout tak, aby nedošlo ke známým problémům nebo předvídatelným selháním.
Profilace a testování
Pro zajištění dostupnosti služeb je zásadní provádět zátěžové testy cloudových prostředků, které by měly odhalit možné příčiny selhání. Profilace těchto metrik pomáhá navrhnout takový systém, který úspěšně ustojí očekávané zatížení bez jakéhokoli nepředvídatelného chování.
Zřizování nadměrných prostředků
Zřizování nadměrných prostředků je postup nasazení prostředků ve svazcích, které svou velikostí přesahují celkové předpokládané využití prostředků v daném čase. V situacích, kdy se přesné potřeby systému nedají odhadnout, může být zřízení nadměrných prostředků přijatelnou strategií, jak zajistit dostatek prostředků pro případ neočekávané špičky zatížení.
Vhodným příkladem může být platforma elektronického obchodování, jejíž servery mají po celý rok konzistentní zatížení, jen před Vánocemi se očekává prudký nárůst v průběhu zatížení. Před očekávanou špičkou je vhodné zřídit dodatečné prostředky na základě historických dat využití v době špičky. Zareagovat dostatečně rychle na prudké zvýšení provozu je totiž většinou obtížné. Jak je popsáno v pozdějších částech, dynamické škálování obnáší časově náročné kroky: zjišťování změn průběhu zatížení a zřizování dalších prostředků k uspokojení nového zatížení. Oba tyto kroky vyžadují čas. A tato časová prodleva může stačit k tomu, aby se systém zahltil nebo v horším případě zcela selhal. V nejlepším případě dojde ke zhoršení kvality služby.
Zřizování nadměrných prostředků je také účinná obrana proti útokům DoS (útokům na dostupnost služby) nebo DDoS (distribuovaným útokům s cílem odepření služby), při kterých útočníci generují požadavky určené k zahlcení systému, a zvýšením objemů provozu se tak snaží způsobit jeho selhání. Při jakémkoli útoku vždy nějakou dobu trvá, než systém útok detekuje a provede nápravná opatření. Začne sice probíhat analýza vzorů požadavků, ale systém už je napadený, a než bude možné implementovat strategii zmírnění, musí být schopný pojmout zvýšený objem provozu.
Replikace
Důležité komponenty systému je možné duplikovat pomocí dalších hardwarových a softwarových komponent, a tiše tak vyřešit selhání v postižených částech systému, aniž by došlo k selhání celého systému. Existují dvě základní strategie replikace:
- Aktivní replikace, kdy všechny replikované prostředky jsou aktivní současně, reagují na všechny požadavky a zpracovávají je. Každý požadavek klienta se zpracovává následovně: všechny prostředky obdrží stejný požadavek, všechny na něj reagují a pořadí požadavků udržuje stav napříč všemi prostředky.
- Pasivní replikace, při které požadavky zpracovává pouze primární jednotka, zatímco sekundární jednotky jen udržují stav a přeberou zpracovávání až v případě, že primární jednotka selže. Klient udržuje kontakt jen s primárním prostředkem, který přenáší změnu stavu do všech sekundárních prostředků. Pasivní replikace má ale jednu nevýhodu. Při přepínání mezi primární a sekundární instancí se totiž může stát, že dojde k přerušení požadavků nebo snížení QoS.
Existuje také hybridní strategie označovaná jako částečně aktivní, která je velmi podobná aktivní strategii. Rozdíl je v tom, že je klientovi předáván pouze výstup primárního prostředku. Výstupy sekundárních prostředků se potlačí a zaprotokolují a jsou připravené k přepnutí, jakmile dojde k selhání primárního prostředku. Následující obrázek znázorňuje rozdíly mezi strategiemi replikace.
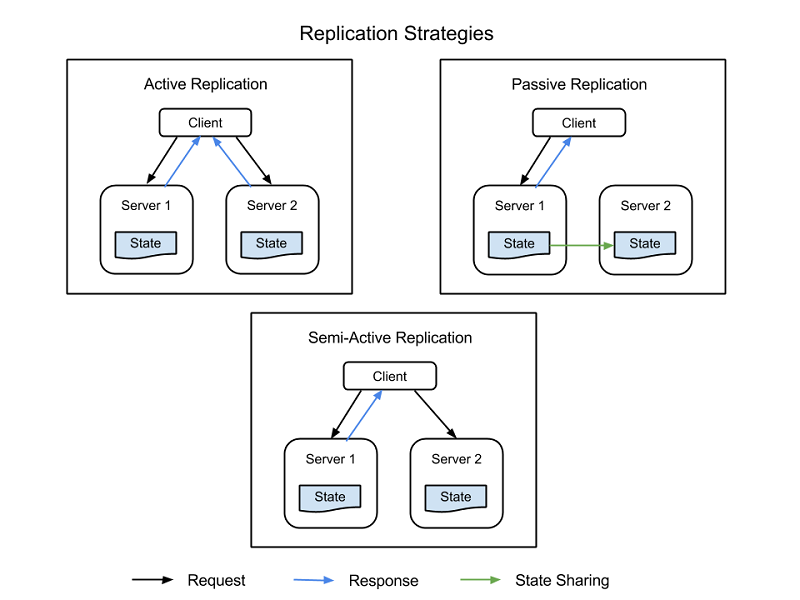
Obrázek 3: Strategie replikace
Důležitým faktorem replikace, který je třeba zvážit, je počet sekundárních prostředků, které se mají použít. Přístup bude u každé aplikace jiný v závislosti na důležitosti systému, v zásadě ale existují tři formální úrovně replikace:
- N+1: To v podstatě znamená, že pro aplikaci, která potřebuje správné fungování uzlů N, je jeden další prostředek zřízený jako bezpečný pro selhání.
- 2N: Na této úrovni je zřízen jeden další uzel pro každý uzel požadovaný pro normální funkci jako bezpečný pro selhání.
- 2N+1: Na této úrovni je zřízen jeden další uzel pro každý uzel potřebný pro normální funkci a jeden další uzel je zřízen jako bezpečný pro selhání.
Reaktivní opatření
Kromě prediktivních opatření můžou systémy přijímat také reaktivní opatření a řešit selhání až ve chvíli, kdy nastane:
Kontroly a monitorování
Všechny prostředky jsou nepřetržitě monitorované. Účelem monitorování je kontrolovat, jestli nenastalo nepředvídatelné chování nebo selhání prostředků. Na základě informací z monitorování je zvolena buď strategie obnovení, nebo strategie opětovné konfigurace. Prostředky se tak buď restartují, nebo jsou zřízeny nové. Monitorování může pomáhat při identifikaci chyb v systémech. Chyby, které způsobují nedostupnost služby, se označují jako selhání a ty, které v systému vyvolávají neočekávané nebo nesprávné chování, jako byzantské chyby.
K odhalení selhání systému slouží několik monitorovacích taktik. Dvě takové taktiky jsou:
- Ping-echo: Monitorovací služba požádá každý prostředek o svůj stav a dostane časový interval pro odpověď.
- Prezenčních signálů: Každá instance odesílá stav do monitorovací služby v pravidelných intervalech bez jakéhokoli triggeru.
Monitorování byzantských chyb obvykle závisí na vlastnostech poskytované služby. Monitorovací systémy můžou kontrolovat základní metriky, jako je latence, využití procesoru nebo využití paměti, a na základě srovnání s očekávanými hodnotami hodnotit, jestli se kvalita služby nezhoršila. Kromě toho jsou v každém důležitém bodě spouštění služby obvykle udržovány protokoly kontroly specifické pro aplikaci a jejich pravidelnou analýzou se ověřuje, jestli služba za všech okolností funguje správně (a jestli do systému nebyly vloženy chyby).
Kontrolní bod a restart
Několik programovacích modelů v cloudu implementuje strategie kontrolních bodů, kdy se ukládá stav v různých fázích provádění programu, aby bylo možné obnovit poslední uložený kontrolní bod. V aplikacích na analýzu dat probíhají často dlouhodobé, paralelně distribuované úlohy prováděné na terabajtech datových sad za účelem extrakce informací. Vzhledem k tomu, že se tyto úlohy spouštějí v několika malých blocích spuštění, může každý krok prováděného programu uložit celkový stav provádění jako kontrolní bod. V bodech selhání, kdy určitý uzel nemůže dokončit daný úkol, se dá prováděný program restartovat z předchozího kontrolního bodu. Největší výzvou při určování platných kontrolních bodů, ke kterým se program může vrátit, je sdílení informací paralelními procesy. Selhání v jednom procesu může způsobit kaskádové vrácení zpět v jiném procesu, protože kontrolní body vytvořené v tomto procesu můžou být výsledkem chyby v datech sdílených chybným procesem. V pozdějších modulech se dozvíte více o odolnosti programovacích modelů proti chybám.
Případové studie testování odolnosti proti chybám
Cloudové služby je potřeba vytvářet s ohledem na redundanci a odolnost proti chybám, protože žádná komponenta rozsáhlého distribuovaného systému nemůže zaručit 100% dostupnost nebo dobu provozu.
Všechny chyby (včetně chyb závislostí ve stejném uzlu, racku, datacentru nebo v regionálně redundantních nasazeních) je potřeba hladce vyřešit, aniž by měly vliv na celý systém. Je důležité otestovat, jestli je systém schopný vyřešit závažná selhání, protože někdy i několik sekund výpadku nebo snížení úrovně služeb může mít za následek ztrátu zisku v řádu stovek tisíc, ne-li milionů dolarů.
Je potřeba provádět pravidelné testování selhání při skutečném provozu, aby byl systém co nejodolnější a mohl zvládnout případný neplánovaný výpadek. Existuje řada systémů vytvořených k testování odolnosti. Jednou z takových sad testů je Simian Army od Netflixu.
Simian Army obsahuje služby (označované jako opice), které jsou určené ke generování různých druhů selhání v cloudu, zjišťování abnormálních podmínek a testování schopnosti systému tyto stavy překonávat. Cílem je udržet cloud bezpečný, zabezpečený a vysoce dostupný. Některé z těchto takzvaných opic v Simian Army jsou:
- Chaos monkey: Nástroj, který náhodně vybere produkční instanci a zakáže ji, aby zajistil, že cloud přežije běžné typy selhání bez jakéhokoli dopadu na zákazníka. Netflix popisuje Chaos Monkey jako "Myšlenka uvolnění divoké opice se zbraní ve vašem datacentru (nebo cloudové oblasti) náhodně zastřelit instance a žvýkat kabely - a to vše, co budeme obsluhovat naše zákazníky bez přerušení." Tento druh testování s podrobným monitorováním může v systému vystavit různé formy slabých stránek a na základě výsledků je možné sestavit strategie automatického obnovení.
- Opice latence: Služba, která vyvolává zpoždění mezi komunikací RESTful různých klientů a serverů, simuluje snížení výkonu a výpadky služeb.
- Opice doktora: Služba, která najde instance, které vykazují špatné chování (například zatížení procesoru) a odebere je ze služby. Poskytuje vlastníkům služby určitý čas na zjištění příčiny problému a nakonec tuto instanci ukončí.
- Chaos gorilla: Služba, která může simulovat ztrátu celé zóny dostupnosti AWS. Slouží k testování, jestli služby automaticky upraví rozložení funkčnosti ve zbývajících zónách, aniž by to zaznamenal uživatel nebo byl potřeba ruční zásah.